ai-agents-for-beginners
Kontekstengineering for AI-agenter

(Klik på billedet ovenfor for at se videoen af denne lektion)
At forstå kompleksiteten i den applikation, du bygger en AI-agent til, er vigtigt for at skabe en pålidelig en. Vi skal bygge AI-agenter, der effektivt håndterer information for at imødekomme komplekse behov ud over prompt engineering.
I denne lektion vil vi se på, hvad kontekstengineering er, og hvilken rolle det spiller i opbygningen af AI-agenter.
Introduktion
Denne lektion vil dække:
• Hvad kontekstengineering er og hvorfor det adskiller sig fra prompt engineering.
• Strategier for effektiv kontekstengineering, herunder hvordan man skriver, vælger, komprimerer og isolerer information.
• Almindelige kontekstfejl der kan afspore din AI-agent, og hvordan man retter dem.
Læringsmål
Efter at have gennemført denne lektion vil du forstå hvordan du:
• Definerer kontekstengineering og skelner det fra prompt engineering.
• Identificerer nøglekomponenterne i kontekst i applikationer med store sprogmodeller (LLM).
• Anvender strategier til at skrive, vælge, komprimere og isolere kontekst for at forbedre agentens ydeevne.
• Genkender almindelige kontekstfejl såsom forurening, distraktion, forvirring og konflikt, og implementerer afbødningsteknikker.
Hvad er kontekstengineering?
For AI-agenter er kontekst det, der driver planlægningen af en AI-agent til at tage bestemte handlinger. Kontekstengineering er praksissen med at sikre, at AI-agenten har de rigtige oplysninger for at fuldføre næste trin i opgaven. Kontekstvinduet er begrænset i størrelse, så som agentbygger skal vi opbygge systemer og processer til at styre tilføjelse, fjernelse og kondensering af informationen i kontekstvinduet.
Prompt Engineering vs Kontekstengineering
Prompt engineering er fokuseret på et enkelt sæt statiske instruktioner for effektivt at styre AI-agenter med et regelsæt. Kontekstengineering handler om, hvordan man håndterer et dynamisk sæt oplysninger, inklusive den indledende prompt, for at sikre, at AI-agenten har det, den har brug for over tid. Hovedideen omkring kontekstengineering er at gøre denne proces gentagelig og pålidelig.
Typer af kontekst
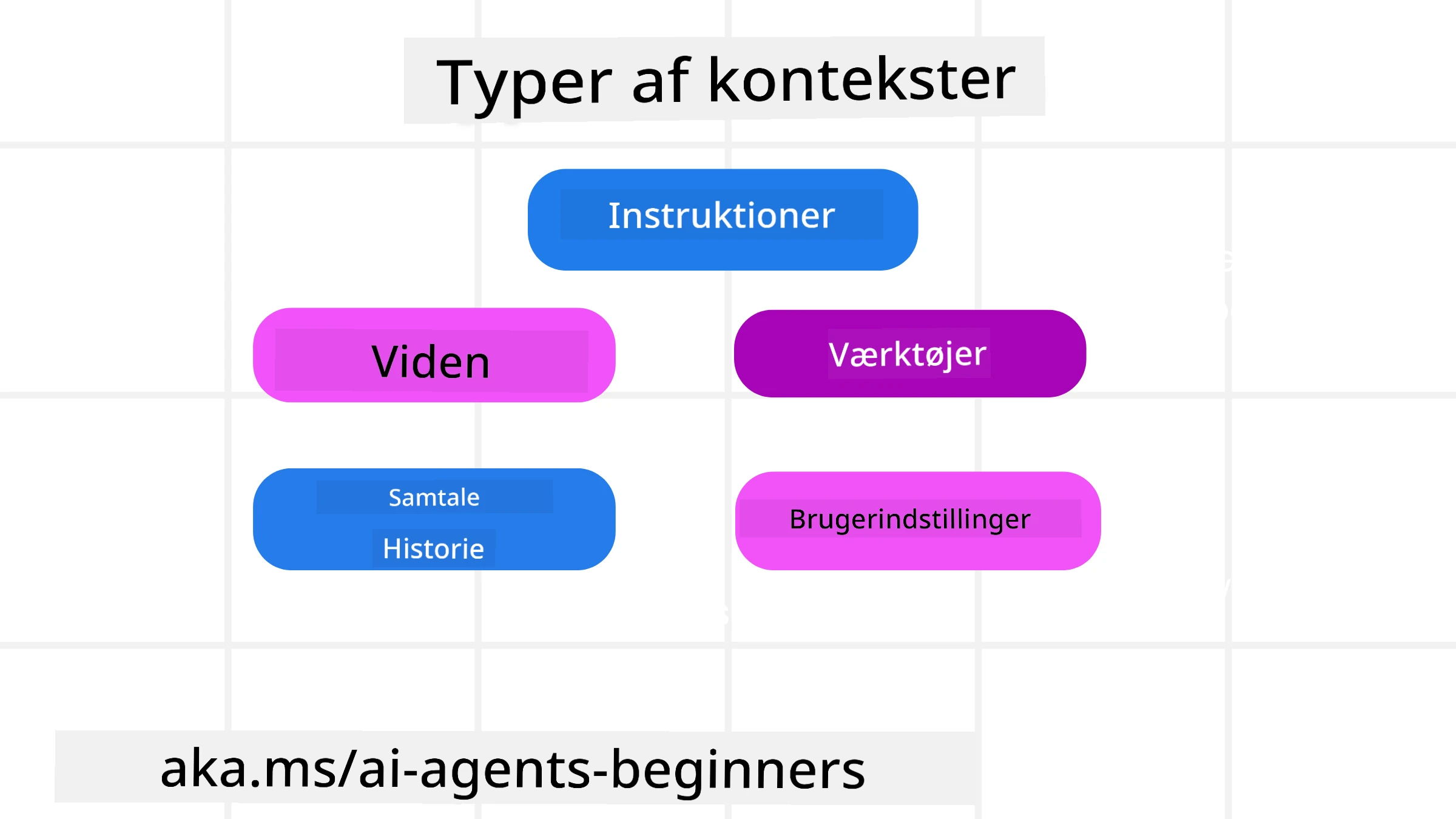
Det er vigtigt at huske, at kontekst ikke kun er én ting. De oplysninger, som AI-agenten har brug for, kan komme fra mange forskellige kilder, og det er op til os at sikre, at agenten har adgang til disse kilder:
De typer kontekst, en AI-agent kan have brug for at håndtere, inkluderer:
• Instruktioner: Dette er som agentens “regler” – prompts, systembeskeder, few-shot-eksempler (der viser AI’en, hvordan man gør noget) og beskrivelser af værktøjer, den kan bruge. Her kombinerer fokusset fra prompt engineering sig med kontekstengineering.
• Viden: Dette dækker fakta, information hentet fra databaser eller langtidsminder, som agenten har akkumuleret. Dette inkluderer integration af et Retrieval Augmented Generation (RAG)-system, hvis en agent har brug for adgang til forskellige videnslager og databaser.
• Værktøjer: Dette er definitioner af eksterne funktioner, API’er og MCP-servere, som agenten kan kalde, sammen med den feedback (resultater), den får ved at bruge dem.
• Samtalehistorik: Den løbende dialog med en bruger. Med tiden bliver disse samtaler længere og mere komplekse, hvilket betyder, at de optager plads i kontekstvinduet.
• Brugerpræferencer: Oplysninger, der er lært om en brugers præferencer over tid. Disse kan gemmes og blive brugt, når der træffes vigtige beslutninger for at hjælpe brugeren.
Strategier for effektiv kontekstengineering
Planlægningsstrategier
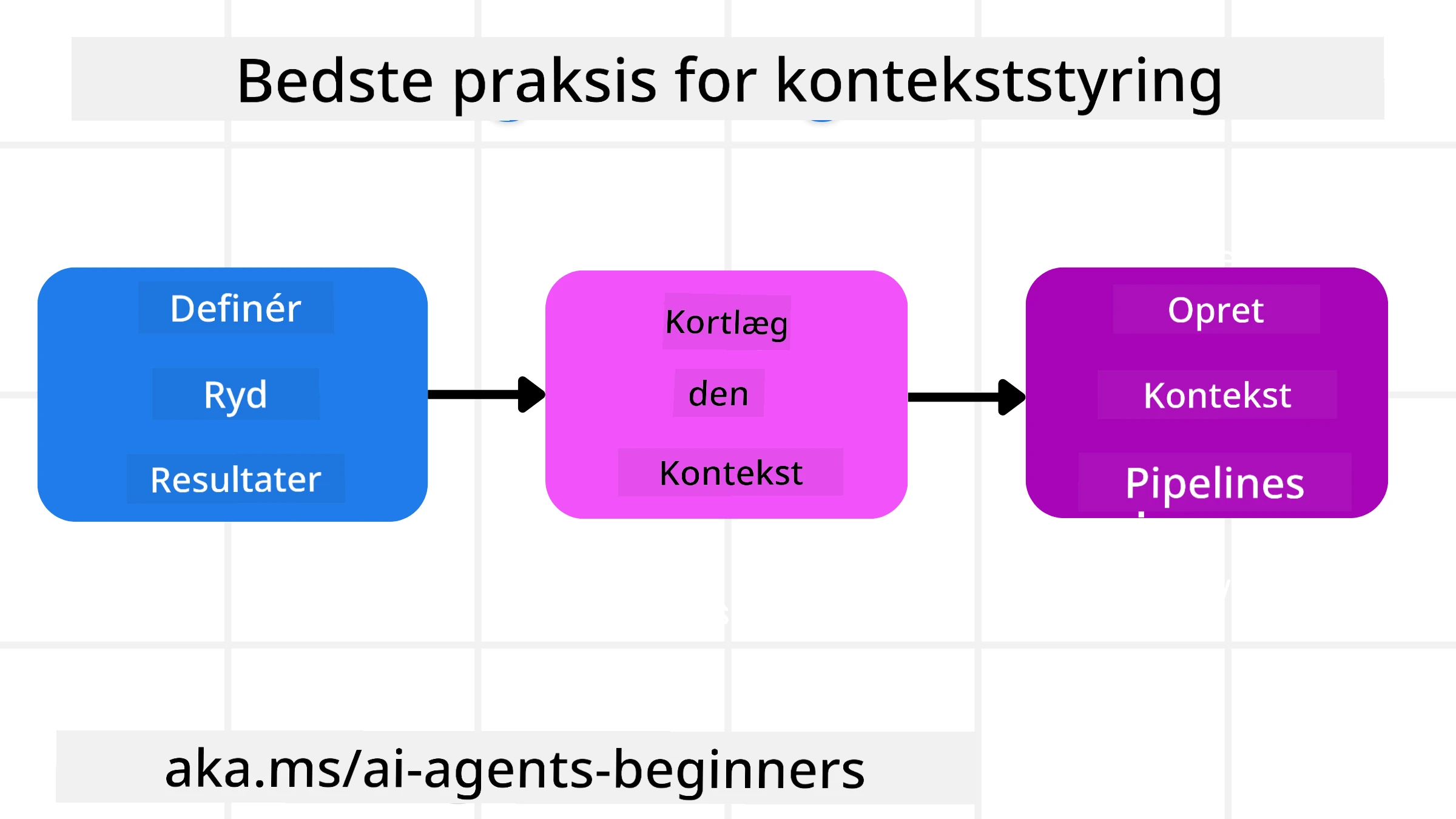
God kontekstengineering starter med god planlægning. Her er en tilgang, der hjælper dig med at begynde at tænke over, hvordan du anvender begrebet kontekstengineering:
- Definer klare resultater - Resultaterne af de opgaver, som AI-agenterne skal have, bør være klart definerede. Svar på spørgsmålet - “Hvordan vil verden se ud, når AI-agenten er færdig med sin opgave?” Med andre ord, hvilken ændring, information eller respons bør brugeren have efter at have interageret med AI-agenten.
- Kortlæg konteksten - Når du har defineret agentens resultater, skal du svare på spørgsmålet “Hvilke informationer har AI-agenten brug for for at fuldføre denne opgave?”. På den måde kan du begynde at kortlægge, hvor den information kan findes.
- Opret kontekstpipelines - Nu hvor du ved, hvor informationen er, skal du svare på spørgsmålet “Hvordan vil agenten få denne information?”. Dette kan gøres på forskellige måder, herunder RAG, brug af MCP-servere og andre værktøjer.
Praktiske strategier
Planlægning er vigtig, men når informationen begynder at flyde ind i vores agents kontekstvindue, har vi brug for praktiske strategier til at håndtere det:
Håndtering af kontekst
Selvom noget information automatisk vil blive tilføjet til kontekstvinduet, handler kontekstengineering om at tage en mere aktiv rolle i håndteringen af denne information, hvilket kan gøres ved nogle strategier:
-
Agentens skriveredskab Dette tillader en AI-agent at notere relevante oplysninger om de aktuelle opgaver og brugerinteraktioner i løbet af en enkelt session. Dette bør eksistere uden for kontekstvinduet i en fil eller et runtime-objekt, som agenten senere kan hente under denne session, hvis det er nødvendigt.
-
Minder Skriveredskaber er gode til at håndtere information uden for kontekstvinduet i en enkelt session. Minder gør det muligt for agenter at gemme og hente relevante oplysninger på tværs af flere sessioner. Dette kunne inkludere sammenfatninger, brugerpræferencer og feedback til forbedringer i fremtiden.
-
Kompressering af kontekst Når kontekstvinduet vokser og nærmer sig sin grænse, kan teknikker som opsummering og beskæring bruges. Dette inkluderer enten at beholde kun den mest relevante information eller fjerne ældre beskeder.
-
Multi-agent systemer At udvikle multi-agent systemer er en form for kontekstengineering, fordi hver agent har sit eget kontekstvindue. Hvordan denne kontekst deles og overføres til forskellige agenter er en anden ting at planlægge, når man bygger disse systemer.
-
Sandkassemiljøer Hvis en agent skal køre noget kode eller behandle store mængder information i et dokument, kan dette kræve mange tokens for at behandle resultaterne. I stedet for at have alt dette gemt i kontekstvinduet, kan agenten bruge et sandkassemiljø, der kan køre denne kode og kun læse resultaterne og anden relevant information.
-
Runtime-tilstandsobjekter Dette gøres ved at oprette containere med information for at håndtere situationer, hvor agenten har brug for adgang til bestemte oplysninger. For en kompleks opgave vil dette gøre det muligt for en agent at gemme resultaterne af hver delopgave trin for trin, så konteksten forbliver knyttet kun til den specifikke delopgave.
Eksempel på kontekstengineering
Lad os sige, at vi vil have en AI-agent til at “Booke mig en tur til Paris.”
• En simpel agent, der kun bruger prompt engineering, kunne blot svare: “Okay, hvornår vil du gerne tage til Paris?”. Den behandlede kun dit direkte spørgsmål på det tidspunkt, hvor brugeren spurgte.
• En agent, der bruger de kontekstengineering-strategier, der er gennemgået, ville gøre meget mere. Før den overhovedet svarer, kunne dens system for eksempel:
◦ Tjekke din kalender for ledige datoer (hentning af realtidsdata).
◦ Hente tidligere rejsepræferencer (fra langtidsminder) som dit foretrukne flyselskab, budget eller om du foretrækker direkte fly.
◦ Identificere tilgængelige værktøjer til fly- og hotelreservation.
- Så kunne et eksempel på et svar være: “Hej [Dit navn]! Jeg kan se, at du er fri den første uge i oktober. Skal jeg kigge efter direkte fly til Paris med [Foretrukket flyselskab] inden for dit sædvanlige [Budget]?”. Dette rigere, kontekstbevidste svar demonstrerer kraften i kontekstengineering.
Almindelige kontekstfejl
Kontekstforurening
Hvad det er: Når en hallucination (falsk information genereret af LLM’en) eller en fejl kommer ind i konteksten og gentagne gange refereres til, hvilket får agenten til at forfølge umulige mål eller udvikle meningsløse strategier.
Hvad man kan gøre: Implementer kontekstvalidering og karantæne. Valider information, før den tilføjes til langtidsminder. Hvis potentiel forurening opdages, start nye konteksttråde for at forhindre, at den dårlige information spreder sig.
Eksempel på rejsebooking: Din agent hallucinerer en direkte flyvning fra en lille lokal lufthavn til en fjern international by, som faktisk ikke tilbyder internationale flyvninger. Dette ikke-eksisterende flyoplysning bliver gemt i konteksten. Senere, når du beder agenten om at booke, bliver den ved med at forsøge at finde billetter til denne umulige rute, hvilket fører til gentagne fejl.
Løsning: Implementer et trin, der validerer flyets eksistens og ruter med en realtids-API før flyoplysningen tilføjes til agentens arbejdskontekst. Hvis valideringen fejler, bliver den fejlagtige information “karantæneret” og ikke brugt videre.
Kontekstdistraktion
Hvad det er: Når konteksten bliver så stor, at modellen fokuserer for meget på den akkumulerede historik i stedet for at bruge det, den lærte under træningen, hvilket fører til gentagne eller ubrugelige handlinger. Modeller kan begynde at lave fejl, selv før kontekstvinduet er fuldt.
Hvad man kan gøre: Brug kontekstsammenfatning. Periodisk komprimeres akkumulerede oplysninger til kortere sammenfatninger, der bevarer vigtige detaljer og fjerner redundant historik. Dette hjælper med at “nulstille” fokus.
Eksempel på rejsebooking: Du har i lang tid diskuteret forskellige drømmerejsedestinationer, inklusive en detaljeret genfortælling af din rygsækrejse for to år siden. Når du endelig beder om at “finde mig en billig flyvning til næste måned”, bliver agenten fanget i de gamle, irrelevante detaljer og bliver ved med at spørge om dit rygsæksudstyr eller tidligere rejseplaner og forsømmer din aktuelle anmodning.
Løsning: Efter et vist antal vendinger eller når konteksten vokser for stor, bør agenten opsummere de mest nylige og relevante dele af samtalen – med fokus på dine aktuelle rejsedatoer og destination – og bruge denne kondenserede sammenfatning til det næste LLM-opkald, mens den mindre relevante historik kasseres.
Kontekstforvirring
Hvad det er: Når unødvendig kontekst, ofte i form af for mange tilgængelige værktøjer, får modellen til at generere dårlige svar eller kalde irrelevante værktøjer. Mindre modeller er især udsatte for dette.
Hvad man kan gøre: Implementer styring af værktøjsudvalg ved hjælp af RAG-teknikker. Gem værktøjsbeskrivelser i en vektordatabase og vælg kun de mest relevante værktøjer til hver specifik opgave. Forskning viser, at det hjælper at begrænse værktøjsvalget til færre end 30.
Eksempel på rejsebooking: Din agent har adgang til dusinvis af værktøjer: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, osv. Du spørger, “Hvad er den bedste måde at komme rundt i Paris på?” På grund af det store antal værktøjer bliver agenten forvirret og forsøger at kalde book_flight inden for Paris, eller rent_car selvom du foretrækker offentlig transport, fordi værktøjsbeskrivelserne kan overlappe, eller den simpelthen ikke kan afgøre det bedste valg.
Løsning: Brug RAG over værktøjsbeskrivelser. Når du spørger om at komme rundt i Paris, henter systemet dynamisk kun de mest relevante værktøjer som rent_car eller public_transport_info baseret på din forespørgsel og præsenterer et fokuseret “loadout” af værktøjer til LLM’en.
Konkststkonflikt
(Note: The heading above in the original is “Context Clash” — ensure correct translation) Oops — I must ensure not to introduce new errors. The heading should be “Konkurrence om kontekst” or “Kontekstkonflikt”. Replace with “Kontekstkonflikt”. I’ll continue the correction in final answer.
Ansvarsfraskrivelse: Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator. Selvom vi bestræber os på nøjagtighed, skal du være opmærksom på, at automatiske oversættelser kan indeholde fejl eller unøjagtigheder. Det oprindelige dokument på dets oprindelige sprog bør betragtes som den autoritative kilde. For kritisk information anbefales en professionel menneskelig oversættelse. Vi hæfter ikke for misforståelser eller fejltolkninger, der opstår som følge af brugen af denne oversættelse.