Overview
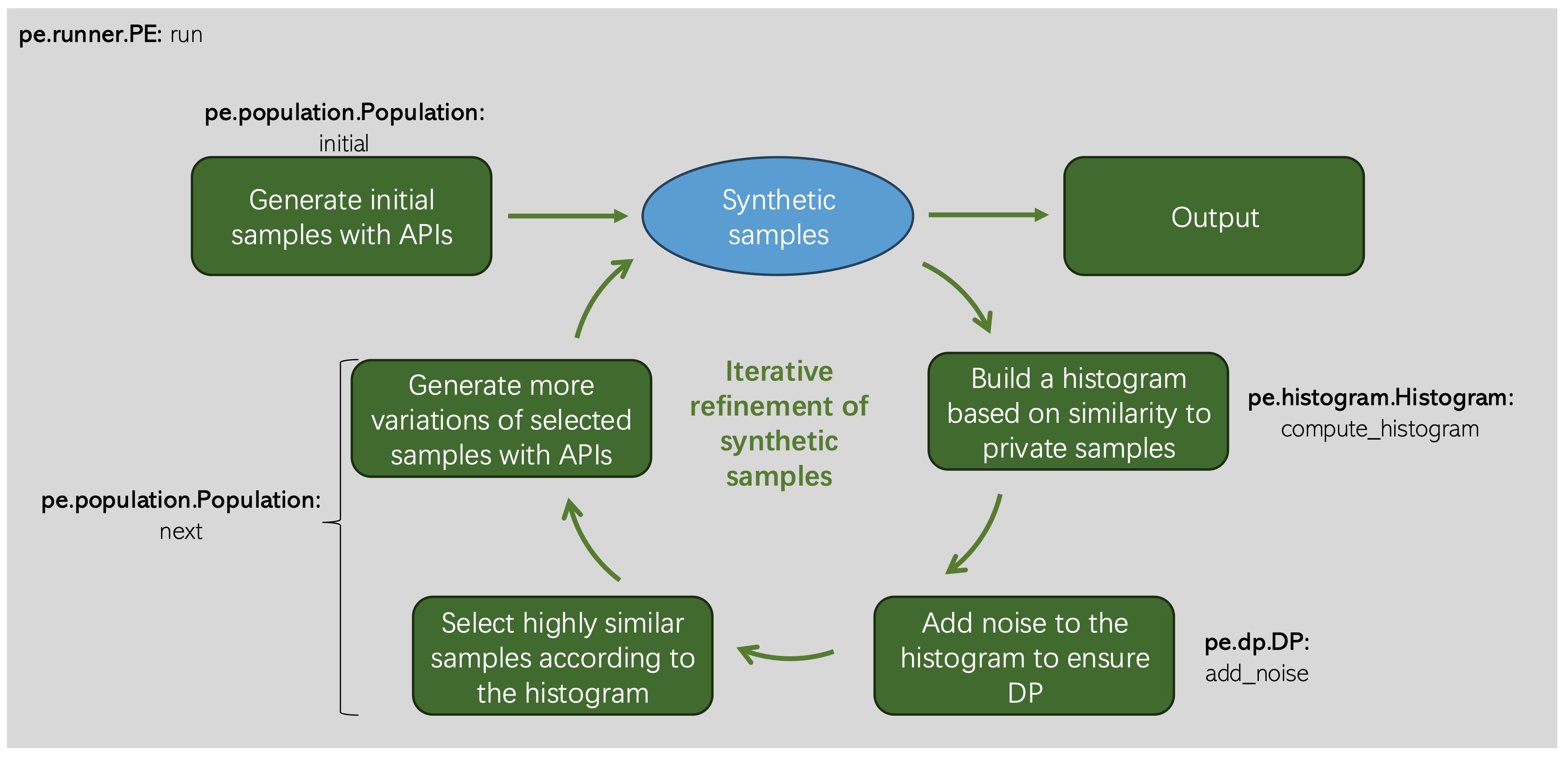
Fig. 1 The workflow of Private Evolution.
The Private Evolution Algorithm
The workflow of Private Evolution is shown in the above Fig. 1. The workflow consists of the following steps:
Using the foundation model API to randomly generate the initial synthetic samples.
Iteratively refining the synthetic samples by:
Building a histogram over the synthetic samples using the private samples. The histogram value for each synthetic sample represents how similar it is to the private samples.
Adding noise to the histogram to ensure differential privacy.
Selecting a subset of the synthetic samples based on the noisy histogram. Those selected samples are expected to be more similar to the private samples.
Using the foundation model API to generate variations of the selected synthetic samples.
Outputting the final synthetic samples.
Core Design Principles of This Library
The design principles of this library are:
Easy to use.
Supporting different data modalities (e.g., images, text, tabular data), different foundation model APIs (e.g., Stable Diffusion, GPT models), different Private Evolution algorithms (e.g., PE, Aug-PE), and different evaluation metrics (e.g., FID), all in one framework.
Easy to add new data modalities, foundation model APIs, Private Evolution algorithms, evaluation metrics, etc.
Towards these goals, the library is designed to be highly modular and extensible, as discussed next.
Core Components of This Library
This library provides a set of core components that can be easily customized or replaced. The core components shown in the Fig. 1 include:
Runner: Running the whole Private Evolution algorithm.
Population: Generating the initial synthetic samples and the variations of the synthetic samples.
Histograms: Building the histogram over the synthetic samples.
DP: Adding noise to the histogram to ensure differential privacy.
In additional to these components shown in the Fig. 1, the library also has the following core components:
Data: This class holds the synthetic samples or the private samples. Different components are mostly communicated through objects of this class.
APIs: This class implements the foundation model APIs. This class is utilized by Population to generate the synthetic samples and the variations of the synthetic samples. It might also be used in some Histograms algorithms when building the histogram (e.g., when
lookaheadin PE is used).Embeddings: This class is used to embed the synthetic/private samples into an embedding space. It might be used in some Histograms algorithms when building the histogram. It might also be used in some metric evaluation callback modules (e.g., for computing FID).
Callbacks and Loggers: The Runner can be configured to call a given list of callback modules at the end of each Private Evolution iteration. This is very useful for saving the intermediate results, evaluating the synthetic samples, etc. Since we might want to evaluate multiple metrics (e.g., FID, precision, recall), and for each metric, we might want to log it in different ways (e.g., saving it to a file, printing it to the console, uploading it to WandB), the library abstracts this part into two modules:
Callbacks: This module computes the metrics and (optionally) return the results. (The callback can also return nothing if it does not need the loggers to help with logging the results, e.g., if this callback is for saving the immediate synthetic samples.)
Loggers: All results returned by the callback modules will be passed through each of the logger modules, which will then log the results in the desired way.