Overview#
What is Olive?#
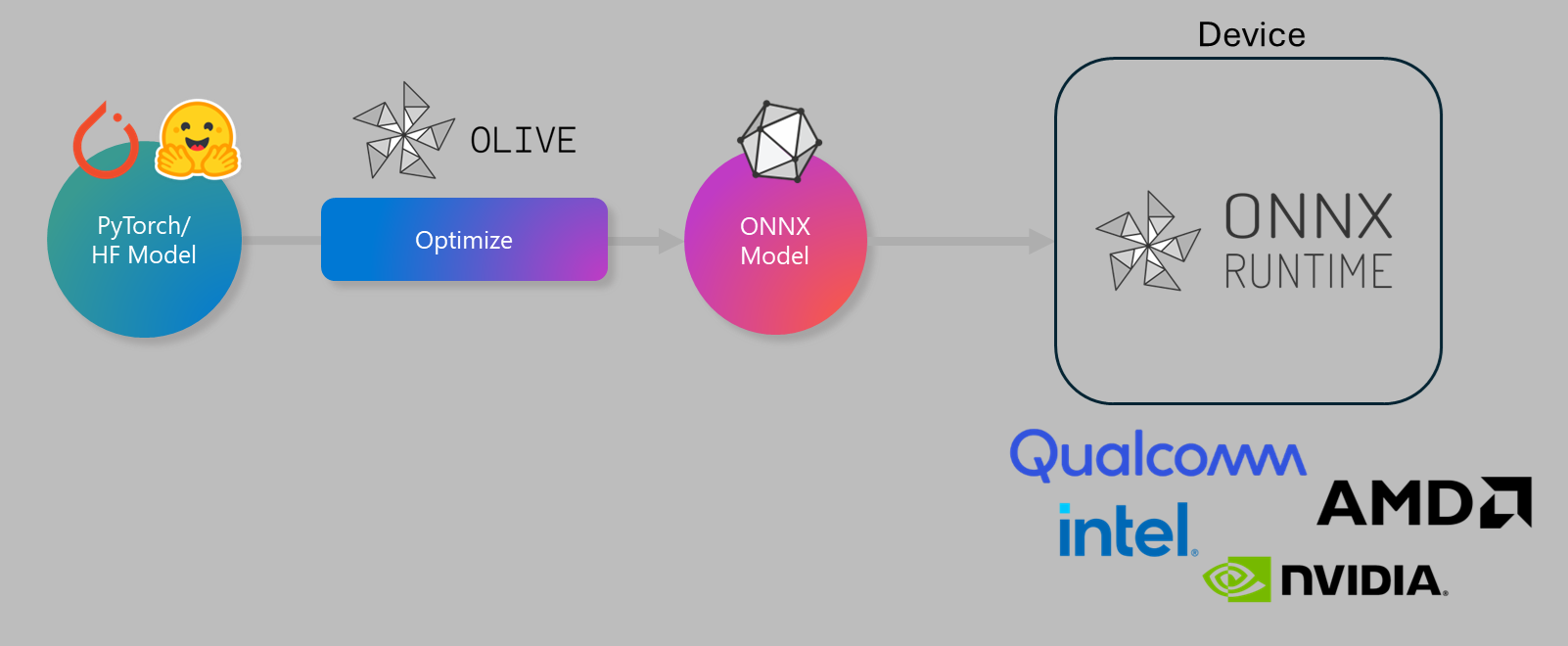
Olive (ONNX LIVE) is a cutting-edge model optimization toolkit with an accompanying CLI that enables you to ship models for the ONNX runtime with quality and performance.
The input to Olive is typically a PyTorch or Hugging Face model, and the output is an optimized ONNX model that is executed on a device (deployment target) running the ONNX runtime. Olive will optimize the model for the deployment target’s AI accelerator (NPU, GPU, CPU) provided by a hardware vendor such as Qualcomm, AMD, Nvidia, or Intel.
Olive executes a workflow, which is an ordered sequence of individual model optimization tasks called passes - example passes include model compression, graph capture, quantization, and graph optimization. Each pass has a set of parameters that can be tuned to achieve the best metrics, such as accuracy and latency, that are evaluated by the respective evaluator. Olive employs a search strategy that uses a search sampler to auto-tune each pass individually or a set of passes together.
Benefits of using Olive#
Reduce frustration and time of trial-and-error manual experimentation with different techniques for graph optimization, compression, and quantization. Define your target and precision and let Olive automatically produce the best model for you.
40+ built-in model optimization components covering cutting-edge techniques in quantization, compression, graph optimization, and finetuning.
Easy-to-use CLI for common model optimization tasks. For example, olive quantize, olive auto-opt, olive finetune. Advanced users can easily construct workflows using YAML/JSON to orchestrate model transformations and optimizations steps.
Model packaging and deployment built-in.
Enables Multi LoRA serving.
Hugging Face and Azure AI Integration.
Built-in caching mechanism to improve team’s productivity.