Large Language Model (LLM)
A large language model (LLM) is a type of AI that can process and produce natural language text. It learns from a massive amount of text data such as books, articles, and web pages to discover patterns and rules of language from them.
How large is an LLM?
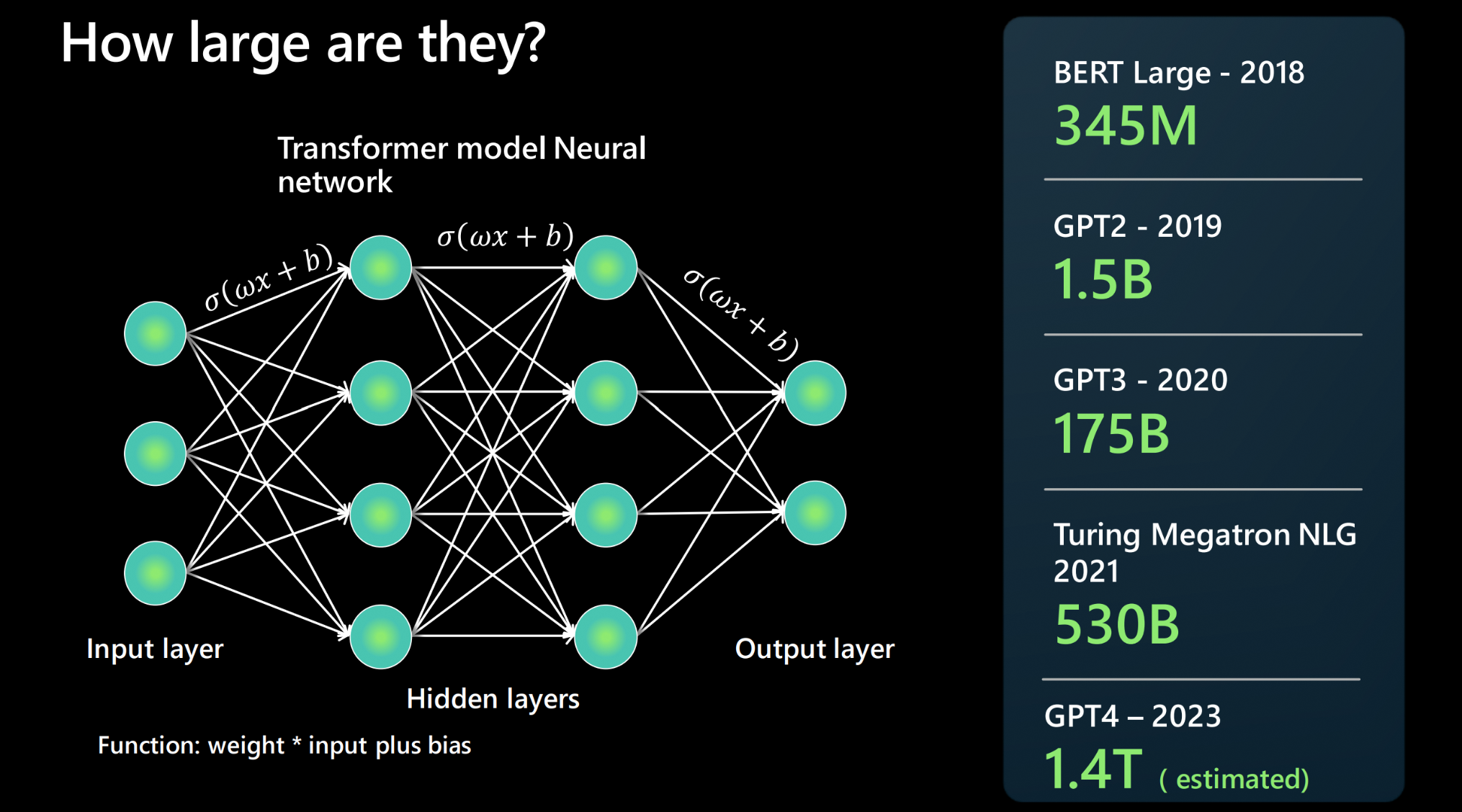
An LLM is built using a neural network architecture. It takes an input, has a number of hidden layers that break down different aspects of language, and then an output layer. People often report how the next foundational model is bigger than the last - what does this mean? The more parameters a model has, the more data it can process, learn from, and generate.
For each connection between two neurons of the neural network architecture, there is a function: weight * input + bias. These produce numerical values that determine how the model processes language. They are rather large - reporting millions of parameters in 2018 to trillions of parameters calculated in 2023 (by GPT4).
What are "Foundational Models"?
A foundation model refers to a specific instance or version of an LLM, such as GPT-3, GPT-4 or Codex, that has been trained and fine-tuned on a large corpus of text or code (in the case of the Codex model). It takes in training data in all different formats and uses a transformer architecture to build a general model. From there adaptions and specializations can be created to achieve certain tasks via prompting or fine-tuning.
How does LLM differ from NLP?
How does a Large Language model differ from traditional Natural Language Processing (NLP) solutions? The table below provides some measures for comparison.
| Traditional NLP | Large Language Models |
|---|---|
| Needs one model per capability. | Reuse single model for many NLP use cases |
| Model trained on a finite set of labelled data | Foundation model trained on many TBs of unlabelled data |
| Highly optimized for specific use case | Open-ended usage - use natural language to "prompt" the model to do something |
What doesn't a LLM do?
While large language models drive rich and powerful generative AI experiences, it's important to remember that the LLM:
- Does NOT Understand language. It's just a predictive engine. Based on text patterns it has previously seen, it can predict completions for the given text input. It does not understand the context or meaning of that content - e,g, it does not understand math.
- Does NOT Understand facts. There are no separate 'modes' for information retrieval vs. creative writing. The model just predicts the next most probable token in the ongoing sequence.
- Does NOT Understand manners, emotion or ethics. Don't anthropomorphize LLMs by attributing human characteristics to them, or claiming they "understand" something. The output is simply the outcome of training data guided by the given prompts.