ai-agents-for-beginners
Kontext-Engineering für KI-Agenten

(Klicken Sie auf das obige Bild, um das Video zu dieser Lektion anzusehen)
Das Verständnis der Komplexität der Anwendung, für die Sie einen KI-Agenten bauen, ist wichtig, um einen zuverlässigen Agenten zu erstellen. Wir müssen KI-Agenten entwickeln, die Informationen effektiv verwalten, um komplexe Anforderungen über Prompt-Engineering hinaus zu erfüllen.
In dieser Lektion betrachten wir, was Kontext-Engineering ist und welche Rolle es beim Aufbau von KI-Agenten spielt.
Einführung
Diese Lektion behandelt:
• Was Kontext-Engineering ist und warum es sich vom Prompt-Engineering unterscheidet.
• Strategien für effektives Kontext-Engineering, einschließlich wie man Informationen schreibt, auswählt, komprimiert und isoliert.
• Häufige Kontextfehler, die Ihren KI-Agenten entgleisen lassen können, und wie man sie behebt.
Lernziele
Nach Abschluss dieser Lektion werden Sie verstehen, wie man:
• Kontext-Engineering definiert und es vom Prompt-Engineering unterscheidet.
• Die wichtigsten Komponenten des Kontexts in Anwendungen mit Large Language Models (LLMs) identifiziert.
• Strategien zum Schreiben, Auswählen, Komprimieren und Isolieren von Kontext anwendet, um die Leistung von Agenten zu verbessern.
• Häufige Kontextfehler wie Poisoning, Ablenkung, Verwirrung und Konflikte erkennt und Gegenmaßnahmen implementiert.
Was ist Kontext-Engineering?
Für KI-Agenten ist Kontext das, was die Planung eines KI-Agenten antreibt, bestimmte Aktionen durchzuführen. Kontext-Engineering ist die Praxis sicherzustellen, dass der KI-Agent die richtigen Informationen hat, um den nächsten Schritt der Aufgabe abzuschließen. Das Kontextfenster ist in der Größe begrenzt, daher müssen wir als Agentenentwickler Systeme und Prozesse entwickeln, um Informationen in das Kontextfenster hinzuzufügen, zu entfernen und zu kondensieren.
Prompt-Engineering vs Kontext-Engineering
Prompt-Engineering konzentriert sich auf eine einzelne Menge statischer Anweisungen, um die KI-Agenten effektiv mit einem Regelwerk zu steuern. Kontext-Engineering befasst sich damit, wie man eine dynamische Menge an Informationen verwaltet, einschließlich des Initialprompts, um sicherzustellen, dass der KI-Agent im Zeitverlauf hat, was er braucht. Die Hauptidee des Kontext-Engineerings ist, diesen Prozess wiederholbar und zuverlässig zu gestalten.
Arten von Kontext
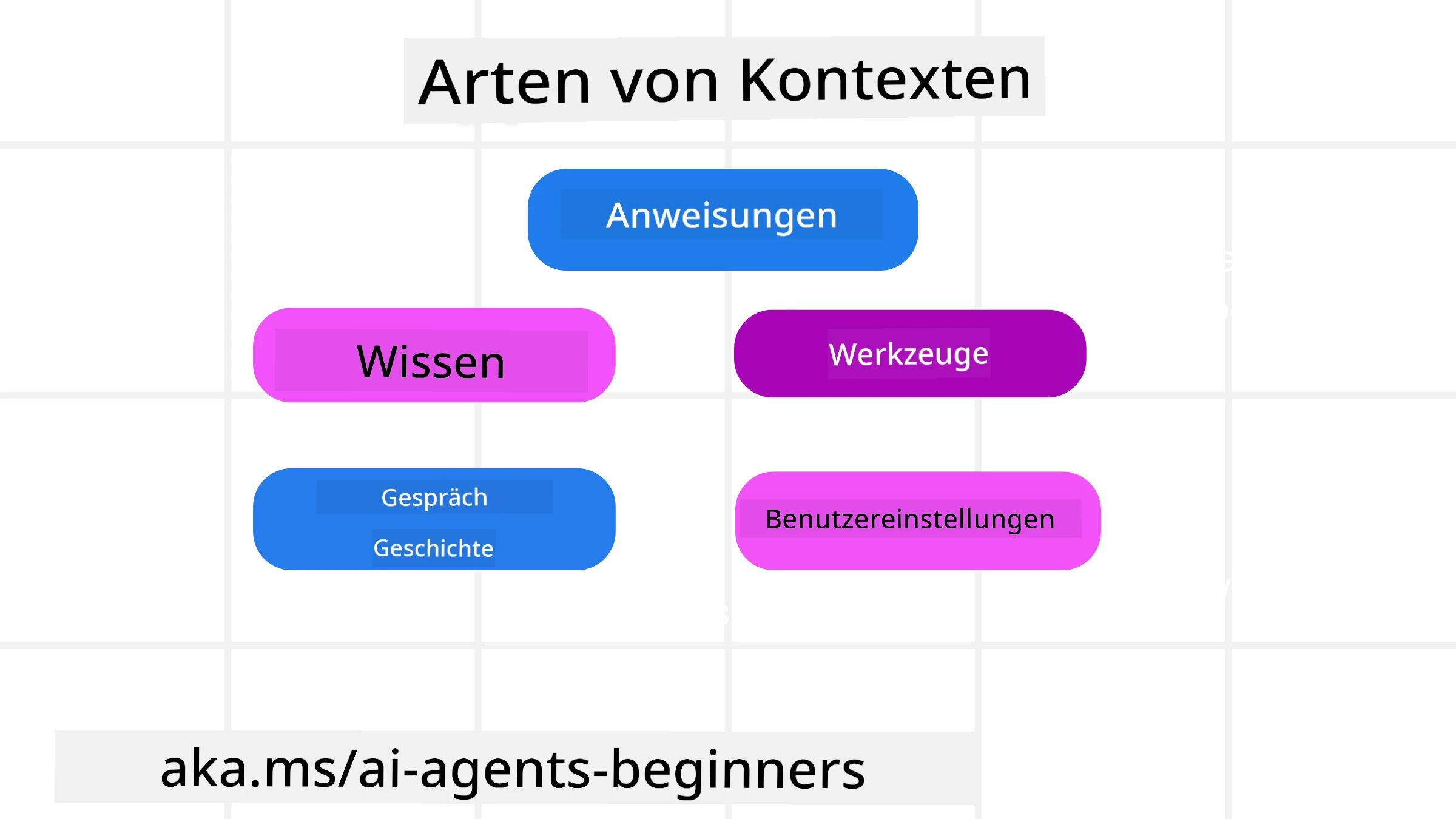
Es ist wichtig zu bedenken, dass Kontext nicht nur eine einzige Sache ist. Die Informationen, die der KI-Agent benötigt, können aus einer Vielzahl unterschiedlicher Quellen stammen, und es liegt an uns sicherzustellen, dass der Agent Zugang zu diesen Quellen hat:
Die Arten von Kontext, die ein KI-Agent verwalten muss, umfassen:
• Anweisungen: Diese sind wie die “Regeln” des Agenten – Prompts, Systemnachrichten, Few-Shot-Beispiele (die der KI zeigen, wie etwas zu tun ist) und Beschreibungen von Werkzeugen, die er verwenden kann. Hier trifft sich der Fokus des Prompt-Engineerings mit dem des Kontext-Engineerings.
• Wissen: Dies umfasst Fakten, aus Datenbanken abgerufene Informationen oder langfristige Erinnerungen, die der Agent angesammelt hat. Dazu gehört die Integration eines Retrieval Augmented Generation (RAG)-Systems, wenn ein Agent Zugriff auf verschiedene Wissensspeicher und Datenbanken benötigt.
• Werkzeuge: Dies sind die Definitionen externer Funktionen, APIs und MCP-Server, die der Agent aufrufen kann, zusammen mit dem Feedback (Ergebnissen), das er durch deren Nutzung erhält.
• Konversationsverlauf: Der laufende Dialog mit einem Nutzer. Mit der Zeit werden diese Gespräche länger und komplexer, was bedeutet, dass sie Platz im Kontextfenster einnehmen.
• Nutzerpräferenzen: Informationen über die Vorlieben oder Abneigungen eines Nutzers, die im Laufe der Zeit gelernt wurden. Diese könnten gespeichert und bei wichtigen Entscheidungen herangezogen werden, um dem Nutzer zu helfen.
Strategien für effektives Kontext-Engineering
Planungsstrategien
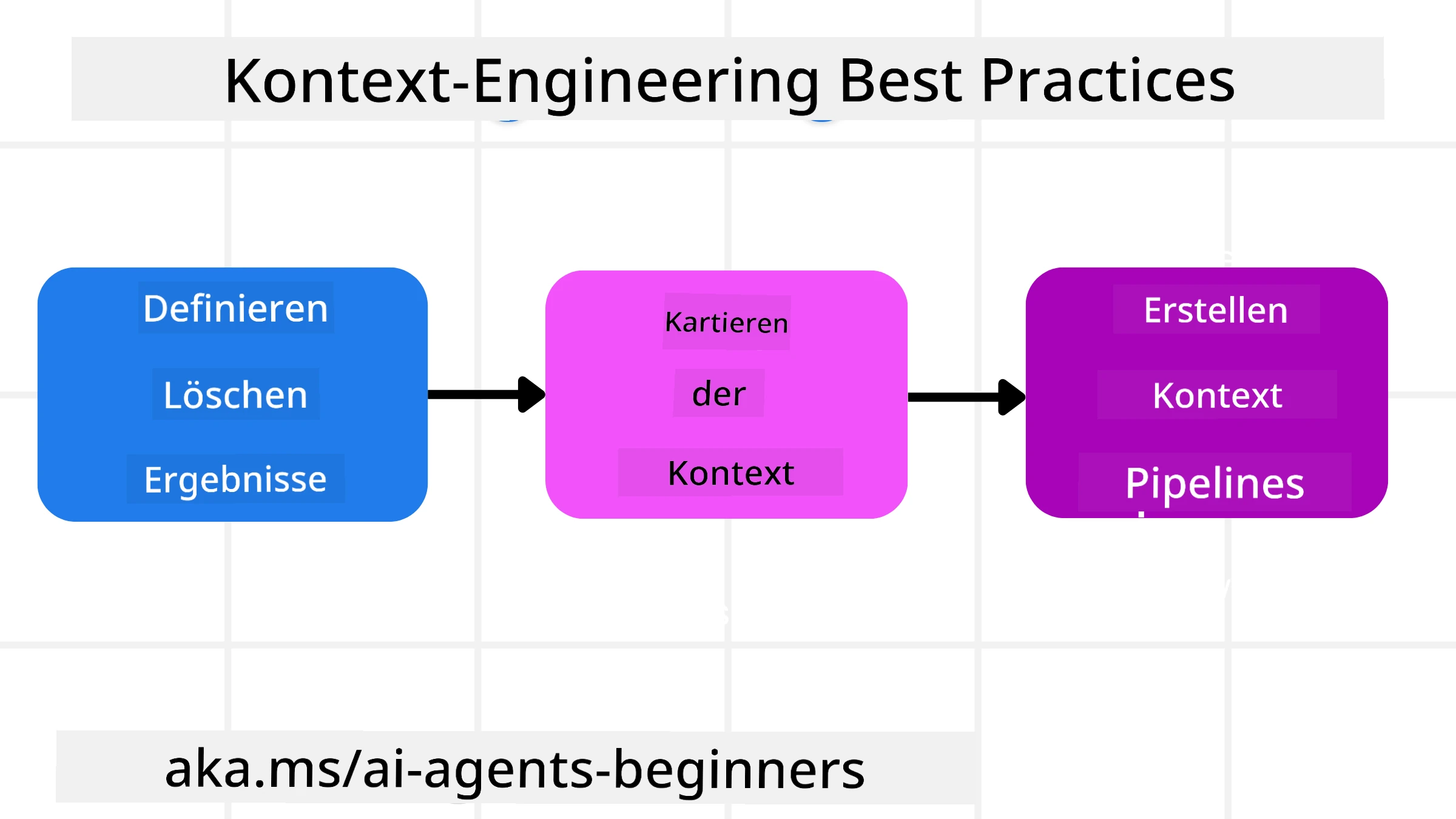
Gutes Kontext-Engineering beginnt mit guter Planung. Hier ist ein Ansatz, der Ihnen hilft, darüber nachzudenken, wie Sie das Konzept des Kontext-Engineerings anwenden können:
- Klare Ergebnisse definieren - Die Ergebnisse der Aufgaben, die KI-Agenten zugewiesen werden, sollten klar definiert sein. Beantworten Sie die Frage: “Wie wird die Welt aussehen, wenn der KI-Agent seine Aufgabe erledigt hat?” Mit anderen Worten, welche Veränderung, Information oder Antwort sollte der Nutzer nach der Interaktion mit dem KI-Agenten haben.
- Den Kontext kartieren - Sobald Sie die Ergebnisse des KI-Agenten definiert haben, müssen Sie die Frage beantworten: “Welche Informationen braucht der KI-Agent, um diese Aufgabe zu erfüllen?”. So können Sie beginnen, den Kontext zu kartieren, wo diese Informationen zu finden sind.
- Kontext-Pipelines erstellen - Jetzt, wo Sie wissen, wo die Informationen sind, müssen Sie die Frage beantworten: “Wie wird der Agent diese Informationen erhalten?”. Dies kann auf verschiedene Weise erfolgen, einschließlich RAG, Einsatz von MCP-Servern und anderen Werkzeugen.
Praktische Strategien
Planung ist wichtig, aber sobald die Informationen beginnen, in das Kontextfenster unseres Agenten zu fließen, müssen wir praktische Strategien haben, um sie zu verwalten:
Kontext verwalten
Während einige Informationen automatisch dem Kontextfenster hinzugefügt werden, geht es beim Kontext-Engineering darum, eine aktivere Rolle bei diesen Informationen zu übernehmen, was durch einige Strategien erreicht werden kann:
-
Agenten-Scratchpad Dieses ermöglicht es einem KI-Agenten, während einer einzelnen Sitzung relevante Informationen über die aktuellen Aufgaben und Nutzerinteraktionen zu notieren. Dies sollte außerhalb des Kontextfensters in einer Datei oder einem Laufzeitobjekt existieren, das der Agent später während dieser Sitzung bei Bedarf abrufen kann.
-
Erinnerungen Scratchpads sind gut, um Informationen außerhalb des Kontextfensters einer einzelnen Sitzung zu verwalten. Erinnerungen ermöglichen es Agenten, relevante Informationen über mehrere Sitzungen hinweg zu speichern und abzurufen. Dies könnte Zusammenfassungen, Nutzerpräferenzen und Feedback für künftige Verbesserungen umfassen.
-
Kontext komprimieren Sobald das Kontextfenster wächst und sich seinem Limit nähert, können Techniken wie Zusammenfassung und Kürzung verwendet werden. Dazu gehört entweder, nur die relevantesten Informationen beizubehalten oder ältere Nachrichten zu entfernen.
-
Multi-Agenten-Systeme Die Entwicklung von Multi-Agenten-Systemen ist eine Form des Kontext-Engineerings, weil jeder Agent sein eigenes Kontextfenster hat. Wie dieser Kontext geteilt und an verschiedene Agenten weitergegeben wird, ist ein weiterer Punkt, der beim Aufbau dieser Systeme geplant werden muss.
-
Sandbox-Umgebungen Wenn ein Agent Code ausführen oder große Mengen an Informationen in einem Dokument verarbeiten muss, kann dies eine große Anzahl von Tokens zur Verarbeitung der Ergebnisse erfordern. Anstatt dies alles im Kontextfenster zu speichern, kann der Agent eine Sandbox-Umgebung verwenden, die diesen Code ausführt und nur die Ergebnisse und andere relevante Informationen liest.
-
Runtime-State-Objekte Dies geschieht durch das Erstellen von Informationscontainern, um Situationen zu verwalten, in denen der Agent Zugriff auf bestimmte Informationen haben muss. Für eine komplexe Aufgabe würde dies einem Agenten ermöglichen, die Ergebnisse jeder Unteraufgabe Schritt für Schritt zu speichern, sodass der Kontext nur mit genau dieser spezifischen Unteraufgabe verbunden bleibt.
Beispiel für Kontext-Engineering
Angenommen, wir möchten, dass ein KI-Agent “Buche mir eine Reise nach Paris.”
• Ein einfacher Agent, der nur Prompt-Engineering verwendet, könnte einfach antworten: “Okay, wann möchtest du nach Paris fahren?”. Er hat nur Ihre direkte Frage zum Zeitpunkt der Anfrage verarbeitet.
• Ein Agent, der die hier behandelten Kontext-Engineering-Strategien anwendet, würde viel mehr tun. Bevor er überhaupt antwortet, könnte sein System zum Beispiel:
◦ Ihren Kalender prüfen auf verfügbare Daten (Abruf von Echtzeitdaten).
◦ Frühere Reisepräferenzen abrufen (aus dem Langzeitgedächtnis), wie Ihre bevorzugte Fluggesellschaft, das Budget oder ob Sie Direktflüge bevorzugen.
◦ Verfügbare Werkzeuge identifizieren für Flug- und Hotelbuchungen.
- Dann könnte eine Beispielantwort sein: “Hey [Your Name]! Ich sehe, dass Sie in der ersten Oktoberwoche frei sind. Soll ich nach Direktflügen nach Paris mit [Preferred Airline] innerhalb Ihres üblichen Budgets von [Budget] suchen?”. Diese reichhaltigere, kontextbewusste Antwort demonstriert die Stärke des Kontext-Engineerings.
Häufige Kontextfehler
Kontext-Poisoning
Was es ist: Wenn eine Halluzination (falsche Information, die vom LLM generiert wurde) oder ein Fehler in den Kontext gelangt und wiederholt referenziert wird, wodurch der Agent unmögliche Ziele verfolgt oder unsinnige Strategien entwickelt.
Was zu tun ist: Implementieren Sie Kontextvalidierung und Quarantäne. Validieren Sie Informationen, bevor sie dem Langzeitgedächtnis hinzugefügt werden. Wenn potenzielles Poisoning erkannt wird, beginnen Sie frische Kontextthreads, um zu verhindern, dass sich die fehlerhafte Information ausbreitet.
Beispiel Reisebuchung: Ihr Agent halluziniert einen Direktflug von einem kleinen lokalen Flughafen zu einer weit entfernten internationalen Stadt, die tatsächlich keine internationalen Flüge anbietet. Dieses nicht existierende Flugdetail wird im Kontext gespeichert. Später, wenn Sie den Agenten bitten zu buchen, versucht er weiterhin, Tickets für diese unmögliche Strecke zu finden, was zu wiederholten Fehlern führt.
Lösung: Implementieren Sie einen Schritt, der die Existenz und Routen von Flügen mit einer Echtzeit-API validiert, bevor das Flugdetail dem Arbeitskontext des Agenten hinzugefügt wird. Wenn die Validierung fehlschlägt, wird die fehlerhafte Information “quarantäneartig” isoliert und nicht weiter verwendet.
Kontext-Ablenkung
Was es ist: Wenn der Kontext so groß wird, dass das Modell zu sehr auf die angesammelte Historie fokussiert ist, anstatt das zu verwenden, was es während des Trainings gelernt hat, was zu repetitiven oder unhilfreichen Aktionen führt. Modelle können sogar Fehler machen, bevor das Kontextfenster voll ist.
Was zu tun ist: Verwenden Sie Kontextzusammenfassung. Komprimieren Sie periodisch angesammelte Informationen in kürzere Zusammenfassungen, wobei wichtige Details beibehalten und redundante Historie entfernt werden. Dies hilft, den Fokus “zurückzusetzen”.
Beispiel Reisebuchung: Sie haben lange Zeit verschiedene Traumreiseziele diskutiert, einschließlich einer detaillierten Schilderung Ihrer Rucksackreise von vor zwei Jahren. Wenn Sie schließlich fragen, “finde mir einen günstigen Flug für nächsten Monat,” verheddert sich der Agent in den alten, irrelevanten Details und fragt ständig nach Ihrer Rucksackausrüstung oder vergangenen Reiserouten, anstatt Ihre aktuelle Anfrage zu bearbeiten.
Lösung: Nach einer bestimmten Anzahl von Runden oder wenn der Kontext zu groß wird, sollte der Agent die jüngsten und relevantesten Teile der Unterhaltung zusammenfassen – mit Fokus auf Ihre aktuellen Reisedaten und das Reiseziel – und diese kondensierte Zusammenfassung für den nächsten LLM-Aufruf verwenden, wobei die weniger relevanten historischen Chats verworfen werden.
Kontext-Verwirrung
Was es ist: Wenn unnötiger Kontext, oft in Form zu vieler verfügbarer Werkzeuge, dazu führt, dass das Modell schlechte Antworten generiert oder irrelevante Werkzeuge aufruft. Kleinere Modelle sind dafür besonders anfällig.
Was zu tun ist: Implementieren Sie Tool-Loadout-Management unter Verwendung von RAG-Techniken. Speichern Sie Werkzeugbeschreibungen in einer Vektordatenbank und wählen Sie nur die relevantesten Werkzeuge für jede spezifische Aufgabe aus. Untersuchungen zeigen, dass die Beschränkung der Werkzeugauswahl auf weniger als 30 hilfreich ist.
Beispiel Reisebuchung: Ihr Agent hat Zugriff auf Dutzende von Werkzeugen: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations usw. Sie fragen: “Wie komme ich am besten in Paris herum?” Aufgrund der schieren Anzahl an Werkzeugen wird der Agent verwirrt und versucht, book_flight innerhalb von Paris aufzurufen oder rent_car, obwohl Sie öffentliche Verkehrsmittel bevorzugen, weil sich die Werkzeugbeschreibungen überschneiden könnten oder er einfach nicht das passende Werkzeug erkennen kann.
Lösung: Verwenden Sie RAG über Werkzeugbeschreibungen. Wenn Sie fragen, wie man sich in Paris fortbewegt, ruft das System dynamisch nur die relevantesten Werkzeuge wie rent_car oder public_transport_info basierend auf Ihrer Anfrage ab und präsentiert dem LLM ein fokussiertes “Loadout” an Werkzeugen.
Kontext-Konflikt
Was es ist: Wenn widersprüchliche Informationen im Kontext existieren, was zu inkonsistentem Schlussfolgern oder schlechten Endantworten führt. Dies geschieht oft, wenn Informationen in Etappen eintreffen und frühe, falsche Annahmen im Kontext verbleiben.
Was zu tun ist: Verwenden Sie Kontext-Pruning und Offloading. Pruning bedeutet, veraltete oder widersprüchliche Informationen zu entfernen, wenn neue Details eintreffen. Offloading gibt dem Modell einen separaten “Scratchpad”-Arbeitsbereich, um Informationen ohne Verunreinigung des Hauptkontexts zu verarbeiten.
Beispiel Reisebuchung: Sie sagen Ihrem Agenten zunächst: “Ich möchte in der Economy-Klasse fliegen.” Später in der Unterhaltung ändern Sie Ihre Meinung und sagen: “Eigentlich, für diese Reise, lasst uns Business Class nehmen.” Wenn beide Anweisungen im Kontext verbleiben, könnte der Agent widersprüchliche Suchergebnisse erhalten oder verwirrt sein, welche Präferenz er priorisieren soll.
Lösung: Implementieren Sie Kontext-Pruning. Wenn eine neue Anweisung einer alten widerspricht, wird die ältere Anweisung aus dem Kontext entfernt oder explizit überschrieben. Alternativ kann der Agent ein Scratchpad verwenden, um widersprüchliche Präferenzen zu klären, bevor er eine Entscheidung trifft, und sicherzustellen, dass nur die finale, konsistente Anweisung seine Aktionen leitet.
Haben Sie weitere Fragen zum Kontext-Engineering?
Treten Sie dem Microsoft Foundry Discord bei, um andere Lernende zu treffen, an Sprechstunden teilzunehmen und Ihre Fragen zu KI-Agenten beantwortet zu bekommen.
Haftungsausschluss: Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, beachten Sie bitte, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache gilt als maßgebliche Quelle. Für wichtige Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir haften nicht für Missverständnisse oder Fehlinterpretationen, die sich aus der Verwendung dieser Übersetzung ergeben.