ai-agents-for-beginners
এজেন্টিক প্রোটোকল ব্যবহার (MCP, A2A এবং NLWeb)

(উপরের ছবিটি ক্লিক করে এই লেসনের ভিডিওটি দেখুন)
যেমনই AI agents-এর ব্যবহার বাড়ছে, তেমনি স্ট্যান্ডার্ডাইজেশন, নিরাপত্তা নিশ্চিত করা, এবং মুক্ত উদ্ভাবন সমর্থন করার জন্য প্রোটোকলের প্রয়োজনীয়তাও বাড়ছে। এই লেসনে, আমরা এই চাহিদা মেটাতে লক্ষ্য করা ৩টি প্রোটোকল কভার করব - Model Context Protocol (MCP), Agent to Agent (A2A) এবং Natural Language Web (NLWeb)।
ভূমিকা
এই লেসনে আমরা আলোচনা করব:
• কিভাবে MCP AI এজেন্টদের বাহ্যিক টুল এবং ডেটা অ্যাক্সেস করতে দেয় যাতে ব্যবহারকারীর কাজ সম্পন্ন করা যায়।
• কিভাবে A2A বিভিন্ন AI এজেন্টের মধ্যে যোগাযোগ এবং সহযোগিতা সক্ষম করে।
• কিভাবে NLWeb যেকোনো ওয়েবসাইটে প্রাকৃতিক ভাষার ইন্টারফেস নিয়ে আসে, যার ফলে AI এজেন্টরা কনটেন্ট আবিষ্কার ও ইন্টারঅ্যাক্ট করতে পারে।
শেখার লক্ষ্য
• চিহ্নিত করুন MCP, A2A, এবং NLWeb-এর মূল উদ্দেশ্য এবং সুবিধাসমূহ AI এজেন্টদের প্রসঙ্গে।
• ব্যাখ্যা করুন প্রতিটি প্রোটোকল কীভাবে LLMs, টুল এবং অন্যান্য এজেন্টদের মধ্যে যোগাযোগ ও ইন্টারঅ্যাকশন সহজ করে।
• চেনুন যে জটিল এজেন্টিক সিস্টেম নির্মাণে প্রতিটি প্রোটোকল কোন আলাদা ভূমিকা পালন করে।
মডেল কনটেক্সট প্রোটোকল
Model Context Protocol (MCP) একটি ওপেন স্ট্যান্ডার্ড যা অ্যাপ্লিকেশনগুলোকে LLMs-কে প্রসঙ্গ এবং টুল প্রদান করার জন্য মানক উপায় প্রদান করে। এটি বিভিন্ন ডেটা সোর্স এবং টুলের একটি “ইউনিভার্সাল অ্যাডাপ্টর” সক্ষম করে, যাতে AI এজেন্টরা সঙ্গতিপূর্ণভাবে সংযুক্ত হতে পারে।
চলুন MCP-এর উপাদানগুলো, সরাসরি API ব্যবহারের তুলনায় এর সুবিধাসমূহ, এবং AI এজেন্টগুলির কিভাবে একটি MCP সার্ভার ব্যবহার করতে পারে তার একটি উদাহরণ দেখি।
MCP মূল উপাদানসমূহ
MCP একটি ক্লায়েন্ট-সার্ভার আর্কিটেকচার-এ কাজ করে এবং মূল উপাদানগুলো হল:
• Hosts হল LLM অ্যাপ্লিকেশনগুলো (উদাহরণস্বরূপ VSCode-এর মতো একটি কোড এডিটর) যা MCP সার্ভারের সঙ্গে সংযোগ শুরু করে।
• Clients হল হোস্ট অ্যাপ্লিকেশনের মধ্যে থাকা উপাদানগুলো যা সার্ভারের সঙ্গে এক-থেকে-এক সংযোগ বজায় রাখে।
• Servers হল হালকা ওজনের প্রোগ্রাম যা নির্দিষ্ট সক্ষমতা প্রকাশ করে।
প্রটোকলে তিনটি মূল প্রিমিটিভ অন্তর্ভুক্ত রয়েছে যা MCP সার্ভারের সক্ষমতাসমূহ:
• Tools: এগুলো পৃথক ক্রিয়া বা ফাংশন যা একটি AI এজেন্ট কল করতে পারে কোনো কাজ করার জন্য। উদাহরণস্বরূপ, একটি আবহাওয়া সার্ভিস “get weather” টুল প্রকাশ করতে পারে, বা একটি ই-কমার্স সার্ভার “purchase product” টুল প্রকাশ করতে পারে। MCP সার্ভারগুলো তাদের সক্ষমতার তালিকায় প্রতিটি টুলের নাম, বর্ণনা, এবং ইনপুট/আউটপুট স্কিমা বিজ্ঞাপন করে।
• Resources: এগুলো রিড-ওনলি ডেটা আইটেম বা ডকুমেন্ট যা একটি MCP সার্ভার প্রদান করতে পারে, এবং ক্লায়েন্টগুলো ডিমান্ডে সেগুলো পুনরুদ্ধার করতে পারে। উদাহরণস্বরূপ ফাইল কনটেন্ট, ডাটাবেস রেকর্ড, বা লগ ফাইল। Resources টেক্সট (যেমন কোড বা JSON) বা বাইনারি (যেমন ইমেজ বা PDF) হতে পারে।
• Prompts: এগুলো পূর্বনির্ধারিত টেমপ্লেট যা পরামর্শকৃত প্রম্পট দেয়, জটিল ওয়ার্কফ্লোগুলোকে সহজ করে।
MCP-এর সুবিধাসমূহ
MCP AI এজেন্টদের জন্য উল্লেখযোগ্য সুবিধা প্রদান করে:
• Dynamic Tool Discovery: এজেন্টগুলো সার্ভার থেকে উপলব্ধ টুলগুলোর একটি তালিকা এবং সেগুলো কী করে সে সম্পর্কে বর্ণনা গতিশীলভাবে পেতে পারে। এটি ঐতিহ্যবাহী API-গুলোর বিপরীতে, যেগুলো প্রায়শই ইন্টিগ্রেশনের জন্য স্ট্যাটিক কোডিং প্রয়োজন করে, অর্থাৎ কোনো API পরিবর্তন হলে কোড আপডেট করা লাগে। MCP একটি “একবার ইন্টিগ্রেট করুন” পদ্ধতি দেয়, ফলে আরও অভিযোজ্যতা আসে।
• Interoperability Across LLMs: MCP বিভিন্ন LLM-গুলোর উপর কাজ করে, কোর মডেল পরিবর্তন করে পারফরম্যান্স মূল্যায়ন করার ফ্লেক্সিবিলিটি দেয়।
• Standardized Security: MCP একটি স্ট্যান্ডার্ড অথেনটিকেশন পদ্ধতি অন্তর্ভুক্ত করে, যা অতিরিক্ত MCP সার্ভার অ্যাক্সেস যোগ করার সময় স্কেলেবিলিটি উন্নত করে। এটি বিভিন্ন ঐতিহ্যবাহী API-এর জন্য আলাদা কী এবং অথেনটিকেশন ধরনের ব্যবস্থাপনার চেয়ে সহজ।
MCP উদাহরণ
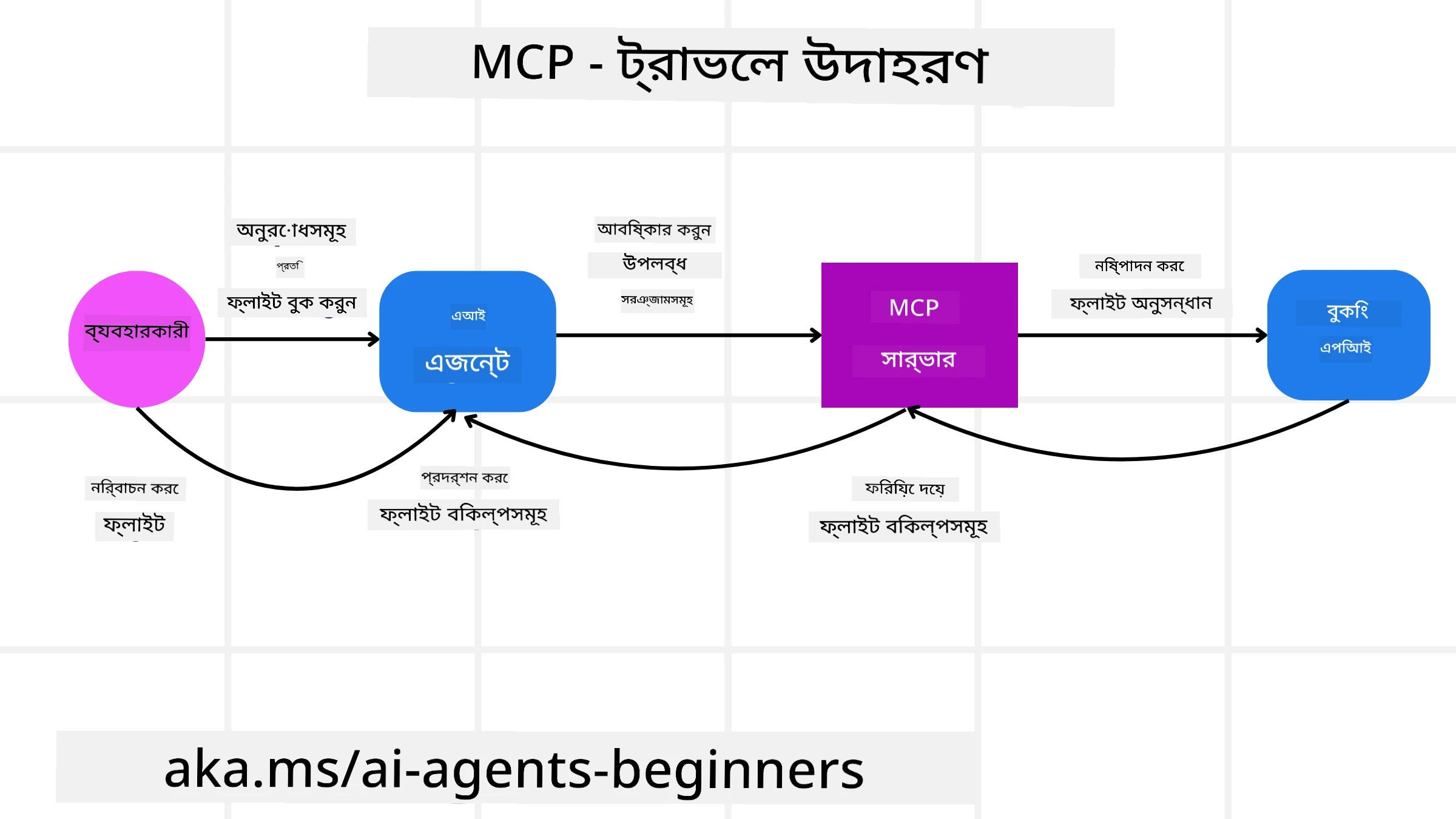
ধরা যাক একজন ব্যবহারকারী MCP-চালিত AI সহকারী ব্যবহার করে একটি ফ্লাইট বুক করতে চান।
-
সংযোগ: AI সহকারী (MCP ক্লায়েন্ট) একটি এয়ারলাইনের প্রদত্ত MCP সার্ভারের সঙ্গে সংযুক্ত হয়।
-
টুল আবিষ্কার: ক্লায়েন্ট এয়ারলাইনের MCP সার্ভারকে জিজ্ঞাসা করে, “আপনার কাছে কোন টুলগুলো উপলব্ধ?” সার্ভার “search flights” এবং “book flights”-এর মতো টুলগুলোর সঙ্গে উত্তর দেয়।
-
টুল আহ্বান: আপনি তখন AI সহকারীকে বলেন, “Please search for a flight from Portland to Honolulu.” AI সহকারী তার LLM ব্যবহার করে সনাক্ত করে যে এটিকে “search flights” টুল কল করতে হবে এবং প্রাসঙ্গিক প্যারামিটার (origin, destination) MCP সার্ভারে পাঠায়।
-
নিষ্পাদন এবং প্রতিক্রিয়া: MCP সার্ভার, একটি র্যাপার হিসেবে কাজ করে, এয়ারলাইনের অভ্যন্তরীণ বুকিং API-তে প্রকৃত কল করে। তারপর এটি ফ্লাইট তথ্য (যেমন JSON ডেটা) গ্রহণ করে এবং AI সহকারীর কাছে ফেরত পাঠায়।
-
অতিরিক্ত ইন্টারঅ্যাকশন: AI সহকারী ফ্লাইট অপশনগুলো উপস্থাপন করে। আপনি যখন একটি ফ্লাইট নির্বাচন করবেন, সহকারী একই MCP সার্ভারে “book flight” টুলটি আহ্বান করতে পারে এবং বুকিং সম্পন্ন করে।
এজেন্ট-টু-এজেন্ট প্রটোকল (A2A)
যেখানে MCP LLM-কে টুলের সাথে সংযুক্ত করার উপর কেন্দ্রীভূত, সেখানে Agent-to-Agent (A2A) প্রটোকল এক ধাপ এগিয়ে যায় এবং বিভিন্ন AI এজেন্টদের মধ্যে যোগাযোগ ও সহযোগিতা সক্রিয় করে। A2A বিভিন্ন সংস্থা, পরিবেশ এবং টেক স্ট্যাক জুড়ে AI এজেন্টদের সংযুক্ত করে যাতে একটি যৌথ টাস্ক সম্পন্ন করা যায়।
এবার আমরা A2A-এর উপাদান এবং সুবিধাসমূহ পরীক্ষা করবো, এবং কিভাবে এটি আমাদের ট্রাভেল অ্যাপ্লিকেশনে প্রয়োগ করা যেতে পারে তার একটি উদাহরণ দেখব।
A2A মূল উপাদানসমূহ
A2A এজেন্টদের মধ্যে যোগাযোগ সক্ষম করা এবং তারা একত্রে ব্যবহারকারীর একটি উপ-কাজ সম্পন্ন করতে কাজ করা নিশ্চিত করে। প্রটোকলের প্রতিটি উপাদান এটি সম্ভব করতে অবদান রাখে:
এজেন্ট কার্ড
একইভাবে যেভাবে একটি MCP সার্ভার টুলের তালিকা শেয়ার করে, একটি এজেন্ট কার্ডে থাকে:
- এজেন্টের নাম .
- যে সাধারণ কাজগুলো এটি সম্পন্ন করে তার বর্ণনা।
- অন্য এজেন্টদের (বা এমনকি মানব ব্যবহারকারীদের) সাহায্য করার জন্য কল করার সময় কখন এবং কেন তারা সেই এজেন্টটিকে কল করবে তা বোঝাতে নির্দিষ্ট দক্ষতাগুলোর তালিকা সহ বর্ণনা।
- এজেন্টটির বর্তমান Endpoint URL
- এজেন্টটির সংস্করণ এবং ক্ষমতাসমূহ যেমন স্ট্রিমিং রেসপন্স এবং পুশ নোটিফিকেশন।
এজেন্ট এক্সিকিউটর
এজেন্ট এক্সিকিউটরটি দায়িত্বপ্রাপ্ত থাকে ব্যবহারকারীর চ্যাটের প্রসঙ্গটি রিমোট এজেন্টে পাঠানোর জন্য, রিমোট এজেন্টকে কাজটি বুঝতে এর প্রয়োজন হয়। একটি A2A সার্ভারে, একটি এজেন্ট ইনকামিং অনুরোধ বিশ্লেষণ করতে এবং নিজের অভ্যন্তরীণ টুল ব্যবহার করে কাজ সম্পাদন করতে নিজের Large Language Model (LLM) ব্যবহার করে।
আর্টিফ্যাক্ট
রিমোট এজেন্ট অনুরোধকৃত কাজ সম্পন্ন করার পরে, তার কাজের ফলাফল একটি আর্টিফ্যাক্ট হিসেবে তৈরি হয়। একটি আর্টিফ্যাক্ট এজেন্টের কাজের ফলাফল ধারণ করে, কার্যটি কী সম্পন্ন হলো তার বর্ণনা, এবং প্রটোকলের মাধ্যমে প্রেরিত টেক্সট প্রসঙ্গ। আর্টিফ্যাক্ট পাঠানোর পর, রিমোট এজেন্টের সঙ্গে সংযোগ বন্ধ করা হয় যতক্ষণ না এটি আবার প্রয়োজন হয়।
ইভেন্ট কিউ
এই উপাদানটি আপডেটগুলি হ্যান্ডেল করা এবং মেসেজ পাস করার জন্য ব্যবহৃত হয়। এজেন্টিক সিস্টেমগুলিতে প্রোডাকশনে এটি বিশেষভাবে গুরুত্বপূর্ণ যাতে টাস্ক সম্পন্ন হওয়ার আগে এজেন্টদের মধ্যে সংযোগ বন্ধ না হয়ে যায়, বিশেষত যখন টাস্ক সম্পূর্ণ হতে সময় বেশি লাগতে পারে।
A2A-এর সুবিধাসমূহ
• উন্নত সহযোগিতা: এটি বিভিন্ন বিক্রেতা ও প্ল্যাটফর্মের এজেন্টদের ইন্টার্যাক্ট, প্রসঙ্গ ভাগ করে নেওয়া, এবং একসঙ্গেই কাজ করতে সক্ষম করে, যা ঐতিহ্যগতভাবে বিচ্ছিন্ন সিস্টেমগুলোর মধ্যে সিলসাহিত অটোমেশনকে সহজ করে।
• মডেল নির্বাচন নমনীয়তা: প্রতিটি A2A এজেন্ট তার অনুরোধ সার্ভিস করার জন্য কোন LLM ব্যবহার করবে তা নিজে নির্ধারণ করতে পারে, ফলে প্রতিটি এজেন্টের জন্য অপ্টিমাইজড বা ফাইন-টিউন করা মডেল ব্যবহার করা যায়, যা কিছু MCP সিনারিওতে একক LLM সংযোগের চেয়ে ভিন্ন।
• নিষ্কাশিত অথেনটিকেশন: অথেনটিকেশন সরাসরি A2A প্রটোকলে অন্তর্ভুক্ত থাকে, যা এজেন্ট ইন্টার্যাকশনের জন্য একটি শক্তিশালী সিকিউরিটি ফ্রেমওয়ার্ক প্রদান করে।
A2A উদাহরণ
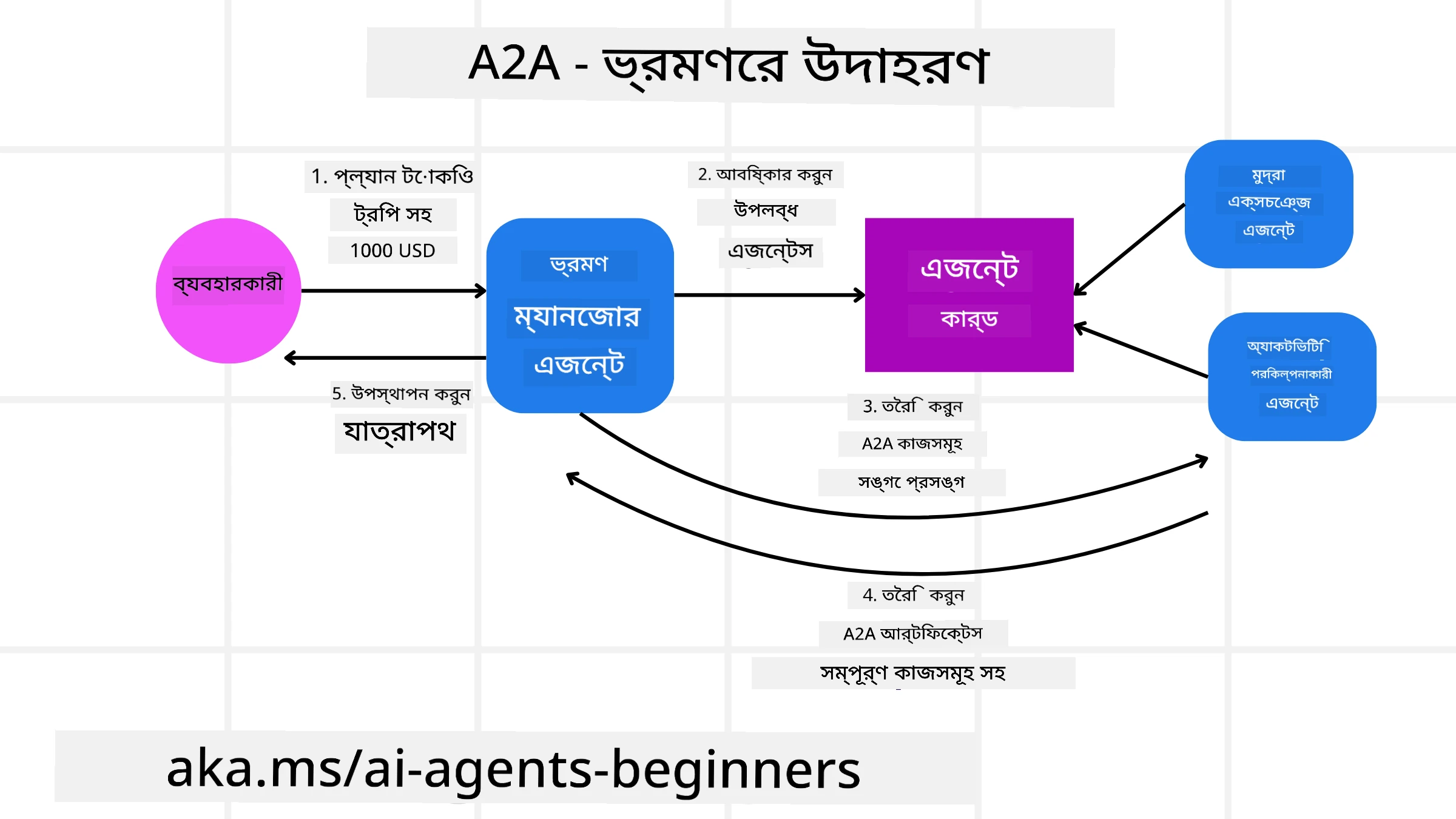
আমাদের ট্রাভেল বুকিং দৃশ্যকল্পটি এবার A2A ব্যবহার করে প্রসারিত করি।
-
বহু-এজেন্টকে ব্যবহারকারীর অনুরোধ: একজন ব্যবহারকারী “ট্রাভেল এজেন্ট” A2A ক্লায়েন্ট/এজেন্টের সঙ্গে ইন্টারঅ্যাক্ট করে, হয়তো বলে, “অনুগ্রহ করে আমাকে পরের সপ্তাহের জন্য হোনোলুলুতে পুরো ট্রিপটি বুক করে দিন, ফ্লাইট, হোটেল, এবং একটি ভাড়া করা গাড়ি সহ”।
-
ট্রাভেল এজেন্ট দ্বারা অর্কেস্ট্রেশন: ট্রাভেল এজেন্ট এই জটিল অনুরোধটি গ্রহণ করে। এটি তার LLM ব্যবহার করে টাস্ক সম্পর্কে যুক্তি করে এবং নির্ধারণ করে যে এটি অন্যান্য বিশেষায়িত এজেন্টদের সাথে ইন্টারঅ্যাক্ট করতে হবে।
-
এজেন্ট-মধ্যে যোগাযোগ: ট্রাভেল এজেন্ট তারপর A2A প্রটোকল ব্যবহার করে ডাউনস্ট্রিম এজেন্টের সাথে সংযুক্ত হয়, যেমন “Airline Agent”, “Hotel Agent”, এবং “Car Rental Agent” — যেগুলো বিভিন্ন কোম্পানি তৈরি করেছে।
-
এজেন্টদের মধ্যে দায়িত্ব বিনিময়: ট্রাভেল এজেন্ট নির্দিষ্ট টাস্কগুলো এই বিশেষায়িত এজেন্টদের কাছে পাঠায় (উদাহরণ: “Find flights to Honolulu,” “Book a hotel,” “Rent a car”)। প্রতিটি বিশেষায়িত এজেন্ট তার নিজস্ব LLM চালায় এবং নিজের টুল (যা MCP সার্ভারও হতে পারে) ব্যবহার করে বুকিংয়ের নির্দিষ্ট অংশ সম্পাদন করে।
-
সংহতকৃত প্রতিক্রিয়া: একবার সব ডাউনস্ট্রিম এজেন্ট তাদের কাজ সম্পন্ন করলে, ট্রাভেল এজেন্ট ফলাফলগুলো (ফ্লাইটের বিবরণ, হোটেলের কনফার্মেশন, গাড়ি রেন্টাল বুকিং) একত্র করে এবং ব্যবহারকারীর কাছে একটি সম্পূর্ণ, চ্যাট-স্টাইল প্রতিক্রিয়া পাঠায়।
প্রাকৃতিক ভাষার ওয়েব (NLWeb)
ওয়েবসাইট দীর্ঘকাল ধরে ব্যবহারকারীদের ইন্টারনেট জুড়ে তথ্য এবং ডেটা অ্যাক্সেস করার প্রধান উপায় হিসেবে কাজ করেছে।
চলুন NLWeb-এর বিভিন্ন উপাদান, NLWeb-এর সুবিধাসমূহ, এবং আমাদের ট্রাভেল অ্যাপ্লিকেশনের মাধ্যমে NLWeb কিভাবে কাজ করে তা উদাহরণ দেখেই দেখি।
NLWeb-এর উপাদানসমূহ
-
NLWeb অ্যাপ্লিকেশন (কোর সার্ভিস কোড): সেই সিস্টেম যা প্রাকৃতিক ভাষার প্রশ্ন প্রক্রিয়া করে। এটি প্ল্যাটফর্মের বিভিন্ন অংশকে সংযুক্ত করে প্রতিক্রিয়া তৈরি করে। আপনি এটিকে ওয়েবসাইটের প্রাকৃতিক ভাষার ফিচারগুলোর চালিকাশক্তি হিসাবে ভাবতে পারেন।
-
NLWeb প্রটোকল: এটি ওয়েবসাইটের সঙ্গে প্রাকৃতিক ভাষার ইন্টার্যাকশনের জন্য একটি মৌলিক নিয়মাবলী। এটি JSON ফরম্যাটে (প্রায়শই Schema.org ব্যবহার করে) প্রতিক্রিয়া পাঠায়। এর উদ্দেশ্য “AI Web” এর জন্য একটি সহজ ভিত্তি তৈরি করা, যেমন HTML অনলাইনে ডকুমেন্ট শেয়ার করা সম্ভব করেছে।
-
MCP সার্ভার (Model Context Protocol Endpoint): প্রতিটি NLWeb সেটআপ একটি MCP সার্ভার হিসেবেও কাজ করে। এর মানে এটি অন্যান্য AI সিস্টেমের সঙ্গে টুল (যেমন একটি “ask” মেথড) এবং ডেটা শেয়ার করতে পারে। বাস্তবে, এটি ওয়েবসাইটের কনটেন্ট এবং ক্ষমতাগুলোকে AI এজেন্টদের দ্বারা ব্যবহারযোগ্য করে, ওয়েবসাইটকে বৃহত্তর “এজেন্ট ইকোসিস্টেম”-এর অংশ করে তোলে।
-
এম্বেডিং মডেলগুলো: এই মডেলগুলো ব্যবহার করা হয় ওয়েবসাইট কনটেন্টকে ভেক্টর (embeddings) নামে সংখ্যাত্মক প্রতিনিধিত্বে রূপান্তর করার জন্য। এই ভেক্টরগুলো অর্থ ধারণ করে এমনভাবে যা কম্পিউটার তুলনা এবং সার্চ করতে পারে। সেগুলো একটি বিশেষ ডাটাবেসে সংরক্ষিত হয়, এবং ব্যবহারকারী নির্ধারণ করতে পারে কোন এম্বেডিং মডেল ব্যবহার করবে।
-
ভেক্টর ডাটাবেস (রিট্রিভাল মেকানিজম): এই ডাটাবেসটি ওয়েবসাইট কনটেন্টের এম্বেডিংগুলো সংরক্ষণ করে। যখন কেউ প্রশ্ন করে, NLWeb দ্রুত সর্বাধিক প্রাসঙ্গিক তথ্য খুঁজে পেতে ভেক্টর ডাটাবেস পরীক্ষা করে। এটি মিলের ভিত্তিতে সম্ভাব্য উত্তরগুলোর একটি তালিকা দ্রুত প্রদান করে। NLWeb বিভিন্ন ভেক্টর স্টোরেজ সিস্টেম যেমন Qdrant, Snowflake, Milvus, Azure AI Search, এবং Elasticsearch-এর সঙ্গে কাজ করে।
NLWeb উদাহরণ
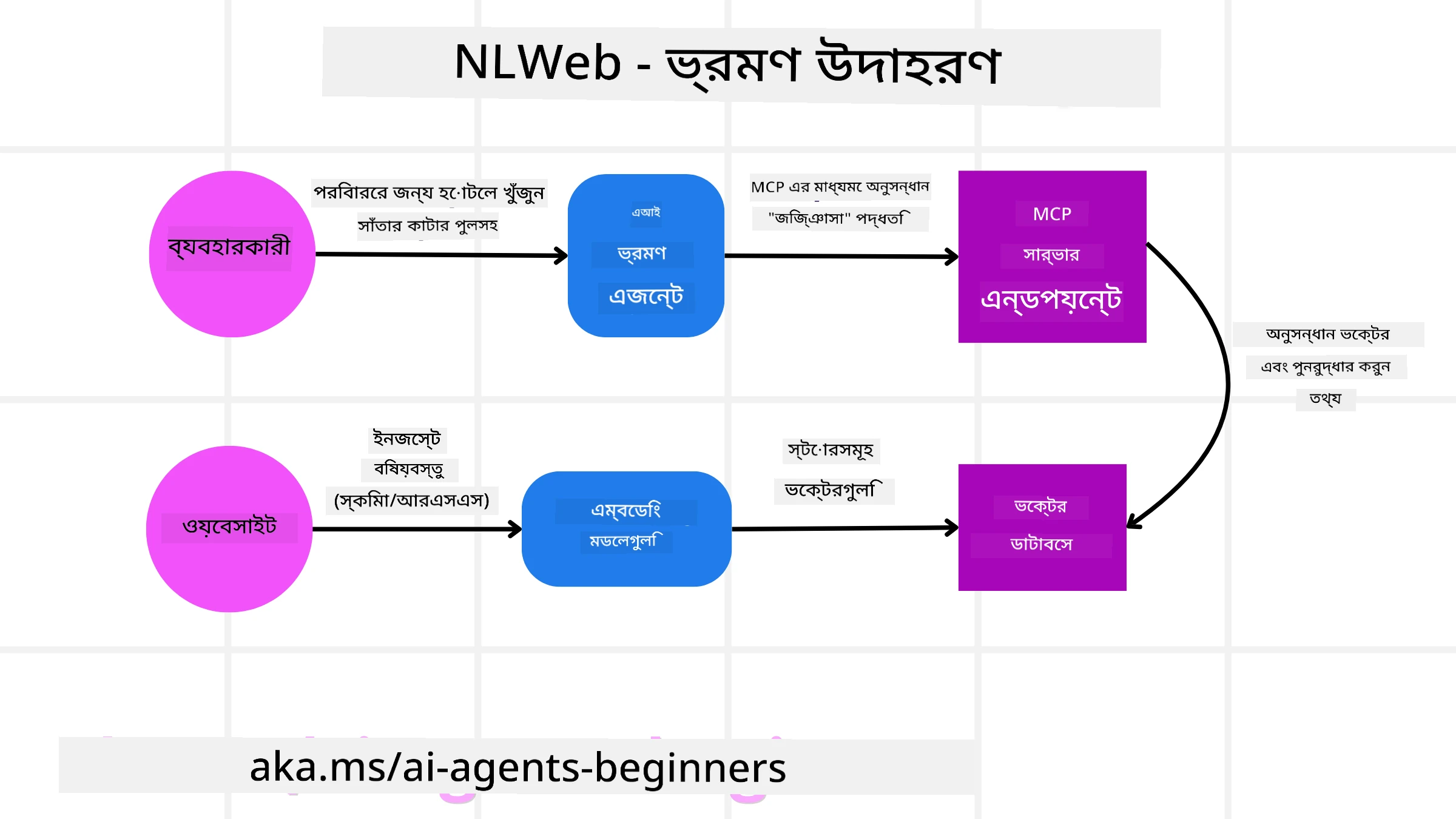
আমাদের ট্রাভেল বুকিং ওয়েবসাইটটি আবার বিবেচনা করুন, তবে এবার এটি NLWeb দ্বারা চালিত।
-
ডেটা ইনজেশন: ট্রাভেল ওয়েবসাইটের বিদ্যমান প্রোডাক্ট ক্যাটালগ (যেমন ফ্লাইট লিস্টিং, হোটেল বর্ণনা, ট্যুর প্যাকেজ) Schema.org ব্যবহার করে ফরম্যাট করা বা RSS ফিডের মাধ্যমে লোড করা হয়। NLWeb-এর টুলগুলো এই স্ট্রাকচার্ড ডেটা ইনজেস্ট করে, এম্বেডিং তৈরি করে, এবং সেগুলোকে লোকাল বা রিমোট ভেক্টর ডাটাবেসে সংরক্ষণ করে।
-
প্রাকৃতিক ভাষার কুয়েরি (মানব): একজন ব্যবহারকারী ওয়েবসাইটে আসে এবং মেনু নেভিগেট করার বদলে একটি চ্যাট ইন্টারফেসে টাইপ করে: “Find me a family-friendly hotel in Honolulu with a pool for next week”.
-
NLWeb প্রসেসিং: NLWeb অ্যাপ্লিকেশন এই কুয়েরিটি গ্রহণ করে। এটি বোঝার জন্য কুয়েরিটি একটি LLM-এ পাঠায় এবং একই সময়ে সংশ্লিষ্ট হোটেল লিস্টিং খোঁজার জন্য ভেক্টর ডাটাবেস সার্চ করে।
-
নুচিত ফলাফল: LLM ডাটাবেস থেকে সার্চ ফলাফলগুলো ব্যাখ্যা করতে সাহায্য করে, “family-friendly”, “pool”, এবং “Honolulu” ক্রাইটেরিয়ার ভিত্তিতে সেরা ম্যাচগুলো শনাক্ত করে এবং তারপর একটি প্রাকৃতিক ভাষার প্রতিক্রিয়া ফরম্যাট করে। অত্যন্ত গুরুত্বপূর্ণভাবে, প্রতিক্রিয়াটি ওয়েবসাইটের ক্যাটালগ থেকে বাস্তব হোটেলকে রেফার করে, কাল্পনিক তথ্য এড়িয়ে চলে।
-
AI এজেন্ট ইন্টারঅ্যাকশন: যেহেতু NLWeb একটি MCP সার্ভার হিসেবে কাজ করে, একটি বহিরাগত AI ট্রাভেল এজেন্টও এই ওয়েবসাইটের NLWeb ইনস্ট্যান্সে সংযুক্ত হতে পারে। AI এজেন্ট তখন সরাসরি ওয়েবসাইটকে জিজ্ঞেস করতে
askMCP মেথড ব্যবহার করতে পারে:ask("Are there any vegan-friendly restaurants in the Honolulu area recommended by the hotel?")। NLWeb ইনস্ট্যান্সটি এটি প্রক্রিয়া করবে, যদি লোড করা থাকে তবে রেস্টুরেন্ট ইনফোগুলি ব্যবহার করে এবং একটি স্ট্রাকচার্ড JSON প্রতিক্রিয়া ফেরত পাঠাবে।
MCP/A2A/NLWeb সম্পর্কে আরও প্রশ্ন আছে?
Join the Microsoft Foundry Discord to meet with other learners, attend office hours and get your AI Agents questions answered.
Resources
অস্বীকৃতি: এই নথিটি এআই অনুবাদ সেবা Co-op Translator ব্যবহার করে অনুবাদ করা হয়েছে। আমরা যথাসম্ভব নির্ভুলতার চেষ্টা করি, তবুও অনুগ্রহ করে বিবেচনা করুন যে স্বয়ংক্রিয় অনুবাদে ত্রুটি বা অসঙ্গতি থাকতে পারে। মূল ভাষায় থাকা মূল নথিটিকেই কর্তৃপক্ষসূত্র হিসেবে গণ্য করা উচিত। গুরুত্বপূর্ণ তথ্যের জন্য পেশাদার মানব অনুবাদ গ্রহণ করার পরামর্শ দেওয়া হয়। এই অনুবাদ ব্যবহারের ফলে কোনো ভুল বোঝাবুঝি বা ভুল ব্যাখ্যার জন্য আমরা দায়ী নই।