VibeVoice: A Frontier Open-Source Text-to-Speech Model
📄 Report · Code · 🤗 Hugging Face
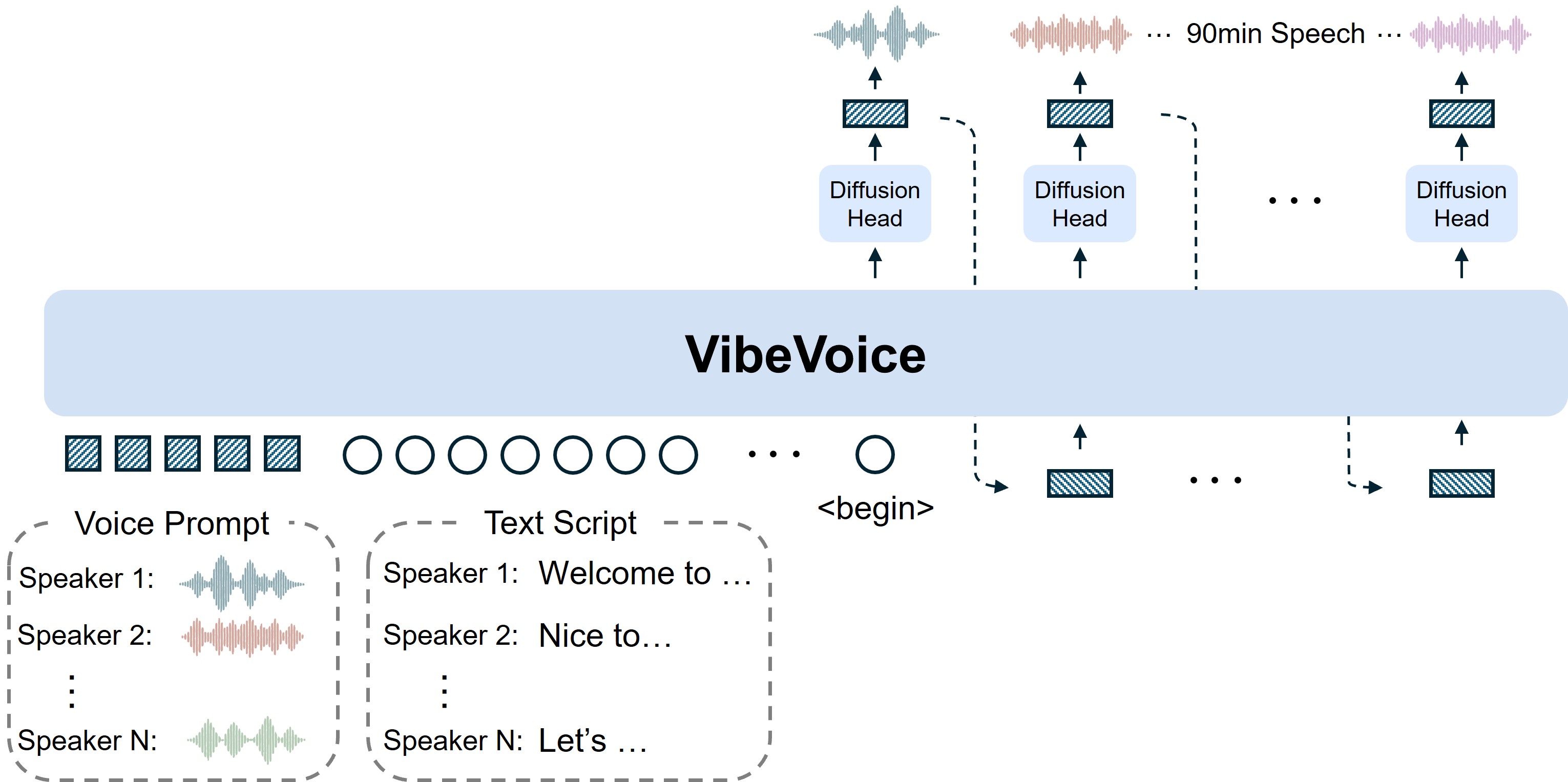
VibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio, such as podcasts, from text. It addresses significant challenges in traditional Text-to-Speech (TTS) systems, particularly in scalability, speaker consistency, and natural turn-taking. A core innovation of VibeVoice is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz. These tokenizers efficiently preserve audio fidelity while significantly boosting computational efficiency for processing long sequences. VibeVoice employs a next-token diffusion framework, leveraging a Large Language Model (LLM) to understand textual context and dialogue flow, and a diffusion head to generate high-fidelity acoustic details. The model can synthesize speech up to 90 minutes long with up to 4 distinct speakers, surpassing the typical 1-2 speaker limits of many prior models.
2025-09-05: VibeVoice is an open-source research framework intended to advance collaboration in the speech synthesis community. After release, we discovered instances where the tool was used in ways inconsistent with the stated intent. Since responsible use of AI is one of Microsoft’s guiding principles, we have disabled the repo until we are confident that out-of-scope use is no longer possible.
Context-Aware Expression
Spontaneous Emotion
Spontaneous Singing
Podcast with Background Music
Cross-Lingual
Mandarin to English
English to Mandarin
Long Conversational Speech
* Timestamps are derived from the generated audio and may contain errors.