PLEX and the available robotic manipulation training data
Data-driven methods for producing robotic manipulation policies have the potential to be effective and scalable, replacing manually engineered controllers. At the same time, recent trends in natural language processing have shown that transformers trained on large amounts of data can exhibit impressive capabilities. In an effort to combine these trends, we introduce PLEX, a scalable transformer-based architecture that can take advantage of several forms of data practically available in quantity and relevant to robotic manipulation. In particular, we consider three common classes of data available for training robotic manipulation models:
-
Multi-task video demonstrations (MTVD), which contain high-quality and potentially annotated demonstrations for a variety of tasks, but have no explicit action information for a robot to mimic
-
Visuomotor trajectories (VMT), which consist of paired sequences of observations and robots’ actions, but do not necessarily correspond to meaningful tasks
-
Target-task demonstrations (TTD), which are high-quality trajectories for a specific task of interest, collected using the robot of interest
Note that the more widely available data tends to be less informative (e.g. videos), while the most informative data (e.g. target demonstrations) is the scarcest.
Method
Our PLanning-EXecution (PLEX) architecture separates the model into a planner, which predicts the future observations (in a latent space), and an executor, which predicts the actions needed to effect those future observations:
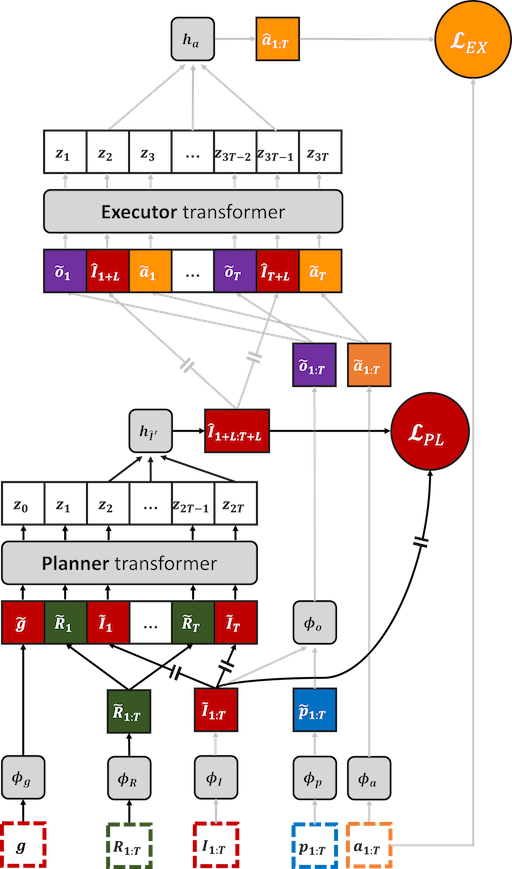
This separation makes PLEX especially amenable to training on the aforementioned data categories. The executor along with the image observation encoder is pretrained on the VMT data, the planner is pretrained on the MTVD data, and the entire PLEX architecture is then finetuned on TTD trajectories.
Experiments

Pretraining. We investigate the performance of PLEX on the Meta-World benchmark by training PLEX on videos from 45 pretraining tasks of Meta-World’s ML50 split and finetuning it on each of ML50’s 5 other tasks:
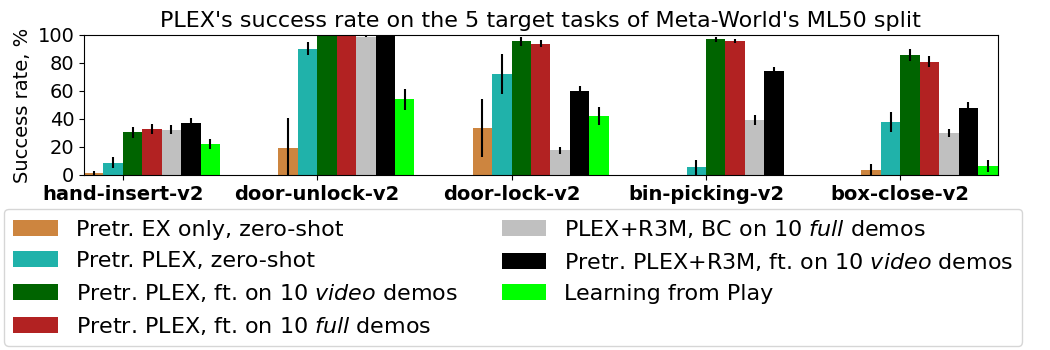
Interestingly, PLEX works fairly well even zero-shot, and needs only videos of the target task demonstrations.
Relative vs. absolute position encoding. One distinguishing feature of PLEX compared to most other transformer-based architectures is its use of relative rather than absolute position encoding. To assess the effectiveness of this design choice, we train PLEX in BC mode from scratch on 9 tasks of the Robosuite/Robomimic benchmark. The results demonstrate that the version with relative position encoding outperforms PLEX with absolute encoding as well as the vanilla Decision Transformer, which relies on the global position encoding scheme:
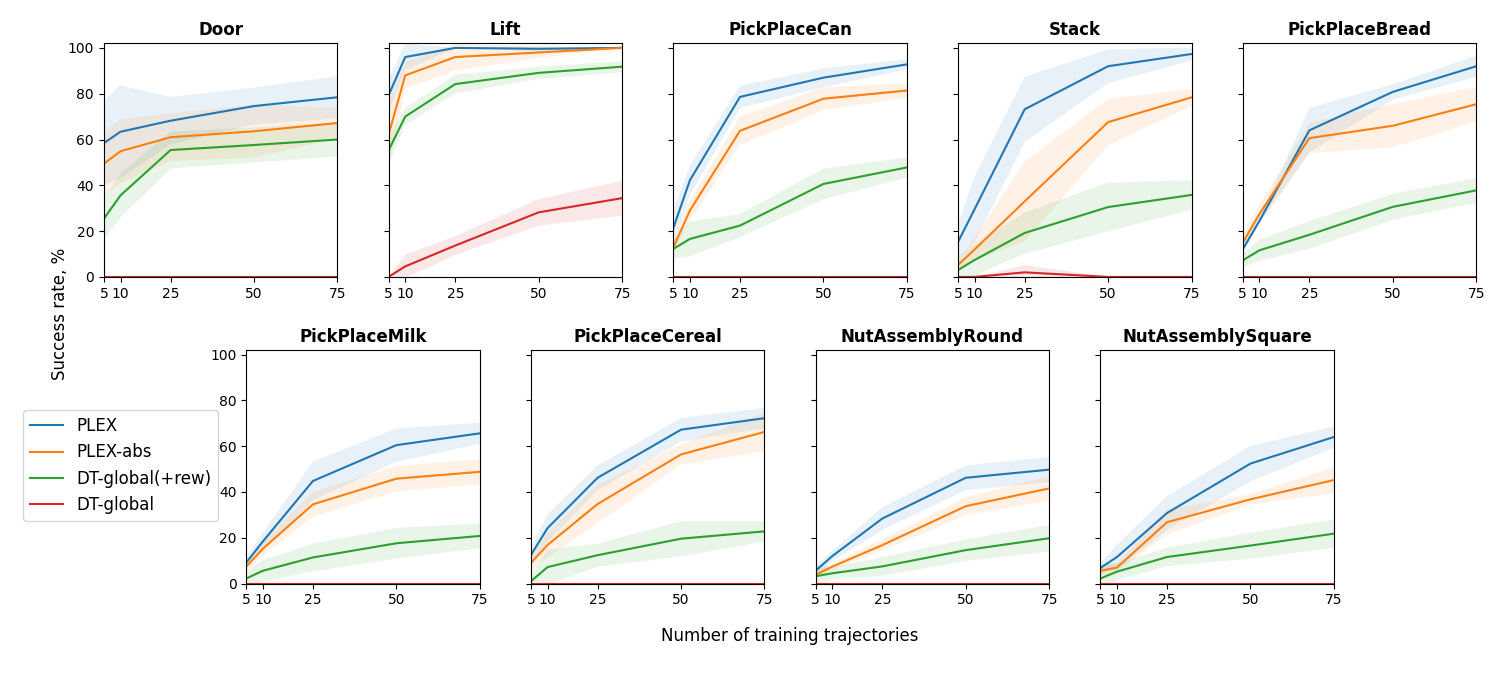
NOTE on the Robosuite dataset: For the Robosuite experiments, we gathered a dataset of high-qualty demonstration trajectories for Robosuite’s Door, Stack, PickPlaceMilk, PickPlaceBread, PickPlaceCereal, and NutAssemblyRound tasks, 75 demonstrations per each. The dataset is available from the Microsoft Download Center, and instructions for processing it can be found here.
Citation
@inproceedings{thomas2023plex,
title={PLEX: Making the Most of the Available Data for Robotic Manipulation Pretraining},
author={Garrett Thomas and Ching-An Cheng and Ricky Loynd and Felipe Vieira Frujeri and Vibhav Vineet and Mihai Jalobeanu and Andrey Kolobov},
booktitle={CoRL},
year={2023}
}