ai-agents-for-beginners
Inženýrství kontextu pro AI agenty

(Klikněte na obrázek výše pro zhlédnutí videa této lekce)
Pochopení složitosti aplikace, pro kterou vytváříte AI agenta, je důležité pro vytvoření spolehlivého agenta. Potřebujeme vytvářet AI agenty, kteří efektivně spravují informace, aby řešili komplexní potřeby dál než jen prompt engineering.
V této lekci se podíváme na to, co je inženýrství kontextu a jakou hraje roli při budování AI agentů.
Úvod
Tato lekce pokryje:
• Co je inženýrství kontextu a proč se liší od prompt engineeringu.
• Strategie pro efektivní inženýrství kontextu, včetně toho, jak psát, vybírat, komprimovat a izolovat informace.
• Běžné selhání kontextu, které mohou vašeho AI agenta zhatit, a jak je opravit.
Cíle učení
Po dokončení této lekce budete rozumět a umět:
• Definovat inženýrství kontextu a odlišit ho od prompt engineeringu.
• Identifikovat klíčové komponenty kontextu v aplikacích založených na velkých jazykových modelech (LLM).
• Aplikovat strategie pro psaní, výběr, kompresi a izolaci kontextu, aby se zlepšil výkon agenta.
• Rozpoznat běžná selhání kontextu, jako je otrava, rozptylení, zmatek a střet, a zavést techniky zmírnění.
Co je inženýrství kontextu?
Pro AI agenty je kontext tím, co řídí plánování agenta, aby provedl určité akce. Inženýrství kontextu je praxe zajištění, že AI agent má správné informace k dokončení dalšího kroku úkolu. Okno kontextu má omezenou velikost, takže jako tvůrci agentů musíme vytvářet systémy a procesy pro přidávání, odebírání a zhušťování informací v okně kontextu.
Prompt engineering vs inženýrství kontextu
Prompt engineering se zaměřuje na jednorázový soubor statických instrukcí pro efektivní nasměrování AI agentů pomocí sady pravidel. Inženýrství kontextu řeší, jak spravovat dynamickou sadu informací, včetně počátečního promptu, aby AI agent měl to, co potřebuje v průběhu času. Hlavní myšlenka inženýrství kontextu je učinit tento proces opakovatelným a spolehlivým.
Typy kontextu
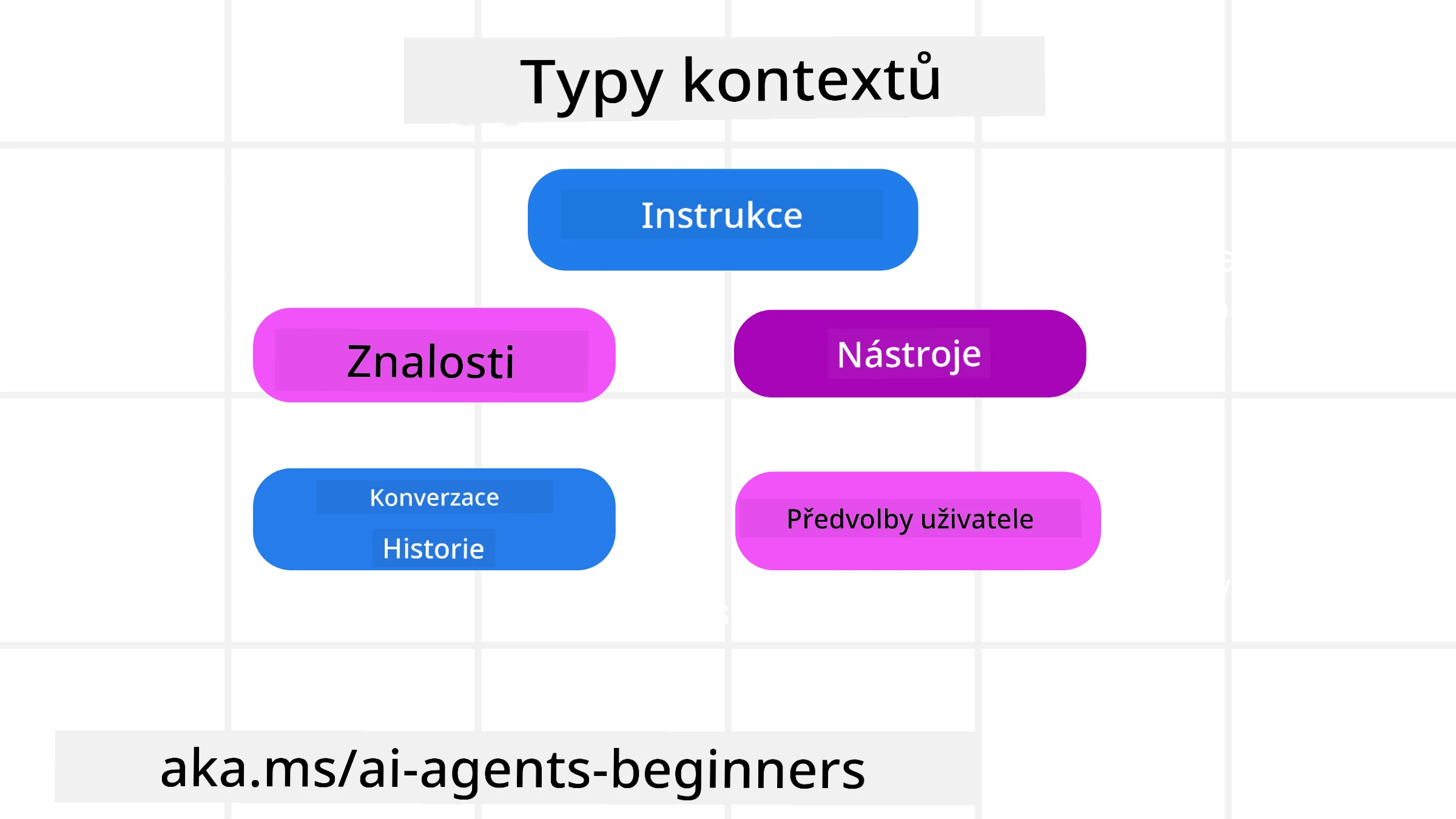
Je důležité si pamatovat, že kontext není jen jedna věc. Informace, které AI agent potřebuje, mohou pocházet z různých zdrojů a je na nás zajistit, aby agent měl k těmto zdrojům přístup:
Typy kontextu, které může AI agent potřebovat spravovat, zahrnují:
• Instrukce: To jsou jako „pravidla“ agenta – prompty, systémové zprávy, few-shot příklady (ukazující AI, jak něco udělat) a popisy nástrojů, které může použít. Zde se propojuje zaměření prompt engineeringu s inženýrstvím kontextu.
• Znalosti: Pokrývá fakta, informace získané z databází nebo dlouhodobé vzpomínky, které si agent uložil. To zahrnuje integraci systému Retrieval Augmented Generation (RAG), pokud agent potřebuje přístup k různým úložištím znalostí a databázím.
• Nástroje: To jsou definice externích funkcí, API a MCP serverů, které může agent volat, spolu se zpětnou vazbou (výsledky), kterou získá jejich použitím.
• Historie konverzace: Probíhající dialog s uživatelem. Jak čas plyne, tyto konverzace se prodlužují a stávají se složitějšími, což znamená, že zabírají místo v okně kontextu.
• Preference uživatele: Informace naučené o uživatelových oblibách nebo nelibostech v průběhu času. Ty mohou být uloženy a vyvolány při rozhodování, aby se uživateli pomohlo.
Strategie pro efektivní inženýrství kontextu
Strategické plánování
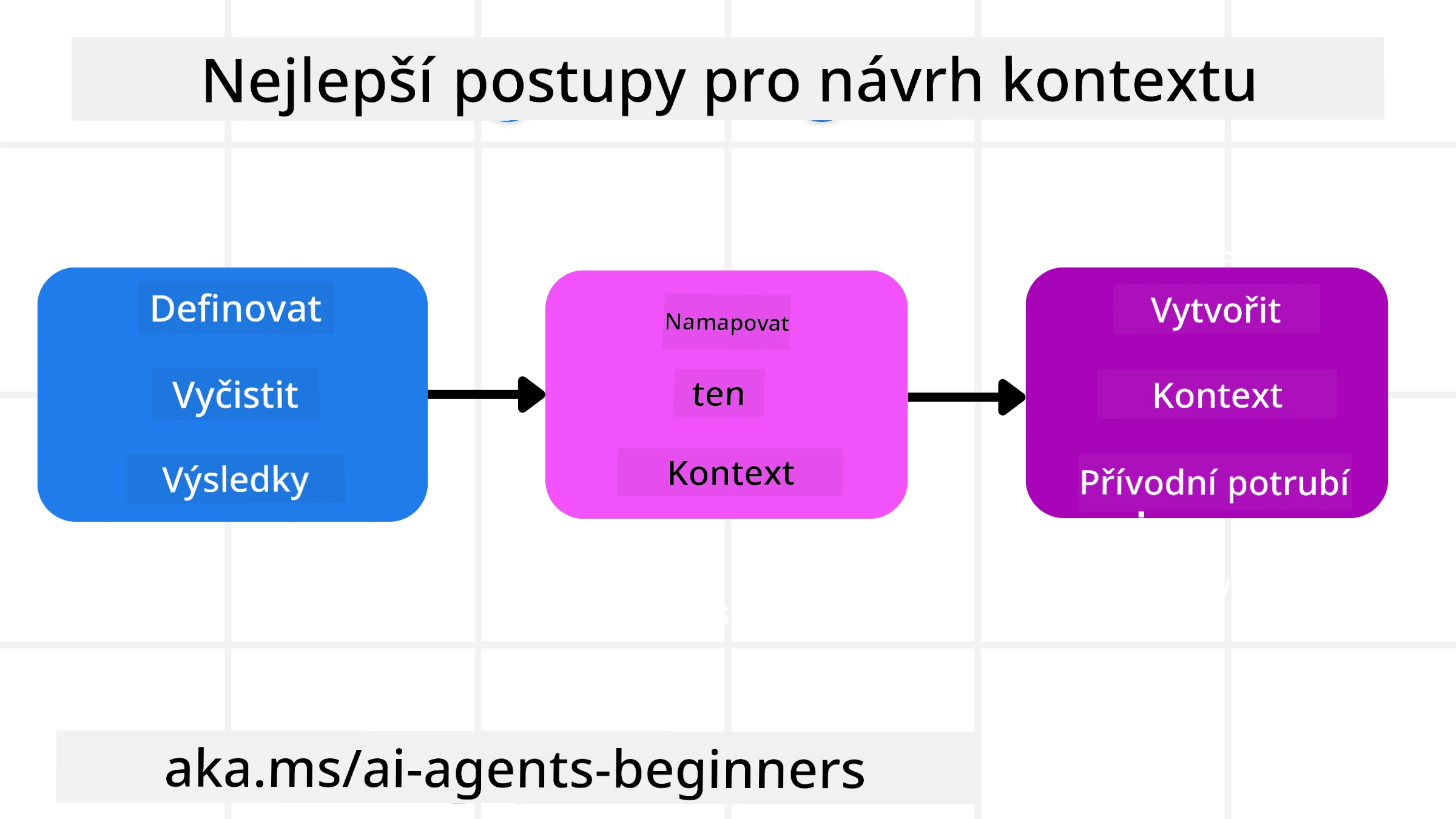
Dobré inženýrství kontextu začíná dobrým plánováním. Zde je přístup, který vám pomůže začít přemýšlet o tom, jak aplikovat koncept inženýrství kontextu:
- Definujte jasné výsledky - Výsledky úkolů, které budou AI agenti vykonávat, by měly být jasně definovány. Odpovězte na otázku – „Jak bude vypadat svět, až AI agent dokončí svůj úkol?“ Jinými slovy, jaká změna, informace nebo odpověď by měl uživatel mít po interakci s AI agentem.
- Namapujte kontext - Jakmile máte definované výsledky AI agenta, musíte odpovědět na otázku „Jaké informace agent potřebuje k dokončení tohoto úkolu?“. Tímto způsobem můžete začít mapovat kontext, kde lze tyto informace nalézt.
- Vytvořte kontextové pipeline - Teď, když víte, kde jsou informace, musíte odpovědět na otázku „Jak agent tyto informace získá?“. To lze udělat různými způsoby včetně RAG, použití MCP serverů a dalších nástrojů.
Praktické strategie
Plánování je důležité, ale jakmile se informace začnou dostávat do okna kontextu našeho agenta, potřebujeme praktické strategie, jak je řídit:
Správa kontextu
Zatímco některé informace budou automaticky přidávány do okna kontextu, inženýrství kontextu znamená aktivnější řízení této informace, což lze provést několika strategiemi:
-
Agent Scratchpad Tento umožňuje AI agentovi dělat si poznámky o relevantních informacích týkajících se aktuálních úkolů a uživatelských interakcí během jedné relace. To by mělo existovat mimo okno kontextu v souboru nebo běhovém objektu, který si agent může později během této relace vyžádat, pokud to bude potřeba.
-
Vzpomínky Scratchpady jsou dobré pro správu informací mimo kontextové okno jedné relace. Vzpomínky umožňují agentům ukládat a vybavovat si relevantní informace napříč více relacemi. To může zahrnovat shrnutí, preference uživatele a zpětnou vazbu pro zlepšení v budoucnu.
-
Kompresování kontextu Jakmile okno kontextu roste a blíží se svému limitu, lze použít techniky jako shrnutí a ořezávání. To zahrnuje buď ponechání pouze nejrelevantnějších informací, nebo odstranění starších zpráv.
-
Multi-agentní systémy Vývoj multi-agentních systémů je formou inženýrství kontextu, protože každý agent má své vlastní okno kontextu. Jak je tento kontext sdílen a předáván různým agentům je další věc, kterou je třeba naplánovat při budování těchto systémů.
-
Sandbox prostředí Pokud agent potřebuje spustit nějaký kód nebo zpracovat velké množství informací v dokumentu, může to vyžadovat velké množství tokenů k zpracování výsledků. Místo toho, aby bylo vše uloženo v okně kontextu, agent může použít sandbox prostředí, které dokáže tento kód spustit a číst jen výsledky a další relevantní informace.
-
Běhové stavové objekty To se provádí vytvořením kontejnerů informací pro řízení situací, kdy agent potřebuje mít přístup k určitým informacím. U složitého úkolu by to umožnilo agentovi ukládat výsledky jednotlivých dílčích úkolů krok za krokem, což umožní, aby kontext zůstal napojený pouze na konkrétní dílčí úkol.
Příklad inženýrství kontextu
Řekněme, že chceme, aby AI agent „Rezervoval mi cestu do Paříže.“
• Jednoduchý agent používající pouze prompt engineering by mohl jednoduše odpovědět: „Dobře, kdy byste chtěli jet do Paříže?“. Zpracoval pouze vaši přímou otázku v okamžiku, kdy ji uživatel položil.
• Agent používající strategie inženýrství kontextu, které jsme pokryli, by udělal mnohem více. Jeho systém by mohl ještě před odpovědí:
◦ Zkontrolovat váš kalendář pro volné termíny (získání dat v reálném čase).
◦ Připomenout si minulé cestovní preference (z dlouhodobé paměti) jako vaši preferovanou leteckou společnost, rozpočet nebo zda preferujete přímé lety.
◦ Identifikovat dostupné nástroje pro rezervaci letů a hotelů.
- Pak by příklad odpovědi mohl být: “Ahoj [Your Name]! Vidím, že máte volno první týden v říjnu. Mám hledat přímé lety do Paříže na [Preferred Airline] v rámci vašeho obvyklého rozpočtu [Budget]?” Tato bohatší, kontextem ovlivněná odpověď demonstruje sílu inženýrství kontextu.
Běžná selhání kontextu
Otrava kontextu
Co to je: Když se do kontextu dostane halucinace (nepravdivá informace generovaná LLM) nebo chyba a je opakovaně odkazována, což způsobí, že agent sleduje nemožné cíle nebo vyvíjí nesmyslné strategie.
Co dělat: Implementujte validaci kontextu a karanténu. Ověřujte informace před jejich přidáním do dlouhodobé paměti. Pokud je zjištěna potenciální otrava, zahajte nové vlákno kontextu, aby se zabránilo šíření špatných informací.
Příklad rezervace cestování: Váš agent vymyslí (zhalucinuje) přímý let z malého místního letiště do vzdáleného mezinárodního města, které ve skutečnosti mezinárodní lety nenabízí. Tento neexistující údaj o letu se uloží do kontextu. Později, když požádáte agenta o rezervaci, stále se snaží najít letenky pro tuto nemožnou trasu, což vede k opakovaným chybám.
Řešení: Zaveďte krok, který ověří existenci letu a trasy pomocí API v reálném čase předtím, než se detail letu přidá do pracovního kontextu agenta. Pokud ověření selže, chybná informace je „zkaranténována“ a dále se nepoužívá.
Rozptylování kontextu
Co to je: Když se kontext stane tak velkým, že model se příliš zaměří na nahromaděnou historii místo využití toho, co se naučil během tréninku, což vede k opakovaným nebo neužitečným akcím. Modely mohou začít dělat chyby ještě před tím, než je okno kontextu plné.
Co dělat: Použijte shrnutí kontextu. Pravidelně komprimujte nahromaděné informace do kratších shrnutí, zachovávající důležité detaily a odstraňující redundantní historii. To pomáhá „resetovat“ fokus.
Příklad rezervace cestování: Diskutovali jste o různých vysněných cestovních destinacích dlouhou dobu, včetně podrobného vyprávění o vašem batohovém výletě před dvěma lety. Když nakonec požádáte najít levný let na příští měsíc, agent se zasekne ve starých, irelevantních detailech a stále se ptá na vaše batohové vybavení nebo minulý itinerář, opomíjejíc vaši aktuální žádost.
Řešení: Po určitém počtu tahů nebo když kontext příliš roste, by agent měl shrnout nejnovější a nejrelevantnější části konverzace – zaměřit se na vaše aktuální cestovní data a destinaci – a použít tento zhuštěný souhrn pro další volání LLM, přičemž méně relevantní historii zahodí.
Zmatek kontextu
Co to je: Když zbytečný kontext, často ve formě příliš mnoha dostupných nástrojů, způsobí, že model generuje špatné odpovědi nebo volá irelevantní nástroje. Menší modely jsou zvláště náchylné k tomuto.
Co dělat: Implementujte správu nástrojů pomocí technik RAG. Ukládejte popisy nástrojů ve vektorové databázi a vybírejte pouze nejrelevantnější nástroje pro každý konkrétní úkol. Výzkumy ukazují, že je vhodné omezit výběr nástrojů na méně než 30.
Příklad rezervace cestování: Váš agent má přístup k desítkám nástrojů: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations atd. Zeptáte se: „Jak se nejlépe pohybovat po Paříži?“ Kvůli obrovskému množství nástrojů se agent změní v zmatek a pokusí se volat book_flight v rámci Paříže, nebo rent_car, i když preferujete veřejnou dopravu, protože popisy nástrojů se mohou překrývat nebo prostě nedokáže rozlišit ten nejlepší.
Řešení: Použijte RAG nad popisy nástrojů. Když se zeptáte na pohyb po Paříži, systém dynamicky vyhledá pouze nejrelevantnější nástroje jako rent_car nebo public_transport_info na základě vašeho dotazu a představí LLM zaměřený „loadout“ nástrojů.
Střet kontextu
Co to je: Když v kontextu existují protichůdné informace, což vede k nekonzistentnímu uvažování nebo špatným konečným odpovědím. To se často stává, když informace přicházejí postupně a rané, nesprávné předpoklady zůstanou v kontextu.
Co dělat: Použijte prořezávání kontextu a odkládání. Prořezávání znamená odstraňování zastaralých nebo protichůdných informací, jak přicházejí nové detaily. Odkládání dává modelu samostatné „scratchpad“ pracovní místo pro zpracování informací bez zahlcení hlavního kontextu.
Příklad rezervace cestování: Nejprve agentovi řeknete: „Chci letět v ekonomické třídě.“ Později v konverzaci změníte názor a řeknete: „Vlastně pro tuto cestu pojďme business třídu.“ Pokud obě instrukce zůstanou v kontextu, agent může dostávat protichůdné výsledky vyhledávání nebo se zmást, kterou preferenci upřednostnit.
Řešení: Implementujte prořezávání kontextu. Když nová instrukce odporuje staré, starší instrukce je odstraněna nebo výslovně přepsána v kontextu. Alternativně může agent použít scratchpad k vyrovnání protichůdných preferencí před rozhodnutím, čímž zajistí, že pouze konečná, konzistentní instrukce budou řídit jeho akce.
Máte další otázky o inženýrství kontextu?
Připojte se k Microsoft Foundry Discord a setkejte se s ostatními studenty, navštěvujte konzultační hodiny a získejte odpovědi na vaše otázky ohledně AI agentů.
Vyloučení odpovědnosti: Tento dokument byl přeložen pomocí AI překladatelské služby Co-op Translator. I když usilujeme o přesnost, mějte prosím na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Původní dokument v jeho mateřském jazyce by měl být považován za autoritativní zdroj. U kritických informací se doporučuje profesionální lidský překlad. Nejsme odpovědní za jakákoli nedorozumění nebo mylné výklady vyplývající z použití tohoto překladu.