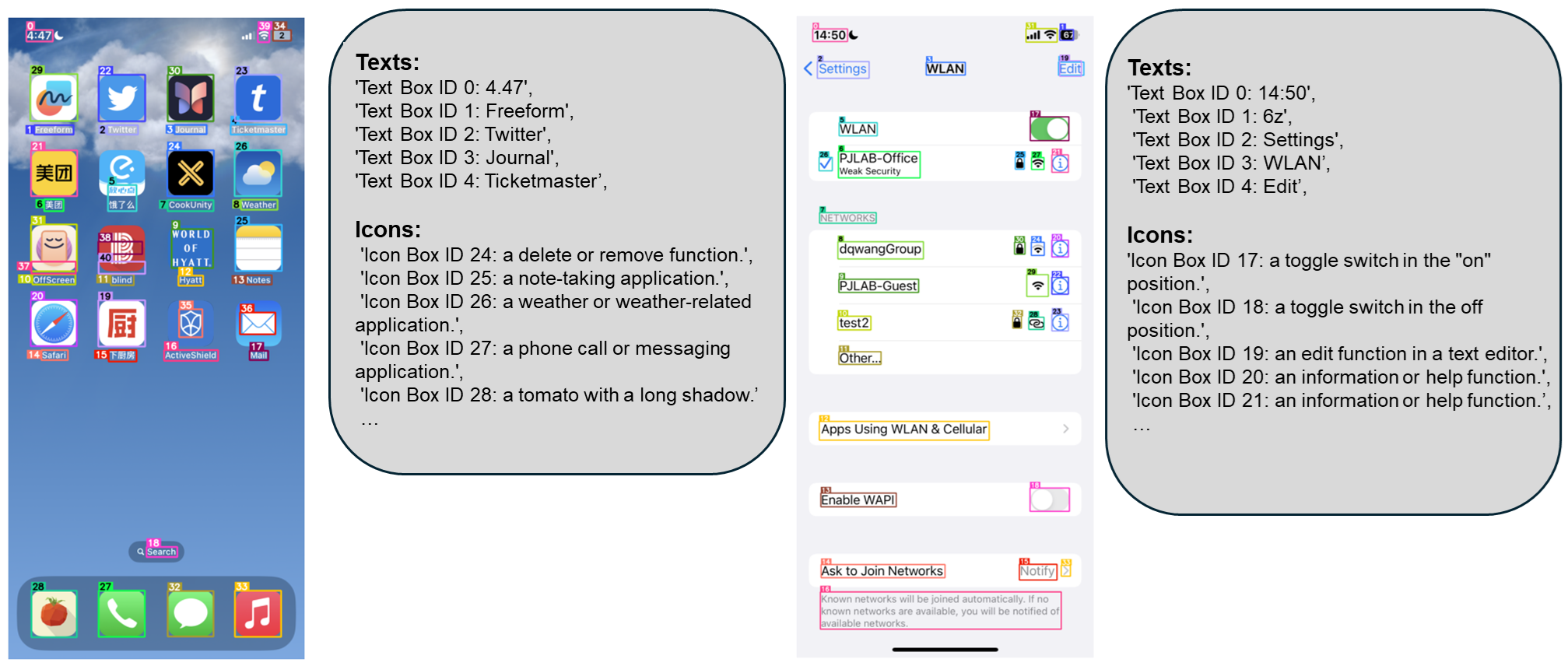
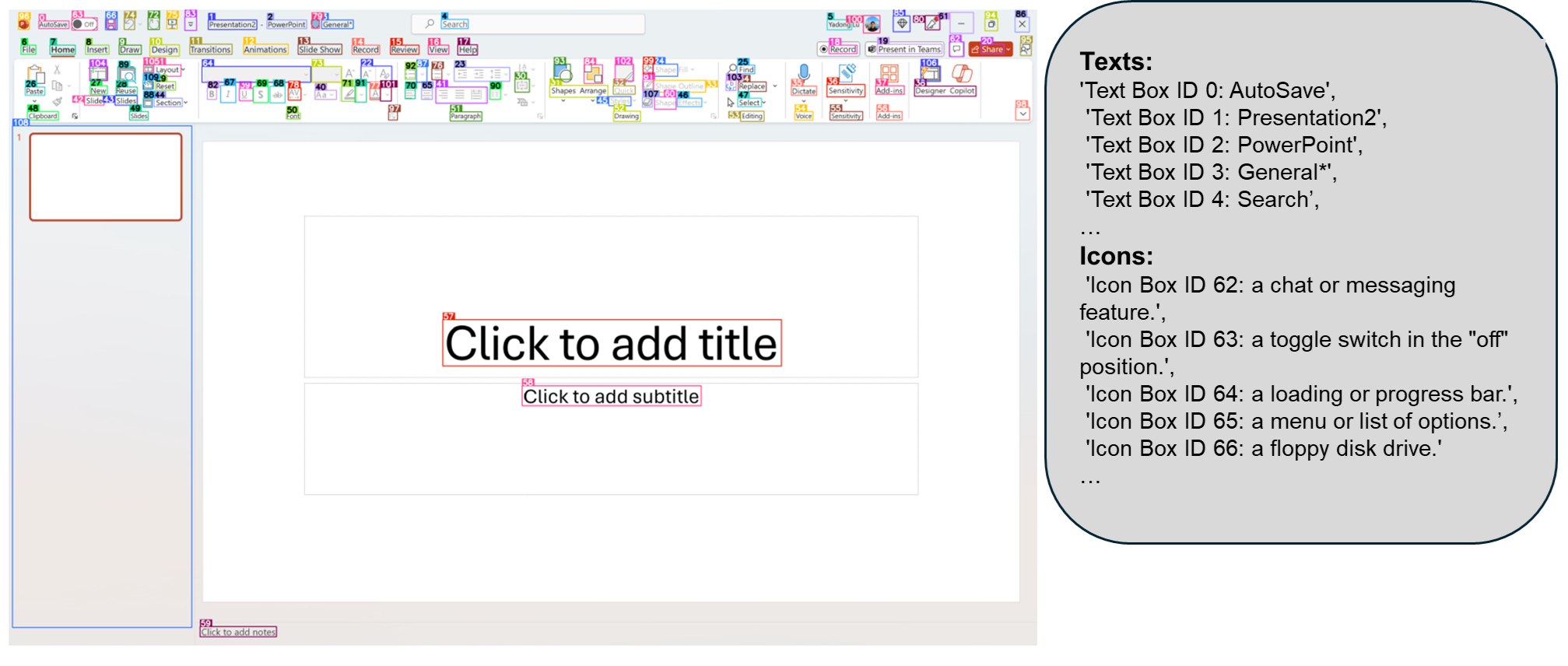
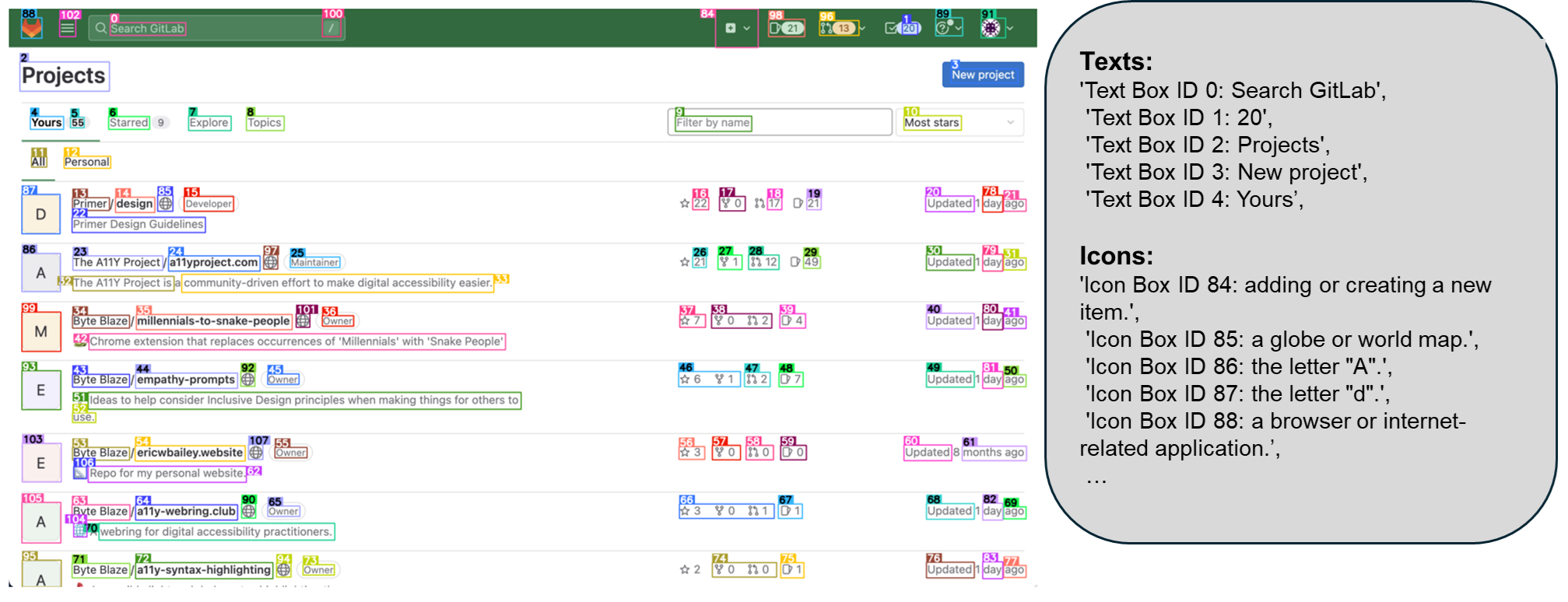
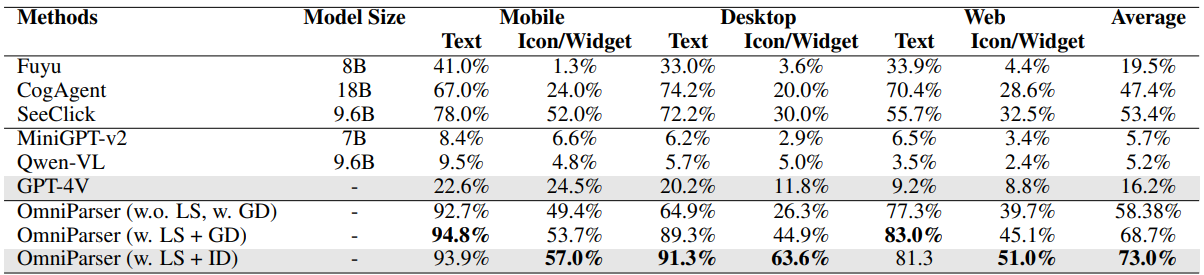
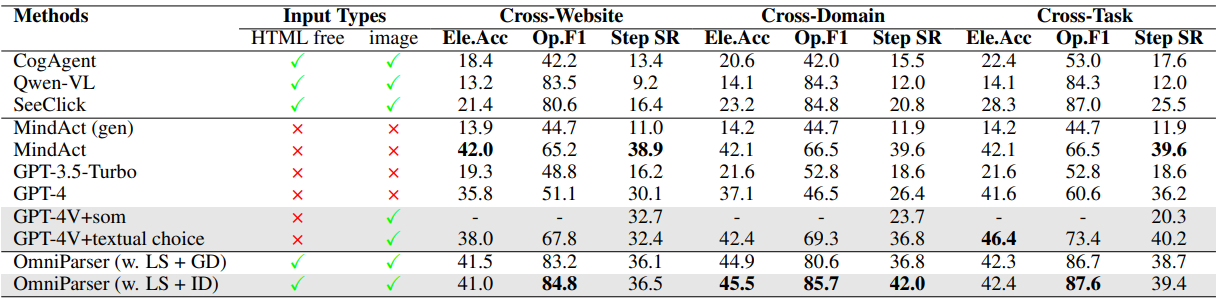
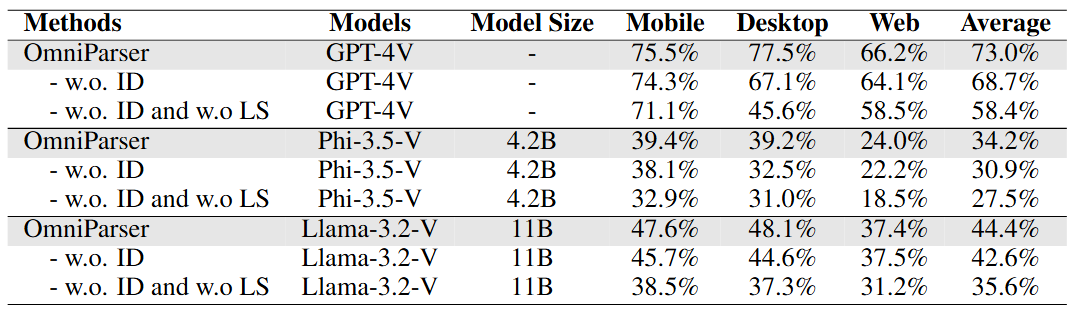
The recent success of large vision language models shows great potential in driving the agent system operating on user interfaces. However, we argue that the power multimodal models like GPT-4V as a general agent on multiple operating systems across different applications is largely underestimated due to the lack of a robust screen parsing technique capable of: 1. reliably identifying interactable icons within the user interface, and 2. understanding the semantics of various elements in a screenshot and accurately associate the intended action with the corresponding region on the screen. To fill these gaps, we introduce OMNIPARSER, a comprehensive method for parsing user interface screenshots into structured elements, which significantly enhances the ability of GPT-4V to generate actions that can be accurately grounded in the corresponding regions of the interface. We first curated an interactable icon detection dataset using popular webpages and an icon description dataset. These datasets were utilized to fine-tune specialized models: a detection model to parse interactable regions on the screen and a caption model to extract the functional semantics of the detected elements. OMNIPARSER significantly improves GPT-4V's performance on ScreenSpot benchmark. And on Mind2Web and AITW benchmark, OMNIPARSER with screenshot only input outperforms the GPT-4V baselines requiring additional information outside of screenshot
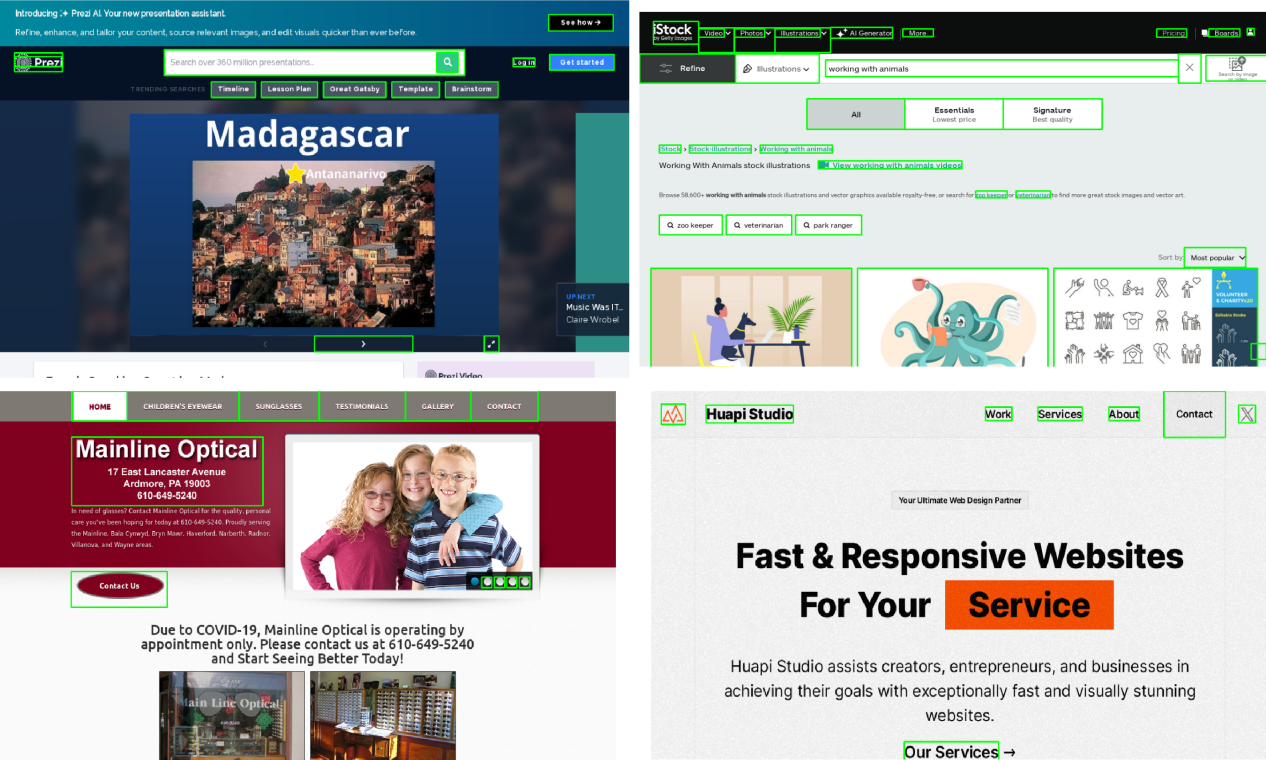
Examples from the Interactable Region Detection dataset. . TThe bounding boxes are based on the interactable region extracted from the DOM tree of the webpage.

@misc{lu2024omniparserpurevisionbased,
title={OmniParser for Pure Vision Based GUI Agent},
author={Yadong Lu and Jianwei Yang and Yelong Shen and Ahmed Awadallah},
year={2024},
eprint={2408.00203},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.00203},
}