Recent advancements in Large Language Models (LLMs) have demonstrated remarkable
capabilities in code generation. However, existing benchmarks primarily focus on
function-level or class-level code generation, leaving a significant gap in evaluating LLMs'
ability to generate complete, deployable software repositories. We introduce
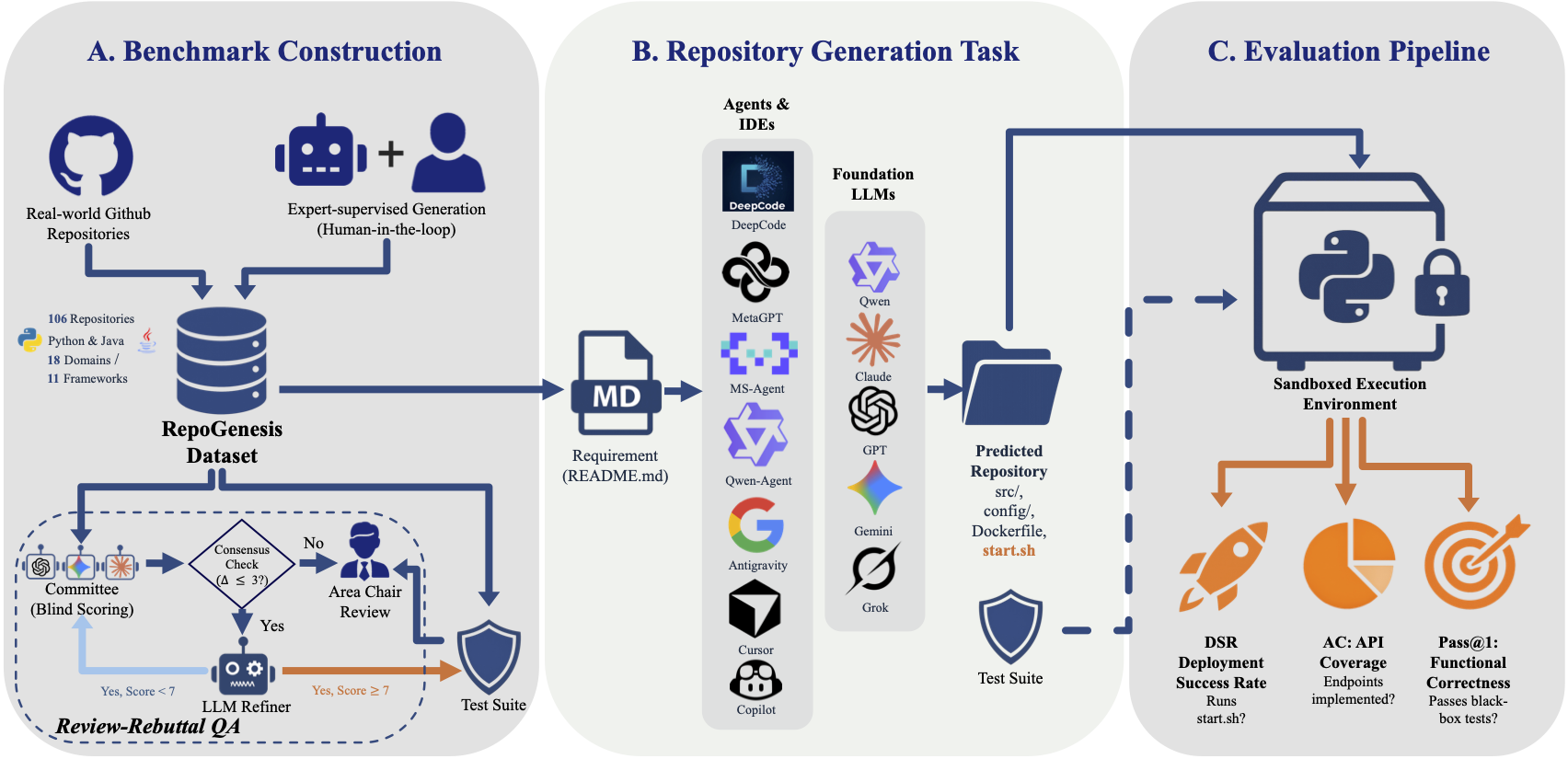
RepoGenesis, the first multilingual benchmark for repository-level
end-to-end web microservice generation. RepoGenesis consists of 106 diverse web microservice
repositories (60 Python, 46 Java) spanning 11 frameworks and 18 application domains. Unlike
traditional benchmarks, RepoGenesis assesses LLMs' capability to generate complete
repositories from natural language requirements, including project structure, dependencies,
configurations, and implementation. We evaluate multiple LLM-based agents and commercial
IDEs using three key metrics: Pass@1 for functional correctness,
API Coverage (AC) for implementation completeness, and Deployment
Success Rate (DSR) for deployability. Our comprehensive evaluation reveals
significant challenges in repository-level code generation and provides insights into the
current state and future directions of automated software development.