Dataset

Our dataset of 100,000 synthetic faces with 2D landmark and per-pixel segmentation labels is available for non-commercial research purposes. Please visit the dataset page.
Face analysis in the wild
using synthetic data alone
International Conference on
Computer Vision 2021
We demonstrate that it is possible to perform face-related computer vision in the wild using synthetic data alone.
The community has long enjoyed the benefits of synthesizing training data with graphics, but the domain gap between real and synthetic data has remained a problem, especially for human faces. Researchers have tried to bridge this gap with data mixing, domain adaptation, and domain-adversarial training, but we show that it is possible to synthesize data with minimal domain gap, so that models trained on synthetic data generalize to real in-the-wild datasets.
We describe how to combine a procedurally-generated parametric 3D face model with a comprehensive library of hand-crafted assets to render training images with unprecedented realism and diversity. We train machine learning systems for face-related tasks such as landmark localization and face parsing, showing that synthetic data can both match real data in accuracy as well as open up new approaches where manual labelling would be impossible.
Our dataset of 100,000 synthetic faces with 2D landmark and per-pixel segmentation labels is available for non-commercial research purposes. Please visit the dataset page.
Pixel-perfect segmentation labels let us achieve near-SOTA results using off-the-shelf neural networks.
With synthetic landmark labels, its easy to predict ten times as many landmarks as usual.



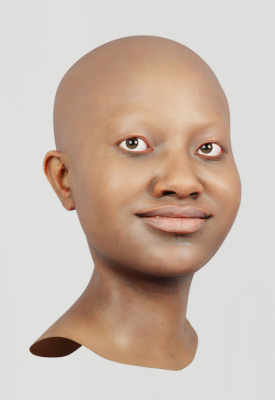



Our synthetic faces are realistic, diverse, and expressive. Starting with our template face, we randomize the identity, choose a random expression, apply a random texture, and attach random hair and clothing. We finally render the face in a random environment using Cycles: a physically-based path tracing renderer.

Identities sampled from our generative model. We trained this model on a diverse set of high quality scan data.

We randomly pick facial expressions from our performance capture database of 70,000 frames.

Synthetically-trained machine learning models should work well across the human population.
By evaluating our landmark detectors on the MUCT Face Database, which exhibits lighting, age, and ethnicity diversity, we see that models trained with synthetic data alone can generalize well to real data of diverse individuals.
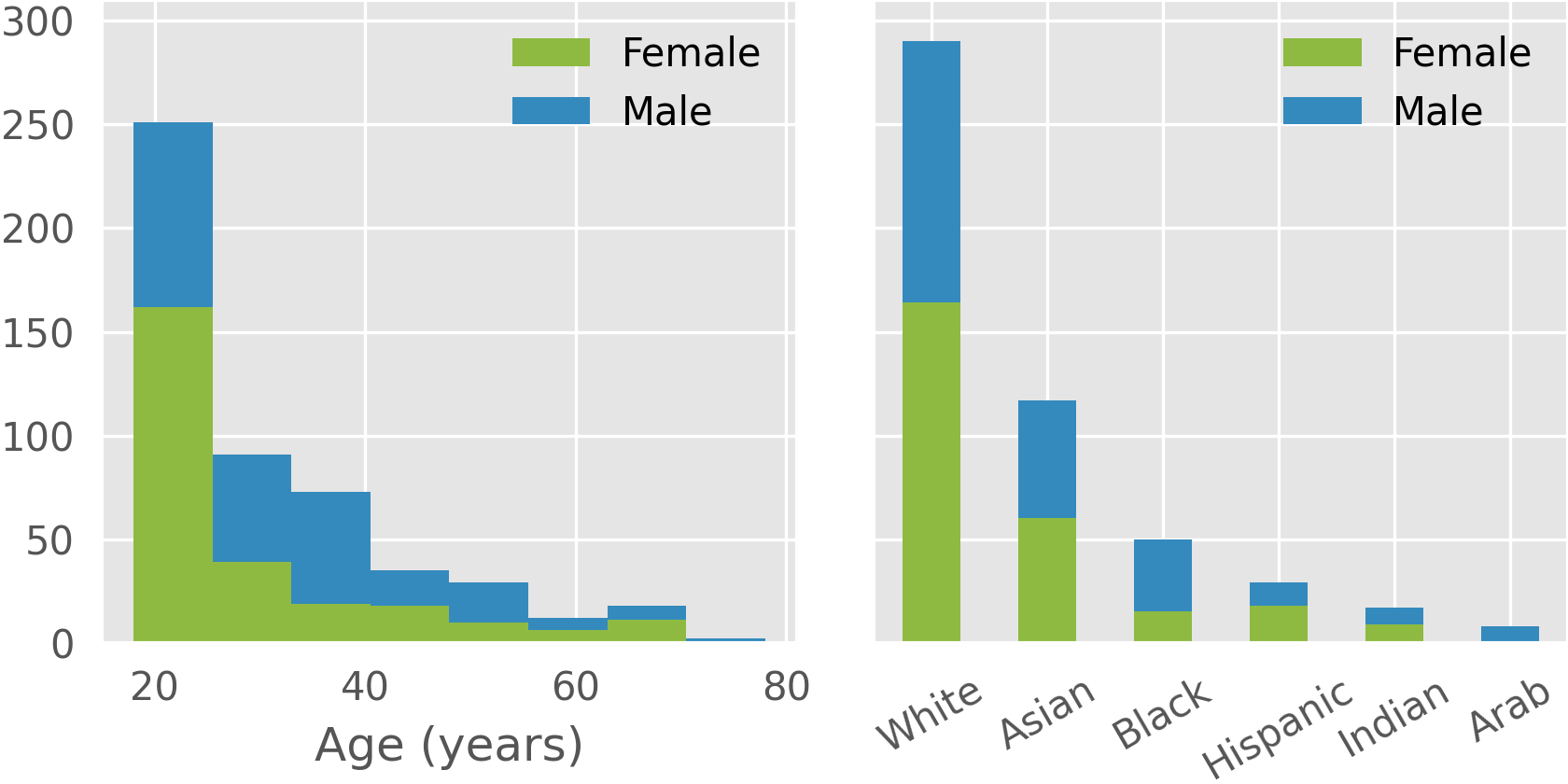
In order to generate diverse synthetic data, our generative models must be trained with diverse source data.
Here are histograms of self-reported age, gender, and ethnicity in our collection of 3D face scans, which was used to build our face model and texture library. Our collection covers a range of age and ethnicity.
@inproceedings{wood2021fake,
title={Fake it till you make it: face analysis in the wild using synthetic data alone},
author={Wood, Erroll and Baltru{\v{s}}aitis, Tadas and Hewitt, Charlie and Dziadzio, Sebastian and Cashman, Thomas J and Shotton, Jamie},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={3681--3691},
year={2021}
}