ai-agents-for-beginners
Ingeniería de Contexto para Agentes de IA

(Haz clic en la imagen de arriba para ver el video de esta lección)
Entender la complejidad de la aplicación para la que estás construyendo un agente de IA es importante para crear uno confiable. Necesitamos construir Agentes de IA que gestionen la información de manera eficaz para abordar necesidades complejas más allá de la ingeniería de prompts.
En esta lección, veremos qué es la ingeniería de contexto y su papel en la construcción de agentes de IA.
Introducción
Esta lección cubrirá:
• Qué es la Ingeniería de Contexto y por qué es diferente de la ingeniería de prompts.
• Estrategias para una Ingeniería de Contexto efectiva, incluyendo cómo escribir, seleccionar, comprimir y aislar la información.
• Fallos comunes de contexto que pueden descarrilar tu agente de IA y cómo solucionarlos.
Objetivos de aprendizaje
Después de completar esta lección, comprenderás cómo:
• Definir la ingeniería de contexto y diferenciarla de la ingeniería de prompts.
• Identificar los componentes clave del contexto en aplicaciones con Modelos de Lenguaje Extensos (LLM).
• Aplicar estrategias para escribir, seleccionar, comprimir y aislar el contexto para mejorar el rendimiento del agente.
• Reconocer fallos comunes de contexto como envenenamiento, distracción, confusión y choque, e implementar técnicas de mitigación.
¿Qué es la Ingeniería de Contexto?
Para los Agentes de IA, el contexto es lo que impulsa la planificación de un Agente de IA para tomar ciertas acciones. La Ingeniería de Contexto es la práctica de asegurarse de que el Agente de IA tenga la información correcta para completar el siguiente paso de la tarea. La ventana de contexto es limitada en tamaño, por lo que, como constructores de agentes, necesitamos crear sistemas y procesos para gestionar la adición, eliminación y condensación de la información en la ventana de contexto.
Ingeniería de prompts vs Ingeniería de contexto
La ingeniería de prompts se centra en un conjunto único de instrucciones estáticas para guiar eficazmente a los Agentes de IA con un conjunto de reglas. La ingeniería de contexto es cómo gestionar un conjunto dinámico de información, incluido el prompt inicial, para garantizar que el Agente de IA tenga lo que necesita a lo largo del tiempo. La idea principal de la ingeniería de contexto es hacer que este proceso sea repetible y confiable.
Tipos de contexto
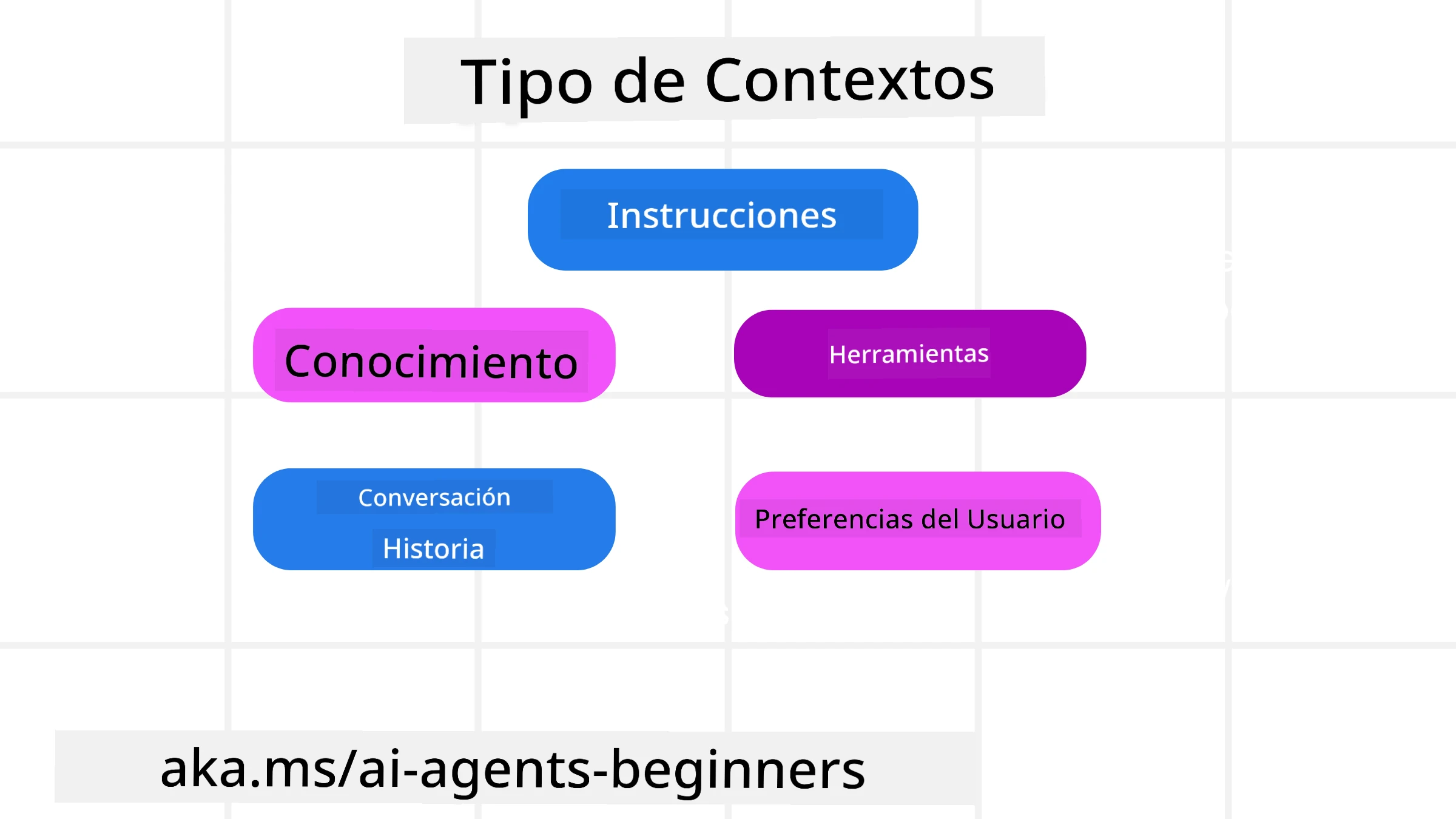
Es importante recordar que el contexto no es solo una cosa. La información que el Agente de IA necesita puede provenir de una variedad de fuentes diferentes y depende de nosotros asegurarnos de que el agente tenga acceso a estas fuentes:
Los tipos de contexto que un agente de IA podría necesitar gestionar incluyen:
• Instrucciones: Estas son como las “reglas” del agente: prompts, mensajes del sistema, ejemplos few-shot (mostrando al IA cómo hacer algo) y descripciones de las herramientas que puede usar. Aquí es donde el enfoque de la ingeniería de prompts se combina con la ingeniería de contexto.
• Conocimiento: Esto abarca hechos, información recuperada de bases de datos o memorias a largo plazo que el agente ha acumulado. Esto incluye integrar un sistema Retrieval Augmented Generation (RAG) si un agente necesita acceso a diferentes almacenes de conocimiento y bases de datos.
• Herramientas: Estas son las definiciones de funciones externas, APIs y servidores MCP que el agente puede llamar, junto con la retroalimentación (resultados) que obtiene al usarlas.
• Historial de conversación: El diálogo continuo con un usuario. Con el paso del tiempo, estas conversaciones se vuelven más largas y complejas, lo que significa que ocupan espacio en la ventana de contexto.
• Preferencias del usuario: Información aprendida sobre los gustos o disgustos de un usuario a lo largo del tiempo. Esto podría almacenarse y recuperarse al tomar decisiones clave para ayudar al usuario.
Estrategias para una Ingeniería de Contexto Efectiva
Estrategias de planificación
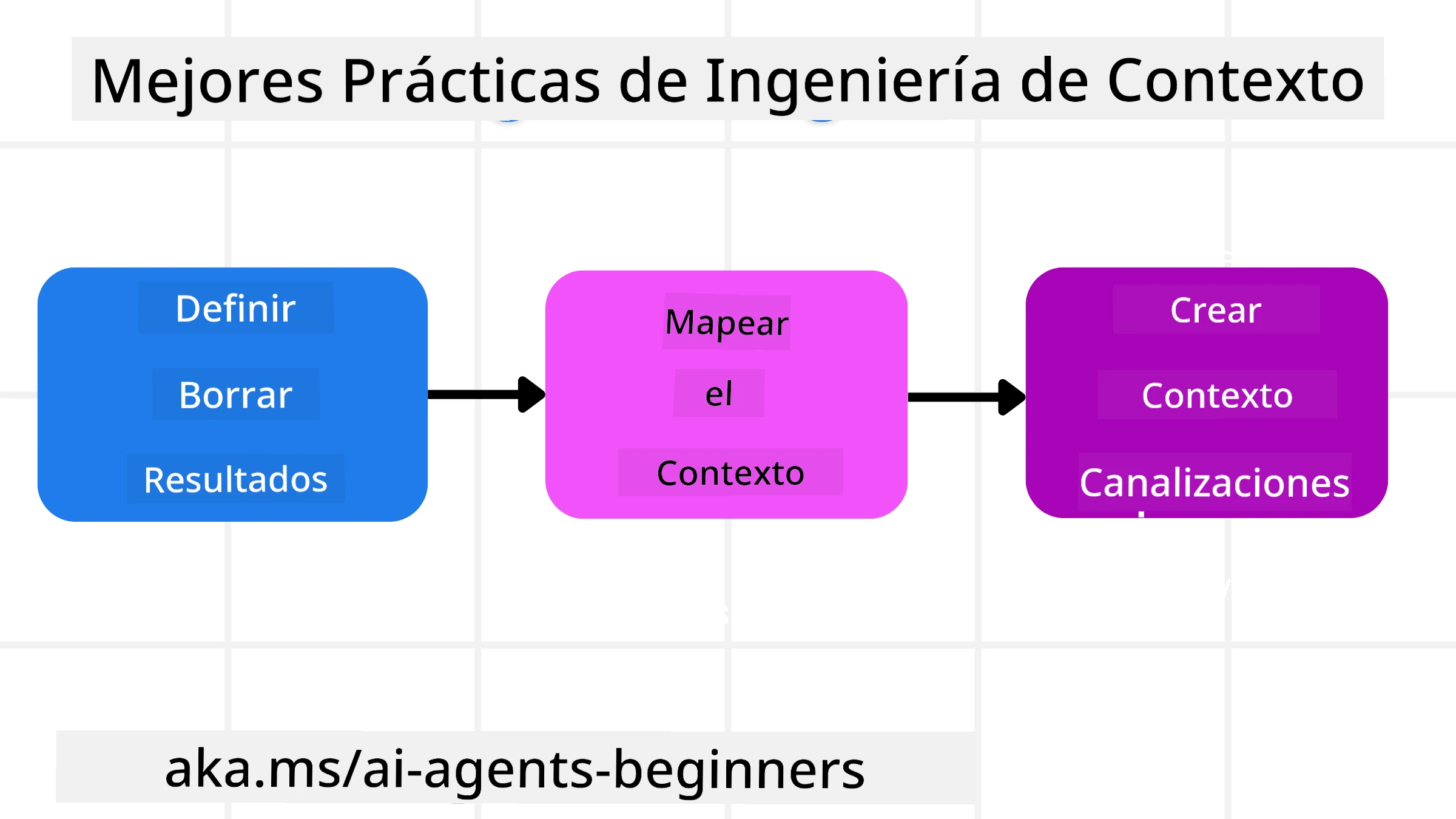
Una buena ingeniería de contexto comienza con una buena planificación. Aquí hay un enfoque que te ayudará a empezar a pensar en cómo aplicar el concepto de ingeniería de contexto:
- Definir resultados claros - Los resultados de las tareas que se asignarán a los Agentes de IA deben estar claramente definidos. Responde a la pregunta: “¿Cómo se verá el mundo cuando el Agente de IA haya terminado su tarea?”. En otras palabras, ¿qué cambio, información o respuesta debería tener el usuario después de interactuar con el Agente de IA?
- Mapear el contexto - Una vez que hayas definido los resultados del Agente de IA, necesitas responder a la pregunta “¿Qué información necesita el Agente de IA para completar esta tarea?”. De esta manera puedes empezar a mapear el contexto de dónde se puede localizar esa información.
- Crear canalizaciones de contexto - Ahora que sabes dónde está la información, necesitas responder a la pregunta “¿Cómo obtendrá el Agente esta información?”. Esto se puede hacer de diversas maneras, incluyendo RAG, uso de servidores MCP y otras herramientas.
Estrategias prácticas
La planificación es importante pero, una vez que la información comienza a fluir en la ventana de contexto de nuestro agente, necesitamos tener estrategias prácticas para gestionarla:
Gestión del contexto
Aunque parte de la información se añadirá a la ventana de contexto automáticamente, la ingeniería de contexto consiste en tomar un papel más activo sobre esta información, lo que se puede lograr con algunas estrategias:
-
Bloc de notas del agente Esto permite que un Agente de IA tome notas de información relevante sobre las tareas actuales y las interacciones con el usuario durante una sola sesión. Esto debería existir fuera de la ventana de contexto en un archivo u objeto en tiempo de ejecución que el agente pueda recuperar más tarde durante esta sesión si es necesario.
-
Memorias Los blocs de notas son buenos para gestionar información fuera de la ventana de contexto de una sola sesión. Las memorias permiten a los agentes almacenar y recuperar información relevante a lo largo de múltiples sesiones. Esto podría incluir resúmenes, preferencias del usuario y retroalimentación para mejoras en el futuro.
-
Comprimir el contexto Una vez que la ventana de contexto crece y está cerca de su límite, se pueden usar técnicas como la resumenización y el recorte. Esto incluye mantener solo la información más relevante o eliminar mensajes más antiguos.
-
Sistemas multiagente Desarrollar sistemas multiagente es una forma de ingeniería de contexto porque cada agente tiene su propia ventana de contexto. Cómo se comparte y se pasa ese contexto a diferentes agentes es otra cosa que planificar al construir estos sistemas.
-
Entornos sandbox Si un agente necesita ejecutar algún código o procesar grandes cantidades de información en un documento, esto puede requerir una gran cantidad de tokens para procesar los resultados. En lugar de tener todo esto almacenado en la ventana de contexto, el agente puede usar un entorno sandbox que pueda ejecutar este código y solo leer los resultados y otra información relevante.
-
Objetos de estado en tiempo de ejecución Esto se hace creando contenedores de información para gestionar situaciones en las que el Agente necesita tener acceso a cierta información. Para una tarea compleja, esto permitiría a un Agente almacenar los resultados de cada subtarea paso a paso, permitiendo que el contexto permanezca conectado solo a esa subtarea específica.
Ejemplo de Ingeniería de Contexto
Supongamos que queremos que un agente de IA “Me reserve un viaje a París.”
• Un agente simple que usa solo ingeniería de prompts podría responder simplemente: “De acuerdo, ¿cuándo te gustaría ir a París?”. Solo procesó tu pregunta directa en el momento en que el usuario la hizo.
• Un agente que use las estrategias de ingeniería de contexto descritas haría mucho más. Antes de responder, su sistema podría:
◦ Comprobar tu calendario para fechas disponibles (recuperando datos en tiempo real).
◦ Recordar preferencias de viajes pasadas (desde la memoria a largo plazo) como tu aerolínea preferida, presupuesto, o si prefieres vuelos directos.
◦ Identificar herramientas disponibles para reservar vuelos y hoteles.
- Then, un ejemplo de respuesta podría ser: “¡Hola [Tu Nombre]! Veo que estás libre la primera semana de octubre. ¿Busco vuelos directos a París en [Preferred Airline] dentro de tu presupuesto habitual de [Budget]?” Esta respuesta más rica y consciente del contexto demuestra el poder de la ingeniería de contexto.
Fallos comunes de contexto
Envenenamiento del contexto
Qué es: Cuando una alucinación (información falsa generada por el LLM) o un error entra en el contexto y se referencia repetidamente, haciendo que el agente persiga objetivos imposibles o desarrolle estrategias sin sentido.
Qué hacer: Implementar validación del contexto y cuarentena. Valida la información antes de añadirla a la memoria a largo plazo. Si se detecta un posible envenenamiento, inicia nuevos hilos de contexto para evitar que la mala información se propague.
Ejemplo de reserva de viaje: Tu agente alucina un vuelo directo desde un pequeño aeropuerto local a una ciudad internacional distante que en realidad no ofrece vuelos internacionales. Este detalle de vuelo inexistente se guarda en el contexto. Más tarde, cuando le pides al agente que reserve, sigue intentando encontrar billetes para esta ruta imposible, lo que conduce a errores repetidos.
Solución: Implementar un paso que valide la existencia de vuelos y rutas con una API en tiempo real antes de añadir el detalle del vuelo al contexto de trabajo del agente. Si la validación falla, la información errónea se “pone en cuarentena” y no se usa más.
Distracción del contexto
Qué es: Cuando el contexto se vuelve tan grande que el modelo se centra demasiado en el historial acumulado en lugar de usar lo que aprendió durante el entrenamiento, lo que conduce a acciones repetitivas o poco útiles. Los modelos pueden empezar a cometer errores incluso antes de que la ventana de contexto esté llena.
Qué hacer: Usar resumen del contexto. Comprime periódicamente la información acumulada en resúmenes más cortos, manteniendo los detalles importantes y eliminando el historial redundante. Esto ayuda a “resetear” el foco.
Ejemplo de reserva de viaje: Has estado discutiendo varios destinos de viaje soñados durante mucho tiempo, incluyendo un relato detallado de tu viaje de mochilero de hace dos años. Cuando finalmente pides “encuéntrame un vuelo barato para el mes que viene”, el agente se queda atascado en los detalles antiguos e irrelevantes y sigue preguntando sobre tu equipo de mochilero o itinerarios pasados, descuidando tu petición actual.
Solución: Después de cierto número de intercambios o cuando el contexto crezca demasiado, el agente debería resumir las partes más recientes y relevantes de la conversación – enfocándose en tus fechas y destino de viaje actuales – y usar ese resumen condensado para la siguiente llamada al LLM, descartando el chat histórico menos relevante.
Confusión del contexto
Qué es: Cuando el contexto innecesario, a menudo en forma de demasiadas herramientas disponibles, hace que el modelo genere malas respuestas o llame a herramientas irrelevantes. Los modelos más pequeños son especialmente propensos a esto.
Qué hacer: Implementar gestión de carga de herramientas usando técnicas RAG. Almacena las descripciones de las herramientas en una base de datos vectorial y selecciona solo las herramientas más relevantes para cada tarea específica. La investigación muestra limitar las selecciones de herramientas a menos de 30.
Ejemplo de reserva de viaje: Tu agente tiene acceso a docenas de herramientas: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, etc. Preguntas, “¿Cuál es la mejor forma de moverse por París?” Debido a la gran cantidad de herramientas, el agente se confunde e intenta llamar a book_flight dentro de París, o rent_car aunque prefieras el transporte público, porque las descripciones de las herramientas pueden solaparse o simplemente no puede discernir cuál es la mejor.
Solución: Usar RAG sobre las descripciones de herramientas. Cuando preguntas sobre cómo moverte por París, el sistema recupera dinámicamente solo las herramientas más relevantes como rent_car o public_transport_info según tu consulta, presentando un “conjunto de herramientas” enfocado al LLM.
Choque de contexto
Qué es: Cuando existe información contradictoria dentro del contexto, llevando a razonamientos inconsistentes o respuestas finales malas. Esto ocurre a menudo cuando la información llega por etapas y las primeras suposiciones incorrectas permanecen en el contexto.
Qué hacer: Usar poda del contexto y descarga. Podar significa eliminar información desactualizada o conflictiva a medida que llegan nuevos detalles. La descarga da al modelo un espacio de trabajo “bloc de notas” separado para procesar la información sin saturar el contexto principal.
Ejemplo de reserva de viaje: Inicialmente le dices a tu agente, “Quiero volar en clase económica.” Más adelante en la conversación cambias de opinión y dices, “En realidad, para este viaje, vayamos en clase ejecutiva.” Si ambas instrucciones permanecen en el contexto, el agente podría recibir resultados de búsqueda contradictorios o confundirse sobre qué preferencia priorizar.
Solución: Implementar poda del contexto. Cuando una nueva instrucción contradice una anterior, la instrucción más antigua se elimina o se anula explícitamente en el contexto. Alternativamente, el agente puede usar un bloc de notas para reconciliar preferencias contradictorias antes de decidir, asegurando que solo la instrucción final y consistente guíe sus acciones.
¿Tienes más preguntas sobre Ingeniería de Contexto?
Únete al Microsoft Foundry Discord para encontrarte con otros estudiantes, asistir a horas de oficina y resolver tus dudas sobre Agentes de IA.
Descargo de responsabilidad: Este documento ha sido traducido utilizando el servicio de traducción por IA Co-op Translator. Si bien nos esforzamos por la precisión, tenga en cuenta que las traducciones automatizadas pueden contener errores o inexactitudes. El documento original en su idioma nativo debe considerarse la fuente autorizada. Para información crítica, se recomienda una traducción profesional realizada por traductores humanos. No nos hacemos responsables de los malentendidos o interpretaciones erróneas que puedan derivarse del uso de esta traducción.