ai-agents-for-beginners
Контекстен инженеринг за AI агенти

(Кликнете върху изображението по-горе, за да гледате видеото на този урок)
Разбирането на сложността на приложението, за което изграждате AI агент, е важно за създаването на надежден такъв. Трябва да изграждаме AI агенти, които ефективно управляват информацията, за да адресират сложни нужди отвъд prompt engineering.
В този урок ще разгледаме какво представлява контекстният инженеринг и неговата роля при изграждането на AI агенти.
Въведение
Този урок ще обхване:
• Какво представлява контекстният инженеринг и защо се различава от prompt engineering.
• Стратегии за ефективен контекстен инженеринг, включително как да пишем, избираме, компресираме и изолираме информацията.
• Чести провали на контекста, които могат да саботират вашия AI агент и как да ги поправите.
Учебни цели
След завършване на този урок, ще разбирате как да:
• Дефинирате контекстния инженеринг и да го разграничите от prompt engineering.
• Идентифицирате ключовите компоненти на контекста в приложения с големи езикови модели (LLM).
• Прилагате стратегии за писане, подбор, компресиране и изолиране на контекста, за да подобрите работата на агента.
• Разпознавате чести провали на контекста като отравяне, разсейване, объркване и конфликт, и прилагате техники за смекчаване.
Какво е контекстен инженеринг?
За AI агенти, контекстът е това, което движи планирането на AI агента да предприеме определени действия. Контекстният инженеринг е практиката да се уверим, че AI агентът има правилната информация, за да завърши следващата стъпка от задачата. Контекстният прозорец е ограничен по размер, така че като създатели на агенти трябва да изграждаме системи и процеси за управление на добавянето, премахването и кондензирането на информацията в контекстния прозорец.
Prompt Engineering срещу Контекстен инженеринг
Prompt engineering се фокусира върху един набор от статични инструкции за ефективно насочване на AI агентите с набор от правила. Контекстният инженеринг е начинът за управление на динамичен набор от информация, включително началния prompt, за да се гарантира, че AI агентът има това, от което се нуждае с течение на времето. Основната идея около контекстния инженеринг е да направите този процес повтаряем и надежден.
Видове контекст
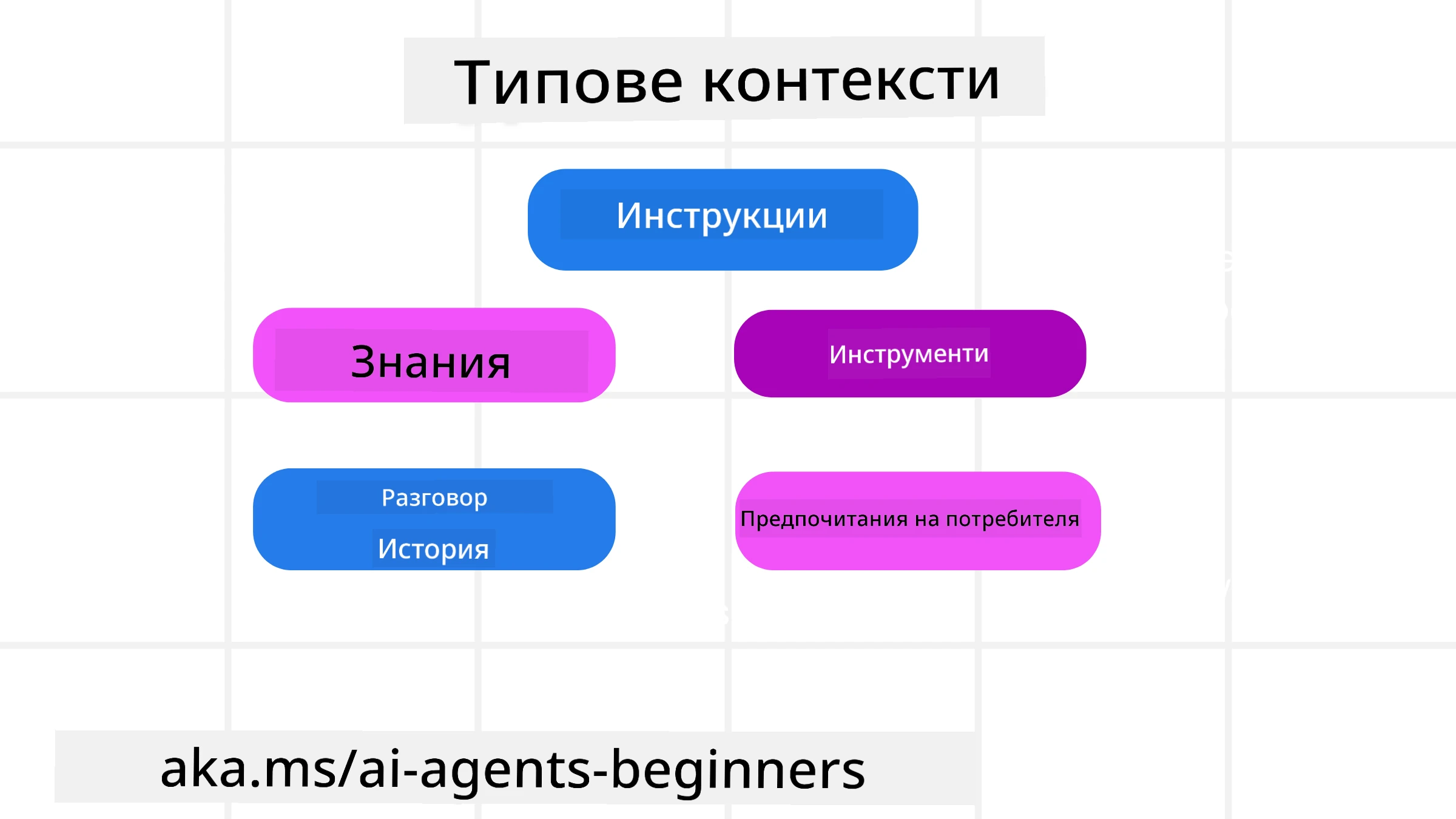
Важно е да запомните, че контекстът не е само едно нещо. Информацията, от която AI агентът се нуждае, може да идва от различни източници и зависи от нас да осигурим достъп на агента до тези източници:
Видовете контекст, които един AI агент може да се наложи да управлява, включват:
• Инструкции: Това са нещо като “правилата” на агента – prompts, system messages, few-shot примери (показващи на AI как да направи нещо) и описания на инструментите, които може да използва. Тук се комбинират фокусът на prompt engineering и контекстния инженеринг.
• Знание: Това обхваща факти, информация извлечена от бази данни или дългосрочни спомени, които агентът е натрупал. Това включва и интегриране на Retrieval Augmented Generation (RAG) система, ако агентът се нуждае от достъп до различни хранилища за знание и бази данни.
• Инструменти: Това са дефинициите на външни функции, APIs и MCP Servers, които агентът може да извиква, заедно с обратната връзка (резултатите), които получава от тях.
• История на разговора: Продължаващият диалог с потребителя. С времето тези разговори стават по-дълги и по-сложни, което означава, че заемат място в контекстния прозорец.
• Предпочитания на потребителя: Информация, научена за вкусовете или антипатиите на потребителя с течение на времето. Тези данни могат да се съхраняват и извикват при вземането на ключови решения, за да помогнат на потребителя.
Стратегии за ефективен контекстен инженеринг
Стратегии за планиране
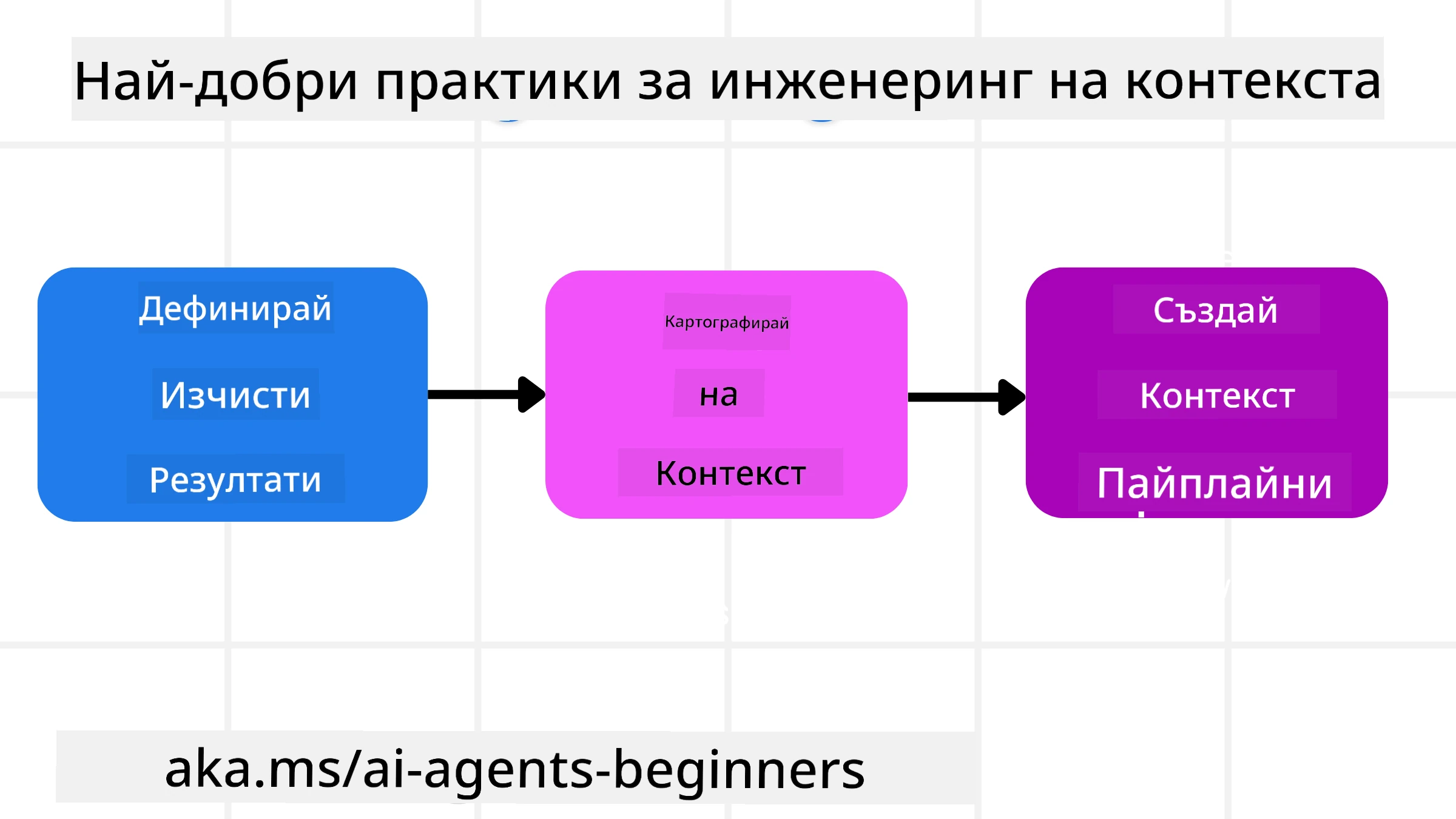
Добър контекстен инженеринг започва с добро планиране. Ето един подход, който ще ви помогне да започнете да мислите как да приложите концепцията за контекстен инженеринг:
- Определете ясни резултати - Резултатите от задачите, които ще бъдат възложени на AI агентите, трябва да бъдат ясно дефинирани. Отговорете на въпроса - “Как ще изглежда светът, когато AI агентът завърши задачата си?” С други думи, каква промяна, информация или отговор трябва да има потребителят след взаимодействието с AI агента.
- Картографирайте контекста - След като сте дефинирали резултатите на AI агента, трябва да отговорите на въпроса “Каква информация трябва да има AI агентът, за да завърши тази задача?”. По този начин можете да започнете да картографирате контекста къде може да се намери тази информация.
- Създайте контекстни тръбопроводи - Сега, когато знаете къде е информацията, трябва да отговорите на въпроса “Как агентът ще получи тази информация?”. Това може да се направи по различни начини, включително RAG, използване на MCP сървъри и други инструменти.
Практически стратегии
Планирането е важно, но веднага щом информацията започне да навлиза в контекстния прозорец на нашия агент, трябва да имаме практически стратегии за нейното управление:
Управление на контекста
Докато някои информации ще се добавят в контекстния прозорец автоматично, контекстният инженеринг е за по-активна роля при управлението на тази информация, която може да се извърши чрез няколко стратегии:
-
Бележник на агента Това позволява на AI агент да води бележки за релевантна информация относно текущите задачи и взаимодействия с потребителя по време на една сесия. Това трябва да съществува извън контекстния прозорец в файл или runtime обект, който агентът може по-късно да извика по време на тази сесия, ако е необходимо.
-
Спомени Бележниците са добри за управление на информация извън контекстния прозорец на една сесия. Спомените дават възможност на агентите да съхраняват и извличат релевантна информация през множество сесии. Това може да включва резюмета, предпочитания на потребителя и обратна връзка за подобрения в бъдеще.
-
Компресиране на контекста Когато контекстният прозорец расте и приближава своя предел, могат да се използват техники като обобщаване и подрязване. Това включва или запазване само на най-релевантната информация, или премахване на по-старите съобщения.
-
Многoагентни системи Разработването на многoагентна система е форма на контекстен инженеринг, защото всеки агент има свой собствен контекстен прозорец. Как този контекст се споделя и предава на различните агенти е още нещо, което трябва да се планира при изграждането на тези системи.
-
Пясъчни среди (Sandbox Environments) Ако агент трябва да изпълни някакъв код или да обработи големи количества информация в документ, това може да отнеме голям брой токени за обработка на резултатите. Вместо да се съхранява всичко това в контекстния прозорец, агентът може да използва пясъчна среда, която може да изпълнява този код и да чете само резултатите и друга релевантна информация.
-
Runtime обекти за състояние Това се прави чрез създаване на контейнери с информация, за да се управляват ситуации, когато агентът трябва да има достъп до определена информация. При комплексна задача това би позволило на агента да съхранява резултатите от всяка подпроцедура стъпка по стъпка, като контекстът остава свързан само с конкретната подпроцедура.
Пример за контекстен инженеринг
Да кажем, че искаме AI агент да “Резервира пътуване до Париж за мен.”
• Прост агент, използващ само prompt engineering, може просто да отговори: “Добре, кога бихте искали да отидете в Париж?”. Той обработва само вашия директен въпрос в момента, в който потребителят го зададе.
• Агент, използващ стратегиите за контекстен инженеринг, разгледани по-горе, би направил много повече. Преди дори да отговори, неговата система може да:
◦ Провери вашия календар за налични дати (извличайки реални данни).
◦ Възпроизведе минали предпочитания за пътуване (от дългосрочната памет) като предпочитана авиокомпания, бюджет или дали предпочитате директни полети.
◦ Идентифицира наличните инструменти за резервация на полети и хотели.
- Тогава примерен отговор може да бъде: “Hey [Your Name]! I see you’re free the first week of October. Shall I look for direct flights to Paris on [Preferred Airline] within your usual budget of [Budget]?”. Този по-богат, контекстно осъзнат отговор демонстрира силата на контекстния инженеринг.
Чести провали на контекста
Отравяне на контекста
Какво е това: Когато халюцинация (невярна информация, генерирана от LLM) или грешка влиза в контекста и се препраща многократно, което кара агента да преследва невъзможни цели или да развива нелепи стратегии.
Какво да направите: Внедрете валидация на контекста и карантина. Валутирайте информацията преди да бъде добавена към дългосрочната памет. Ако бъде открито потенциално отравяне, започнете чисти контекстни нишки, за да предотвратите разпространението на лошата информация.
Пример за резервация на пътуване: Вашият агент халюцинира директен полет от малко местно летище до отдалечен международен град, който всъщност не предлага международни полети. Тази несъществуваща подробност за полета се запазва в контекста. По-късно, когато помолите агента да резервира, той продължава да търси билети за този невъзможен маршрут, което води до повторни грешки.
Решение: Внедрете стъпка, която валидация на съществуването и маршрутите на полети чрез реално-времево API преди добавянето на подробността за полета в работния контекст на агента. Ако валидирането се провали, грешната информация се поставя в “карантина” и не се използва повече.
Разсейване на контекста
Какво е това: Когато контекстът стане толкова голям, че моделът се фокусира твърде много върху натрупаната история вместо да използва това, което е научил по време на обучението, което води до повтарящи се или безполезни действия. Моделите могат да започнат да грешат дори преди контекстният прозорец да е пълен.
Какво да направите: Използвайте обобщаване на контекста. Периодично компресирайте натрупаната информация в по-кратки резюмета, запазвайки важните детайли и премахвайки излишната история. Това помага да се “рестартира” фокусът.
Пример за резервация на пътуване: Дълго време сте обсъждали различни мечтани дестинации за пътуване, включително подробно описание на вашето пътуване с раница от преди две години. Когато най-накрая помолите да “намери ми евтин полет за следващия месец”, агентът се задържа в старите, нерелевантни детайли и продължава да задава въпроси за вашето раницоводско оборудване или минали маршрути, пренебрегвайки текущата ви заявка.
Решение: След определен брой ходове или когато контекстът стане твърде голям, агентът трябва да обобщи най-скорошните и релевантни части от разговора – фокусирайки се върху текущите ви дати за пътуване и дестинация – и да използва това кондензирано резюме за следващото LLM извикване, като изхвърли по-малко релевантния исторически чат.
Объркване на контекста
Какво е това: Когато ненужен контекст, често под формата на твърде много налични инструменти, кара модела да генерира лоши отговори или да извиква нерелевантни инструменти. По-малките модели са особено склонни към това.
Какво да направите: Внедрете управление на набор от инструменти (tool loadout), използвайки RAG техники. Съхранявайте описанията на инструментите във векторна база данни и избирайте само най-релевантните инструменти за всяка конкретна задача. Изследванията показват да се ограничи изборът на инструменти до по-малко от 30.
Пример за резервация на пътуване: Вашият агент има достъп до десетки инструменти: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations и т.н. Попитате, “Кой е най-добрият начин да се придвижвам из Париж?” Поради огромния брой инструменти, агентът се обърква и се опитва да извика book_flight вътре в Париж, или rent_car, въпреки че предпочитате обществения транспорт, защото описанията на инструментите могат да се припокриват или просто не успява да определи най-подходящия.
Решение: Използвайте RAG върху описанията на инструментите. Когато попитате за придвижване в Париж, системата динамично извлича само най-релевантните инструменти като rent_car или public_transport_info въз основа на вашето запитване, представяйки фокусиран “набор” от инструменти към LLM.
Конфликт в контекста
Какво е това: Когато в контекста съществува противоречива информация, водеща до непоследователно разсъждение или лоши крайни отговори. Това често се случва, когато информация пристига на етапи и ранни, погрешни предположения остават в контекста.
Какво да направите: Използвайте подрязване на контекста (context pruning) и оттоварване (offloading). Подрязването означава премахване на остаряла или противоречива информация, когато пристигнат нови детайли. Оттоварването дава на модела отделно работно пространство “scratchpad”, за да обработва информация без да задръства основния контекст.
Пример за резервация на пътуване: Първоначално казвате на агента, “Искам да летя в икономична класа.” По-късно в разговора променяте решението си и казвате, “Всъщност за това пътуване да бъде бизнес класа.” Ако и двете инструкции останат в контекста, агентът може да получи противоречиви резултати от търсения или да се обърка коя предпочитание да приоритизира.
Решение: Внедрете подрязване на контекста. Когато нова инструкция противоречи на стара, по-старата инструкция се премахва или изрично се презаписва в контекста. Като алтернатива, агентът може да използва scratchpad, за да помири противоречивите предпочитания преди да вземе решение, като гарантира, че само окончателната, последователна инструкция го ръководи.
Искате ли още въпроси относно контекстния инженеринг?
Присъединете се към Discord на Microsoft Foundry за да се срещнете с други учащи, да посетите office hours и да получите отговори на въпросите си за AI агенти.
Отказ от отговорност: Този документ е преведен с помощта на AI преводаческа услуга Co-op Translator. Въпреки че се стремим към точност, моля, имайте предвид, че автоматизираните преводи могат да съдържат грешки или неточности. Оригиналният документ на оригиналния език трябва да се счита за авторитетен източник. За критична информация се препоръчва професионален човешки превод. Не носим отговорност за каквито и да е недоразумения или погрешни тълкувания, възникнали в резултат на използването на този превод.