ai-agents-for-beginners

(برای مشاهده ویدیو این درس روی تصویر بالا کلیک کنید)
الگوی طراحی استفاده از ابزار
ابزارها جالب هستند زیرا به عاملهای هوش مصنوعی اجازه میدهند قابلیتهای گستردهتری داشته باشند. به جای اینکه عامل تنها مجموعه محدودی از اقدامات را انجام دهد، با افزودن یک ابزار، عامل اکنون میتواند دامنه وسیعی از اقدامات را انجام دهد. در این فصل، به الگوی طراحی استفاده از ابزار میپردازیم که شرح میدهد چگونه عاملهای هوش مصنوعی میتوانند از ابزارهای خاص برای رسیدن به اهدافشان استفاده کنند.
مقدمه
در این درس قصد داریم به سوالات زیر پاسخ دهیم:
- الگوی طراحی استفاده از ابزار چیست؟
- چه مواردی برای استفاده از آن مناسب است؟
- عناصر/بلوکهای سازنده لازم برای پیادهسازی این الگو چیست؟
- ملاحظات ویژه برای استفاده از الگوی طراحی استفاده از ابزار برای ساخت عاملهای هوش مصنوعی قابل اعتماد چیست؟
اهداف یادگیری
پس از اتمام این درس، قادر خواهید بود:
- الگوی طراحی استفاده از ابزار و هدف آن را تعریف کنید.
- موارد کاربردی که الگوی استفاده از ابزار در آنها کاربرد دارد را شناسایی کنید.
- عناصر کلیدی لازم برای پیادهسازی این الگو را درک کنید.
- ملاحظات حفظ اعتمادپذیری عاملهای هوش مصنوعی که از این الگو استفاده میکنند را بشناسید.
الگوی طراحی استفاده از ابزار چیست؟
الگوی طراحی استفاده از ابزار بر توانایی دادن به مدلهای زبانی بزرگ (LLMs) برای تعامل با ابزارهای خارجی به منظور دستیابی به اهداف خاص متمرکز است. ابزارها کدهایی هستند که توسط عامل اجرا میشوند تا عملیات خاصی را انجام دهند. یک ابزار میتواند تابع سادهای مانند ماشین حساب باشد، یا فراخوانی API به یک سرویس شخص ثالث مانند جستجوی قیمت سهام یا پیشبینی آب و هوا. در زمینه عاملهای هوش مصنوعی، ابزارها طوری طراحی شدهاند که توسط عاملها در پاسخ به فراخوانیهای توابع تولیدشده توسط مدل اجرا شوند.
مواردی که میتوان از آن استفاده کرد کدامند؟
عاملهای هوش مصنوعی میتوانند برای انجام کارهای پیچیده، بازیابی اطلاعات یا اتخاذ تصمیمات از ابزارها بهره ببرند. الگوی طراحی استفاده از ابزار اغلب در موقعیتهایی به کار میرود که نیاز به تعامل پویا با سیستمهای خارجی مانند پایگاههای داده، سرویسهای وب یا مفسرهای کد وجود دارد. این قابلیت برای موارد متنوعی کاربرد دارد از جمله:
- بازیابی اطلاعات پویا: عاملها میتوانند از APIهای خارجی یا پایگاههای داده پرسوجو کنند تا دادههای بهروز را دریافت کنند (مثلاً پرسوجو در یک پایگاه داده SQLite برای تحلیل داده، دریافت قیمت سهام یا اطلاعات آب و هوا).
- اجرای کد و تفسیر: عاملها میتوانند کد یا اسکریپت اجرا کنند تا مسائل ریاضی را حل کنند، گزارش تولید کنند یا شبیهسازی انجام دهند.
- اتوماسیون جریان کاری: خودکارسازی کارهای تکراری یا چند مرحلهای با ادغام ابزارهایی مانند زمانبندهای کار، خدمات ایمیل یا خطوط لوله داده.
- پشتیبانی مشتری: عاملها میتوانند با سیستمهای مدیریت ارتباط با مشتری (CRM)، سامانههای تیکتینگ یا پایگاههای دانش برای حل سوالات کاربران تعامل داشته باشند.
- تولید و ویرایش محتوا: عاملها میتوانند از ابزارهایی مانند بررسی دستور زبان، خلاصهسازی متن، یا ارزیابی ایمنی محتوا برای کمک به وظایف خلق محتوا استفاده کنند.
عناصر/بلوکهای سازنده لازم برای پیادهسازی الگوی استفاده از ابزار چیست؟
این بلوکهای سازنده به عامل هوش مصنوعی اجازه میدهند مجموعه گستردهای از کارها را انجام دهد. بیایید به عناصر کلیدی که برای پیادهسازی الگوی طراحی استفاده از ابزار لازم است نگاهی بیندازیم:
-
طرح ساختار/خواندن توابع/ابزار: تعریف دقیق ابزارهای موجود، شامل نام تابع، هدف، پارامترهای لازم و خروجیهای مورد انتظار. این ساختارها به مدل زبانی بزرگ کمک میکنند تا بفهمد چه ابزارهایی در دسترس هستند و چگونه درخواستهای معتبر بسازد.
-
منطق اجرای تابع: حاکم بر اینکه چگونه و کی ابزارها بر اساس هدف کاربر و متن گفتگو فراخوانی میشوند. این میتواند شامل ماژولهای برنامهریز، مکانیزمهای مسیریابی یا جریانهای شرطی باشد که استفاده از ابزارها را به صورت پویا تعیین میکنند.
-
سیستم مدیریت پیام: اجزایی که جریان مکالمه بین ورودیهای کاربر، پاسخهای مدل زبانی، فراخوانیهای ابزار و خروجیهای ابزار را مدیریت میکنند.
-
چارچوب ادغام ابزار: زیرساختی که عامل را به ابزارهای مختلف متصل میکند، چه آنها توابع ساده باشند یا سرویسهای خارجی پیچیده.
-
مدیریت خطا و اعتبارسنجی: مکانیزمهایی برای مدیریت شکست در اجرای ابزار، اعتبارسنجی پارامترها و کنترل پاسخهای غیرمنتظره.
-
مدیریت وضعیت: ردیابی متن گفتگو، تعاملهای پیشین با ابزار و دادههای پایدار برای حفظ سازگاری در تعاملات چند مرحلهای.
در ادامه بیایید بیشتر درباره فراخوانی تابع/ابزار توضیح دهیم.
فراخوانی تابع/ابزار
فراخوانی تابع اصلیترین روشی است که امکان تعامل مدلهای بزرگ زبانی (LLMs) با ابزارها را فراهم میکند. معمولاً میبینید «تابع» و «ابزار» به جای هم استفاده میشوند چون «توابع» (بلاکهای کد قابل استفاده مجدد) همان «ابزارهایی» هستند که عاملها برای انجام کارها استفاده میکنند. برای اجرای کد یک تابع، مدل زبانی بزرگ باید درخواست کاربر را با توصیف توابع مقایسه کند. برای این کار، یک ساختار شامل توصیف تمام توابع در دسترس به مدل ارسال میشود. مدل سپس مناسبترین تابع را برای کار انتخاب کرده و نام و آرگومانهای آن را باز میگرداند. تابع انتخابشده اجرا میشود، پاسخ آن به مدل بازگردانده میشود، و مدل از این اطلاعات برای پاسخ به درخواست کاربر استفاده میکند.
برای اینکه توسعهدهندگان بتوانند فراخوانی توابع برای عاملها را پیادهسازی کنند، به موارد زیر نیاز دارند:
- مدلی از LLM که فراخوانی تابع را پشتیبانی کند
- ساختاری شامل توصیف توابع
- کد هر تابع توصیفشده
برای روشنتر شدن، بیایید مثال گرفتن زمان جاری در یک شهر را بررسی کنیم:
-
یک مدل LLM که فراخوانی تابع را پشتیبانی میکند راهاندازی کنید:
همه مدلها فراخوانی تابع را پشتیبانی نمیکنند، پس مهم است که بررسی کنید مدلی که استفاده میکنید این ویژگی را دارد یا خیر. Azure OpenAI فراخوانی تابع را پشتیبانی میکند. ما میتوانیم با شروع به ایجاد کلاینت Azure OpenAI کار را آغاز کنیم.
# مقداردهی اولیهٔ کلاینت Azure OpenAI client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_AI_PROJECT_ENDPOINT"), api_key=os.getenv("AZURE_OPENAI_API_KEY"), api_version="2024-05-01-preview" ) -
ایجاد ساختار تابع:
سپس یک ساختار JSON تعریف میکنیم که شامل نام تابع، توصیف اینکه تابع چه کاری انجام میدهد و نامها و توصیف پارامترهای تابع است. این ساختار را به همراه درخواست کاربر برای پیدا کردن زمان در سانفرانسیسکو به کلاینتی که قبلاً ایجاد شده ارسال میکنیم. نکته مهم این است که فراخوانی ابزار برگردانده میشود، نه پاسخ نهایی به سوال. همانطور که قبلاً گفته شد، مدل نام تابع انتخابشده برای کار و آرگومانهایی که به آن داده میشود را بازمیگرداند.
# توصیف عملکرد برای مدل جهت خواندن tools = [ { "type": "function", "function": { "name": "get_current_time", "description": "Get the current time in a given location", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } } ]# پیام اولیه کاربر messages = [{"role": "user", "content": "What's the current time in San Francisco"}] # اولین فراخوانی API: درخواست از مدل برای استفاده از تابع response = client.chat.completions.create( model=deployment_name, messages=messages, tools=tools, tool_choice="auto", ) # پردازش پاسخ مدل response_message = response.choices[0].message messages.append(response_message) print("Model's response:") print(response_message)Model's response: ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_pOsKdUlqvdyttYB67MOj434b', function=Function(arguments='{"location":"San Francisco"}', name='get_current_time'), type='function')]) -
کد تابع لازم برای انجام آن کار:
حال که مدل تابع مورد نیاز برای اجرا را انتخاب کرده، کدی که کار را انجام میدهد باید پیادهسازی و اجرا شود. میتوانیم کدی برای گرفتن زمان جاری در پایتون بنویسیم. همچنین باید کدی نوشته شود که نام و آرگومانها را از response_message استخراج کند تا نتیجه نهایی به دست آید.
def get_current_time(location): """Get the current time for a given location""" print(f"get_current_time called with location: {location}") location_lower = location.lower() for key, timezone in TIMEZONE_DATA.items(): if key in location_lower: print(f"Timezone found for {key}") current_time = datetime.now(ZoneInfo(timezone)).strftime("%I:%M %p") return json.dumps({ "location": location, "current_time": current_time }) print(f"No timezone data found for {location_lower}") return json.dumps({"location": location, "current_time": "unknown"})# رسیدگی به فراخوانیهای تابع if response_message.tool_calls: for tool_call in response_message.tool_calls: if tool_call.function.name == "get_current_time": function_args = json.loads(tool_call.function.arguments) time_response = get_current_time( location=function_args.get("location") ) messages.append({ "tool_call_id": tool_call.id, "role": "tool", "name": "get_current_time", "content": time_response, }) else: print("No tool calls were made by the model.") # فراخوانی دوم API: دریافت پاسخ نهایی از مدل final_response = client.chat.completions.create( model=deployment_name, messages=messages, ) return final_response.choices[0].message.contentget_current_time called with location: San Francisco Timezone found for san francisco The current time in San Francisco is 09:24 AM.
فراخوانی تابع در هسته اکثر، اگر نگوییم تمام، طراحی استفاده از ابزار برای عاملها قرار دارد، با این حال پیادهسازی آن از صفر گاهی چالشبرانگیز است. همانطور که در درس ۲ یاد گرفتیم، چارچوبهای عاملی بلوکهای از پیش ساخته شدهای برای پیادهسازی استفاده از ابزار فراهم میکنند.
نمونههای استفاده از ابزار با چارچوبهای عاملی
در اینجا چند مثال از نحوه اجرای الگوی طراحی استفاده از ابزار با استفاده از چارچوبهای عاملی مختلف آورده شده است:
چارچوب عامل مایکروسافت
چارچوب عامل مایکروسافت یک چارچوب هوش مصنوعی متنباز برای ساخت عاملهای هوش مصنوعی است. این چارچوب فرآیند فراخوانی توابع را ساده میکند، به طوری که شما میتوانید ابزارها را به عنوان توابع پایتون با دکوراتور @tool تعریف کنید. چارچوب ارتباط رفت و برگشتی بین مدل و کد شما را مدیریت میکند. همچنین دسترسی به ابزارهای از پیش ساخته مانند جستجوی فایل و مفسر کد را از طریق AzureAIProjectAgentProvider فراهم میسازد.
نمودار زیر فرآیند فراخوانی تابع با چارچوب عامل مایکروسافت را نشان میدهد:
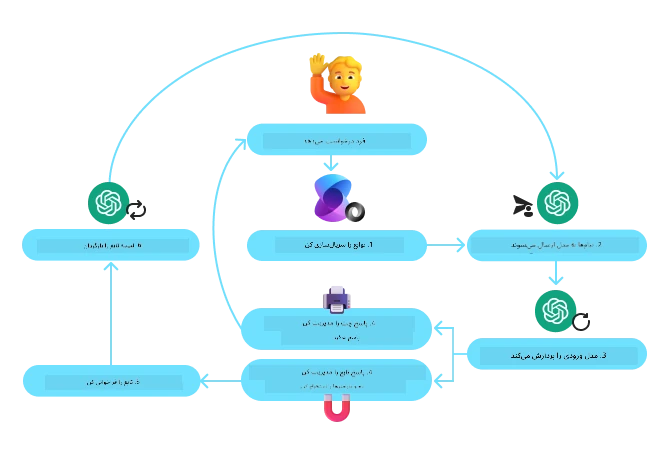
در چارچوب عامل مایکروسافت، ابزارها به صورت توابع دکوری تعریف میشوند. میتوانیم تابع get_current_time را که قبلاً دیدیم، به کمک دکوراتور @tool به یک ابزار تبدیل کنیم. چارچوب به طور خودکار تابع و پارامترهای آن را سریالسازی میکند و ساختاری برای ارسال به مدل زبانی ایجاد میکند.
from agent_framework import tool
from agent_framework.azure import AzureAIProjectAgentProvider
from azure.identity import AzureCliCredential
@tool
def get_current_time(location: str) -> str:
"""Get the current time for a given location"""
...
# ایجاد کلاینت
provider = AzureAIProjectAgentProvider(credential=AzureCliCredential())
# ایجاد یک عامل و اجرای آن با ابزار
agent = await provider.create_agent(name="TimeAgent", instructions="Use available tools to answer questions.", tools=get_current_time)
response = await agent.run("What time is it?")
سرویس عامل هوش مصنوعی آزور
سرویس عامل هوش مصنوعی آزور یک چارچوب عاملی جدیدتر است که به توسعهدهندگان امکان میدهد بدون نیاز به مدیریت منابع محاسباتی و ذخیرهسازی زیرساختی، عاملهای هوش مصنوعی با کیفیت بالا، قابل توسعه و امن بسازند، استقرار دهند و مقیاس کنند. این سرویس مخصوصاً برای برنامههای سازمانی کاربردی است زیرا یک سرویس کاملاً مدیریت شده با امنیت سازمانی محسوب میشود.
در مقایسه با توسعه مستقیم با API مدل زبانی بزرگ، سرویس عامل هوش مصنوعی آزور برخی مزایا دارد، از جمله:
- فراخوانی خودکار ابزار – نیازی به تجزیه فراخوانی ابزار، اجرای آن و مدیریت پاسخ نیست؛ همه اینها اکنون در سمت سرور انجام میشود
- مدیریت امن دادهها – به جای مدیریت وضعیت گفتگو به صورت دستی، میتوانید روی رشتهها برای ذخیره همه اطلاعات مورد نیاز حساب کنید
- ابزارهای آماده – ابزارهایی که میتوانید برای تعامل با منابع داده خود استفاده کنید، مانند Bing، Azure AI Search، و Azure Functions.
ابزارهای موجود در سرویس عامل AI آزور به دو دسته تقسیم میشوند:
- ابزارهای دانش:
- ابزارهای عمل:
این سرویس به ما امکان میدهد این ابزارها را به عنوان یک toolset با هم استفاده کنیم. همچنین از threads استفاده میکند که تاریخچه پیامها از یک مکالمه خاص را دنبال میکنند.
تصور کنید شما یک نماینده فروش در شرکتی به نام Contoso هستید. میخواهید یک عامل مکالمهای توسعه دهید که بتواند به سوالات مربوط به دادههای فروش شما پاسخ دهد.
تصویر زیر نشان میدهد چگونه میتوانید از سرویس عامل هوش مصنوعی آزور برای تحلیل دادههای فروش خود استفاده کنید:

برای استفاده از هر یک از این ابزارها با این سرویس، میتوانیم یک کلاینت ایجاد کرده و یک ابزار یا مجموعه ابزار تعریف کنیم. برای پیادهسازی عملی این کار میتوانیم از کد پایتون زیر استفاده کنیم. مدل زبانی بزرگ قادر خواهد بود مجموعه ابزار را ببیند و تصمیم بگیرد که آیا از تابع تعریفشده توسط کاربر fetch_sales_data_using_sqlite_query استفاده کند یا از مفسر کد از پیش ساخته شده، بسته به درخواست کاربر.
import os
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
from fetch_sales_data_functions import fetch_sales_data_using_sqlite_query # تابع fetch_sales_data_using_sqlite_query که در فایل fetch_sales_data_functions.py یافت میشود.
from azure.ai.projects.models import ToolSet, FunctionTool, CodeInterpreterTool
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# راهاندازی مجموعه ابزار
toolset = ToolSet()
# راهاندازی نماینده فراخوانی تابع با تابع fetch_sales_data_using_sqlite_query و افزودن آن به مجموعه ابزار
fetch_data_function = FunctionTool(fetch_sales_data_using_sqlite_query)
toolset.add(fetch_data_function)
# راهاندازی ابزار مفسر کد و افزودن آن به مجموعه ابزار.
code_interpreter = code_interpreter = CodeInterpreterTool()
toolset.add(code_interpreter)
agent = project_client.agents.create_agent(
model="gpt-4o-mini", name="my-agent", instructions="You are helpful agent",
toolset=toolset
)
ملاحظات ویژه برای استفاده از الگوی طراحی استفاده از ابزار جهت ساخت عاملهای هوش مصنوعی قابل اعتماد چیست؟
یک نگرانی رایج درباره SQL تولید شده پویا توسط مدلهای زبانی بزرگ امنیت است، به ویژه خطر تزریق SQL یا اقدامات مخرب مانند حذف یا دستکاری پایگاه داده. اگرچه این نگرانیها معتبر هستند، میتوان آنها را با پیکربندی صحیح سطح دسترسی پایگاه داده به طور مؤثری کاهش داد. برای بیشتر پایگاههای داده، این شامل تنظیم پایگاه داده در حالت فقط خواندنی است. برای سرویسهای پایگاه داده مانند PostgreSQL یا Azure SQL، باید به برنامه نقش فقط-خواندنی (SELECT) اختصاص داده شود.
اجرای برنامه در محیطی امن باعث افزایش حفاظت میشود. در سناریوهای سازمانی، دادهها معمولاً استخراج و از سیستمهای عملیاتی به یک پایگاه داده فقط خواندنی یا انبار داده با ساختار قابل فهم برای کاربر تبدیل میشوند. این رویکرد تضمین میکند که دادهها امن، برای کارایی و دسترسی بهینه شدهاند و برنامه دسترسی محدود و فقط-خواندنی دارد.
نمونه کدها
- پایتون: چارچوب عامل
- .NET: چارچوب عامل
سوالات بیشتری درباره الگوهای طراحی استفاده از ابزار دارید؟
به Microsoft Foundry Discord بپیوندید تا با سایر یادگیرندگان ملاقات کنید، در ساعتهای اداری شرکت کنید و سوالات خود درباره عاملهای هوش مصنوعی را بپرسید.
منابع بیشتر
- کارگاه سرویس عاملهای هوش مصنوعی آزور
- کارگاه چندعاملی نویسنده خلاق Contoso
- نمای کلی چارچوب عامل مایکروسافت
درس قبلی
درس بعدی
سلب مسئولیت: این سند با استفاده از سرویس ترجمه هوش مصنوعی Co-op Translator ترجمه شده است. در حالی که ما برای دقت تلاش میکنیم، لطفاً توجه داشته باشید که ترجمههای خودکار ممکن است حاوی اشتباهات یا نادرستیهایی باشند. سند اصلی به زبان مادری خود باید به عنوان مرجع معتبر در نظر گرفته شود. برای اطلاعات حیاتی، توصیه میشود از ترجمه حرفهای انسانی استفاده شود. ما مسئول هیچ گونه سوءتفاهم یا تفسیر نادرست ناشی از استفاده از این ترجمه نیستیم.