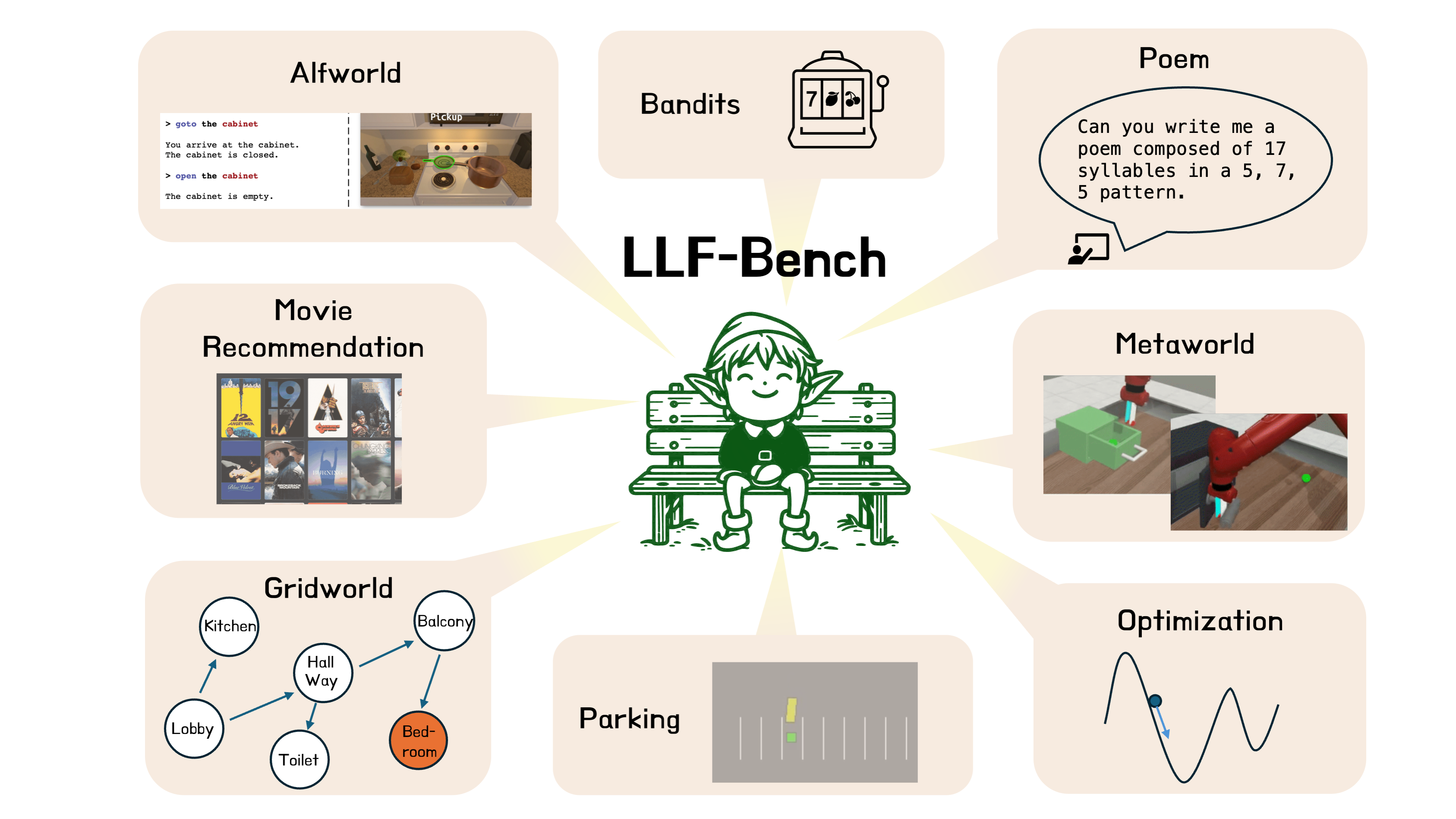
LLF-Bench : Benchmark for Interactive Learning from Language Feedback
LLF-Bench : Benchmark for Interactive Learning from Language Feedback
A diverse collection of 8 learning problems.
LLF-Bench includes diverse environments such as navigation,
user recommendation, robotic manipulation domain, and poem generation.
Robust to Prompt hacking
LLF-Bench generates and randomizes verbalization making it hard for
LLM-based agents to prompt hack to any given environment.
Requires learning
LLF-Bench includes environments that require learning no matter how smart the
LLM, or any other foundation model is. This provides a way to evaluate learning in LLM-based agents.
Interactive learning
LLF-Bench contains environments with which the agent can interact
enabling the study of exploration and learning from feedback. This is in contrast to offline
evaluation benchmarks for LLMs such as MMLU or Big Bench Hard.
What is LLF-Bench? LLF-Bench (Learning from Language Feedback Benchmark; pronounced as “elf bench”), is a new benchmark to evaluate the ability of AI agents to interactively learn from just language feedback. The agent interacts with an environment in LLF-Bench, takes action, and gets language feedback instead of rewards or action. LLF-Bench consists of 8 diverse benchmarks.
# Clone the LLF-bench code
git clone https://github.com/microsoft/LLF-Bench.git
# Optional but recommended: create a conda environment.
conda create -n LLF-Bench python=3.8 -y
conda activate LLF-Bench
# Install LLF Bench
cd LLF-Bench
pip install -e .
# To install Alfworld and Metaworld, we need some more resources. See Github for details.
How is it different from RL? Reinforcement learning (RL) is another commonly studied interactive learning setting. The key difference is that in RL, the agent is trained using rewards, whereas in LLF (the paradigm upon which LLF-Bench) is based, uses language feedback instead of rewards.
Why language feedback? Language feedback has two main advantages over rewards and expert actions (which are the two most commonly used feedbacks). Firstly, unlike rewards, language feedback is very expressive and consequently can pack a lot more information which can help the agent train faster, and unlike actions, language feedback can be more easily provided by non-expert humans. Secondly, language feedback is closer to how humans learn, and this makes it more natural for many settings.
Can LLF-Bench be used to evaluate LLMs? Yes! In fact, that is one of the main purposes behind LLF-Bench -- to robustly evaluate LLM-based Agents. There are two reasons to prefer LLF-Bench for such evaluation: firstly, LLF-Bench provides a diverse set of environments where each environment provides sampled verbalizations of the problem making it harder to prompt hack. Secondly, LLF-Bench includes environments that require learning, so that no matter how good an LLM is, it cannot zero-shot solve those LLF-Bench environments. Therefore, LLF-agents must show signs of learning new information to be able to solve those environments.