Abstract
Simulated humanoids are an appealing research domain due to their physical capabilities. Nonetheless, they are also challenging to control, as a policy must drive an unstable, discontinuous, and high-dimensional physical system. One widely studied approach is to utilize motion capture (MoCap) data to teach the humanoid agent low-level skills (e.g., standing, walking, and running) that can then be re-used to synthesize high-level behaviors. However, even with MoCap data, controlling simulated humanoids remains very hard, as MoCap data offers only kinematic information. Finding physical control inputs to realize the demonstrated motions requires computationally intensive methods like reinforcement learning. Thus, despite the publicly available MoCap data, its utility has been limited to institutions with large-scale compute. In this work, we dramatically lower the barrier for productive research on this topic by training and releasing high-quality agents that can track over three hours of MoCap data for a simulated humanoid in the dm_control physics-based environment. We release MoCapAct (Motion Capture with Actions), a dataset of these expert agents and their rollouts, which contain proprioceptive observations and actions. We demonstrate the utility of MoCapAct by using it to train a single hierarchical policy capable of tracking the entire MoCap dataset within dm_control and show the learned low-level component can be re-used to efficiently learn downstream high-level tasks. Finally, we use MoCapAct to train an autoregressive GPT model and show that it can control a simulated humanoid to perform natural motion completion given a motion prompt.
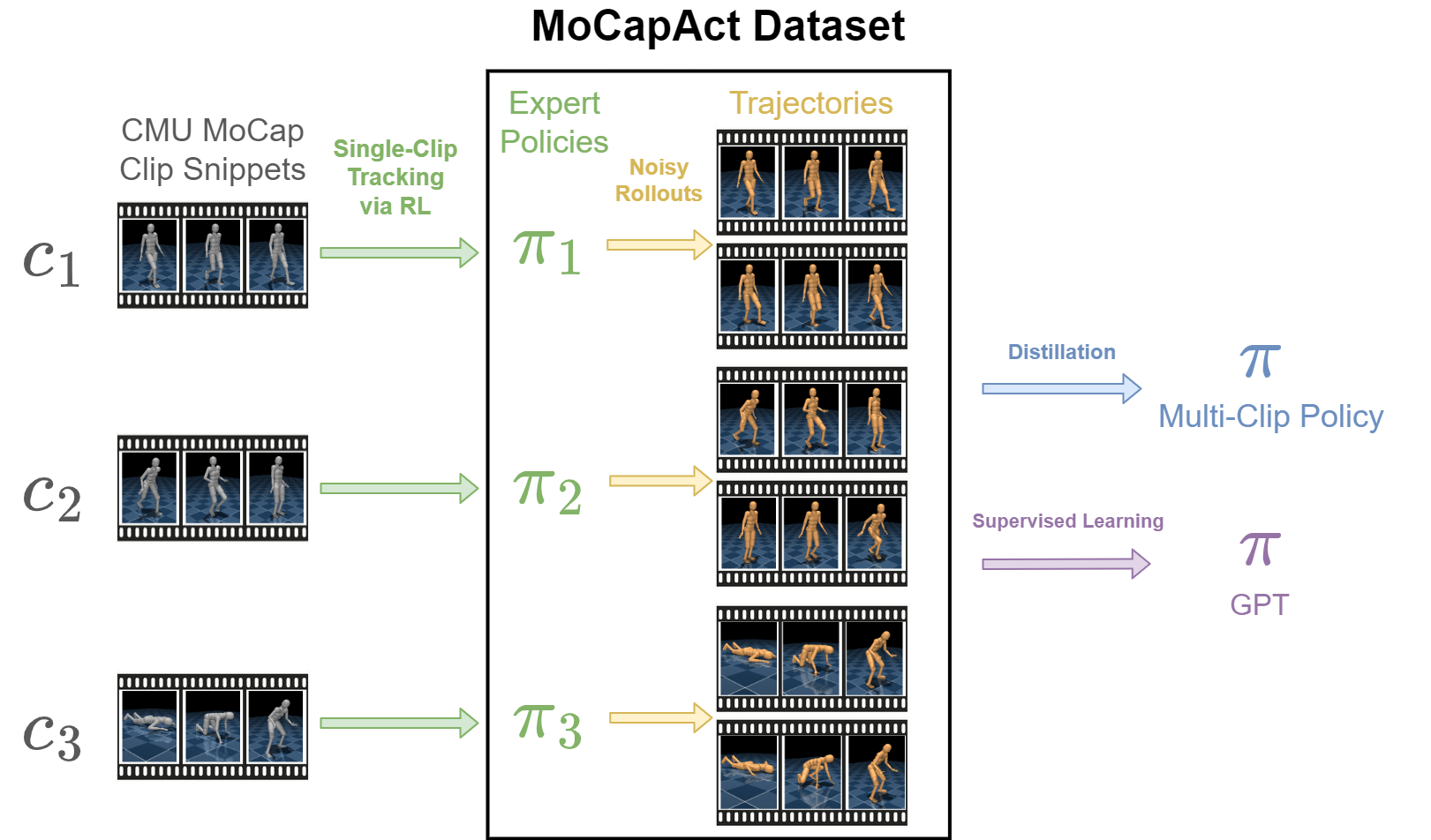
MoCapAct Dataset
The MoCapAct dataset consists of:
- expert policies that are trained to track individual clip snippets and
- HDF5 files of noisy rollouts collected from each expert.
We include zipped rollout datasets of two sizes: a “small” 46 GB dataset with 20 rollouts per snippet and a “large” 559 GB dataset with 200 rollouts per snippet. The HDF5 files can be used to train a multi-clip policy or GPT policy. Please refer to Appendix B of our paper for the structure of the experts and HDF5 files.
Download Instructions
We provide the dataset and models on the MoCapAct collection on Hugging Face. This collection consists of two pages:
- A model zoo which contains the clip snippet experts, multiclip policies, RL-trained policies for the transfer tasks, and the GPT policy.
- A dataset page which contains the small rollout dataset and large rollout dataset.
We also provide example experts and rollouts to allow users to run the upcoming examples and to familiarize with the dataset files before downloading the full dataset. The example experts are located here, and the example rollout data files are located here. For instance, after downloading the example experts, an expert can be loaded using our package:
from mocapact import observables
from mocapact.sb3 import utils
expert_path = "/path/to/example_experts/CMU_083_33/CMU_083_33-0-194/eval_rsi/model"
expert = utils.load_policy(expert_path, observables.TIME_INDEX_OBSERVABLES)
from mocapact.envs import tracking
from dm_control.locomotion.tasks.reference_pose import types
dataset = types.ClipCollection(ids=['CMU_083_33'], start_steps=[0], end_steps=[194])
env = tracking.MocapTrackingGymEnv(dataset)
obs, done = env.reset(), False
while not done:
action, _ = expert.predict(obs, deterministic=True)
obs, rew, done, _ = env.step(action)
print(rew)
After downloading the example small rollouts, the HDF5 rollouts files can be read and utilized in Python:
import h5py
dset = h5py.File("/path/to/example_small_dataset/CMU_083_33.hdf5", "r")
print("Expert actions from first rollout episode:")
print(dset["CMU_083_33-0-194/0/actions"][...])
Clip Snippet Experts
We train an expert policy for each of the 2589 snippets within the MoCap dataset. We find that the experts faithfully reproduce the overwhelming majorty of clips. On clips where the expert deviates from the clip (e.g., bottom right), the expert learns some other behavior to keep the episode from terminating early.
The commands to generate the videos from the example experts are:
python -m mocapact.clip_expert.evaluate \
--policy_root /path/to/example_experts/CMU_016_22/CMU_016_22-0-82/eval_rsi/model \
--act_noise 0 \
--ghost_offset 1 \
--always_init_at_clip_start
# other snippets are CMU_015_04-1036-1217, CMU_038_03-0-208, CMU_049_02-405-575, CMU_049_07-0-127,
# CMU_061_01-172-377, CMU_075_09-0-203, CMU_090_06-0-170
Noisy Rollouts
We generate the dataset by repeatedly rolling out the experts with some injected action noise and recording the observations, actions, rewards, etc. Below are videos showing noisy rollouts for the same clips from the previous section.
For most snippets, the rollouts look very similar. This is because the experts are trained to track the MoCap clips in spite of the injected noise. This helps the learned multi-clip and GPT policies to correct the mistakes they make in a rollout.
The commands to generate the videos from the example experts are:
python -m mocapact.clip_expert.evaluate
--policy_root /path/to/example_experts/CMU_016_22/CMU_016_22-0-82/eval_rsi/model \
--act_noise 0.1 \
--ghost_offset 1 \
--termination_error_threshold 1 \
--always_init_at_clip_start
# other snippets are CMU_015_04-1036-1217, CMU_038_03-0-208, CMU_049_02-405-575, CMU_049_07-0-127,
# CMU_061_01-172-377, CMU_075_09-0-203, CMU_090_06-0-170
Multi-Clip Policy
We then train a multi-clip policy on the dataset to track all the clips in dm_control. On some clips, we find the mutli-clip policy can faithfully track the MoCap clip (including very long segments):
On other clips, the policy can only track the clip for a short time before making a mistake that causes the humanoid to lose balance and fall over:
To generate the videos, first download and unzip multiclip_policy.tar.gz from the dataset.
Then, run:
python -m mocapact.distillation.evaluate \
--policy_path /path/to/multiclip_policy/full_dataset/model/model.ckpt \
--act_noise 0 \
--ghost_offset 1 \
--always_init_at_clip_start \
--termination_error_threshold 10 \
--clip_snippets CMU_016_22
# other clips are CMU_015_04, CMU_038_03, CMU_049_07, CMU_061_01-172, CMU_069_56, CMU_075_09
Task Transfer
We can re-use the low-level component of the mutli-clip policy to aid in learning new humanoid tasks.
In a go-to-target task with a sparse reward, we find that including a low-level policy is needed to solve the task. The low-level policy introduces natural gaits, whereas not using a low-level policy produces unstable contorting behavior.
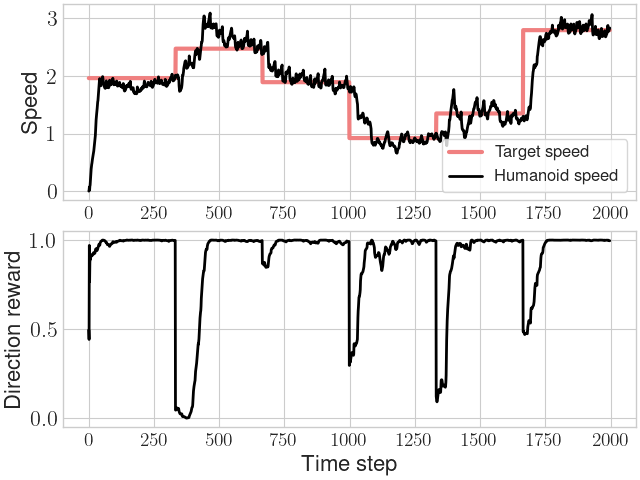
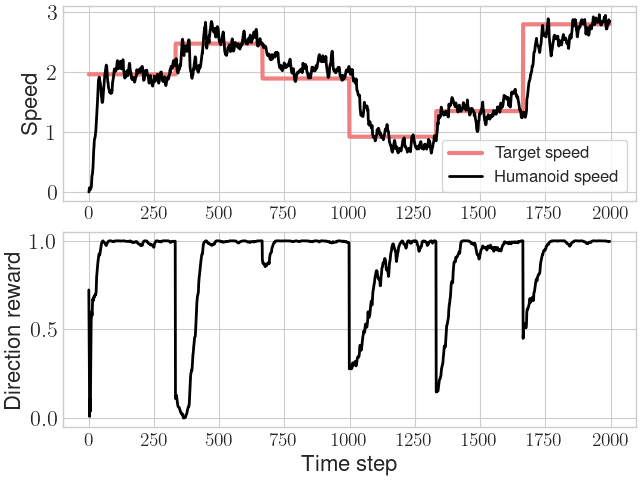
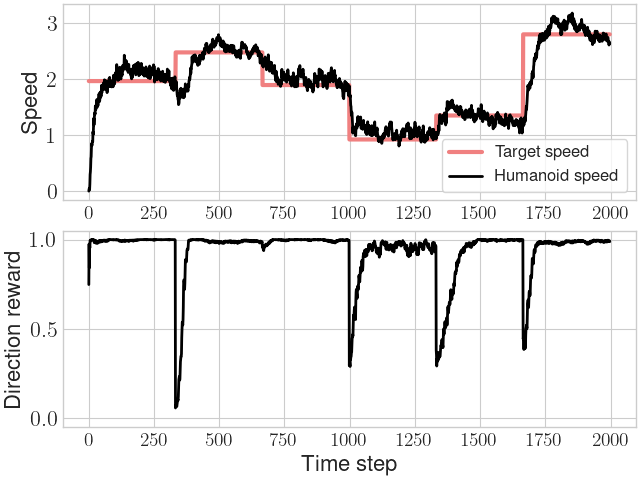
In a velocity control task, we similarly find a low-level policy produces natural gaits, whereas not using a low-level policy causes the agent to learn idiosyncratic behavior.
 |
 |
 |
To generate the videos, first download and unzip transfer.tar.gz from the dataset.
Then, (for the general low-level policy) run:
python -m mocapact.transfer.evaluate \
--model_root /path/to/transfer/go_to_target/general_low_level \
--task /path/to/mocapact/transfer/config.py:go_to_target
python -m mocapact.transfer.evaluate \
--model_root /path/to/transfer/velocity_control/general_low_level \
--task /path/to/mocapact/transfer/config.py:velocity_control \
--task.config.steps_before_changing_velocity 333 \
--big_arena \
--episode_steps 2000
Motion Completion
Inspired by sentence completion from NLP, we train a GPT policy to perform motion completion. The policy takes as input the past 32 observations from the humanoid (the “context”) and outputs the action to be applied. As with the previous sections, the humanoid is initialized at some time step in a MoCap clip. The first 32 observations (the “prompt”) are then generated by rolling out the corresponding expert policy for 32 time steps. In the videos, the prompt is shown by a red humanoid. From there, the GPT policy controls the humanoid (visualized in bronze).
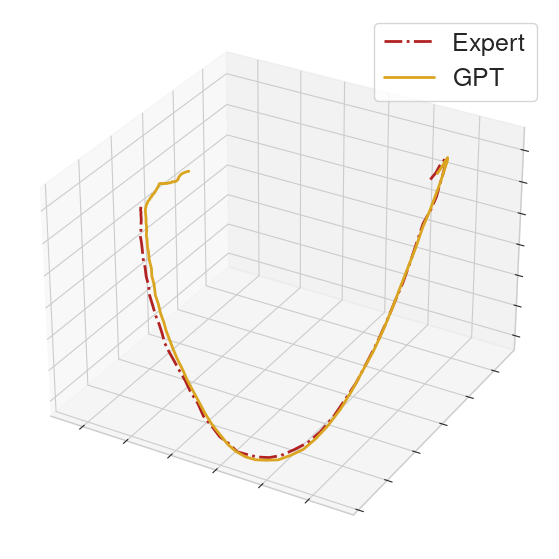
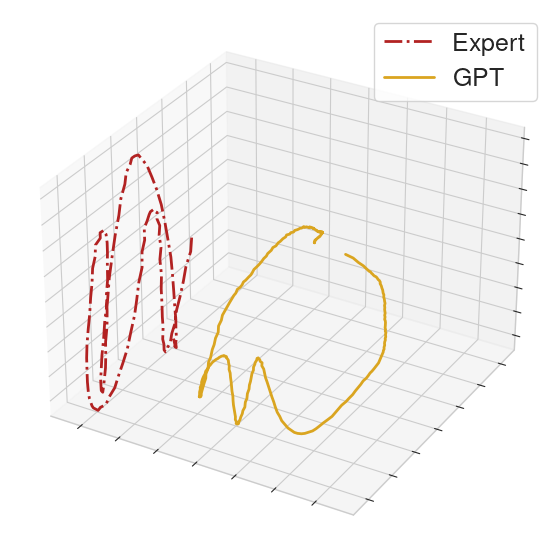
To help compare the behavior between GPT and the MoCap clip, we collect the actions executed in a rollout from each of the GPT policy and an expert policy. From the collected actions, we form action sequences of length 32 for each of the GPT policy and the expert. We then perform PCA on these sequences and provide 3-dimensional visualizations.
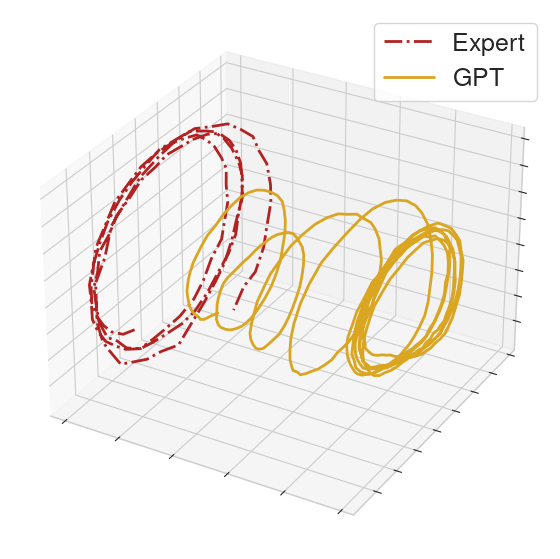
On many locomotion clips, the GPT policy will produce limit cycles that match the MoCap behavior.
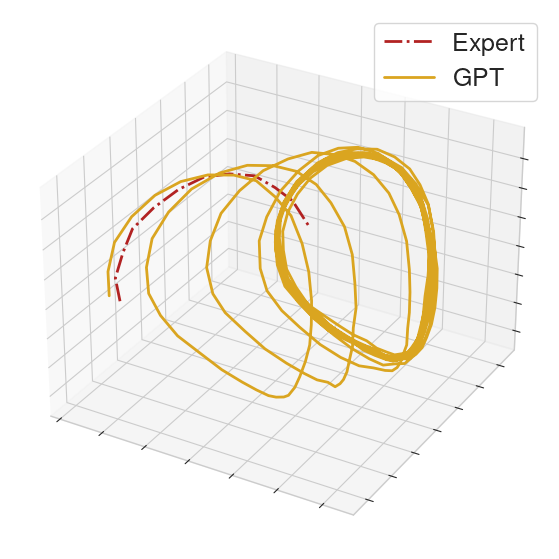 |
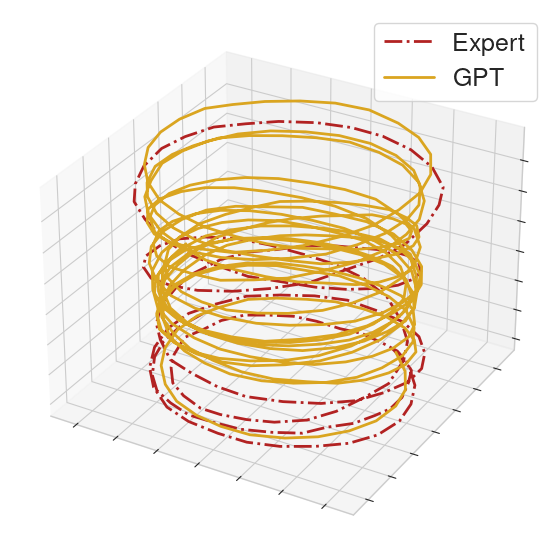 |
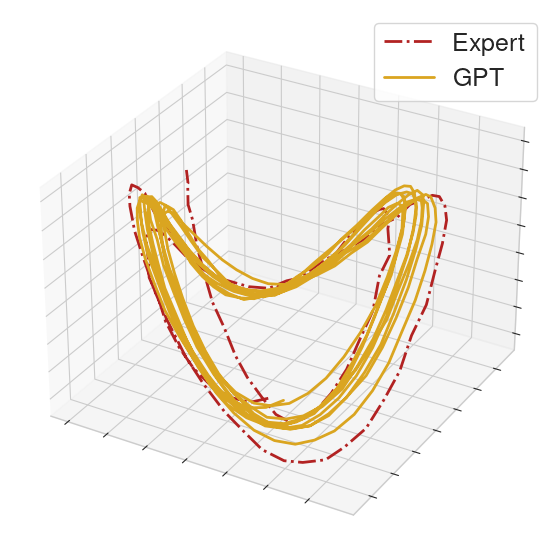 |
On some clips, the GPT policy produces noticeably different behavior from the MoCap clip. This typically happens if the context gives ambiguous information.
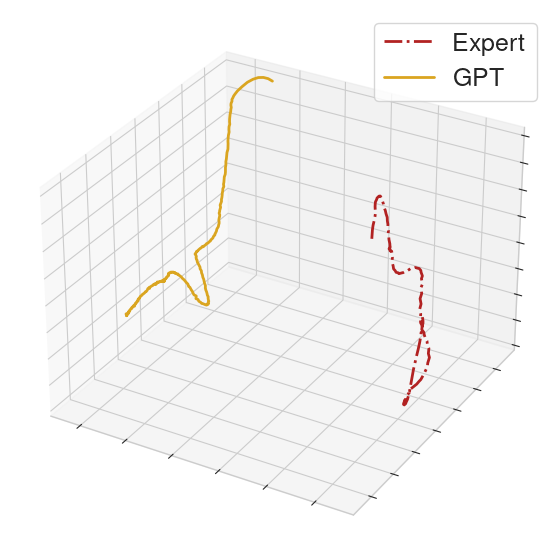 |
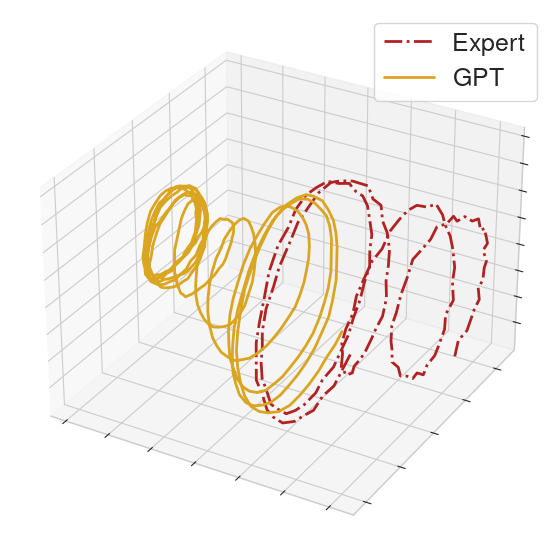 |
On some clips of very unique behavior, the GPT can reproduce the snippet. After the end of the snippet, the policy makes a mistake and causes the humanoid to fall over.
 |
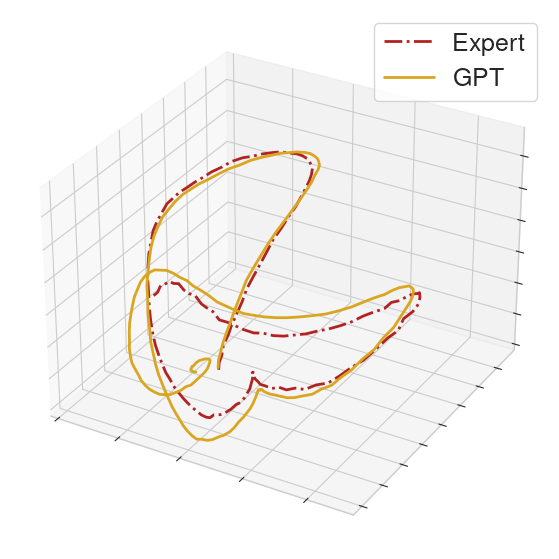 |
We rolled out the GPT policy on a held-out set of clips to assess how well it generalizes to unseen prompts. On some of these clips, the policy can competently control the humanoid. In the left video, we see behavior that resembles the MoCap clip, though the PCA projections imply the executed actions of the expert and GPT can be distinguished. In the other two videos, the policy produces very different behavior than the underlying clip.
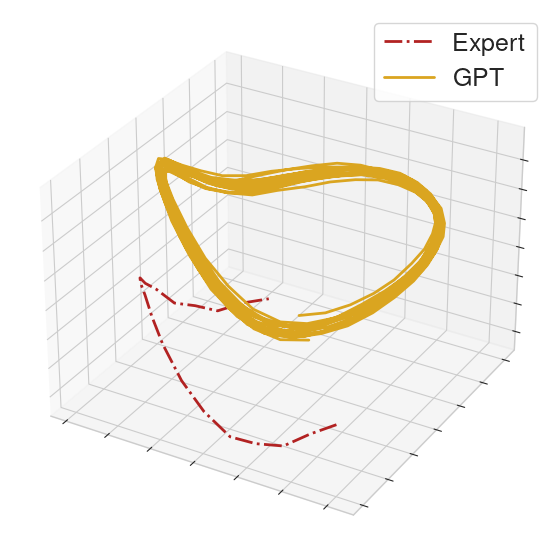 |
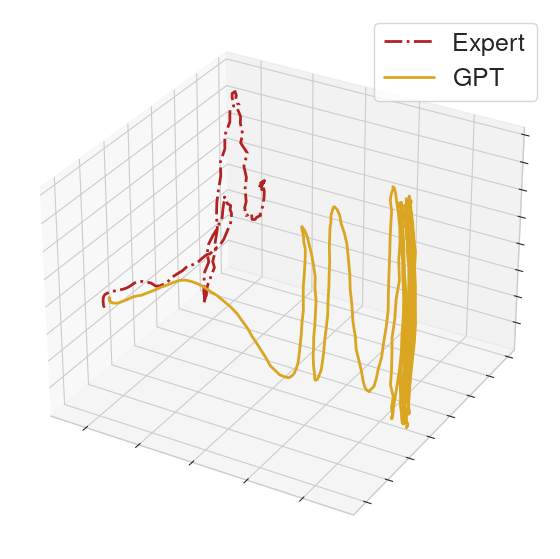 |
 |
On other held-out clips, the policy fails shortly after the prompt, highlighting that our GPT policy does not generalize perfectly.
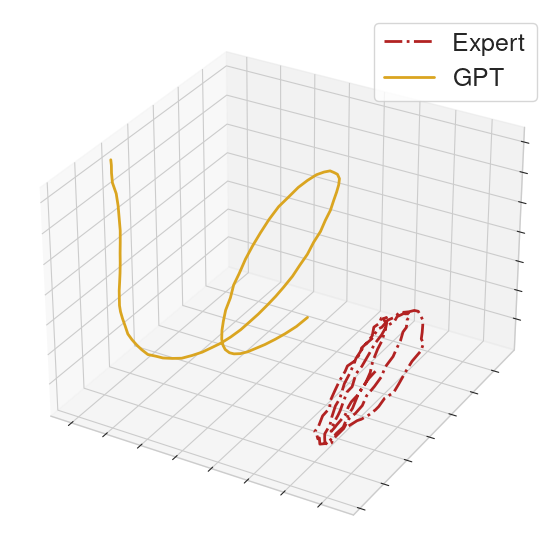 |
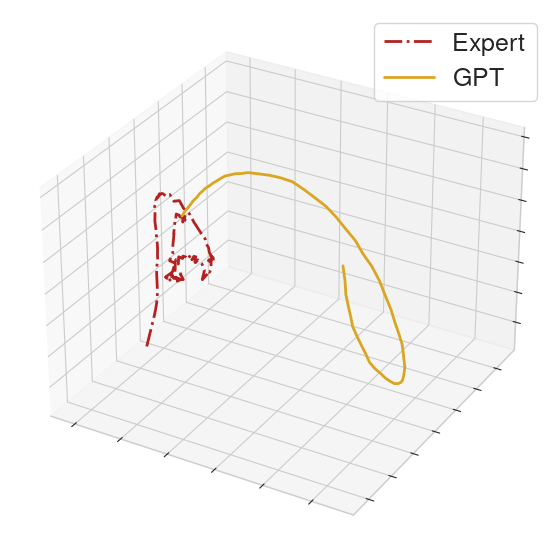 |
 |
To generate the videos, first download gpt.ckpt from the dataset and the example experts.
Then, run:
python -m mocapact.distillation.motion_completion.py \
--policy_path /path/to/gpt.ckpt \
--nodeterministic \
--ghost_offset 1 \
--expert_root /path/to/example_experts/CMU_016_25 \
--max_steps 500 \
--always_init_at_clip_start \
--prompt_length 32 \
--min_steps 32 \
--device cuda \
--clip_snippet CMU_016_25
# other clips are CMU_008_02, CMU_015_04-1332-1513, CMU_015_05-948-1139, CMU_038_03,
# CMU_041_04, CMU_049_06, CMU_056_06-0-201, CMU_061_01-172-377, CMU_069_12,
# CMU_069_21, CMU_069_42-0-206, CMU_069_46
Citation
If you reference or use MoCapAct in your research, please cite:
@inproceedings{wagener2022mocapact,
title="{MoCapAct}: A Multi-Task Dataset for Simulated Humanoid Control",
author={Wagener, Nolan and Kolobov, Andrey and Frujeri, Felipe Vieira and Loynd, Ricky and Cheng, Ching-An and Hausknecht, Matthew},
booktitle={Advances in Neural Information Processing Systems},
volume={35},
pages={35418--35431},
year={2022}
}