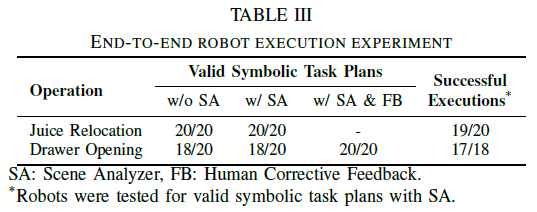
We introduce a pipeline that enhances a general-purpose Vision Language Model, GPT-4V(ision), by integrating observations of human actions to facilitate robotic manipulation. This system analyzes videos of humans performing tasks and creates executable robot programs that incorporate affordance insights. The computation starts by analyzing the videos with GPT-4V to convert environmental and action details into text, followed by a GPT-4-empowered task planner. In the following analyses, vision systems reanalyze the video with the task plan. Object names are grounded using an open-vocabulary object detector, while focus on the hand-object relation helps to detect the moment of grasping and releasing. This spatiotemporal grounding allows the vision systems to further gather affordance data (e.g., grasp type, way points, and body postures). Experiments across various scenarios demonstrate this method's efficacy in achieving real robots' operations from human demonstrations in a zero-shot manner.
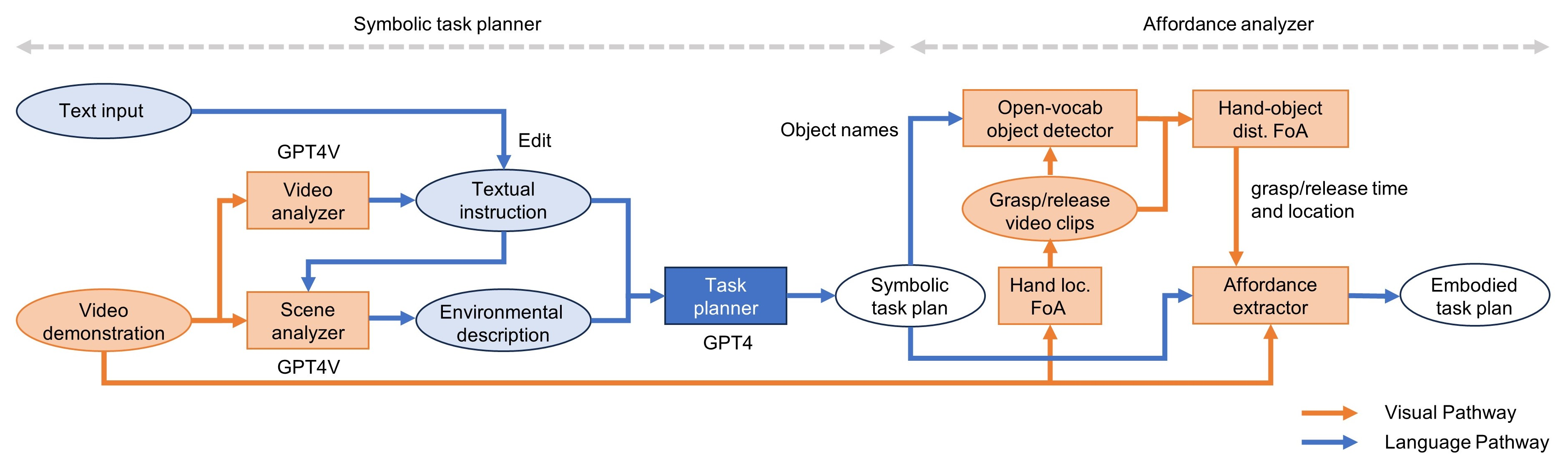
Proposed pipeline of the multimodal task planner. It consists of the symbolic task planner and the affordance analyzer. Blue components/lines are text-based information, and the red components are vision-related information. FoA denotes focus-of-attention.
The below prompt is used to generate a textual instruction from a video of a human performing a task.
These are frames from a video in which a human is doing something. Understand these frames and generate a one-sentence instruction for humans to command these actions to a robot.
As a reference, the necessary and sufficient human actions are defined as follows:
HUMAN ACTION LIST
Grab(arg1): Take hold of arg1.
Preconditions: Arg1 is in a reachable distance. No object is held (i.e., BEING_GRABBED)
Postconditions: Arg1 is held (i.e., BEING_GRABBED).
MoveHand(arg1): Move a robot hand closer to arg1 to allow any actions to arg1. Arg 1 is a description of the hand's destination. For example, "near the table" or "above the box".
Release(arg1): Release arg1.
Preconditions: Arg1 is being held (i.e., BEING_GRABBED).
Postconditions: Arg1 is released (i.e., not BEING_GRABBED).
PickUp(arg1): Lift arg1.
Preconditions: Arg1 is being held (i.e., BEING_GRABBED).
Postconditions: Arg1 is being held (i.e., BEING_GRABBED).
Put(arg1, arg2): Place arg1 on arg2.
Preconditions: Arg1 is being held (i.e., BEING_GRABBED).
Postconditions: Arg1 is being held (i.e., BEING_GRABBED).
Response should be a sentence in a form of human-to-human communication (i.e., do not directly use the functions). Return only one sentence without including your explanation in the response (e.g., Do not include a sentence like "here are the step-by-step instructions").

The below prompt is used to generate a scene description from a video of a human performing a task. The input to GPT-4V is the textual instruction, which is replaced with "[ACTION]" in the prompt, and the first frame of the video.
This is a scene in which a human is doing "[ACTION]". Understand this scene and generate a scenery description to assist in task planning:
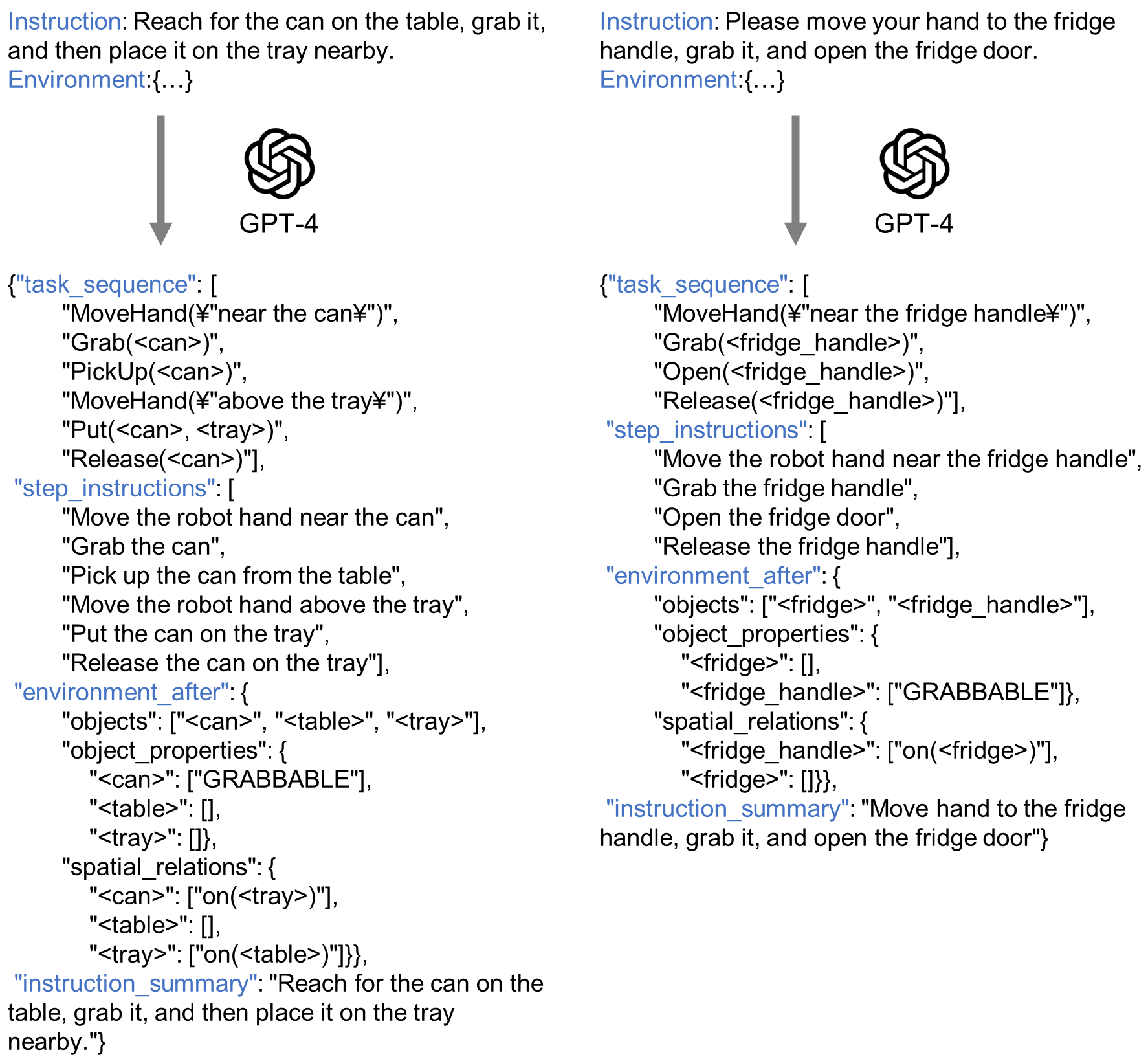
Information about environments is given as python dictionary. For example:
{
"objects": [
"<cup>",
"<office_table>"],
"object_properties": {
"<cup>": ["GRABBABLE"],
"<office_table>":[]},
"spatial_relations": {
"<cup>": ["on(<office_table>)"],
"<office_table>":[]},
"your_explanation": "Human is picking up the cup from the office table and placing it back on the table. I omitted the juice on the table as it is not being manipulated."
}
- The "objects" field denotes the list of objects. Enclose the object names with '<' and '>'. Connect the words without spaces, using underscores instead. Do not include human beings in the object list.
- The "object_properties" field denotes the properties of the objects. Objects have the following properties:
- GRABBABLE: If an object has this attribute, it can be potentially grabbed by the robot.
- The "spatial_relations" field denotes the list of relationships between objects. Use only the following functions to describe these relations: [inside(), on()]. For example, 'on(<office_table>)' indicates that the object is placed on the office table. Ignore any spatial relationships not listed in this list.
Please take note of the following.
1. Focus only on the objects related to the human action and omit object that are not being manipulated or interacted with in this task. Explain what you included and what you omitted and why in the "your_explanation" field.
2. The response should be a Python dictionary only, without any explanatory text (e.g., Do not include a sentence like "here is the environment").
3. Insert "```python" at the beginning and then insert "```" at the end of your response.

We used GPT-4 for task planning. The input to GPT-4 consisted of a set of textual instructions and the scenery information generated by the scene analyzer. The base code and prompt are available at this repository.
After the system comprehends the task sequence, it synchronizes this sequence with the human demonstration by re-analyzing the input video.


Examples of robot execution are presented in sped-up videos. The trajectory of the robot's hand is defined relative to the object's position at the moment of grasping. Consequently, the object's position is reverified during execution, and the trajectory is recalculated based on these coordinates. Arm postures are computed using inverse kinematics, and human poses from the demonstration can also be utilized for multi-degree-of-freedom arms. Several skills, such as the grasp skill, are trained using reinforcement learning.


Robustness to the environment: The system functions even in environments that differ from the teaching environment (e.g., shelves with different textures), as long as similar affordances are present.

Reusability: A task demonstrated by a human can be repeatedly applied to multiple copies of the same object as long as the same affordances are present in the environment.

Those robot executions are repeatable.

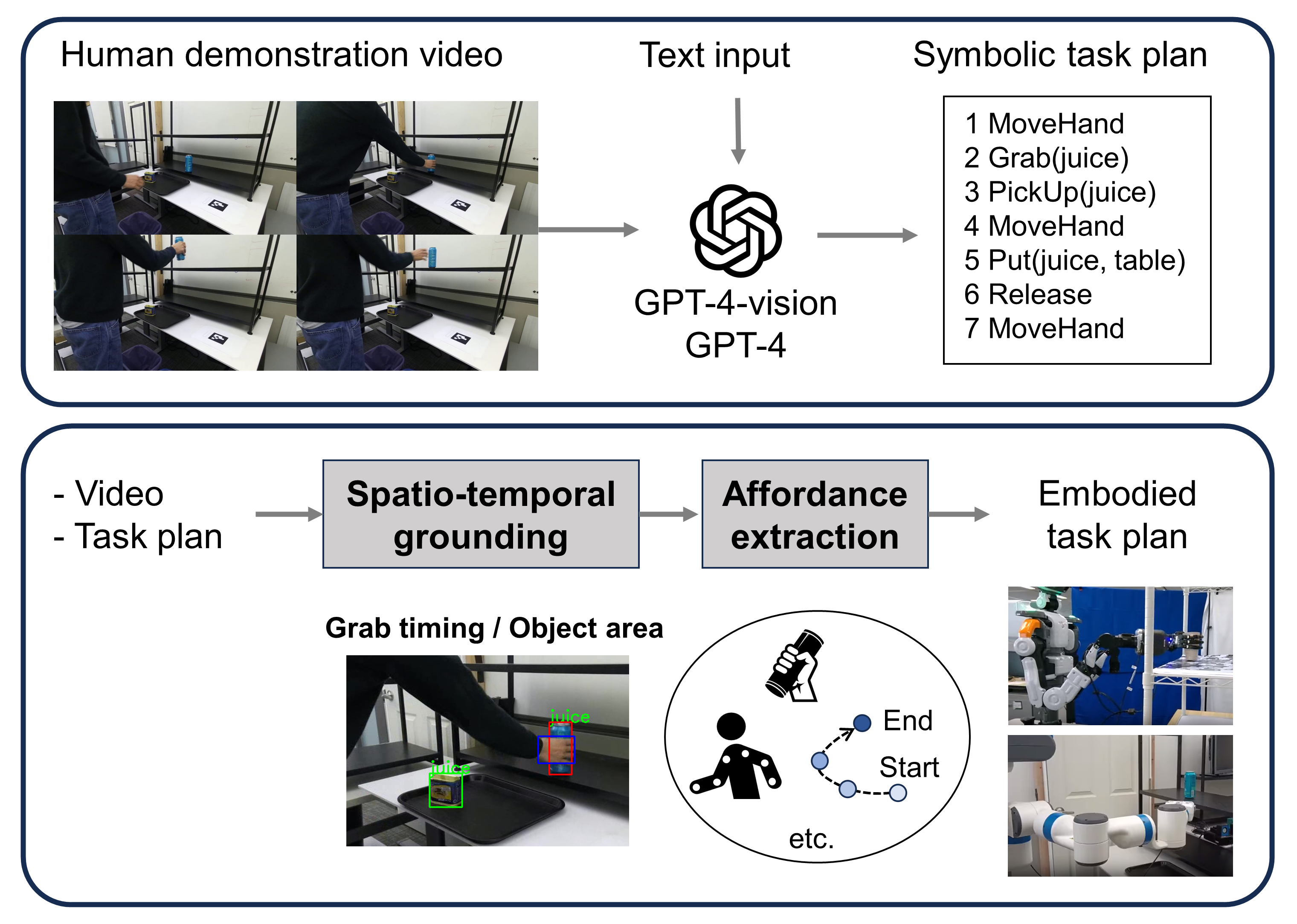
We evaluated the end-to-end success rates of a SEED-noid robot performing various operations based on 20 human demonstrations each. The robot execution system utilized a first-person camera mounted on the robot's head. While the end-to-end performance reached 85-95%, the results highlighted the importance of human feedback in addressing misinterpretations by GPT-4V.