DirectX-Specs
Mesh Shader
v0.86
Contents
-
SV_RenderTargetArrayIndex limitations based on queryable capability
- D3D API calls
- HLSL attributes and intrinsics
- numthreads
- outputtopology
- System Value Semantics
- SV_DispatchThreadID
- SV_GroupThreadID
- SV_GroupIndex
- SV_GroupID
- SetMeshOutputCounts
- Shared Output Arrays
- Vertex Indices
- Vertex Attributes
- Primitive Attributes
- Signature Linkage
- Mesh Payload
- SV_ViewID
- SV_CullPrimitive
- SV_PrimitiveID in the Pixel Shader
- DispatchMesh - intrinsic
- Rendering of the mesh
- Examples
Intro
This document describes a next-generation replacement for Vertex and Geometry shaders in a D3D12 pipeline called “Mesh shader”. Mesh shader support in D3D12 attempts to strike a balance between programmability and expressiveness, with efficient and intuitive implementations.
Motivation for adding Mesh Shader
The main goal of the Mesh shader is to increase the flexibility and performance of the geometry pipeline. Mesh shaders subsume most aspects of Vertex and Geometry shaders into one shader stage by processing batches of vertices and primitives before the rasterizer. They are additionally capable of amplifying and culling geometry.
Mesh shaders also enhance performance by allowing geometry to be pre-culled without outputting new index buffers to memory, whereas currently some geometry is culled by fixed function hardware.
There will additionally be a new Amplification shader stage, which enables current tessellation scenarios. Eventually the entire vertex pipeline will be two stages: an Amplification shader followed by a Mesh shader.
In recent years developers proposed geometry pipelines that process index buffers with a compute shader before vertex shaders. This compels us to revisit geometry pipelines and move towards accommodating this type of pipeline as part of the API.
Mesh shaders require developers to refactor their geometry toolchain by separating geometry into compressed batches (meshlets) that fit well into the Mesh shader model and turn off hardware index reads altogether. Titles can convert meshlets into regular index buffers for vertex shader fallback.
From the hardware perspective the goal is to remove the need for the index processing part of the IA and allow GPUs to be more parallel.
Mesh and Amplification shaders will use graphics root signature or their parameters. We will add shader visibility flags for Mesh and Amplification shader root signature slots.
With Mesh shaders, index buffers and input layouts can not be specified in the PipelineState description.
The Amplification shader and the Mesh shader are only supported for D3D12.
Both the Mesh shader and the Amplification shader are bound to new shader bind points.
Streamout is not planned to be carried over from the GeometryShader. Instead, a new type of append buffer might be added in the future instead, but will not be outlined in this spec.
Conceptual high level overview
A Mesh shader is a new type of shader that combines vertex and primitive processing. VS, HS, DS, and GS shader stages are replaced with Amplification Shader and Mesh Shader. Roughly, Mesh shaders replace VS+GS or DS+GS shaders and Amplification shaders replace VS+HS.
The Amplification shader allows users to decide how many Mesh shader groups to run and passes data to those groups. The intent for the Amplification shader is to eventually replace hardware tessellators.
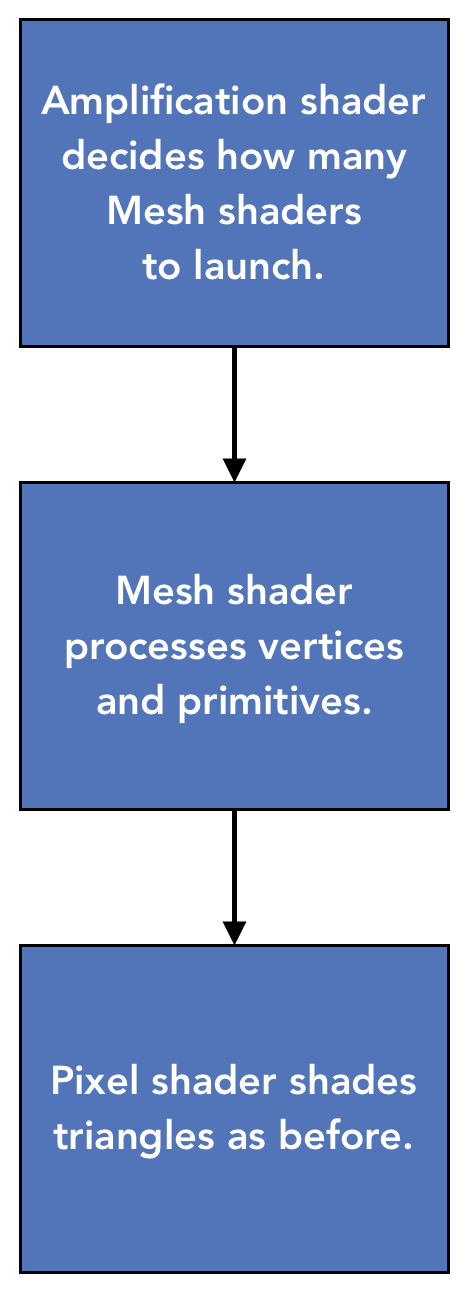
The Mesh shader runs in threadgroups which are launched by calling a new API:
void DispatchMesh(UINT ThreadGroupCountX, UINT ThreadGroupCountY, UINT ThreadGroupCountZ);
Indirect dispatch is also supported by adding
D3D12_INDIRECT_ARGUMENT_TYPE_DISPATCH_MESH enum value to D3D12_INDIRECT_ARGUMENT_TYPE
and D3D12_DISPATCH_MESH_ARGUMENTS member to D3D12_INDIRECT_ARGUMENT_DESC.
More details in the ExecuteIndirect section.
Mesh shader threadgroups have access to groupshared memory like compute shaders. Shader writers are free to declare groupshared arrays up to the maximum allowed size. The groupshared limit for mesh shaders is reduced to 28k, slightly smaller than the 32k limit which applies to compute shaders.
Mesh shader outputs comprise vertices and primitives. Different from, say, a vertex shader, there is no implicit association of a threadgroup thread and an output vertex or a primitive. For example, a threadgroup may have 3 threads, each thread outputting 6 vertices and 2 primitives for a total of 18 vertices and 6 primitives per threadgroup. This gives sufficient freedom to the shader writer to balance the ALU loads in threads and avoid wasting lanes.
The following output rules (A) will apply and may be validated:
-
The output vertices for all output primitives must be written by the mesh shader in the output, otherwise behavior is undefined.
-
The number of output vertices and primitives must be specified at runtime by the shader by calling SetMeshOutputCounts, otherwise, the shader will not output any mesh, and writing to vertex or primitive attributes or indices results in undefined behavior.
A new type of output is added – per-primitive output.
The packed size in rows of attributes for vertices
plus the packed size in rows of attributes for primitives
cannot exceed 32 rows (where each row is a vector of 4 attributes).
The Mesh shader can be attached to a Pixel shader if desired, but does not have to be if the app just wants to do UAV accesses but no rasterization.
In the case that there is a Pixel shader,
in the Mesh shader to Pixel shader pipeline,
signature elements are no longer aligned between stages by packing location.
Instead, Pixel shader input elements must be matched to output elements
from the mesh shader by the semantic name, system value type and semantic index.
Attributes that are uniform for a primitive,
including system value attributes such as:
SV_RenderTargetArrayIndex, SV_ViewportArrayIndex, and SV_CullPrimitive,
should now be placed in the attribute structure for primitives,
rather than the attribute structure for vertices.
Attributes used with GetAttributeAtVertex
should be placed in the attribute structure for vertices,
and marked with the nointerpolation modifier.
In the case that there is a pixel shader input aligned with a mesh shader per-primitive output,
and that attribute is not marked as nointerpolation, the driver will still force the attribute to nointerpolate
in order to maintain functionality.
Vertex order is determined by the order of the vertex indices for the primitive.
The first vertex is the one referenced by the first index in this vector.
When the term provoking vertex is used in other feature descriptions,
for the mesh shader pipeline, it means the first vertex.
This order applies to the component order of SV_Barycentrics
and the index passed to GetAttributeAtVertex.
If a nointerpolation attribute in the vertices is read directly in the pixel shader,
its value comes from the first vertex specified in the vertex indices for this primitive.
Primitive attributes do not require any interpolation modifiers to be specified, nor do they have any effect.
Inputs to the Mesh shader don’t have IA enabled.
Since IA is disabled, each thread of the Mesh shader receives inputs
similar to those in a compute shader, meaning just thread IDs,
plus a group-uniform mesh payload from an Amplification shader, if any.
It’s up to the shader author to read indices, read vertices, and output primitives.
To make reading and processing of some types of legacy index buffers easier, D3D will
provide helper functions, which are described in a separate “future work” document.
Geometry culling and amplification are possible,
similar to what a Geometry Shader can do now.
The number of threads in a threadgroup must be declared with the
[numthreads(X, Y, Z)] attribute,
and the implementation must provide a 3-dimensional grid with exactly X*Y*Z
user accessible threads in the threadgroup.
The threadgroup dimensions are limited by X*Y*Z <= 128.
To support the ViewID feature of D3D12, there is a system value input SV_ViewID
which specifies the current view being computed by the Mesh shader group.
The model exposed to the user is the same as with the shader stages of the existing vertex pipeline.
You write your mesh shader as if the group is computing only one view, with some constraints.
In order to enable single-pass muti-view implementation for Tier 3 View Instancing,
certain constraints will be enforced on what is allowed to be dependent on SV_ViewID.
This ensure that vertices and primitives produced for each view align across views,
while vertex and primitive attributes can vary per-view.
A new primitive attribute SV_CullPrimitive allows you to cull primitives
on a per-view basis, which translates to a view mask on multi-view implementations.
The compiler will track SV_ViewID dependent attributes and groupshared memory
so that the D3D runtime can validate the shader against
the attribute and groupshared limits
for the view count on Tier 3 View Instancing.
More details in the SV_ViewID section.
Programmable amplification support is done using an Amplification shader. This shader stage can be used to replace the hardware tessellator. The idea is to be able to launch a variable number of children Mesh shaders to enable amplification factors larger than a single Mesh shader can support. An Amplification shader is bound with a Mesh shader in a Pipeline State Object, and therefore an Amplification shader can only launch one type of a child Mesh shader, many instances of it, if needed.
Mesh shader output size limits
Given:
| Variable | Definition |
|---|---|
n_vert_attr, n_prim_attr |
Total number of vertex or primitive scalar attributes |
n_views |
Number of views for Tier 3 View Instancing, otherwise == 1 |
n_vert_per_view_attr, n_prim_per_view_attr |
Number of scalar attributes dependent on SV_ViewID |
n_vert_view_shared_attr, n_prim_view_shared_attr |
Number of scalar attributes not dependent on SV_ViewID |
and the following definitions:
#define ALIGN32(n) (((n) + 31) & ~31)
n_vert_attr = n_vert_view_shared_attr + (n_vert_per_view_attr * n_views);
vert_attr_bytes = n_vert_attr * 4;
n_prim_attr = n_prim_view_shared_attr + (n_prim_per_view_attr * n_views);
prim_attr_bytes = n_prim_attr * 4;
The following Mesh shader output limit applies:
vert_attr_bytes * ALIGN32(n_verts) + prim_attr_bytes * ALIGN32(n_prims) <= 32,768
Additionally, without accounting for per-view expansion, vertex and primitive attributes must pack into 32 4-component vector rows in total, in accordance with vertex attribute packing rules, without packing vertex and primitive attributes into the same row.
Since the number of enabled views isn’t known when the shader is compiled, the output size will be validated by the compiler and DXIL validator assuming only one view. At PSO creation time, runtime validation will verify that output space limitations are not exceeded with per-view attributes expanded by the number of views.
Amplification shader and Mesh shader
The amplification shader creates an output structure for child threadgroups and sets the number of child threadgroups to launch, which are then used to run mesh shaders.
For clarification, the way an amplification shader outputs child threadgroups can be seen as similar to how the hull shader outputs tessellation factors.
Each child Mesh shader has access to the data structure created by the parent Amplification shader. This is not entirely dissimilar to how currently per-patch attributes get passed into the domain shader.
There is no “return” semantics from the Mesh shader into the Amplification shader – all the Amplification shader does is send the number of child Mesh shaders to launch to the system.
| Required Support from the device | |
|---|---|
| Amplification shader | Mandatory |
| Amplification shader outputs to Mesh shader | Up to 16k bytes per instance |
| Mesh shader | Mandatory |
| Mesh shader num threads | 128 |
| Mesh shader max output verts | 256 |
| Mesh shader max output prims | 256 |
Amplification shader output payload must not exceed 16k bytes per instance.
Mesh shader output data (including alignment constraints) must not exceed 32k bytes per instance.
The size of these two combined must not exceed 47k bytes.
Rasterization order
When rasterization is enabled (pixel shader or depth only rendering) and the pipeline contains an amplification shader and/or mesh shader, the following rasterization ordering guarantees apply:
Triangles generated by any individual mesh shader thread group are always retired by the rasterizer in the order that thread group specified it’s primitive outputs. This remains true for all the cases in the rest of this discussion, where ordering with respect to neighboring thread groups is discussed.
Pixel shader invocations (any shader invocations) may not execute in order. Rather only the resulting rendertarget/depth/stencil buffer accesses must honor any specified ordering, over any given target location, e.g. rendertaret/depth sample. If the application needs UAV accesses during pixel shader invocation to be ordered over any given target location, the RasterizerOrderedViews (ROV) feature needs to be used in the pixel shader.
If the pipeline state includes a mesh shader but no amplification shader, the outputs of each thread group are retired by the rasterizer sequentially with respect to neighboring thread groups. So all primitives generated by the DispatchMesh() API call are retired by the rasterizer in a fully defined order. The ordering of thread groups is defined as:
for(z in [0..ThreadGroupCountZ-1])
{
for(y in [0...ThreadGroupCountY-1])
{
for(x in [0...ThreadGroupCountX-1])
{
group (x,y,z) is next
}
}
}
If the pipeline includes an amplification shader, only partial ordering of rasterization output is guaranteed. Individual amplification shader thread groups retire their rasterized output, produced via child mesh shader thread groups, in sequential order with respect to neighboring amplification shader thread groups. The ordering of thread groups is the (x,y,z) order described above, applied to the amplification shader stage in this case.
However, the child mesh shader thread groups produced by any individual amplification shader thread group may retire rasterized output in any order with respect to other children of the parent amplification shader thread group.
At the same time, individual mesh shader invocations still retire rasterized output in each mesh shader’s output primitive order (defined at the beginning of this discussion). In the presence of an amplification shader, any ROV accesses from a pixel shader over a given target location are ordered, with the exception of the arbitrary ordering of mesh shader rasterization retirement described above.
Pipeline Statistics
In order to track the number of invocations of Mesh Shaders and Amplification shaders in a given program, as well as the number of primitives output by a mesh shader, applications can use the Pipeline Statistics feature.
This means versioning the D3D12_QUERY_DATA_PIPELINE_STATISTICS struct to include ASInvocations and MSInvocations -
to track the number of amplification/mesh shaders that are invoked- and MSPrimitives to track the number of primitives output by a mesh shader.
This exists as follows:
typedef struct D3D12_QUERY_DATA_PIPELINE_STATISTICS1
{
UINT64 IAVertices;
UINT64 IAPrimitives;
UINT64 VSInvocations;
UINT64 GSInvocations;
UINT64 GSPrimitives;
UINT64 CInvocations;
UINT64 CPrimitives;
UINT64 PSInvocations;
UINT64 HSInvocations;
UINT64 DSInvocations;
UINT64 CSInvocations;
UINT64 ASInvocations;
UINT64 MSInvocations;
UINT64 MSPrimitives;
} D3D12_QUERY_DATA_PIPELINE_STATISTICS1;
Similarly, a new DDI, D3D12DDI_QUERY_DATA_PIPELINE_STATISTICS1 is used:
typedef struct D3D12DDI_QUERY_DATA_PIPELINE_STATISTICS1
{
UINT64 IAVertices;
UINT64 IAPrimitives;
UINT64 VSInvocations;
UINT64 GSInvocations;
UINT64 GSPrimitives;
UINT64 CInvocations;
UINT64 CPrimitives;
UINT64 PSInvocations;
UINT64 HSInvocations;
UINT64 DSInvocations;
UINT64 CSInvocations;
UINT64 ASInvocations;
UINT64 MSInvocations;
UINT64 MSPrimitives;
} D3D12DDI_QUERY_DATA_PIPELINE_STATISTICS1;
Since some drivers have Mesh Shader support without support in pipeline statistics, it is important to
use CheckFeatureSupport to query D3D12_FEATURE_DATA_D3D12_OPTIONS8 for MeshShaderPipelineStatsSupported
before using Pipeline Statistics to evaluate mesh shader or amplification shader data.
This query returns true on all drivers past the Windows 10 May 2021 Update release that support Mesh Shaders.
This can be done as follows:
D3D12_FEATURE_DATA_D3D12_OPTIONS8 featureData = {};
pDevice->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS8, &featureData, sizeof(featureData));
VERIFY_IS_TRUE(featureData.MeshShaderPipelineStatsSupported);
If featureData.MeshShaderPipelineStatsSupported returns false, meaning that either the driver does not support
Mesh Shaders or the driver was released prior to Iron, the query to D3D12_QUERY_DATA_PIPELINE_STATISTICS1 will return 0
for the three new fields.
The following enums are also revised to support the new pipeline statistics struct:
D3D12_QUERY_HEAP_TYPE_PIPELINE_STATISTICS1 is added to the enum D3D12_QUERY_HEAP_TYPE.
D3D12_QUERY_TYPE_PIPELINE_STATISTICS1 is added to the enum D3D12_QUERY_TYPE.
D3D12DDI_QUERY_HEAP_TYPE_PIPELINE_STATISTICS1 is added to the enum D3D12DDI_QUERY_HEAP_TYPE.
D3D12DDI_QUERY_TYPE_PIPELINE_STATISTICS1 is added to the enum D3D12DDI_QUERY_TYPE.
MSPrimitives and view instancing
The interaction between the MSPrimitives pipeline statistic and view instancing depends on the view instancing tier (D3D12_VIEW_INSTANCING_TIER) of the device.
On D3D12_VIEW_INSTANCING_TIER_NOT_SUPPORTED devices, view instancing doesn’t affect MSPrimitives.
On D3D12_VIEW_INSTANCING_TIER_1 devices, view instances increment MSPrimitives.
On D3D12_VIEW_INSTANCING_TIER_2 devices,
- If SV_ViewID is referenced from MS, view instances increment MSPrimitives.
- If SV_ViewID is referenced from a later stage like PS, view instances might or might not increment MSPrimitives.
On D3D12_VIEW_INSTANCING_TIER_3 devices,
- If SV_ViewID is referenced from MS, view instances increment MSPrimitives.
- If SV_ViewID is referenced from a later stage like PS, then view instances don’t increment MSPrimitives.
Culled primitives’ effect on MSPrimitives
Culled primitives might or might not be included in MSPrimitives, depending on the GPU implementation.
Applications can find out whether the GPU implementation includes culled primitives in the MSPrimitives count, using a queriable capability called MSPrimitivesPipelineStatisticIncludesCulledPrimitives.
The capability is queried using
D3D12_FEATURE_DATA_D3D12_OPTIONS12 featureData12 = {};
VERIFY_SUCCEEDED(m_pDevice->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS12, &featureData12, sizeof(featureData12)));
bool includeCulledPrimitives = featureData12.MSPrimitivesPipelineStatisticIncludesCulledPrimitives == D3D12_TRI_STATE_TRUE;
In the API, the capability appears as
typedef
enum D3D12_FEATURE
{
...
D3D12_FEATURE_D3D12_OPTIONS12 = 41
} D3D12_FEATURE;
typedef
enum D3D12_TRI_STATE
{
D3D12_TRI_STATE_UNKNOWN = -1,
D3D12_TRI_STATE_FALSE = 0,
D3D12_TRI_STATE_TRUE = 1
} D3D12_TRI_STATE;
typedef struct D3D12_FEATURE_DATA_D3D12_OPTIONS12
{
_Out_ D3D12_TRI_STATE MSPrimitivesPipelineStatisticIncludesCulledPrimitives;
} D3D12_FEATURE_DATA_D3D12_OPTIONS12;
If the capability value is FALSE, then culled primitives are not included in the MSPrimitives count.
If the capability value is TRUE, then called primitives are included in the MSPrimitives count.
If the capability value is UNKNOWN, then the culled primitives might or might not be included in the count.
Remark
At the DDI level, drivers do not return UNKNOWN. At the application level, a capability value of UNKNOWN may be returned if the capability can not be queried from the driver. This could be relevant when, for example, using a driver which supports the mesh shader feature but has not been updated to support the 0086 DDI version.
At the DDI level, the capability is communicated through UMD DDI revision 0086:
#define D3D12DDI_INTERFACE_VERSION_R8 ((D3D12DDI_MAJOR_VERSION << 16) | D3D12DDI_MINOR_VERSION_R8)
#define D3D12DDI_BUILD_VERSION_0086 6
#define D3D12DDI_SUPPORTED_0086 ((((UINT64)D3D12DDI_INTERFACE_VERSION_R8) << 32) | (((UINT64)D3D12DDI_BUILD_VERSION_0086) << 16))
With revision 0086, there exists a revised OPTIONS structure:
// D3D12DDICAPS_TYPE_D3D12_OPTIONS
typedef struct D3D12DDI_D3D12_OPTIONS_DATA_0086
{
...
BOOL MSPrimitivesPipelineStatisticIncludesCulledPrimitives;
}
SV_RenderTargetArrayIndex limitations based on queryable capability
Some target hardware has limitations where mesh shaders that write to the SV_RenderTargetArrayIndex attribute are limited to outputting a 3 bit value. This allows for selecting between at most 8 render targets. On such hardware, outputting an index value larger than 7 produces undefined behavior.
Other hardware, however, does not possess a limitation on valid output values of SV_RenderTargetArrayIndex and has support for full 11-bit render target array indexing.
Remark
11-bit indexing is the maximum needed, because Direct3D defines the max slices for an array texture as 2048.
Direct3D 12 has a queryable capability allowing applications to know if the target hardware supports
values of SV_RenderTargetArrayIndex which are 8 or greater. This capability is expressed through the
MeshShaderSupportsFullRangeRenderTargetArrayIndex field of D3D12_FEATURE_DATA_D3D12_OPTIONS9.
Applications can check this capability as follows:
D3D12_FEATURE_DATA_D3D12_OPTIONS9 featureData = {};
pDevice->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS9, &featureData, sizeof(featureData));
if (featureData.MeshShaderSupportsFullRangeRenderTargetArrayIndex)
...
Note that D3D12_FEATURE_DATA_D3D12_OPTIONS9 was not present in the first Windows OS release that introduced support for mesh shaders. Applications running on an operating system version where D3D12_FEATURE_DATA_D3D12_OPTIONS9 is not available must assume that mesh shaders only support a maximum render target array index of 7 and going beyond this produces undefined results.
From a DDI perspective, there exists a revised options structure:
typedef struct D3D12DDI_D3D12_OPTIONS_DATA_0081
{
...
BOOL MeshShaderSupportsFullRangeRenderTargetArrayIndex;
}
Drivers report their mesh-shader-render-target-array-index by setting the MeshShaderSupportsFullRangeRenderTargetArrayIndex field accordingly. On drivers which set the field to false or are of an older DDI version, the capability value is assumed to be false.
List of D3D API calls
Note that in the following tables, all functions must be supported by the device. Optional strictly means that the user has an option of whether or not to make use of this function.
| Function Name | Mandatory/optional for user to call |
|---|---|
| CheckFeatureSupport(Feature, *pFeatureSupportData, FeatureSupportDataSize) | Mandatory |
| CreatePipelineState(pipelineStateStreamDescriptor, riid, ppPipelineState) | Mandatory |
| DispatchMesh(ThreadGroupCountX, ThreadGroupCountY, ThreadGroupCountZ) | Optional |
| ExecuteIndirect(*pCommandSignature, MaxCommandCount, *pArgumentBuffer, ArgumentBufferOffset, *pCountBuffer, CountBufferOffset) | Optional |
List of HLSL elements for Mesh shader
| Function Name | Mandatory/optional for shader to use |
|---|---|
[numthreads(X, Y, Z)] |
Mandatory, X*Y*Z <= 128 |
[outputtopology(T)] |
Required: T is "line" or "triangle" |
SV_DispatchThreadID |
Optional input |
SV_GroupThreadID |
Optional input |
SV_GroupIndex |
Optional input |
SV_GroupID |
Optional input |
SetMeshOutputCounts(numVertices, numPrimitives) |
Optional |
vertex indices |
Required |
attributes for vertices |
Required with at least SV_Position |
attributes for primitives |
Optional |
mesh payload |
Optional payload from Amplification shader, payload size <= 16k |
SV_ViewID |
Optional input view ID for the group |
SV_CullPrimitive |
Optional per-primitive cull flag |
groupshared memory |
Optional, total size <= 28k |
List of HLSL elements for Amplification shader
| Function Name | Mandatory/optional for Amplification shader |
|---|---|
[numthreads(X, Y, Z)] |
Mandatory, X*Y*Z <= 128 |
| DispatchMesh(ThreadGroupCountX, ThreadGroupCountY, ThreadGroupCountZ, MeshPayload) | Mandatory, sizeof(MeshPayload) <= 16k |
groupshared memory |
Optional, total size <= 32k |
D3D API calls
CheckFeatureSupport
HRESULT CheckFeatureSupport(
D3D12_FEATURE Feature,
void *pFeatureSupportData,
UINT FeatureSupportDataSize
);
To determine whether mesh and amplification shaders are supported, you may call CheckFeatureSupport using a new D3D12_FEATURE enum,
D3D12_FEATURE_D3D12_OPTIONS7, which populates pFeatureSupportData with a new struct D3D12_FEATURE_DATA_D3D12_OPTIONS7.
This struct contains a field, MeshShaderTier, which references a new enum, D3D12_MESH_SHADER_TIER, defined as follows:
typedef enum D3D12_MESH_SHADER_TIER {
D3D12_MESH_SHADER_TIER_NOT_SUPPORTED,
D3D12_MESH_SHADER_TIER_1,
} ;
To ensure that mesh and amplification shaders are supported, after calling CheckFeatureSupport, check that
the MeshShaderTier is not D3D12_MESH_SHADER_TIER_NOT_SUPPORTED. The following code demonstrates this:
D3D12_FEATURE_DATA_D3D12_OPTIONS7 featureData = {};
pDevice->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS7, &featureData, sizeof(featureData));
VERIFY_ARE_NOT_EQUAL(featureData.MeshShaderTier, D3D12DDI_MESH_SHADER_TIER_NOT_SUPPORTED);
CreatePipelineState
HRESULT CreatePipelineState(
const D3D12_PIPELINE_STATE_STREAM_DESC *pDesc,
REFIID riid,
void **ppPipelineState
);
This function, along with a pipeline state stream descriptor that has a mesh shader and (optionally) an amplification shader attached, will create a graphics pipeline state object.
The descriptor:
-
must have IA and streamout disabled
-
must have a mesh shader attached (
MS) -
may optionally have an amplification shader attached (
AS) -
must not have any other shader types attached (
VS,GS,HS,DS) -
must use DXIL bytecode for all attached shaders
To attach mesh shaders and amplification shaders to a D3D12_PIPELINE_STATE_STREAM_DESC streamDesc, create a struct that contains
CD3DX12_PIPELINE_STATE_STREAM_AS and CD3DX12_PIPELINE_STATE_STREAM_MS, and set each to a corresponding D3D12_SHADER_BYTECODE.
For example:
struct PSO_STREAM
{
CD3DX12_PIPELINE_STATE_STREAM_ROOT_SIGNATURE pRootSignature;
CD3DX12_PIPELINE_STATE_STREAM_AS AS;
CD3DX12_PIPELINE_STATE_STREAM_MS MS;
...
CD3DX12_PIPELINE_STATE_STREAM_SAMPLE_DESC SampleDesc;
} Stream;
Stream.AS = GetASBytecode();
Stream.MS = GetMSBytecode();
...
D3D12_PIPELINE_STATE_STREAM_DESC streamDesc = {};
streamDesc.pPipelineStateSubobjectStream = &Stream;
streamDesc.SizeInBytes = sizeof(Stream);
CComPtr<ID3D12PipelineState> spPso;
pDevice->CreatePipelineState(&streamDesc, IID_PPV_ARGS(&spPso))
DispatchMesh API
DispatchMesh(ThreadGroupCountX, ThreadGroupCountY, ThreadGroupCountZ)
DispatchMesh launches the threadgroups for the amplification shader or the mesh shader in a case where no amplification shader is attached. Each of the three thread group counts must be less than 64k and the product of ThreadGroupCountX*ThreadGroupCountY*ThreadGroupCountZ must not exceed 2^22.
If there is an amplification shader, it will internally use an HLSL version of DispatchMesh with the same size limits to launch mesh shaders.
ExecuteIndirect
void ExecuteIndirect(
ID3D12CommandSignature *pCommandSignature,
UINT MaxCommandCount,
ID3D12Resource *pArgumentBuffer,
UINT64 ArgumentBufferOffset,
ID3D12Resource *pCountBuffer,
UINT64 CountBufferOffset
);
Execute indirect moves some work from the CPU to the GPU for increased performance.
In order to use this in conjunction with DispatchMesh, the ID3D12CommandSignature passed in must
have a D3D12_INDIRECT_ARGUMENT_DESC with a type of D3D12_INDIRECT_ARGUMENT_TYPE_DISPATCH_MESH
and a byteStride of sizeof(D3D12_DISPATCH_ARGUMENTS).
// New enum value of D3D12_INDIRECT_ARGUMENT_TYPE
typedef enum D3D12_INDIRECT_ARGUMENT_TYPE {
...
D3D12_INDIRECT_ARGUMENT_TYPE_DISPATCH_MESH
} D3D12_INDIRECT_ARGUMENT_TYPE;
typedef struct D3D12_INDIRECT_ARGUMENT_DESC {
D3D12_INDIRECT_ARGUMENT_TYPE Type; // = D3D12_INDIRECT_ARGUMENT_TYPE_DISPATCH_MESH
union {
...
// New member D3D12_DISPATCH_MESH_ARGUMENTS
struct {
UINT ThreadGroupCountX;
UINT ThreadGroupCountY;
UINT ThreadGroupCountZ;
} D3D12_DISPATCH_MESH_ARGUMENTS;
};
} D3D12_INDIRECT_ARGUMENT_DESC;
HLSL attributes and intrinsics
numthreads
[numthreads(X, Y, Z)]
void main(...)
This is a mandatory function attribute on the entry point of the Mesh shader.
It specifies the launch size of the threadgroup of the Mesh shader, just like with compute shader.
The number of threads can not exceed X * Y * Z = 128.
The implementation must call the Mesh shader with the number of user-available threads in each dimension equal to X, Y and Z, and it should not provide any hardware IA-based functionality. In the future, there will be D3D helper functions to help read the indices.
All output vertices for all output primitives must be set by the same threadgroup. Sharing of output vertices or output indices between Mesh shader threadgroups is not possible.
Note that a shader with this attribute greater than the number of threads returned by the runtime will fail pipeline state object creation call.
outputtopology
[outputtopology(T)]
void main(...)
This is a mandatory function attribute on the entry point of the Mesh shader.
It specifies the topology for the output primitives of the mesh shader.
T must be either "line" or "triangle".
System Value Semantics
Each of the following four system-values is computed in the following way:
If an Amplification Shader is used, system values are computed with respect to the DispatchMesh intrinsic called by the Amplification Shader.
If an Amplification Shader is not used, system values are relative to the invoking DispatchMesh API call.
For example, if an Amplification Shader is called with DispatchMesh(2,1,1)
and each AS invokes a Mesh Shader with DispatchMesh(1,1,1),
the SV_GroupID within each Mesh Shader threadgroup would be (0,0,0) since they are
computed with respect to the DispatchMesh(1,1,1) call.
SV_DispatchThreadID
void main(..., in uint3 dispatchThreadId : SV_DispatchThreadID, ...)
Provides the uint3 index of the current thread inside a DispatchMesh.
This is computed as explained above in System Value Semantics.
For a more detailed description see the HLSL docs.
SV_GroupThreadID
void main(..., in uint3 groupThreadId : SV_GroupThreadID, ...)
Provides the uint3 index of the current thread inside a threadgroup. This is computed as explained above in System Value Semantics.
For a more detailed description see the HLSL docs.
SV_GroupIndex
void main(..., in uint threadIndex : SV_GroupIndex, ...)
Provides the uint flattened index of the current thread inside a threadgroup. This is computed as explained above in System Value Semantics.
For a more detailed description see the HLSL docs.
SV_GroupID
void main(..., in uint3 groupId : SV_GroupID, ...)
Provides the uint3 index of the current threadgroup inside a DispatchMesh. This is computed as explained above in System Value Semantics.
For a more detailed description see the HLSL docs.
SetMeshOutputCounts
void SetMeshOutputCounts(
uint numVertices,
uint numPrimitives);
At the beginning of the shader the implementation internally sets a count of vertices and primitives to be exported from a threadgroup to 0. It means that if a mesh shader returns without calling this function, it will not output any mesh. This function sets the actual number of outputs from the threadgroup.
Some restrictions on the function use and interactions with output arrays follow.
-
This function can only be called once per shader.
-
This call must occur before any writes to any of the shared output arrays. The validator will verify this is the case.
-
If the compiler can prove that this function is not called, then the threadgroup doesn’t have any output. If the shader writes to any of the shared output arrays, compilation and shader validation will fail. If the shader does not call any of these functions, the compiler will issue a warning, and no rasterization work will be issued.
-
Only the input values from the first active thread are used.
-
This call must dominate all writes to shared output arrays. In other words, there must not be any execution path that even appears to reach any writes to any output array without first having executed this call.
Examples follow to illustrate restriction 5. and some other restrictions.
These are valid:
{ //...
SetMeshOutputCounts(...);
for (...) { // uniform or divergent
if (...) { // uniform or divergent
// write to output arrays -> Valid
}
}
}
{ //...
if (uniform_cond) {
SetMeshOutputCounts(...);
for (...) { // uniform or divergent
if (...) { // uniform or divergent
// write to output arrays -> Valid
}
}
}
}
{ //...
if (uniform_cond)
return;
SetMeshOutputCounts(...);
for (...) { // uniform or divergent
if (...) { // uniform or divergent
// write to output arrays -> Valid
}
}
}
These are not valid:
{ // ...
if (uniform_cond) {
SetMeshOutputCounts(...);
}
if (uniform_cond) {
// write to output arrays
// Invalid because write is not inside the same branch
// as SetMeshOutputCounts(...);
}
}
{ // ...
if (divergent_cond) {
// Invalid when called from divergent flow control
// however, the compiler may not catch this, resulting
// in undefined behavior.
SetMeshOutputCounts(...);
}
...
}
{ //...
if (uniform_cond) {
SetMeshOutputCounts(...);
} else {
SetMeshOutputCounts(...);
// Invalid: multiple calls in shader, even though they are under
// mutually exclusive flow control conditions.
}
}
The following scenarios produce undefined behavior. The hardware implementation is not required to clamp or mask out of bounds writes. Optional runtime validation (GBV) may catch these cases and issue errors.
-
The function is called from divergent flow control.
-
numVerticesis greater than the array dimension of thevertices. -
numPrimitivesis greater than the array dimension of theprimitives. -
The index used when writing to
verticesis greater than thenumVerticesspecified here. -
The index used when writing to vertex
indicesor attributes forprimitivesis greater than thenumPrimitivesspecified here.
Shared Output Arrays
There are three output parameters on the mesh shader defining arrays of output shared across the group, so that the threads in the Mesh shader group can cooperate on filling in the values.
The dimensions of these arrays define the maximum number of
vertices and primitives that may be output from this shader.
The array dimension must be included, even if it is 1.
A shader with a greater maximum number of vertices or primitives
than returned by the runtime will fail the pipeline state object creation call.
Each array cannot be read from,
and can only be written to after a call to
SetMeshOutputCounts is made
to set the actual vertex and primitive output sizes
for this thread group invocation.
See SetMeshOutputCounts
for interactions and restrictions for sizes and indexing.
When writing to the indices, the whole uint2 or uint3 vector element of the indices array must be written to at once. You cannot write just one component and leave other components to be filled in later.
Example:
void main(..., out indices Indices[MAX_OUTPUT_PRIMITIVES], ...) {
...
Indices[i] = uint3(1, 2, 3); // Allowed.
Indices[i].x = 1; // Not Allowed.
When writing to attributes, it is fine to write to any subset of the attribute structure at once, and fine to never write some attributes, if the rasterizer and downstream shader will not read them.
If the same element in one of these arrays is written to, in whole or in part, more than once, then the last value written is the value that will be used.
See the corresponding sections for details on each parameter.
| Mesh shader shared output arrays | Array dimension defines maximum number of | Required |
|---|---|---|
vertex indices |
primitives | Required |
attributes for vertices |
vertices | Required |
attributes for primitives |
primitives | Optional |
Vertex Indices
[outputtopology("line" or "triangle")]
void main(...,
out indices
[uint2 for line or uint3 for triangle]
primitiveIndices[MAX_OUTPUT_PRIMITIVES],
...)
This required parameter defines the shared output vertex indices array for the Mesh shader threadgroup.
Each array element defines the vertex indices that make up one output primitive.
The out and indices modifiers must be used with this parameter.
The type is either uint2 for outputtopology("line"),
or uint3 for outputtopology("triangle").
The static size of the array, MAX_OUTPUT_PRIMITIVES here,
defines the maximum number of primitives this mesh shader can produce,
and must match the size of the Primitive Attributes array.
The maximum size for this array is 256 elements.
You must write all two or three vertex indices of a primitive at once, otherwise the compiler and validator will throw an error. If you write the same primitive index more than once, the last value written will define the indices for the primitive.
Writing to this array must occur after the SetMeshOutputCounts call.
See that section for information on output size and indexing behavior and restrictions.
Remark
As there isn’t a way to inspect or access the raw output indices of a mesh shader from the application level, the underlying GPU implementation may choose to store output indices in a different format from uint2 or uint3.
Vertex Attributes
struct VertexAttributes {
// User-defined per-vertex attributes
// semantics are required and interpolation mode is used
};
void main(...,
out vertices VertexAttributes sharedVertices[MAX_OUTPUT_VERTICES],
...)
This required parameter defines the shared output vertex attribute array for the Mesh shader threadgroup.
The out and vertices modifiers must be used with this parameter.
The static size of the array, MAX_OUTPUT_VERTICES here,
defines the maximum number of vertices this mesh shader can produce.
The maximum size for this array is 256 elements.
This array is write-only, so the compiler will issue an error if you attempt to read from the array.
You can write individual attributes, and leave others unwritten if they will not be used in the Pixel shader. If you write to the same attribute at the same vertex index, the last value written will be the value exported from the Mesh shader.
This structure must have system-value or user-defined semantics defined for all elements, and the interpolation modes apply to the vertex attributes, just as with the elements of an output structure used as the return value from a Vertex shader.
One 4-component vector with the SV_Position semantic must be present in this structure,
since this is required by the rasterizer.
Writing to this array must occur after the SetMeshOutputCounts call.
See that section for information on output size and indexing behavior and restrictions.
Primitive Attributes
struct PrimitiveAttributes {
// User-defined per-primitive attributes
// semantics are required but interpolation mode is ignored
};
void main(...,
out primitives PrimitiveAttributes sharedPrimitives[MAX_OUTPUT_PRIMITIVES],
...)
This optional parameter defines the shared output primitive attribute array for the Mesh shader threadgroup.
The out and primitives modifiers must be used with this parameter.
The static size of the array, MAX_OUTPUT_PRIMITIVES here,
defines the maximum number of primitives this mesh shader can produce,
and must match the size of the vertex indices array.
The maximum size for this array is 256 elements.
You can write individual attributes, and leave others unwritten if they will not be used in the Pixel shader. If you write to the same attribute at the same primitive index, the last value written will be the value exported from the Mesh shader.
This structure must have system-value or user-defined semantics defined for all elements.
SV_RenderTargetIndex and SV_ViewportIndex and SV_CullPrimitive
can only be per-primitive attributes in MeshShader.
SV_ShadingRate is settable from mesh shaders on platforms which support coarse shading. When set from a mesh shader, SV_ShadingRate functions as an actual per-primitive attribute– not, say, a per-provoking-vertex attribute.
Writing to this array must occur after the SetMeshOutputCounts call.
See that section for information on output size and indexing behavior and restrictions.
Signature Linkage
In order to reuse pixel shaders that work on the traditional graphics pipeline, Signature linkage rules for the Mesh shader pipeline have been changed.
In the new Mesh shader pipeline, signature elements must be linked by matching semantic name, and semantic index. For system values, linkage is by the system value type and semantic index. Elements must no longer be linked by the packed location.
Packing locations are still set for vertex and primitive elements in signatures, but these may not match the pixel shader locations, due to the way these elements are defined in separate structures for Mesh shader. The elements will be packed with vertex elements first, with primitive elements packed starting on the row immediately following the last row used by the vertex elements. Vertex and primitive attributes will not be packed into the same row, even when the interpolation mode matches.
All of these elements must fit into a single 32-row (128 scalar element) signature. However, the actual number of components used will be used in the size limit calculation defined in the Mesh shader output size limits section.
Mesh Payload
void main(...,
in payload MeshPayloadStruct MeshPayload,
...)
This optional input supplies the payload passed to the Amplification shader’s DispatchMesh call. This parameter provides the same input values for the entire Mesh shader thread group.
The structure type for this parameter should match the user-defined structure used at the DispatchMesh call in the Amplification shader. Runtime will validate that the structure size reported by the compiler matches between the Amplification shader and the Mesh shader.
The data layout of this structure is the same as for structured buffers. The maximum size for this structure is 16k bytes.
SV_ViewID
SV_ViewID is special in the way it allows for a driver to create a version of
the shader that computes all views in a single shader pass. It does this by
duplicating SV_ViewID dependent values, computations, and attributes.
Runtime validation is required to check whether SV_ViewID expansion can be
supported a set number of views based on the number of dependent attributes.
For Mesh shader, this is complicated by accessing group shared memory.
Group shared memory dependent on SV_ViewID must be similarly expanded
by the number of views.
In addition to validation that attribute expansion fits within the available attribute limits
(as the current graphics pipeline does),
the runtime will also check that group shared expansion fits.
Dynamically indexed arrays written to with SV_ViewID dependent values
must be expanded by the multiplying the size by the number of views.
If a temporary or groupshared array is indexed by a value dependent on SV_ViewID,
the compiler (or DXIL validator) will issue an error,
as this usage is likely the result of incorrect assumptions about the model,
and probably will not result in the expected behavior,
or efficiency and consistency between multi-pass and single-pass implementations.
SV_ViewID dependent values are not tracked through writes to global memory,
however, values read from global memory at an address that is dependent on SV_ViewID
are considered dependent as well.
If in practice, validation detects the violation of a constraint in error, we will revisit and revise this section.
Note: SV_ViewID is only available as an input to a Mesh Shader, not an Amplification Shader.
Note: SV_ViewID is currently available as an input to Pixel Shader that does not consume attribute space (system generated value), and therefore cannot be written as an output from Mesh Shader.
In addition to the storage expansions, some constraints are required to enable a single-pass implementation.
The following values may not be dependent on SV_ViewID:
- The
numVerticesandnumPrimitivesvalues passed toSetMeshOutputCounts. - The index into the attribute array for
vertices, attribute array forprimitives, andindicesarray. - The index values written to the
indicesarray.
Amplification shaders do not support SV_ViewID input.
SV_CullPrimitive
This is a per-primitive boolean culling value that indicates whether to cull the primitive for the current view (SV_ViewID). Hardware that expands views inline can turn this into a per-view mask value in place of SV_ViewportID. SV_CullPrimitive will not consume space in the primitive signature. For the purpose of validating per-view attribute expansion, one 32-bit attribute will always be counted for SV_ViewportID, whether or not SV_ViewportID was declared. No attributes are counted for SV_CullPrimitive.
SV_PrimitiveID in the Pixel Shader
When mesh shaders are used, there is no system generated primitiveID (uint SV_PrimitiveID) value. If a pixel shader inputs SV_primitiveID and is paired with a mesh shader, the mesh shader must include SV_PrimitiveID as part of its primitive outputs and must manually output a value of its choosing for each primitive. So this behaves no differently than any other mesh shader primitive output without a special name. The basic purpose here is to allow pixel shaders that were written to work with other shaders like geometry shaders, where SV_PrimitiveID does exist, or vertex shaders, where the primitiveID is auto-generated, to be shared with the mesh shader as well.
DispatchMesh intrinsic
template <typename payload_t>
DispatchMesh(uint ThreadGroupCountX,
uint ThreadGroupCountY,
uint ThreadGroupCountZ,
groupshared payload_t MeshPayload);
This function, called from the amplification shader, launches the threadgroups for the mesh shader. This function must be called exactly once per amplification shader, must not be called from non-uniform flow control. The DispatchMesh call implies a GroupMemoryBarrierWithGroupSync(), and ends the amplification shader group’s execution.
The arguments are treated as uniform for the group, meaning that they are read from the first thread if not group-uniform (or groupshared). The intended use is to have the whole group of threads cooperate on constructing the MeshPayload. It also means that you cannot amplify the number of unique MeshPayload contents beyond the number of Amplification shader groups launched by the API.
Each of the three thread group counts must be less than 64k and the product of ThreadGroupCountX*ThreadGroupCountY*ThreadGroupCountZ must not exceed 2^22, or behavior is undefined.
A payload of data passed to all instances of Mesh shaders invoked by this call is passed through the MeshPayload parameter.
The payload type, specified by payload_t here, must be a user-defined struct
type. The size of this type must match the size of the type used in the Mesh
shader for the GetMeshPayload call. The maximum size
allowed for this structure is 16k bytes.
The size of the payload structure counts against groupshared memory limits. These limits are, to reiterate, 28k for mesh shaders and 32k for amplification shaders. For example, an application using the highest possible payload size of 16k would only have 16k left of groupshared available to its amplification shader and 12k to its mesh shader.
The structure is not flattened into a packed signature layout, but instead passed with the data layout specified by the native structure. Data layout should be the same as for structured buffers.
Rendering of the mesh
The mesh is rendered with the set of vertices and primitives set by the output functions. Runtime validation may be able to check for completeness of the meshes and correctness of the indices and issue an error if the rules (A) aren’t satisfied.
Programmable Primitive Amplification
A limited form of primitive amplification as in GS-amplification is supported with Mesh shaders. It’s possible to amplify input point geometry with up to 1:V and/or 1:P ratio where V is the number of output vertices reported by the runtime and P is the number of output primitives reported by the runtime.
However, programmable amplification as in Amplification shaders can’t be done in a single threadgroup because expansion factors are decided by the program and can be huge.
The Amplification shader is intended to be the shader stage that enables programmable Amplification in Mesh shaders.
Streamout
We don’t plan on supporting streamout as part of this feature. Instead, in the future, we would like to add a special append buffer UAV type or mode which will ensure the UAV’s outputs are in order of inputs and can be used from any shader stage including regular compute.
Examples
Example 1: Passthrough
// This gets read from the user vertex SRV
struct MyInputVertex
{
float4 something : SOMETHING;
};
// This is a bunch of outparams for the Mesh shader. At least SV_Position must be present.
struct MyOutputVertex
{
float4 ndcPos : SV_Position;
float4 someAttr : ATTRIBUTE;
};
#define NUM_THREADS_X 96
#define NUM_THREADS_Y 1
#define NUM_THREADS_Z 1
#define MAX_NUM_VERTS 252
#define MAX_NUM_PRIMS (MAX_NUM_VERTS / 3)
groupshared uint indices[MAX_NUM_VERTS];
// We output no more than 1 primitive per input primitive
// Input primitive has up to 3 input vertices and up to 3 output vertices
[outputtopology("triangle")]
[numthreads(NUM_THREADS_X, NUM_THREADS_Y, NUM_THREADS_Z)]
void PassthroughMesh shader(
in uint tid : SV_DispatchThreadID,
in uint tig : SV_GroupIndex,
out vertices MyOutputVertex verts[MAX_NUM_VERTS],
out indices uint3 triangles[MAX_NUM_PRIMS])
{
// Use a helper to read and deduplicate indices
// We need to read no more than MAX_NUM_VERTS indices and no more
// than MAX_NUM_PRIMS primitives. An offline index pre-process
// ensures that each threadgroup gets an efficiently packed
// workload. Because it's preprocessed, we only need to give the
// helper function our threadgroup index.
uint numVerticesInThreadGroup;
uint numPrimitivesInThreadGroup;
uint packedConnectivityForThisLanesPrimitive;
ReadTriangleListIndices(
numVerticesInThreadGroup, // out
numPrimitivesInThreadGroup, // out
indices, // out
packedConnectivityForThisLanesPrimitive, // out
indexBufferSRV, // SRV with the offline made IB
tig, // Thread group index
false); // 32 bit per index
// Set number of outputs
SetMeshOutputCounts(numVerticesInThreadGroup, numPrimitivesInThreadGroup);
// Transform the vertices and write them
uint numVertexIterations = numVerticesInThreadGroup / NUM_THREADS;
for (uint i=0; i <= numVertexIterations; ++i)
{
uint localVertexIndex = i * NUM_THREADS + tig;
if (localVertexIndex < numVerticesInThreadGroup)
{
MyOutputVertex v = User_LoadAndProcessVertex(indices[localVertexIndex]);
verts[localVertexIndex] = v;
}
}
// Now write the primitives
if (tig < numPrimitivesInThreadGroup)
{
triangles[tig] = uint3(
packedConnectivityForThisLanesPrimitive & 0xFF,
(packedConnectivityForThisLanesPrimitive >> 8) & 0xFF,
(packedConnectivityForThisLanesPrimitive >> 16) & 0xFF);
}
}
Example 2: Culling
// This gets read from the user vertex SRV
struct MyInputVertex
{
float4 something : SOMETHING;
};
// This is a bunch of outparams for the Mesh shader. At least SV_Position should be present.
struct MyOutputVertex
{
float4 ndcPos : SV_Position;
float4 someAttr : ATTRIBUTE;
};
cbuffer DrawParams
{
uint numPrimitivesInMesh;
};
#define NUM_THREADS_X 96
#define NUM_THREADS_Y 1
#define NUM_THREADS_Z 1
#define MAX_NUM_VERTS 252
#define MAX_NUM_PRIMS (MAX_NUM_VERTS / 3)
groupshared uint indices[MAX_NUM_VERTS];
groupshared uint remappedIndices[MAX_NUM_VERTS];
groupshared float4 ndcPositions[MAX_NUM_VERTS];
groupshared uint primitiveVisibilityMask[(MAX_NUM_PRIMS + 31) / 32];
groupshared uint vertexVisibilityMask[(MAX_NUM_PRIMS + 31) / 32];
// We output no more than 1 primitive per input primitive
// Input primitive has up to 3 input vertices and up to 3 output vertices
[outputtopology("triangle")]
[numthreads(NUM_THREADS_X, NUM_THREADS_Y, NUM_THREADS_Z)]
void PassthroughMesh shader(
in uint tid : SV_DispatchThreadID,
in uint tig : SV_GroupIndex,
out vertices MyOutputVertex verts[MAX_NUM_VERTS],
out indices uint3 triangles[MAX_NUM_PRIMS])
{
// Use helper to read and deduplicate indices
uint numVerticesInThreadGroup;
uint numPrimitivesInThreadGroup;
uint packedConnectivityForThisLanesPrimitive;
ReadTriangleListIndices(
numVerticesInThreadGroup, // out
numPrimitivesInThreadGroup, // out
indices, // out
packedConnectivityForThisLanesPrimitive, // out
indexBufferSRV, // SRV with the IB
tig, // Threadgroup index
false); // 32 bit per index
// Transform the vertices and write them
uint numIterationsOverVertices = numVerticesInThreadGroup / NUM_THREADS;
for (uint i=0; i <= numIterationsOverVertices; ++i)
{
uint localVertexIndex = i * NUM_THREADS + tig;
if (localVertexIndex < numVerticesInThreadGroup)
{
ndcPositions[localVertexIndex] =
User_LoadAndProcessVertexPosition(indices[localVertexIndex]);
}
}
// Reset visibility masks here
if (tig < _countof(primitiveVisibilityMask))
{
primitiveVisibilityMask[tig] = 0;
}
if (tig < _countof(vertexVisibilityMask))
{
vertexVisibilityMask[tig] = 0;
}
GroupSharedBarrier();
// Perform culling for all primitives
if (tig < numPrimitivesInThreadGroup)
{
// Call a helper to cull
uint3 indices = UnpackIndices(packedConnectivityForThisLanesPrimitive);
bool visible = CullTriangleHelper(
ndcPositions[indices.x],
ndcPositions[indices.y],
ndcPositions[indices.z],
D3D_CULL_ALL);
// Mark visible triangles and vertices in groupshared
if (visible)
{
primitiveVisibilityMask[tig / 32] |= 1 << (tig & 31);
vertexVisibilityMask[indices.x / 32] |= 1 << (indices.x & 31);
vertexVisibilityMask[indices.y / 32] |= 1 << (indices.y & 31);
vertexVisibilityMask[indices.z / 32] |= 1 << (indices.z & 31);
}
}
GroupSharedBarrier();
// Compute vertex packing results. Packing may help skip waves and we also
// require tight packing of the outputs. Packing may also fail to remove
// any work and so in this example we may end up with more vertices than
// there are lanes. We contrived the example to have enough lanes to fit
// one primitive into a lane.
uint myPackedPrimitiveIndex;
uint myPackedConnectivity;
uint numPackedVertices;
uint numPackedPrimitives;
ComputePackedIndices(
/*out*/remappedIndices,
/*out*/myPackedPrimitiveIndex,
/*out*/myPackedConnectivity,
/*out*/numPackedVertices,
/*out*/numPackedPrimitives,
/*in*/ vertexVisibilityMask,
/*in*/ primitiveVisibilityMask,
/*in*/ packedConnectivityForThisLanesPrimitive);
// Declare the number of outputs
SetMeshOutputCounts(numPackedVertices, numPackedPrimitives);
// Process the attributes and write the packed vertex out. This needs
// a loop because we may have 3 vertices per thread if packing didn't
// succeed in removing work.
numIterationsOverVertices = numPackedVertices / NUM_THREADS;
for (uint i=0; i <= numIterationsOverVertices; ++i)
{
uint localVertexIndex = i * NUM_THREADS + tig;
if (localVertexIndex < numPackedVertices)
{
uint remappedIndex = remappedIndices[localVertexIndex];
ov = User_LoadAndProcessRestOfVertex(ndcPositions[remappedIndex],
indices[remappedIndex]);
verts[localVertexIndex] = ov;
}
}
// Now write the primitives. We have enough threads to do one prim per thread.
if (tig < numPackedPrimitives)
{
triangles[tig] = uint3(
myPackedConnectivity & 0xFF,
(myPackedConnectivity >> 8) & 0xFF,
(myPackedConnectivity >> 16) & 0xFF);
}
}
Example 3: Amplification
// This gets read from the SRVs. Vertex buffers aren't automatically loaded now.
struct MyInputVertex
{
float4 something : SOMETHING;
};
// This is a bunch of outparams for the Mesh shader
struct MyOutputVertex
{
float4 ndcPos : SV_Position;
float4 someAttr : ATTRIBUTE;
};
// We expand a number of points into screenspace quads, each having 2 triangles
[outputtopology("triangle")]
[numthreads(64,1,1)]
void PassthroughPrimShader(
in uint tid : SV_DispatchThreadID,
in uint tig : SV_GroupIndex,
out vertices MyOutputVertex verts[256],
out indices uint3 triangles[128])
{
float4 ndcPosOfPoint;
float2 size;
User_LoadAndProcessParticleCentre(ndcPosOfPoint, size, tid);
// Check if it's going to be visible
bool isVisible = User_CullParticle(ndcPosOfPoint, size);
// Compute compaction vector
uint myIndexInVisibleIndex = PrefixSum(willBeVisible);
if (!isVisible)
{
return;
}
// Re-read the particle after compaction
User_LoadAndProcessParticleCentre(ndcPosOfPoint, size, myIndexInVisibleIndex);
// Output vertices and primitives
uint numBitsSetAcrossThreadgroup = D3DCountOnes(willBeVisible);
SetMeshOutputCounts(numBitsSetAcrossThreadgroup*4, numBitsSetAcrossThreadgroup*2);
uint i0 = myIndexInVisibleIndex * 4;
verts[i0 + 0] = User_GetTLVertex(ndcPosOfPoint, size);
verts[i0 + 1] = User_GetTRVertex(ndcPosOfPoint, size);
verts[i0 + 2] = User_GetBLVertex(ndcPosOfPoint, size);
verts[i0 + 3] = User_GetBRVertex(ndcPosOfPoint, size);
triangles[myIndexInVisibleIndex * 2 + 0] = uint3(i0, i0 + 1, i0 + 2);
triangles[myIndexInVisibleIndex * 2 + 1] = uint3(i0, i0 + 2, i0 + 3);
}