ai-agents-for-beginners
Brug af agentiske protokoller (MCP, A2A og NLWeb)

(Klik på billedet ovenfor for at se videoen af denne lektion)
Efterhånden som brugen af AI-agenter vokser, øges også behovet for protokoller, der sikrer standardisering, sikkerhed og understøtter åben innovation. I denne lektion gennemgår vi 3 protokoller, der søger at opfylde dette behov - Model Context Protocol (MCP), Agent to Agent (A2A) og Natural Language Web (NLWeb).
Introduktion
I denne lektion gennemgår vi:
• Hvordan MCP gør det muligt for AI-agenter at få adgang til eksterne værktøjer og data for at fuldføre brugerens opgaver.
• Hvordan A2A muliggør kommunikation og samarbejde mellem forskellige AI-agenter.
• Hvordan NLWeb bringer naturlige sproggrænseflader til enhver hjemmeside, så AI-agenter kan opdage og interagere med indholdet.
Læringsmål
• Identificere kerneformålet og fordelene ved MCP, A2A og NLWeb i konteksten af AI-agenter.
• Forklare hvordan hver protokol faciliterer kommunikation og interaktion mellem LLM’er, værktøjer og andre agenter.
• Genkende de forskellige roller, hver protokol spiller i opbygningen af komplekse agentiske systemer.
Model Context Protocol
Model Context Protocol (MCP) er en åben standard, der giver en standardiseret måde for applikationer at levere kontekst og værktøjer til LLM’er. Dette muliggør en “universel adapter” til forskellige datakilder og værktøjer, som AI-agenter kan forbinde til på en konsekvent måde.
Lad os se på komponenterne i MCP, fordelene sammenlignet med direkte API-brug, og et eksempel på, hvordan AI-agenter kunne bruge en MCP-server.
MCP Core Components
MCP opererer på en klient-server-arkitektur, og kernekomponenterne er:
• Værter er LLM-applikationer (for eksempel en kodeeditor som VSCode), der starter forbindelserne til en MCP Server.
• Klienter er komponenter inden for værtapplikationen, som opretholder en-til-en-forbindelser med servere.
• Servere er letvægtsprogrammer, der eksponerer specifikke kapabiliteter.
Inde i protokollen er tre kerneprimitiver inkluderet, som er kapabiliteterne for en MCP Server:
• Værktøjer: Dette er diskrete handlinger eller funktioner, som en AI-agent kan kalde for at udføre en handling. For eksempel kan en vejrtjeneste eksponere et “get weather”-værktøj, eller en e-handelsserver kan eksponere et “purchase product”-værktøj. MCP-servere annoncerer hvert værktøjs navn, beskrivelse og input/output-skema i deres kapabilitetsliste.
• Ressourcer: Dette er skrivebeskyttede dataelementer eller dokumenter, som en MCP-server kan levere, og klienter kan hente dem efter behov. Eksempler inkluderer filindhold, databaseposter eller logfiler. Ressourcer kan være tekst (som kode eller JSON) eller binære (som billeder eller PDF’er).
• Prompter: Dette er foruddefinerede skabeloner, der giver foreslåede prompts og muliggør mere komplekse arbejdsgange.
Fordele ved MCP
MCP tilbyder betydelige fordele for AI-agenter:
• Dynamisk opdagelse af værktøjer: Agenter kan dynamisk modtage en liste over tilgængelige værktøjer fra en server sammen med beskrivelser af, hvad de gør. Dette står i kontrast til traditionelle API’er, som ofte kræver statisk kodning for integrationer, hvilket betyder, at enhver API-ændring nødvendiggør kodeopdateringer. MCP tilbyder en “integrer en gang”-tilgang, hvilket fører til større tilpasningsevne.
• Interoperabilitet på tværs af LLM’er: MCP fungerer på tværs af forskellige LLM’er og giver fleksibilitet til at skifte kernemodeller for at evaluere bedre ydeevne.
• Standardiseret sikkerhed: MCP inkluderer en standard autentificeringsmetode, hvilket forbedrer skalerbarheden ved tilføjelse af adgang til yderligere MCP-servere. Dette er enklere end at håndtere forskellige nøgler og autentificeringstyper for forskellige traditionelle API’er.
MCP Example
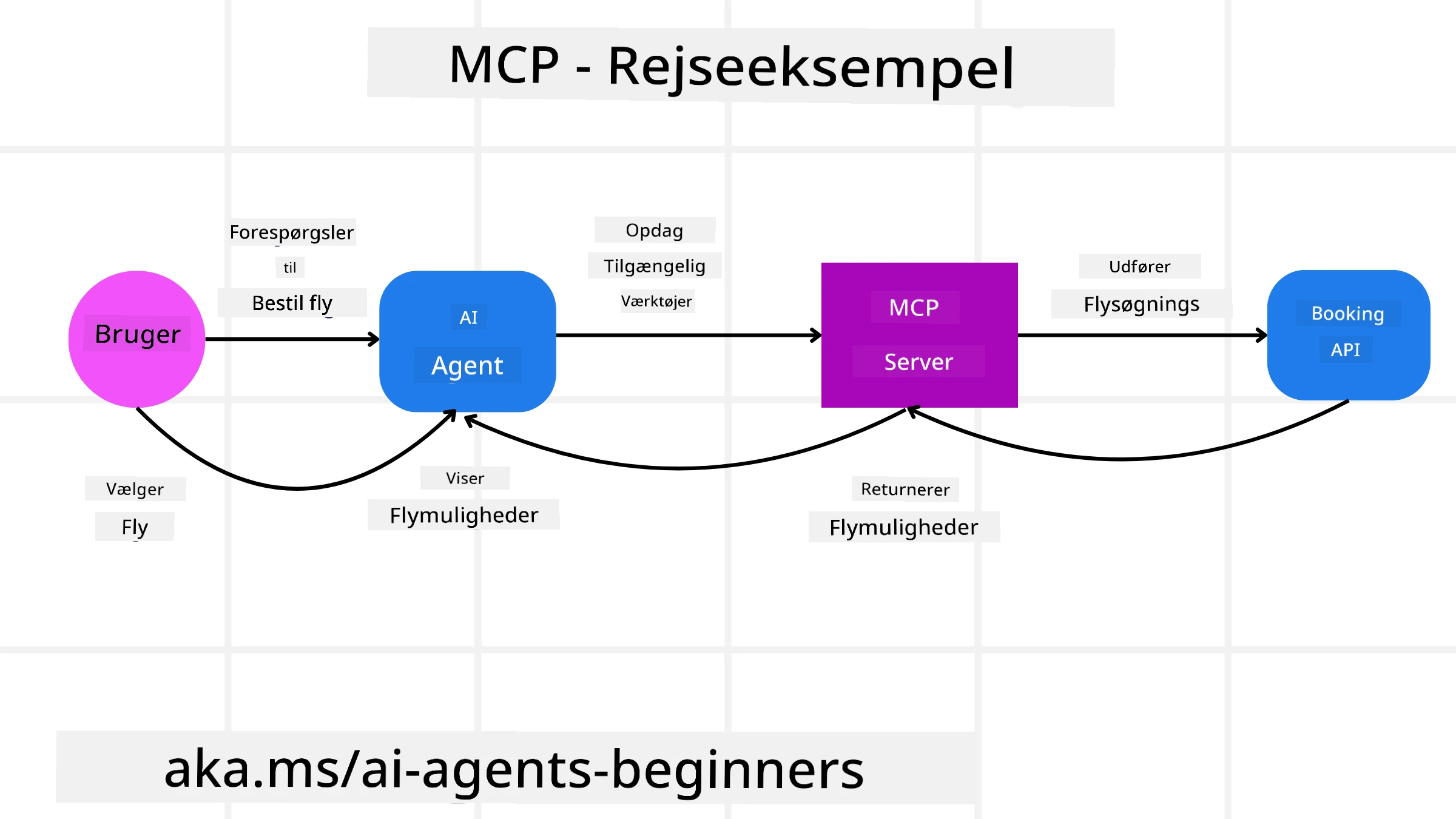
Forestil dig, at en bruger ønsker at booke en flyrejse ved hjælp af en AI-assistent drevet af MCP.
-
Forbindelse: AI-assistenten (MCP-klienten) opretter forbindelse til en MCP-server leveret af et flyselskab.
-
Opdagelse af værktøjer: Klienten spørger flyselskabets MCP-server: “Hvilke værktøjer har I tilgængelige?” Serveren svarer med værktøjer som “search flights” og “book flights”.
-
Kald af værktøj: Du beder derefter AI-assistenten: “Søg venligst efter en flyrejse fra Portland til Honolulu.” AI-assistenten, ved hjælp af sin LLM, identificerer, at den skal kalde “search flights”-værktøjet og sender de relevante parametre (afgangssted, destination) til MCP-serveren.
-
Udførelse og svar: MCP-serveren, der fungerer som en wrapper, foretager det faktiske kald til flyselskabets interne booking-API. Den modtager derefter flyoplysningerne (f.eks. JSON-data) og sender dem tilbage til AI-assistenten.
-
Yderligere interaktion: AI-assistenten præsenterer flymulighederne. Når du har valgt en flyrejse, kan assistenten kalde “book flight”-værktøjet på den samme MCP-server og fuldføre bookingen.
Agent-to-Agent Protocol (A2A)
Mens MCP fokuserer på at forbinde LLM’er til værktøjer, tager Agent-to-Agent (A2A) protokollen det et skridt videre ved at gøre det muligt for forskellige AI-agenter at kommunikere og samarbejde. A2A forbinder AI-agenter på tværs af forskellige organisationer, miljøer og teknologistakke for at fuldføre en fælles opgave.
Vi gennemgår komponenterne og fordelene ved A2A samt et eksempel på, hvordan det kunne anvendes i vores rejseapplikation.
A2A Core Components
A2A fokuserer på at muliggøre kommunikation mellem agenter og lade dem arbejde sammen om at fuldføre en underopgave for brugeren. Hver komponent i protokollen bidrager til dette:
Agentkort
Ligesom en MCP-server deler en liste over værktøjer, har et Agentkort:
- Navnet på agenten .
- En beskrivelse af de generelle opgaver den udfører.
- En liste over specifikke færdigheder med beskrivelser for at hjælpe andre agenter (eller endda menneskelige brugere) med at forstå, hvornår og hvorfor de ville ønske at kalde den agent.
- Den nuværende Endpoint URL for agenten
- Den version og funktioner af agenten såsom streaming-svar og push-notifikationer.
Agent-udfører
Agent-udføreren er ansvarlig for at videregive konteksten fra brugerchatten til den fjernagent, den fjernagent har brug for dette for at forstå den opgave, der skal udføres. På en A2A-server bruger en agent sin egen Large Language Model (LLM) til at parse indkommende anmodninger og udføre opgaver ved hjælp af sine egne interne værktøjer.
Artefakt
Når en fjernagent har fuldført den anmodede opgave, oprettes dens arbejdsprodukt som et artefakt. Et artefakt indeholder resultatet af agentens arbejde, en beskrivelse af, hvad der blev fuldført, og den tekstkontekst, der sendes gennem protokollen. Efter artefaktet er sendt, lukkes forbindelsen til den fjernagent, indtil den igen er nødvendig.
Begivenhedskø
Denne komponent bruges til at håndtere opdateringer og sende beskeder. Den er særlig vigtig i produktion for agentiske systemer for at forhindre, at forbindelsen mellem agenter lukkes, før en opgave er fuldført, især når opgavens fuldførelsestid kan tage længere tid.
Fordele ved A2A
• Forbedret samarbejde: Det gør det muligt for agenter fra forskellige leverandører og platforme at interagere, dele kontekst og arbejde sammen, hvilket letter sømløs automatisering på tværs af traditionelt adskilte systemer.
• Fleksibilitet i valg af model: Hver A2A-agent kan beslutte, hvilken LLM den bruger til at servicere sine forespørgsler, hvilket tillader optimerede eller finjusterede modeller pr. agent, i modsætning til en enkelt LLM-forbindelse i nogle MCP-scenarier.
• Indbygget autentificering: Autentificering er integreret direkte i A2A-protokollen og giver en robust sikkerhedsramme for agentinteraktioner.
A2A Example
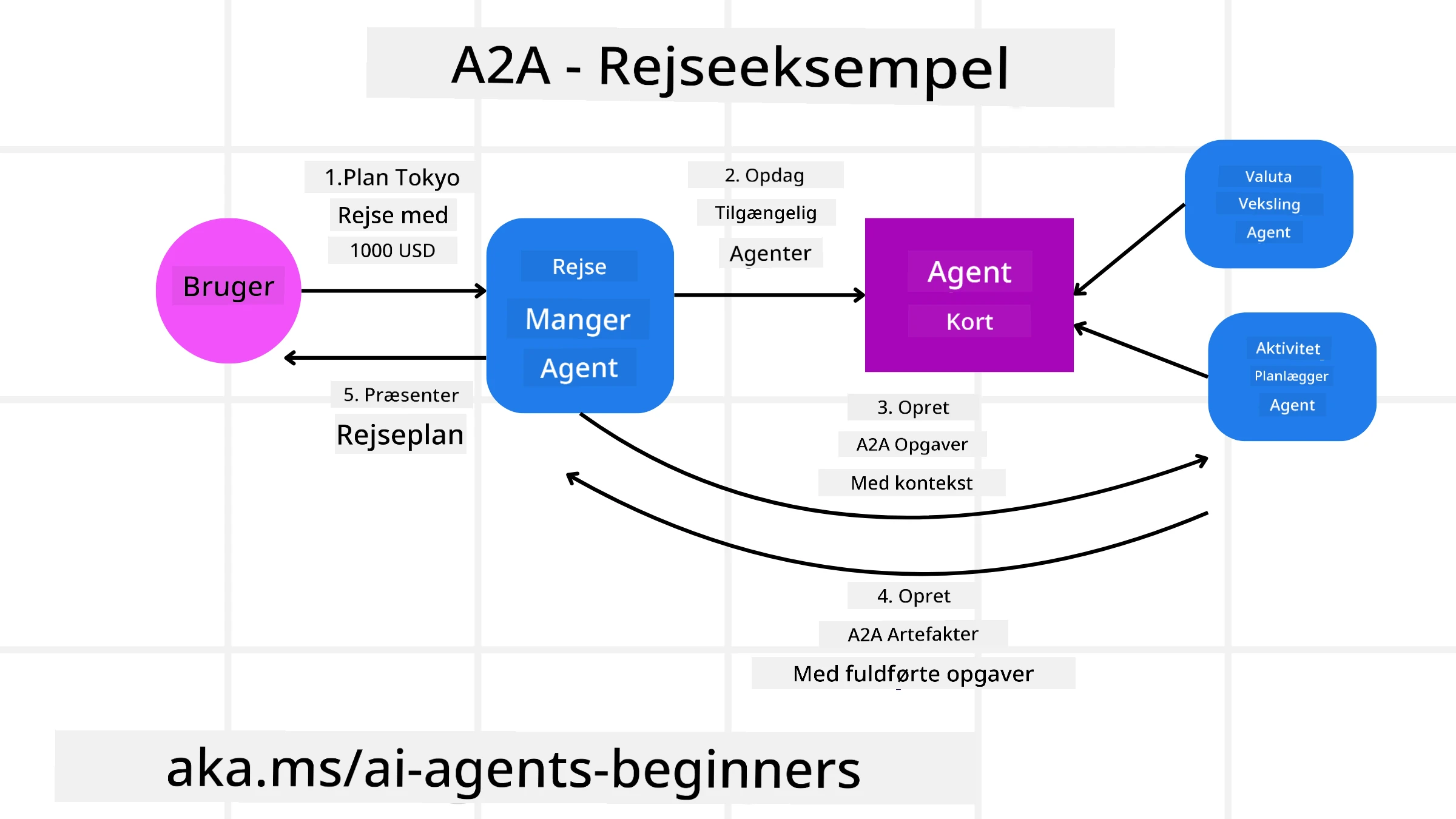
Lad os udbygge vores rejsebookingsscenario, men denne gang ved hjælp af A2A.
-
Brugerens anmodning til multi-agent: En bruger interagerer med en “Travel Agent” A2A-klient/agent, måske ved at sige: “Book venligst en hel rejse til Honolulu i næste uge, inklusive fly, hotel og lejebil”.
-
Orkestrering af rejseagenten: Rejseagenten modtager denne komplekse anmodning. Den bruger sin LLM til at ræsonnere om opgaven og afgøre, at den skal interagere med andre specialiserede agenter.
-
Inter-agent kommunikation: Rejseagenten bruger derefter A2A-protokollen til at forbinde til downstream-agenter, såsom en “Airline Agent”, en “Hotel Agent” og en “Car Rental Agent”, der er oprettet af forskellige virksomheder.
-
Delegeret opgaveudførelse: Rejseagenten sender specifikke opgaver til disse specialiserede agenter (f.eks. “Find flights to Honolulu”, “Book a hotel”, “Rent a car”). Hver af disse specialiserede agenter, der kører deres egne LLM’er og bruger deres egne værktøjer (som i sig selv kunne være MCP-servere), udfører deres specifikke del af bookingen.
-
Konsolideret svar: Når alle downstream-agenter har fuldført deres opgaver, samler rejseagenten resultaterne (flyoplysninger, hotelbekræftelse, lejebilreservation) og sender et omfattende, chat-lignende svar tilbage til brugeren.
Natural Language Web (NLWeb)
Websteder har længe været den primære måde for brugere at få adgang til information og data på internettet.
Lad os se på de forskellige komponenter i NLWeb, fordelene ved NLWeb og et eksempel på, hvordan vores NLWeb fungerer ved at kigge på vores rejseapplikation.
Komponenter i NLWeb
-
NLWeb Application (Core Service Code): Systemet, der behandler spørgsmål i naturligt sprog. Det forbinder de forskellige dele af platformen for at skabe svar. Du kan tænke på det som motoren, der driver de naturlige sprogfunktioner på en hjemmeside.
-
NLWeb Protocol: Dette er et basisk sæt regler for naturlig sproginteraktion med en hjemmeside. Det sender svar tilbage i JSON-format (ofte ved hjælp af Schema.org). Dets formål er at skabe et simpelt fundament for “AI Web”, på samme måde som HTML gjorde det muligt at dele dokumenter online.
-
MCP Server (Model Context Protocol Endpoint): Hver NLWeb-opsætning fungerer også som en MCP-server. Det betyder, at den kan dele værktøjer (som en “ask”-metode) og data med andre AI-systemer. I praksis gør dette hjemmesidens indhold og evner brugbare for AI-agenter og gør sitet til en del af det bredere “agent-økosystem”.
-
Embedding Models: Disse modeller bruges til at konvertere hjemmesideindhold til numeriske repræsentationer kaldet vektorer (embeddings). Disse vektorer indfanger betydning på en måde, som computere kan sammenligne og søge i. De gemmes i en specialdatabase, og brugere kan vælge, hvilken embedding-model de vil bruge.
-
Vector Database (Retrieval Mechanism): Denne database gemmer embeddingene af hjemmesideindholdet. Når nogen stiller et spørgsmål, tjekker NLWeb vektordatabasen for hurtigt at finde den mest relevante information. Den giver en hurtig liste over mulige svar, rangeret efter lighed. NLWeb fungerer med forskellige vektorlager-systemer såsom Qdrant, Snowflake, Milvus, Azure AI Search og Elasticsearch.
NLWeb ved eksempel
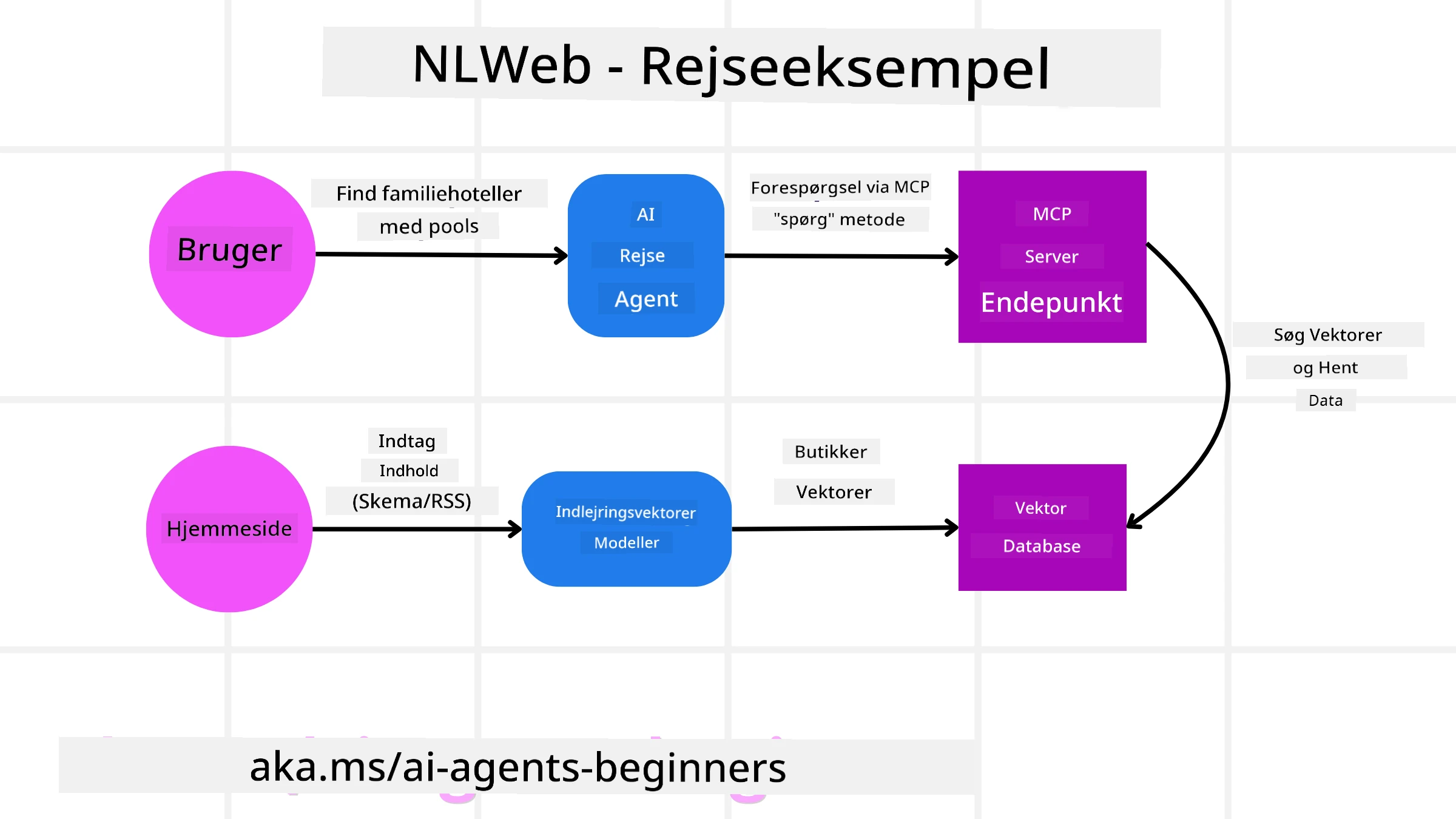
Overvej igen vores rejsebookingshjemmeside, men denne gang er den drevet af NLWeb.
-
Dataindsamling: Rejsewebstedets eksisterende produktkataloger (f.eks. flylister, hotelbeskrivelser, udflugts-pakker) formateres ved hjælp af Schema.org eller indlæses via RSS-feeds. NLWebs værktøjer indtager disse strukturerede data, opretter embeddings og gemmer dem i en lokal eller fjern vektordatabase.
-
Forespørgsel i naturligt sprog (menneske): En bruger besøger hjemmesiden og skriver i stedet for at navigere i menuer i en chatgrænseflade: “Find mig et familievenligt hotel i Honolulu med pool til næste uge”.
-
NLWeb-behandling: NLWeb-applikationen modtager denne forespørgsel. Den sender forespørgslen til en LLM for forståelse og søger samtidig i sin vektordatabase efter relevante hotelopslag.
-
Præcise resultater: LLM’en hjælper med at fortolke søgeresultaterne fra databasen, identificere de bedste match baseret på kriterierne “familievenligt”, “pool” og “Honolulu”, og formatterer derefter et svar i naturligt sprog. Vigtigt er det, at svaret henviser til faktiske hoteller fra webstedets katalog og undgår opdigtede oplysninger.
-
AI-agent-interaktion: Fordi NLWeb fungerer som en MCP-server, kunne en ekstern AI-rejseagent også oprette forbindelse til denne hjemmesides NLWeb-instans. AI-agenten kunne så bruge
ask("Are there any vegan-friendly restaurants in the Honolulu area recommended by the hotel?"). NLWeb-instansen ville behandle dette, udnytte sin database af restaurantinformation (hvis den er indlæst) og returnere et struktureret JSON-svar.
Har du flere spørgsmål om MCP/A2A/NLWeb?
Deltag i Microsoft Foundry Discord for at mødes med andre lærende, deltage i kontortimer og få svar på dine spørgsmål om AI-agenter.
Ressourcer
Ansvarsfraskrivelse: Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator (https://github.com/Azure/co-op-translator). Selvom vi stræber efter nøjagtighed, skal du være opmærksom på, at automatiserede oversættelser kan indeholde fejl eller unøjagtigheder. Det oprindelige dokument på originalsproget bør betragtes som den autoritative kilde. For kritiske oplysninger anbefales professionel menneskelig oversættelse. Vi påtager os intet ansvar for misforståelser eller fejltolkninger, der måtte opstå som følge af brugen af denne oversættelse.