ai-agents-for-beginners
Използване на агентни протоколи (MCP, A2A и NLWeb)

(Кликнете върху изображението по-горе, за да гледате видеото на този урок)
С нарастването на използването на AI агенти расте и нуждата от протоколи, които гарантират стандартизация, сигурност и подкрепят отворени иновации. В този урок ще разгледаме 3 протокола, които се стремят да отговорят на тази нужда - Model Context Protocol (MCP), Agent to Agent (A2A) и Natural Language Web (NLWeb).
Въведение
В този урок ще разгледаме:
• Как MCP позволява на AI агенти да осъществяват достъп до външни инструменти и данни, за да изпълняват задачи на потребителя.
• Как A2A дава възможност за комуникация и сътрудничество между различни AI агенти.
• Как NLWeb въвежда интерфейси на естествен език за всеки уебсайт, позволявайки на AI агенти да откриват и взаимодействат със съдържанието.
Цели на обучението
• Идентифицирайте основната цел и предимствата на MCP, A2A и NLWeb в контекста на AI агентите.
• Обяснете как всеки протокол улеснява комуникацията и взаимодействието между LLMs, инструменти и други агенти.
• Разпознайте различните роли, които всеки протокол играе при изграждането на сложни агентни системи.
Протокол за контекст на модела
The Model Context Protocol (MCP) е отворен стандарт, който предоставя стандартизиран начин за приложения да предоставят контекст и инструменти на LLMs. Това позволява “универсален адаптер” към различни източници на данни и инструменти, към които AI агенти могат да се свързват по последователен начин.
Нека разгледаме компонентите на MCP, предимствата в сравнение с директното използване на API и пример за това как AI агенти биха могли да използват MCP сървър.
Основни компоненти на MCP
MCP работи на клиент-сървърна архитектура и основните компоненти са:
• Хостове са приложения за LLM (например редактор на код като VSCode), които стартират връзките към MCP сървър.
• Клиенти са компоненти в рамките на хост приложението, които поддържат едно към едно връзки със сървърите.
• Сървъри са леки програми, които предоставят конкретни възможности.
В протокола са включени три основни примитива, които представляват възможностите на един MCP сървър:
• Инструменти: Това са отделни действия или функции, които AI агент може да извика, за да извърши действие. Например, услуга за времето може да предостави инструмент “get weather”, или e-commerce сървър може да предостави инструмент “purchase product”. MCP сървърите рекламират името на всеки инструмент, описание и входно/изходна схема в списъка с възможности.
• Ресурси: Това са само за четене елементи от данни или документи, които MCP сървър може да предостави и които клиентите могат да извличат при поискване. Примери са съдържание на файлове, записи от бази данни или лог файлове. Ресурсите могат да бъдат текстови (като код или JSON) или бинарни (като изображения или PDF).
• Подсказки: Това са предварително дефинирани шаблони, които предоставят предложени подсказки и позволяват по-сложни работни потоци.
Предимства на MCP
MCP предлага значителни предимства за AI агенти:
• Динамично откриване на инструменти: Агентите могат динамично да получат списък с налични инструменти от сървър заедно с описания на това какво правят. Това се различава от традиционните API-та, които често изискват статично кодиране за интеграции, което означава, че всяка промяна на API изисква обновяване на кода. MCP предлага подход “интегрирай веднъж”, което води до по-голяма адаптивност.
• Интероперативност между LLMs: MCP работи с различни LLMs, предоставяйки гъвкавост при смяна на основните модели за по-добра производителност.
• Стандартизирана сигурност: MCP включва стандартен метод за автентикация, подобрявайки скалируемостта при добавяне на достъп до допълнителни MCP сървъри. Това е по-просто от управлението на различни ключове и типове автентикация за различни традиционни API-та.
Пример за MCP
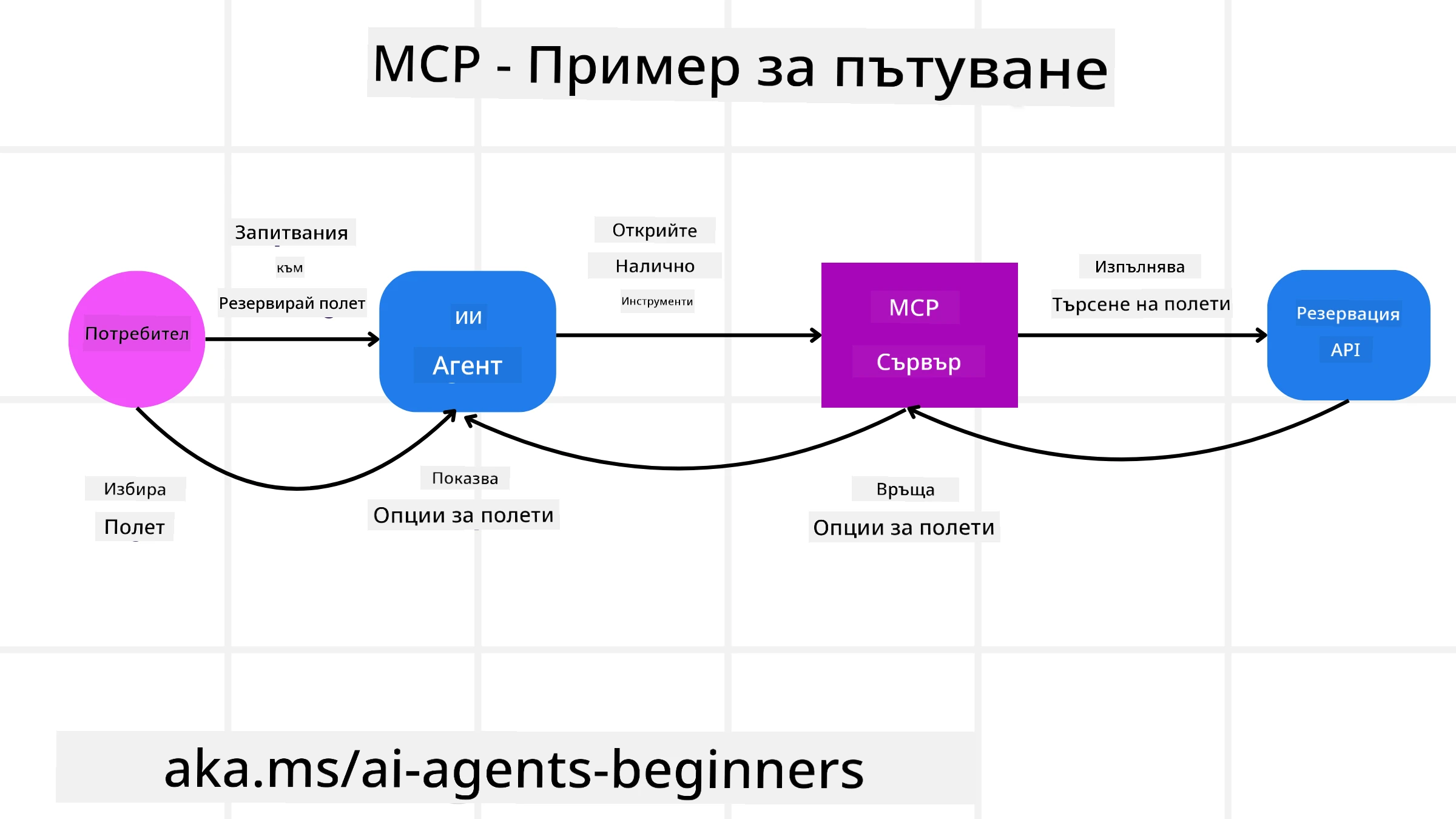
Представете си, че потребител иска да резервира полет, използвайки AI асистент, захранван от MCP.
-
Връзка: AI асистентът (MCP клиентът) се свързва към MCP сървър, предоставен от авиокомпанията.
-
Откриване на инструменти: Клиентът пита MCP сървъра на авиокомпанията: “Какви инструменти имате налични?” Сървърът отговаря с инструменти като “search flights” и “book flights”.
-
Извикване на инструмент: Тогава питате AI асистента: “Моля, потърси полет от Портланд до Хонолулу.” AI асистентът, използвайки своя LLM, определя, че трябва да извика инструмента “search flights” и предава съответните параметри (изход, дестинация) на MCP сървъра.
-
Изпълнение и отговор: MCP сървърът, действащ като обвивка, прави реалното повикване към вътрешното API за резервации на авиокомпанията. След това получава информацията за полетите (напр. JSON данни) и я изпраща обратно на AI асистента.
-
По-нататъшно взаимодействие: AI асистентът представя опциите за полети. След като изберете полет, асистентът може да извика инструмента “book flight” на същия MCP сървър, завършвайки резервацията.
Протокол агент към агент (A2A)
Докато MCP се фокусира върху свързването на LLMs с инструменти, протоколът Agent-to-Agent (A2A) прави крачка напред, като позволява комуникация и сътрудничество между различни AI агенти. A2A свързва AI агенти от различни организации, среди и технологични стекове, за да изпълнят споделена задача.
Ще разгледаме компонентите и предимствата на A2A, както и пример как той може да бъде приложен в нашето пътническо приложение.
Основни компоненти на A2A
A2A се фокусира върху улесняване на комуникацията между агенти и върху това те да работят заедно за изпълнение на подзадача на потребителя. Всеки компонент на протокола допринася за това:
Карта на агента
Similar to how an MCP server shares a list of tools, an Agent Card has:
- Името на агента .
- A description of the general tasks it completes.
- A list of specific skills with descriptions to help other agents (or even human users) understand when and why they would want to call that agent.
- The current Endpoint URL of the agent
- The version and capabilities of the agent such as streaming responses and push notifications.
Agent Executor
The Agent Executor is responsible for passing the context of the user chat to the remote agent, the remote agent needs this to understand the task that needs to be completed. In an A2A server, an agent uses its own Large Language Model (LLM) to parse incoming requests and execute tasks using its own internal tools.
Артефакт
След като отдалечен агент изпълни поисканата задача, неговият работен продукт се създава като артефакт. Артефактът съдържа резултата от работата на агента, описание на това, което е било завършено, и текстовия контекст, който се изпраща чрез протокола. След като артефактът бъде изпратен, връзката с отдалечения агент се затваря, докато не е необходимо отново.
Опашка за събития
Този компонент се използва за обработка на актуализации и предаване на съобщения. Той е особено важен в продукционни агентни системи, за да се предотврати затварянето на връзката между агентите преди задачата да бъде завършена, особено когато времето за изпълнение на задачата може да бъде по-дълго.
Предимства на A2A
• Подобрено сътрудничество: Позволява на агенти от различни доставчици и платформи да взаимодействат, да споделят контекст и да работят заедно, улеснявайки безпроблемна автоматизация между традиционно несвързани системи.
• Гъвкав избор на модел: Всеки A2A агент може да реши кой LLM да използва за обслужване на заявките си, позволявайки оптимизирани или финонастроени модели за всеки агент, за разлика от единна LLM връзка в някои MCP сценарии.
• Вградена автентикация: Автентикацията е интегрирана директно в A2A протокола, предоставяйки надеждна рамка за сигурност при взаимодействията между агентите.
Пример за A2A
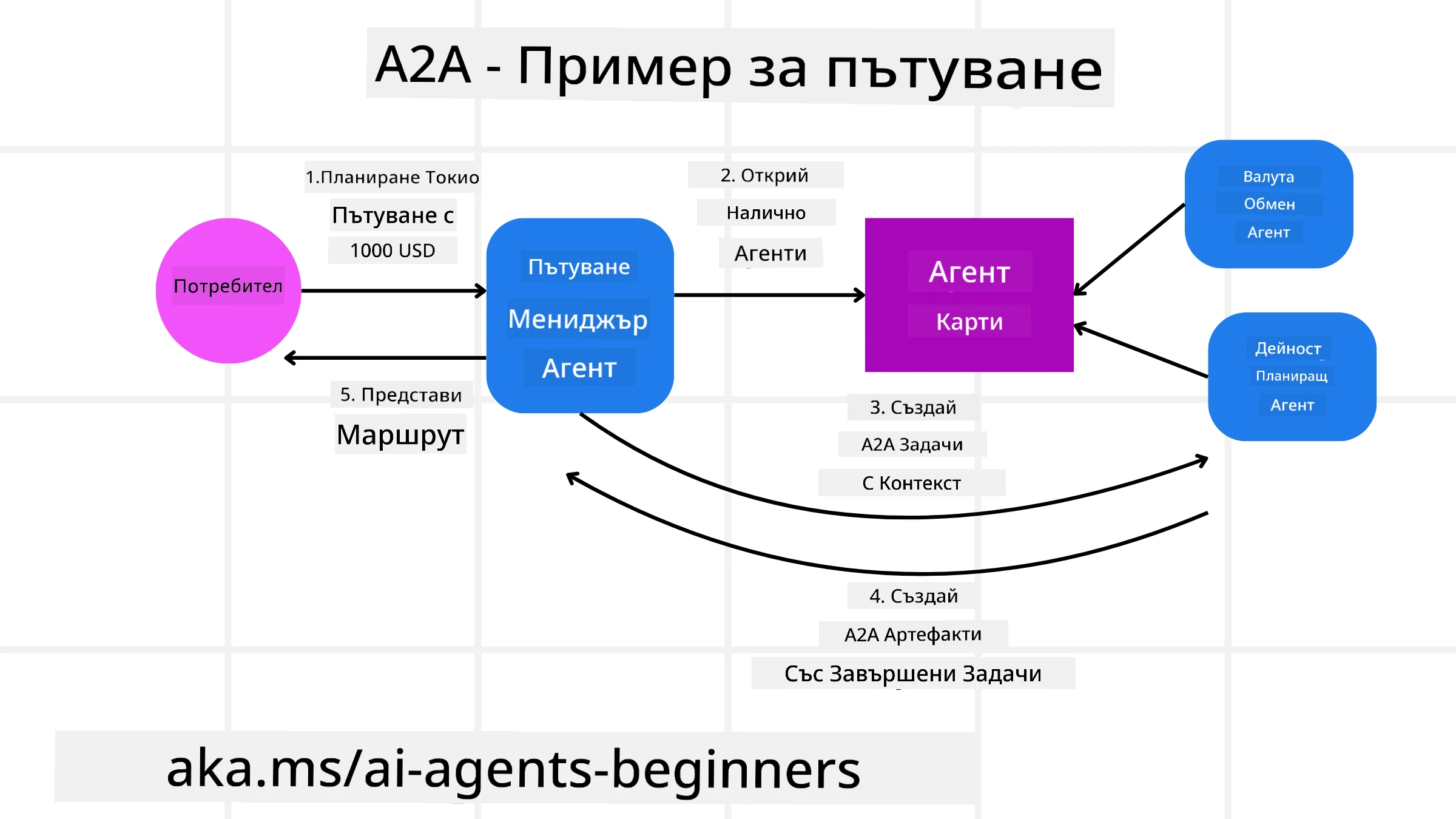
Нека развием нашия сценарий за резервация на пътуване, но този път използвайки A2A.
-
Заявка от потребителя към мултиагент: Потребителят взаимодейства с “Travel Agent” A2A клиент/агент, може би с думите: “Моля, резервирай цялото пътуване до Хонолулу за следващата седмица, включително полети, хотел и наем на кола”.
-
Оркестрация от Travel Agent: Travel Agent получава тази сложна заявка. Той използва своя LLM, за да разсъждава върху задачата и да определи, че трябва да взаимодейства с други специализирани агенти.
-
Комуникация между агенти: Travel Agent използва A2A протокола, за да се свърже със спомагателни агенти, като “Airline Agent”, “Hotel Agent” и “Car Rental Agent”, които са създадени от различни компании.
-
Делегирано изпълнение на задачите: Travel Agent изпраща конкретни задачи на тези специализирани агенти (напр. “Намери полети до Хонолулу”, “Резервирай хотел”, “Наеми кола”). Всеки от тези специализирани агенти, работещи със собствени LLMs и използващи свои инструменти (които сами по себе си могат да бъдат MCP сървъри), изпълнява своята част от резервацията.
-
Консолидиран отговор: След като всички downstream агенти завършат задачите си, Travel Agent компилира резултатите (детайли за полетите, потвърждение на хотела, резервация на кола) и изпраща цялостен, в стил чат, отговор обратно на потребителя.
Уеб на естествения език (NLWeb)
Уебсайтовете отдавна са основният начин за потребителите да получават информация и данни в интернет.
Нека разгледаме различните компоненти на NLWeb, предимствата на NLWeb и пример как нашият NLWeb работи, като погледнем нашето пътническо приложение.
Компоненти на NLWeb
-
NLWeb Application (Core Service Code): Системата, която обработва въпроси на естествен език. Тя свързва различните части на платформата, за да създава отговори. Можете да я разглеждате като двигателя, който захранва функциите на естествения език на един уебсайт.
-
NLWeb Protocol: Това е основен набор от правила за взаимодействие на естествен език с уебсайт. Той връща отговори в JSON формат (често използвайки Schema.org). Неговата цел е да създаде проста основа за “AI Web”, по същия начин, по който HTML направи възможно споделянето на документи онлайн.
-
MCP Server (Model Context Protocol Endpoint): Всяка NLWeb инсталация работи и като MCP сървър. Това означава, че може да споделя инструменти (като метод “ask”) и данни с други AI системи. На практика това прави съдържанието и възможностите на уебсайта използваеми от AI агенти, позволявайки сайтът да стане част от по-широката “екосистема на агентите”.
-
Embedding Models: Тези модели се използват за преобразуване на съдържанието на уебсайта в числови представяния, наречени вектори (embeddings). Тези вектори улавят смисъла по начин, който компютрите могат да сравняват и търсят. Те се съхраняват в специална база данни, а потребителите могат да избират кой embedding модел искат да използват.
-
Vector Database (Retrieval Mechanism): Тази база данни съхранява embeddings на съдържанието на уебсайта. Когато някой зададе въпрос, NLWeb проверява векторната база данни, за да намери бързо най-подходящата информация. Тя дава бърз списък с възможни отговори, класирани по сходство. NLWeb работи с различни системи за съхранение на вектори като Qdrant, Snowflake, Milvus, Azure AI Search и Elasticsearch.
Пример за NLWeb
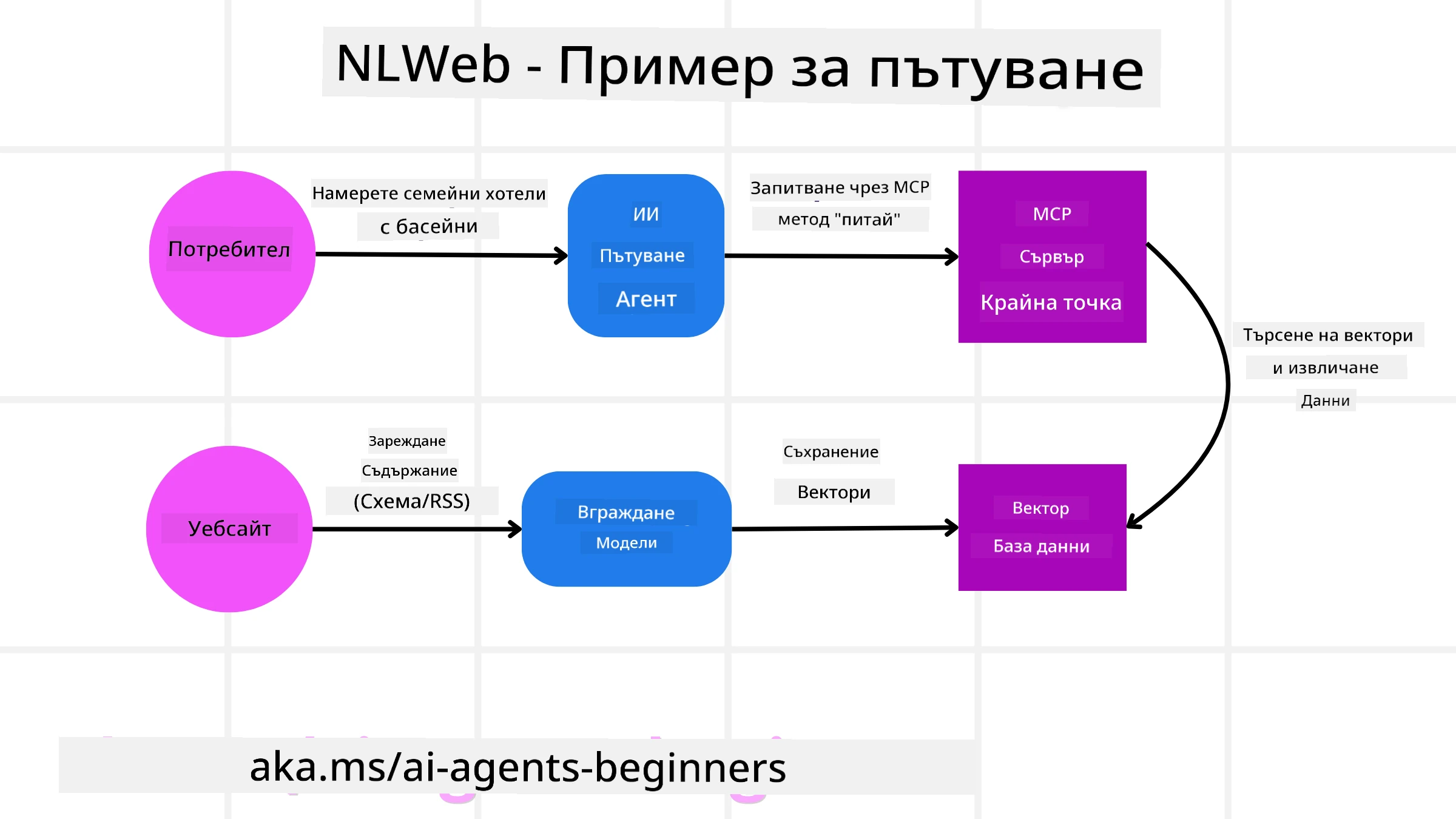
Вземете отново нашия уебсайт за резервации на пътувания, но този път той е захранван от NLWeb.
-
Въвеждане на данни: Съществуващите продуктови каталози на туристическия сайт (напр. списъци с полети, описания на хотели, туристически пакети) се форматират с използване на Schema.org или се зареждат чрез RSS канали. Инструментите на NLWeb въвеждат тези структурирани данни, създават embeddings и ги съхраняват в локална или отдалечена векторна база данни.
-
Запитване на естествен език (човек): Потребител посещава сайта и, вместо да навигира през менюта, въвежда в чат интерфейс: “Намери ми семеен хотел в Хонолулу с басейн за следващата седмица”.
-
Обработка от NLWeb: NLWeb приложението получава това запитване. То изпраща запитването до LLM за разбиране и едновременно търси в своята векторна база данни за релевантни хотелски обяви.
-
Точни резултати: LLM помага да се интерпретират резултатите от търсенето в базата данни, да се определят най-добрите съвпадения въз основа на критериите “семеен”, “басейн” и “Хонолулу”, и след това форматира отговора на естествен език. Ключово е, че отговорът се отнася до реални хотели от каталога на сайта, като се избягва измисляне на информация.
-
Взаимодействие с AI агент: Понеже NLWeb служи като MCP сървър, външен AI туристически агент също може да се свърже с тази NLWeb инстанция на уебсайта. AI агентът може да използва метода
ask("Are there any vegan-friendly restaurants in the Honolulu area recommended by the hotel?"). NLWeb инстанцията ще обработи това, използвайки своята база данни с информация за ресторанти (ако е заредена), и ще върне структуриран JSON отговор.
Имате ли още въпроси относно MCP/A2A/NLWeb?
Присъединете се към Discord на Microsoft Foundry, за да се срещнете с други учащи се, да посетите офис часове и да получите отговори на въпросите си за AI агенти.
Ресурси
Отказ от отговорност: Този документ е преведен с помощта на AI услуга за превод Co-op Translator. Въпреки че се стремим към точност, имайте предвид, че автоматизираните преводи могат да съдържат грешки или неточности. Оригиналният документ на неговия език трябва да се счита за авторитетен източник. За критична информация се препоръчва професионален превод от квалифициран преводач. Не носим отговорност за каквито и да е недоразумения или погрешни тълкувания, възникнали от използването на този превод.