Challenge 01 - Building Out the Bronze
< Previous Challenge - Home - Next Challenge >
Introduction
The overall goal of this hackathon is to take data from 2 different data sources and combine them into consolidated tables so that the business user(s) consuming this data do not realize that it originated from different data sets
We will use the AdventureWorksLT and WideWorldImporters SQL databases for our source data.
For this hackathon you will use Azure Synapse and/or Azure Databricks to copy data from these source systems and format them appropriately for business user consumption by utilizing a three-tiered data architecture.
Description
We are now ready to setup the environment and populate the data into the Bronze Data Layer. For this challenge, we want to bring in the data “as is”. No data transformation is needed at this layer.
-
Environmental Setup
We need to set up the proper environment for the Hackathon. Thus, we need everyone on the team to have access to the Azure Synapse and Databricks environments. Also, any ancillary resources such as Power BI, the Azure Storage Accounts and Key Vault.It would be a good idea for each team to host the solution in a new Resource Group in a subscription that all particpants have access to. Thus, at least one person should be owner of the Resource Group and then provide the rest of the team the proper access to that Resource Group. For more informaton on this topic, see the Learning Resources below.
This way each person in the team can take turns to lead the hack and just in case one person has to drop, the rest of the team can still progress through the challenges.
-
Hydration of Data in the Bronze Data Lake
For this challenge we will be working with two SQL data sets:- AdventureWorks
- WideWorldImporters
You will not setup the source databases for this challenge, they are setup and configured already. Your coaches will provide the connection details for these data sources for you to utilize.
The goal is not to import all data from these databases, just choose to only bring in either the Customer or Sales Order data. There is no need to do both.
HINT: Customers have addresses and Sales Orders have header, detail and product associated with them. Both have their own complexities, so one is not easier than the other. See the graphic below for reference.
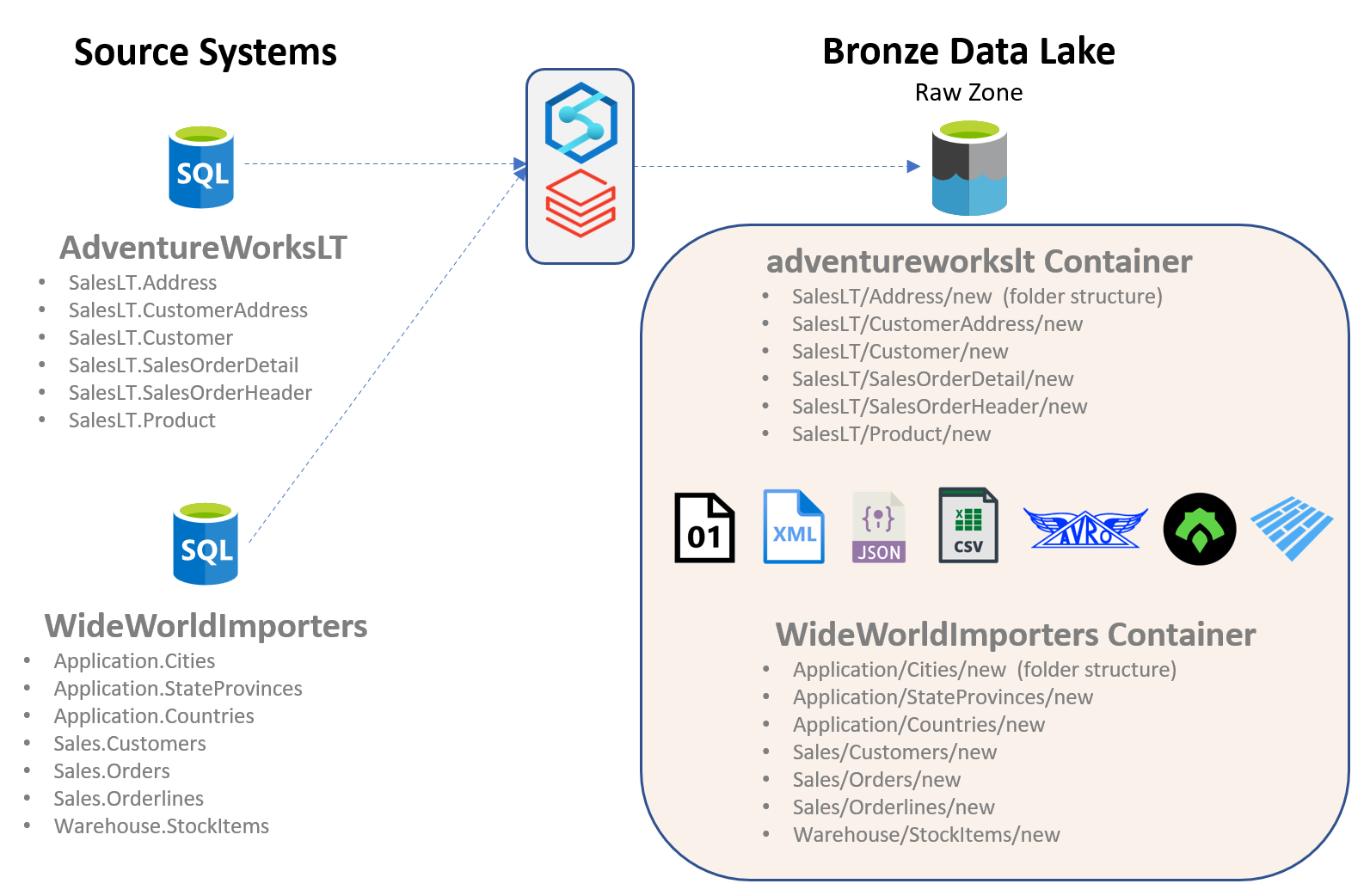
Things to keep in mind about data in the Bronze layer:
- Organized by Source
Have a look at the above diagram to get an idea of what your storage organization would be like. - Data Landed in Native Format
In an effort to load data as-is, we often keep the data format in the Raw Layer the same as it is in the source. This means our Raw Layer often has CSV and TXTs, depending on the type of source.
That being said, if we manage to bring in the data in Parquet format instead, that would be an added bonus. - Additional Checks
- Schema Validated
- Lake Hierarchy Applied
- Timeliness Assessed
- Elements Tagged
- Completeness and Accuracy Accepted
Business Case
Now that we know what we need to do, it’s also important to understand why we are doing this.
From an organizational standpoint, the Bronze layer serves two main purposes:
- Long Term Storage and Recovery
Organizations often need a place to dump huge amounts of structured and unstructured data for processing and Azure Data Lake Storage is often the cheapest and most efficient way to do say. The Raw layer is designed in a way to effectively act as a sink for further processing as well as a store for data for however long it is required. This can act as a backup for other systems as well. - Auditability
Since we don’t do much in terms of additional processing on the data we bring into the Raw layer, the data is unfiltered and unpurified, which is a good thing in terms of auditability. This raw data is always immutable and can act as a reference of what the source system looked like at a given point in time. We usually keep the data in its native format, but this holds true even if we decide to store it in a more modern data format.
Even though the Bronze layer is generally locked down in most organizations, some teams are often given access to it to do some quick discovery work. This is often the case with Data Science teams working on prototyping a new solution.
Success Criteria
To complete this challenge successfully, you should be able to:
- Validate that all resources exist in one Resource Group and are tagged appropriately.
- Validate that all team members have proper access to all the assets: Storage Accounts, Synapse and Databricks Workspaces, etc.
- Showcase the data copied into the Bronze layer and be able to articulate the file type and folder structure and the reasons for your choices.
- Showcase that no credentials are stored in an Azure Synapse Linked Service or a Databricks Notebook.
Learning Resources
The following links may be useful to achieving the success criteria listed above.
- RBAC - Azure built-in roles
- Azure Synapse access control
- Use Azure Key Vault secrets in pipeline activities
- Databricks - Manage Users
- Access Azure Blob Storage using Azure Databricks and Azure Key Vault
- Azure Databricks - Secret Scopes
Bonus Challenge
- Implement incremental pipeline functionality to only receive newly inserted, updated or deleted records from the source system and specify the tables needed to copy so as to only run one master pipeline for all source tables per database. For more on this topic check out Incrementally load data from multiple tables in SQL Server to a database in Azure SQL Database using the Azure portal.