ai-agents-for-beginners

(Klik på billedet ovenfor for at se videoen af denne lektion)
Agentic RAG
Denne lektion giver en omfattende oversigt over Agentic Retrieval-Augmented Generation (Agentic RAG), et fremspirende AI-paradigme hvor store sprogmodeller (LLMs) selvstændigt planlægger deres næste skridt, mens de henter information fra eksterne kilder. I modsætning til statiske mønstre med hent-og-læs involverer Agentic RAG iterative kald til LLM’en, krydret med værktøjs- eller funktionskald og strukturerede outputs. Systemet evaluerer resultater, forfiner forespørgsler, kalder yderligere værktøjer om nødvendigt og fortsætter denne cyklus, indtil en tilfredsstillende løsning er opnået.
Introduktion
Denne lektion vil dække
- Forstå Agentic RAG: Lær om det fremspirende paradigme i AI, hvor store sprogmodeller (LLMs) selvstændigt planlægger deres næste skridt, mens de trækker information fra eksterne datakilder.
- Forstå Iterativ Maker-Checker Stil: Forstå sløjfen af iterative kald til LLM, krydret med værktøjs- eller funktionskald og strukturerede outputs, designet til at forbedre korrekthed og håndtere fejlbehæftede forespørgsler.
- Udforsk Praktiske Anvendelser: Identificer scenarier hvor Agentic RAG skinner, såsom korrektheds-fokuserede miljøer, komplekse databaseinteraktioner og udvidede arbejdsgange.
Læringsmål
Efter at have gennemført denne lektion vil du vide hvordan du/forstår:
- Forståelse af Agentic RAG: Lær om det fremspirende AI-paradigme, hvor store sprogmodeller (LLMs) selvstændigt planlægger deres næste skridt, mens de trækker information fra eksterne datakilder.
- Iterativ Maker-Checker Stil: Forstå konceptet med en sløjfe af iterative kald til LLM, krydret med værktøjs- eller funktionskald og strukturerede outputs, designet til at forbedre korrekthed og håndtere fejlbehæftede forespørgsler.
- At eje ræsonneringsprocessen: Forstå systemets evne til at eje sin ræsonneringsproces og træffe beslutninger om, hvordan problemer skal angribes uden at være afhængig af foruddefinerede veje.
- Arbejdsgang: Forstå hvordan en agentisk model selvstændigt beslutter at hente markedsrapport om tendenser, identificere konkurrentdata, korrelere interne salgsdata, syntetisere fund og evaluere strategien.
- Iterative Sløjfer, Værktøjsintegration og Hukommelse: Lær om systemets afhængighed af et gentaget interaktionsmønster, der bevarer tilstand og hukommelse på tværs af skridt for at undgå gentagne sløjfer og træffe informerede beslutninger.
- Håndtering af Fejltilstande og Selvkorrektion: Udforsk systemets robuste selvkorrektionsmekanismer, herunder iteration og gensøgning, brug af diagnostiske værktøjer og fald tilbage til menneskelig overvågning.
- Grænser for Agentur: Forstå begrænsningerne for Agentic RAG med fokus på domænespecifik autonomi, infrastrukturafhængighed og respekt for sikkerhedsbarrierer.
- Praktiske Brugssager og Værdi: Identificer situationer hvor Agentic RAG udmærker sig, såsom korrektheds-først miljøer, komplekse databaseinteraktioner og udvidede arbejdsgange.
- Styring, Gennemsigtighed og Tillid: Lær om vigtigheden af styring og gennemsigtighed, inklusiv forklarbar ræsonnering, bias-kontrol og menneskelig overvågning.
Hvad er Agentic RAG?
Agentic Retrieval-Augmented Generation (Agentic RAG) er et fremspirende AI-paradigme, hvor store sprogmodeller (LLMs) selvstændigt planlægger deres næste skridt, mens de henter information fra eksterne kilder. I modsætning til statiske hent-og-læs-mønstre indebærer Agentic RAG iterative kald til LLM, krydret med værktøjs- eller funktionskald og strukturerede outputs. Systemet evaluerer resultater, forfiner forespørgsler, kalder yderligere værktøjer om nødvendigt og fortsætter denne cyklus, indtil en tilfredsstillende løsning opnås. Denne iterative “maker-checker” stil forbedrer korrekthed, håndterer fejlagtige forespørgsler og sikrer resultater af høj kvalitet.
Systemet ejer aktivt sin ræsonneringsproces, omskriver fejlede forespørgsler, vælger forskellige hentemetoder og integrerer flere værktøjer — såsom vektorsøgning i Azure AI Search, SQL-databaser eller brugerdefinerede API’er — før det færdiggør sit svar. Det karakteristiske træk ved et agentisk system er dets evne til at eje sin ræsonneringsproces. Traditionelle RAG-implementeringer er afhængige af foruddefinerede veje, men et agentisk system bestemmer selvstændigt rækkefølgen af skridt baseret på kvaliteten af den fundne information.
Definition af Agentic Retrieval-Augmented Generation (Agentic RAG)
Agentic Retrieval-Augmented Generation (Agentic RAG) er et nyt paradigme inden for AI-udvikling, hvor LLM’er ikke blot henter information fra eksterne datakilder, men også selvstændigt planlægger deres næste skridt. I modsætning til statiske hent-og-læs-mønstre eller nøje scriptede prompt-sekvenser involverer Agentic RAG en sløjfe af iterative kald til LLM, krydret med værktøjs- eller funktionskald og strukturerede outputs. Ved hvert trin evaluerer systemet de opnåede resultater, beslutter om det skal forfine sine forespørgsler, kalder eventuelt yderligere værktøjer og fortsætter denne cyklus, indtil det når en tilfredsstillende løsning.
Denne iterative “maker-checker” driftsstil er designet til at forbedre korrekthed, håndtere dårligt formede forespørgsler til strukturerede databaser (f.eks. NL2SQL) og sikre balancerede, højkvalitetsresultater. I stedet for kun at stole på nøje designede promptkæder ejer systemet aktivt sin ræsonneringsproces. Det kan omskrive fejlede forespørgsler, vælge forskellige hentemetoder og integrere flere værktøjer — såsom vektorsøgning i Azure AI Search, SQL-databaser eller brugerdefinerede API’er — før svaret færdiggøres. Dette fjerner behovet for alt for komplekse orkestreringsrammer. I stedet kan en forholdsvis simpel sløjfe “LLM-kald → værktøjsbrug → LLM-kald → …” levere sofistikerede og velunderbyggede outputs.
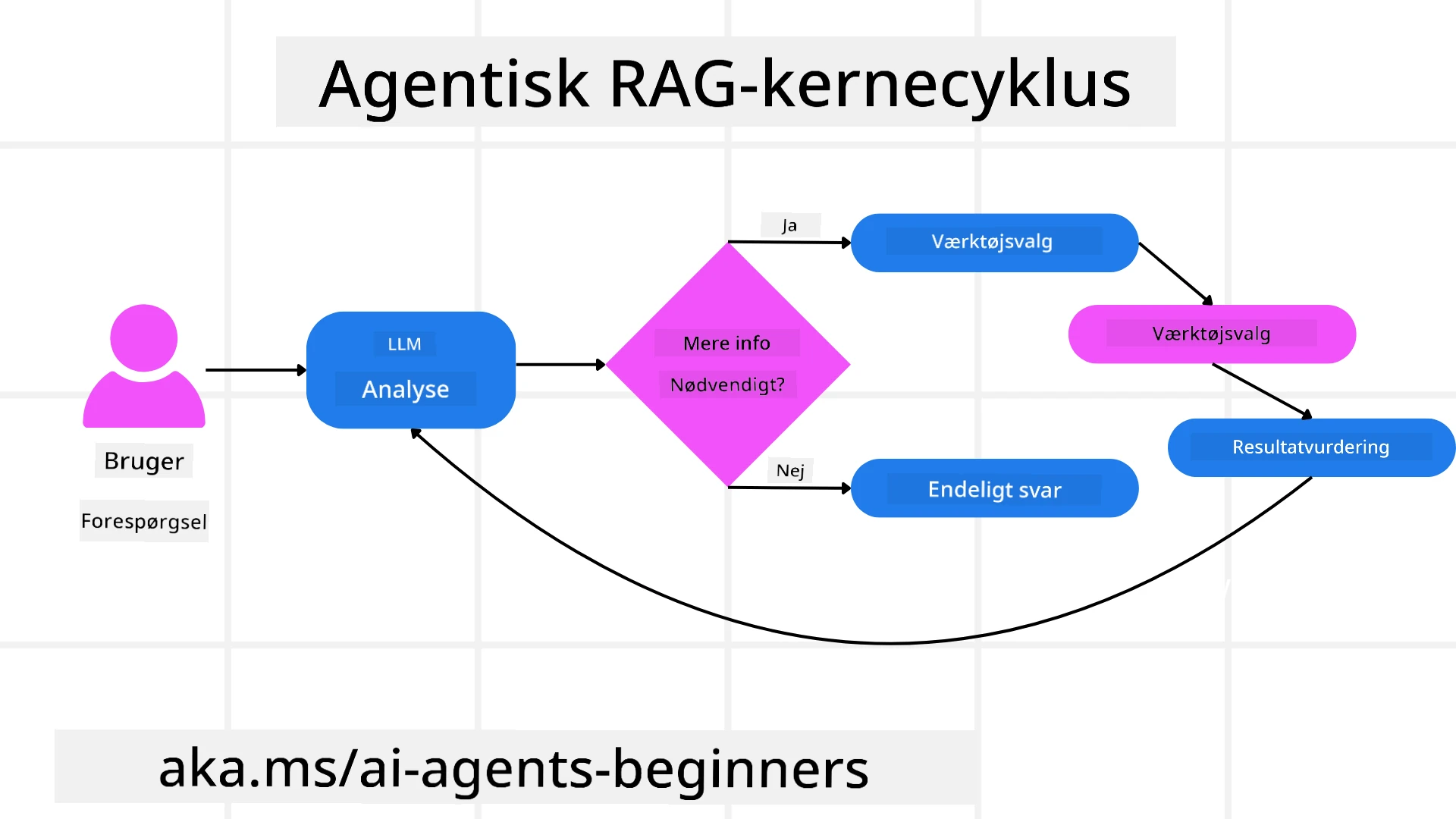
Eje Ræsonneringsprocessen
Det karakteristiske træk, der gør et system “agentisk”, er dets evne til at eje sin ræsonneringsproces. Traditionelle RAG-implementeringer afhænger ofte af, at mennesker foruddefinerer en vej for modellen: en tankekæde, der skitserer, hvad der skal hentes og hvornår. Men når et system er virkelig agentisk, bestemmer det internt, hvordan det vil angribe problemet. Det udfører ikke bare et script; det fastlægger selvstændigt rækkefølgen af skridt baseret på kvaliteten af den information, det finder. For eksempel, hvis det bliver bedt om at skabe en produktlanceringsstrategi, stoler det ikke kun på en prompt, der specificerer hele forsknings- og beslutningsprocessen. I stedet beslutter den agentiske model uafhængigt at:
- Hente aktuelle markedsrapport om tendenser ved brug af Bing Web Grounding
- Identificere relevante konkurrentdata ved brug af Azure AI Search.
- Korreler historiske interne salgsdata ved brug af Azure SQL Database.
- Syntetisere fundene til en sammenhængende strategi orkestreret via Azure OpenAI Service.
- Evaluere strategien for mangler eller inkonsistenser og om nødvendigt starte en ny runde hentning. Alle disse trin — forfining af forespørgsler, valg af kilder, iteration indtil “tilfredshed” med svaret — besluttes af modellen, ikke forudskrevet af et menneske.
Iterative Sløjfer, Værktøjsintegration og Hukommelse
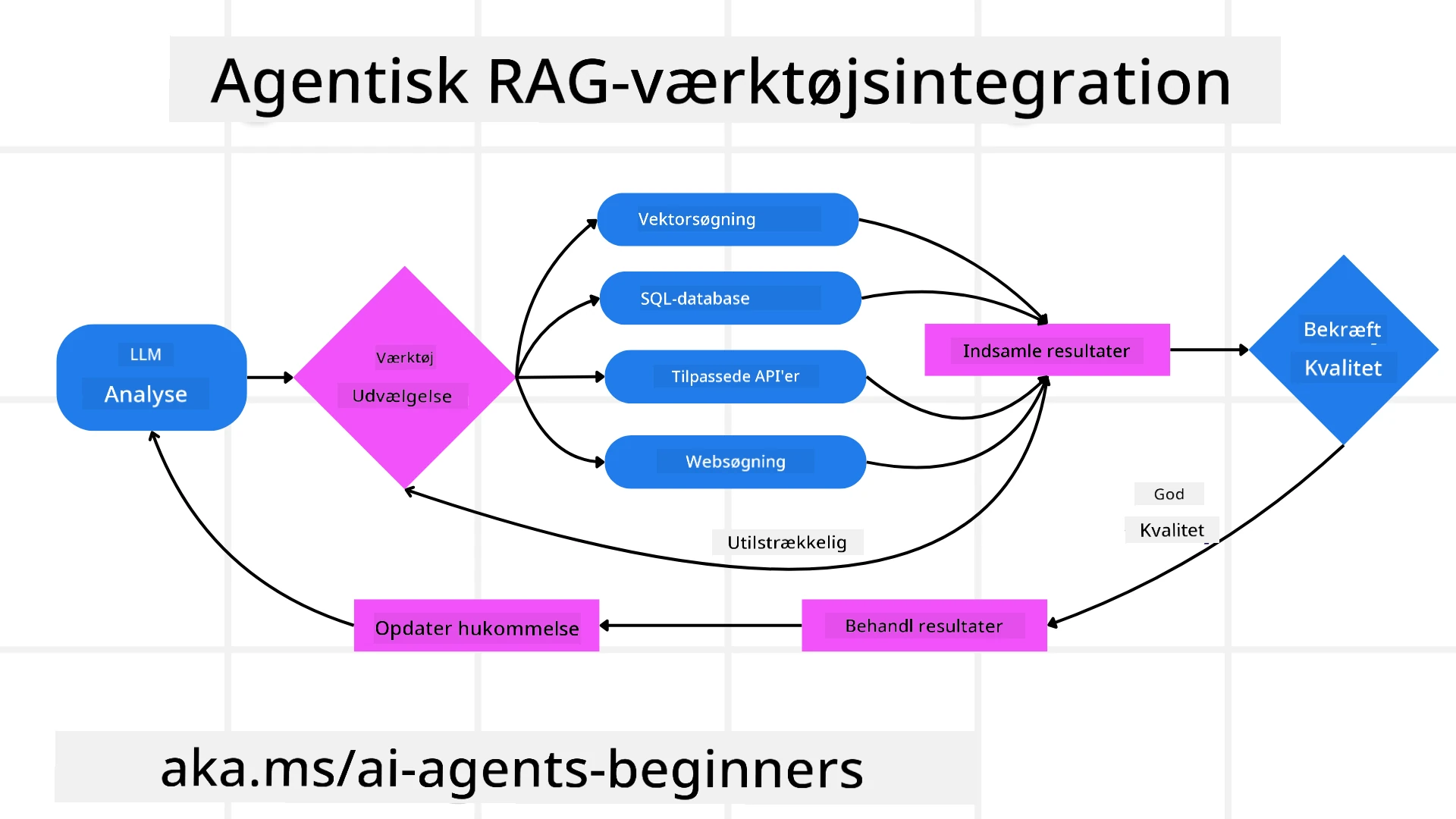
Et agentisk system bygger på et gentaget interaktionsmønster:
- Første Kald: Brugerens mål (dvs. brugerprompt) præsenteres for LLM.
- Værktøjskald: Hvis modellen identificerer manglende information eller tvetydige instruktioner, vælger den et værktøj eller en hentemetode — som en vektordatabasesspørgsmål (f.eks. Azure AI Search Hybrid-søgning over private data) eller et struktureret SQL-kald — for at indsamle mere kontekst.
- Vurdering & Forfining: Efter at have gennemgået de returnerede data afgør modellen, om informationen er tilstrækkelig. Hvis ikke, forfiner den forespørgslen, prøver et andet værktøj eller justerer sin tilgang.
- Gentag Indtil Tilfreds: Denne cyklus fortsætter, indtil modellen vurderer, at den har tilstrækkelig klarhed og beviser til at give et endeligt, velovervejet svar.
- Hukommelse & Tilstand: Fordi systemet opretholder tilstand og hukommelse gennem trinene, kan det huske tidligere forsøg og deres resultater, undgå gentagne sløjfer og træffe mere informerede beslutninger undervejs.
Over tid skaber dette en følelse af voksende forståelse, som gør modellen i stand til at navigere komplekse, flertrinsopgaver uden behov for konstant menneskelig indblanding eller omformulering af prompten.
Håndtering af Fejltilstande og Selvkorrektion
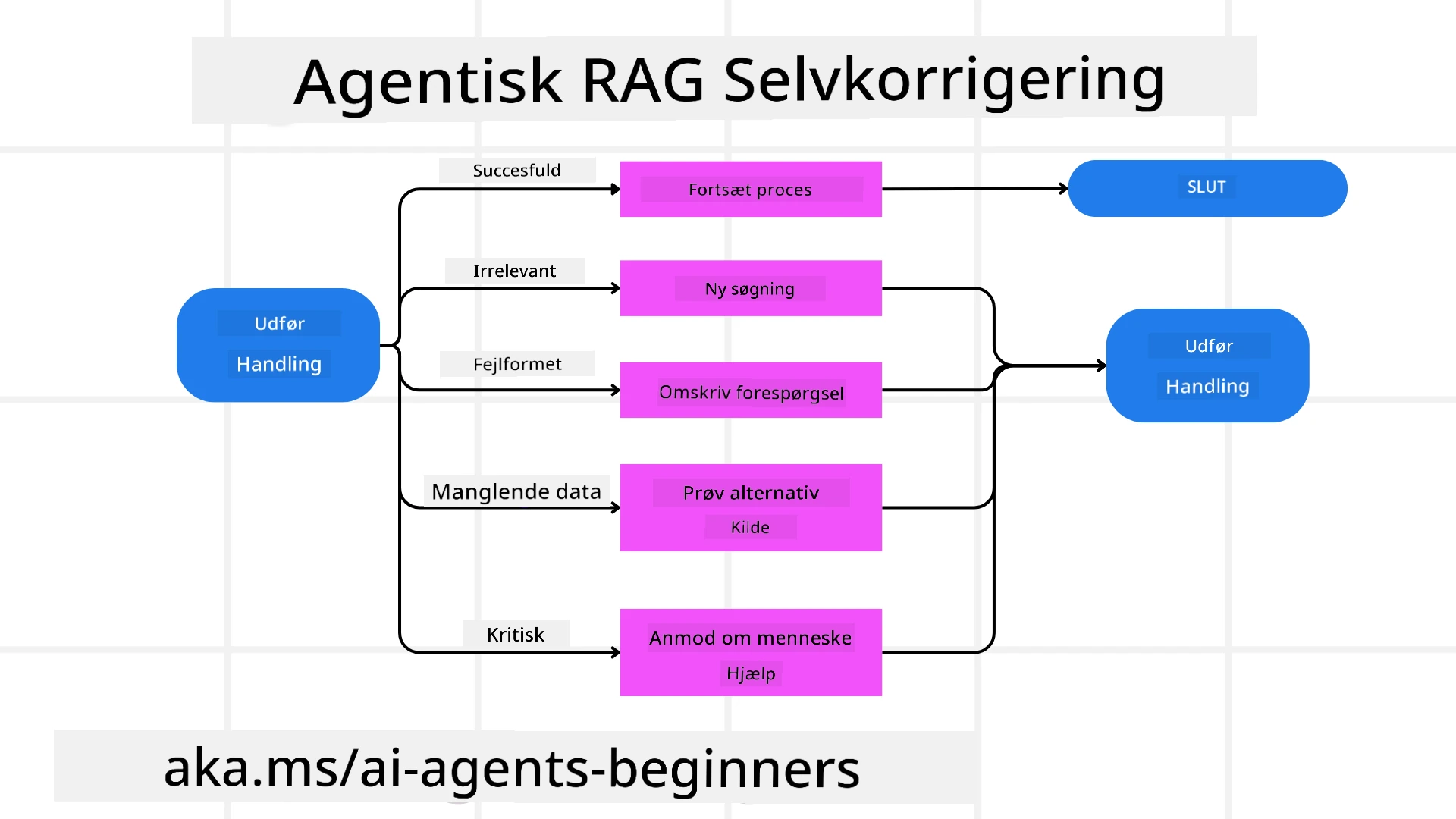
Agentic RAG’s autonomi omfatter også robuste selvkorrektionsmekanismer. Når systemet rammer blindgyder — f.eks. henter irrelevante dokumenter eller støder på fejlagtige forespørgsler — kan det:
- Iterere og Gensøge: I stedet for at returnere lavværdi svar forsøger modellen nye søgestrategier, omskriver databaseforespørgsler eller undersøger alternative datasæt.
- Brug af Diagnostiske Værktøjer: Systemet kan kalde yderligere funktioner, der hjælper med at fejlfinde sine ræsonneringstrin eller bekræfte korrektheden af hentede data. Værktøjer som Azure AI Tracing vil være vigtige for at muliggøre robust observerbarhed og overvågning.
- Fald Tilbage på Menneskelig Overvågning: Ved højest vigtige eller gentagne gange fejlede scenarier kan modellen markere usikkerhed og anmode om menneskelig vejledning. Når mennesket giver korrektiv feedback, kan modellen inkorporere denne læring fremover.
Denne iterative og dynamiske tilgang gør det muligt for modellen at forbedre sig løbende og sikrer, at det ikke blot er et en-gangs system, men et der lærer af sine fejltrin i en given session.
Grænser for Agentur
På trods af sin autonomi inden for en opgave er Agentic RAG ikke analog til Kunstig Generel Intelligens. Dets “agentiske” evner er begrænset til de værktøjer, datakilder og politikker, som er udstukket af menneskelige udviklere. Det kan ikke opfinde sine egne værktøjer eller træde uden for de domænegrænser, der er sat. Det excellerer i stedet i dynamisk orkestrering af de tilgængelige ressourcer. Nøgleforskelle fra mere avancerede AI-former omfatter:
- Domæne-Specifik Autonomi: Agentic RAG-systemer fokuserer på at opnå brugerdefinerede mål inden for et kendt domæne, hvor de anvender strategier som forespørgselsomskrivning eller værktøjsvalg for at forbedre resultater.
- Infrastrukturafhængig: Systemets evner afhænger af de værktøjer og data, som udviklerne har integreret. Det kan ikke overskride disse grænser uden menneskelig indgriben.
- Respekt for Sikkerhedsspærrer: Etiske retningslinjer, overholdelsesregler og forretningspolitikker er stadig meget vigtige. Agentens frihed er altid begrænset af sikkerhedsforanstaltninger og overvågningsmekanismer (forhåbentlig?)
Praktiske Brugssager og Værdi
Agentic RAG udmærker sig i scenarier, der kræver iterativ forfining og præcision:
- Korrektheds-Først Miljøer: Ved compliance-kontroller, regulatorisk analyse eller juridisk forskning kan den agentiske model gentagne gange verificere fakta, konsultere flere kilder og omskrive forespørgsler, indtil der frembringes et grundigt efterprøvet svar.
- Komplekse Databaseinteraktioner: Når der arbejdes med strukturerede data, hvor forespørgsler ofte kan fejle eller kræve justering, kan systemet selvstændigt forfine sine forespørgsler ved brug af Azure SQL eller Microsoft Fabric OneLake og sikre, at den endelige hentning stemmer overens med brugerens hensigt.
- Udvidede Arbejdsgange: Længerevarende sessioner kan udvikle sig, efterhånden som nye oplysninger kommer for dagen. Agentic RAG kan kontinuerligt inkorporere nye data og justere strategier efterhånden som det lærer mere om problemstillingen.
Styring, Gennemsigtighed og Tillid
Efterhånden som disse systemer bliver mere autonome i deres ræsonnering, bliver styring og gennemsigtighed afgørende:
- Forklarbar Ræsonnering: Modellen kan levere en revisionssti over de forespørgsler, den har lavet, de kilder den har konsulteret, og ræsonneringstrinene, den tog for at nå sin konklusion. Værktøjer som Azure AI Content Safety og Azure AI Tracing / GenAIOps kan hjælpe med at opretholde gennemsigtighed og mindske risici.
- Bias-Kontrol og Balanceret Hentning: Udviklere kan justere hentningsstrategier for at sikre, at balancerede og repræsentative datakilder bliver overvejet, og regelmæssigt revidere outputs for at opdage bias eller skæve mønstre ved brug af brugerdefinerede modeller til avancerede data-science organisationer med Azure Machine Learning.
- Menneskelig Overvågning og Overholdelse: Ved følsomme opgaver forbliver menneskelig gennemgang essentiel. Agentic RAG erstatter ikke menneskelig dømmekraft ved vigtige beslutninger — det understøtter ved at levere mere grundigt efterprøvede muligheder.
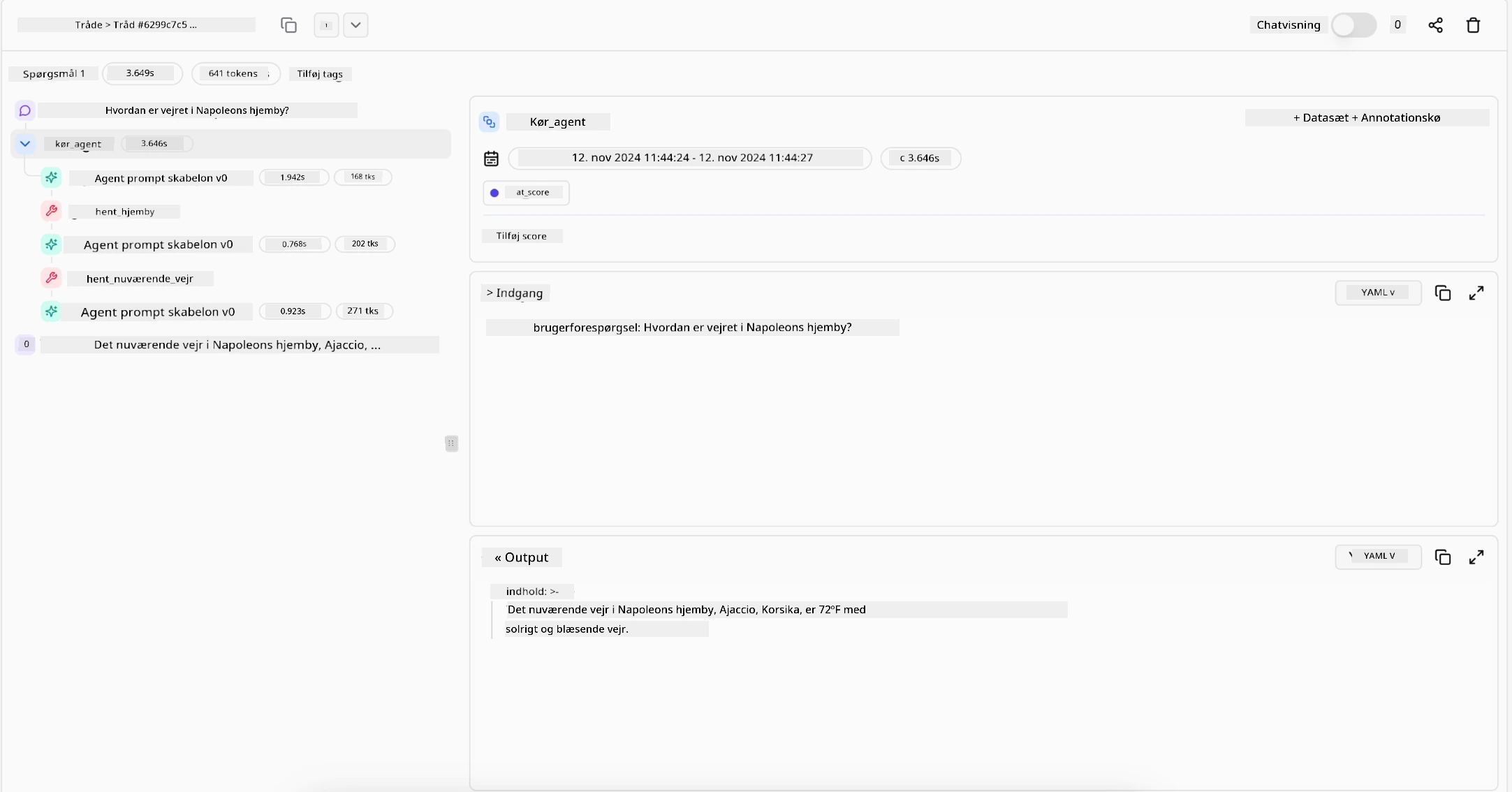
Det er essentielt at have værktøjer, der giver en klar registrering af handlinger. Uden dem kan fejlfinding af en flertrinsproces være meget vanskelig. Se følgende eksempel fra Literal AI (firmaet bag Chainlit) for en Agent-kørsel:
Konklusion
Agentic RAG repræsenterer en naturlig udvikling i, hvordan AI-systemer håndterer komplekse, dataintensive opgaver. Ved at anvende et gentaget interaktionsmønster, selvstændigt vælge værktøjer og forfine forespørgsler indtil et højkvalitetsresultat opnås, bevæger systemet sig ud over statisk prompt-efterlevelse til en mere adaptiv, kontekstbevidst beslutningstager. Selvom det stadig er begrænset af menneskedefinerede infrastrukturer og etiske retningslinjer, muliggør disse agentiske evner rigere, mere dynamiske og i sidste ende mere nyttige AI-interaktioner for både virksomheder og slutbrugere.
Har du flere spørgsmål om Agentic RAG?
Deltag i Microsoft Foundry Discord for at møde andre elever, deltage i kontortimer og få svar på dine AI-agents spørgsmål.
Yderligere Ressourcer
- Implementér Retrieval Augmented Generation (RAG) med Azure OpenAI Service: Lær, hvordan du bruger dine egne data med Azure OpenAI Service. Dette Microsoft Learn-modul giver en omfattende guide til implementering af RAG
- Evaluering af generative AI-applikationer med Microsoft Foundry: Denne artikel omhandler evaluering og sammenligning af modeller på offentligt tilgængelige datasæt, herunder Agentic AI-applikationer og RAG-arkitekturer
- Hvad er Agentic RAG | Weaviate
- Agentic RAG: En komplet guide til agentbaseret Retrieval Augmented Generation – Nyheder fra generation RAG
- Agentic RAG: turbocharge din RAG med forespørgselsreformulering og selvforespørgsel! Hugging Face Open-Source AI Cookbook
- Tilføjelse af Agentic Lag til RAG
- Fremtiden for Videnassistenter: Jerry Liu
- Sådan bygger du Agentic RAG-systemer
- Brug af Microsoft Foundry Agent Service til at skalere dine AI-agenter
Akademiske Artikler
- 2303.17651 Self-Refine: Iterativ Forfining med Selvfeedback
- 2303.11366 Reflexion: Sprogagenter med Verbal Forstærkningslæring
- 2305.11738 CRITIC: Store Sprogsmodeller Kan Selv-korrigere med Værktøjs-interaktiv Kritik
- 2501.09136 Agentic Retrieval-Augmented Generation: En Undersøgelse af Agentic RAG
Forrige Lektion
Næste Lektion
Building Trustworthy AI Agents
Ansvarsfraskrivelse: Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator. Selvom vi bestræber os på at være præcise, bedes du være opmærksom på, at automatiserede oversættelser kan indeholde fejl eller unøjagtigheder. Det oprindelige dokument på dets modersmål bør betragtes som den autoritative kilde. For kritisk information anbefales professionel menneskelig oversættelse. Vi påtager os intet ansvar for eventuelle misforståelser eller fejltolkninger, der opstår som følge af brugen af denne oversættelse.