ai-agents-for-beginners
Using Agentic Protocols (MCP, A2A and NLWeb)

(Klikkaa yllä olevaa kuvaa katsoaksesi tämän oppitunnin videon)
Kun tekoälyagenttien käyttö kasvaa, kasvaa myös tarve protokollille, jotka varmistavat standardisoinnin, turvallisuuden ja tukevat avointa innovointia. Tässä oppitunnissa käsittelemme kolmea protokollaa, jotka pyrkivät täyttämään tämän tarpeen - Model Context Protocol (MCP), Agent to Agent (A2A) ja Natural Language Web (NLWeb).
Johdanto
Tässä oppitunnissa käsittelemme:
• Kuinka MCP antaa tekoälyagenteille pääsyn ulkoisiin työkaluihin ja tietoihin käyttäjän tehtävien suorittamiseksi.
• Kuinka A2A mahdollistaa viestinnän ja yhteistyön eri tekoälyagenttien välillä.
• Kuinka NLWeb tuo luonnollisen kielen käyttöliittymät mille tahansa verkkosivustolle, mahdollistaen tekoälyagenttien löytää ja olla vuorovaikutuksessa sisällön kanssa.
Oppimistavoitteet
• Tunnistaa MCP:n, A2A:n ja NLWebin keskeinen tarkoitus ja hyödyt tekoälyagenttien kontekstissa.
• Selittää miten kukin protokolla helpottaa viestintää ja vuorovaikutusta LLM:ien, työkalujen ja muiden agenttien välillä.
• Tunnistaa eri protokollien erilliset roolit monimutkaisten agenttijärjestelmien rakentamisessa.
Model Context Protocol
Model Context Protocol (MCP) on avoin standardi, joka tarjoaa standardoidun tavan sovelluksille tarjota kontekstia ja työkaluja LLM:ille. Tämä mahdollistaa “universaalin sovittimen” eri tietolähteisiin ja työkaluihin, joihin tekoälyagentit voivat kytkeytyä johdonmukaisella tavalla.
Katsotaan MCP:n osia, etuja verrattuna suoraan API:n käyttöön, ja esimerkki siitä, miten tekoälyagentit voisivat käyttää MCP-palvelinta.
MCP:n ydinkomponentit
MCP toimii asiakas-palvelin-arkkitehtuurilla ja ydinosa-alueet ovat:
• Hostit ovat LLM-sovelluksia (esimerkiksi koodieditori kuten VSCode), jotka aloittavat yhteydet MCP-palvelimeen.
• Clientit ovat isäntäohjelman komponentteja, jotka ylläpitävät yksi-yhteen -yhteyksiä palvelimiin.
• Palvelimet ovat kevyitä ohjelmia, jotka tarjoavat tiettyjä kyvykkyyksiä.
Protokollaan kuuluu kolme keskeistä primitiiviä, jotka ovat MCP-palvelimen kyvykkyydet:
• Tools: Nämä ovat erillisiä toimintoja tai funktioita, joita tekoälyagentti voi kutsua suorittaakseen tietyn tehtävän. Esimerkiksi sääpalvelu saattaa tarjota “hae sää” -työkalun, tai verkkokaupan palvelin saattaisi tarjota “osta tuote” -työkalun. MCP-palvelimet mainostavat kunkin työkalun nimeä, kuvausta ja syöte/tuotosskeemaa kyvykkyyslistauksessaan.
• Resources: Nämä ovat vain-luku -tietoelementtejä tai dokumentteja, joita MCP-palvelin voi tarjota, ja klientit voivat hakea niitä tarvittaessa. Esimerkkejä ovat tiedostojen sisällöt, tietokantarekisterit tai lokitiedostot. Resurssit voivat olla tekstiä (kuten koodi tai JSON) tai binäärimuotoisia (kuten kuvat tai PDF:t).
• Prompts: Nämä ovat ennalta määritettyjä malleja, jotka tarjoavat ehdotettuja kehotteita, mahdollistaen monimutkaisempia työnkulkuja.
MCP:n edut
MCP tarjoaa merkittäviä etuja tekoälyagenteille:
• Dynaaminen työkalujen löytäminen: Agentit voivat dynaamisesti vastaanottaa luettelon saatavilla olevista työkaluista palvelimelta sekä kuvaukset siitä, mitä ne tekevät. Tämä eroaa perinteisistä API:ista, jotka usein vaativat staattista koodausta integraatioita varten, mikä tarkoittaa, että API-muutos edellyttää koodimuutoksia. MCP tarjoaa “integroi kerran” -lähestymistavan, mikä johtaa suurempaan mukautuvuuteen.
• Yhteentoimivuus eri LLM:ien välillä: MCP toimii eri LLM:ien kanssa, tarjoten joustavuutta vaihtaa ydintä arvioidakseen parempaa suorituskykyä.
• Standardoitu tietoturva: MCP sisältää standardoidun autentikointimenetelmän, mikä parantaa skaalautuvuutta lisättäessä pääsyä lisäisiin MCP-palvelimiin. Tämä on yksinkertaisempaa kuin eri avainten ja autentikointityyppien hallinta eri perinteisille API:ille.
MCP-esimerkki
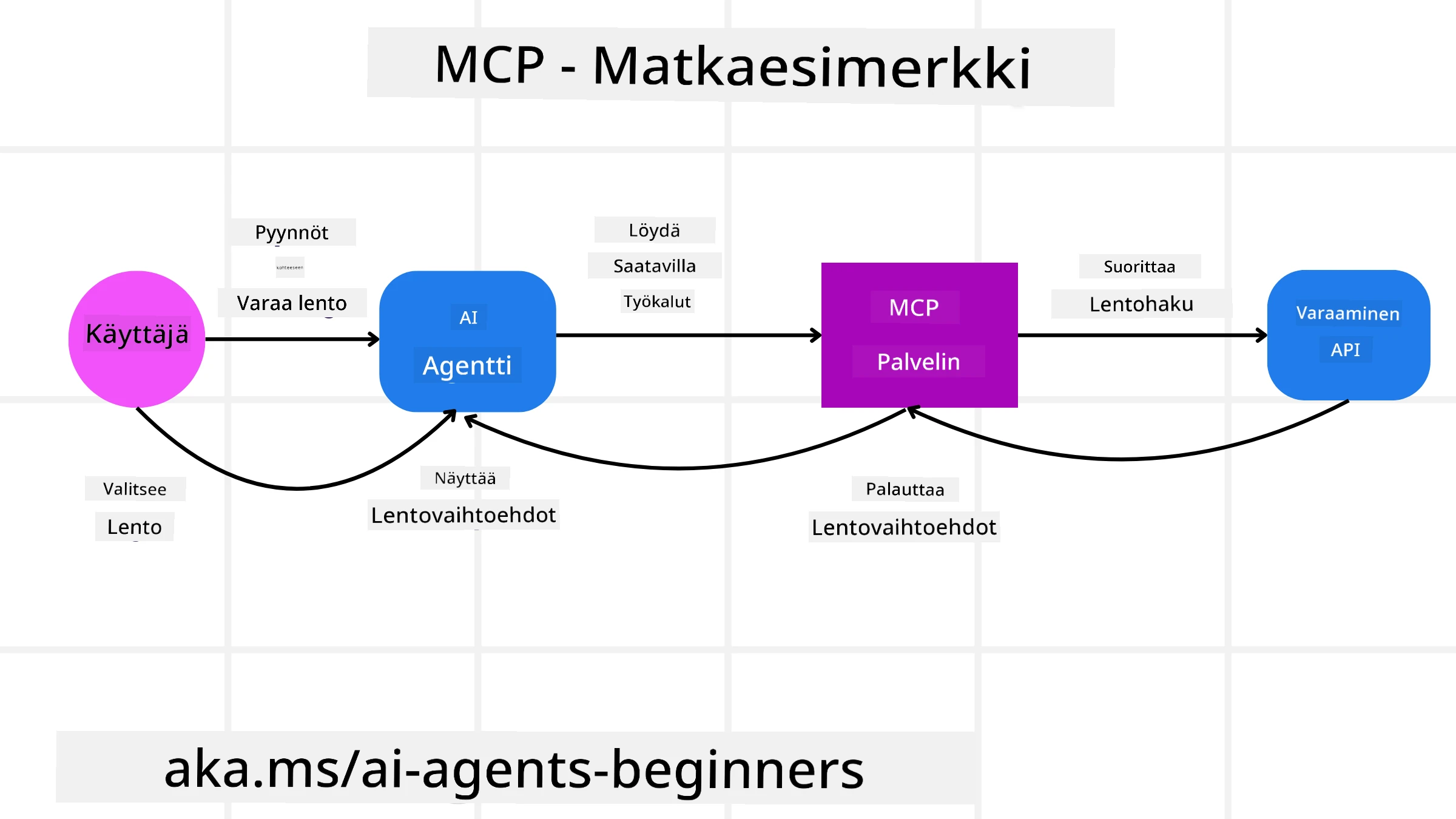
Kuvitellaan, että käyttäjä haluaa varata lennon käyttämällä MCP:llä varustettua tekoälyavustajaa.
-
Yhteys: Tekoälyavustaja (MCP-client) muodostaa yhteyden lentoyhtiön tarjoamaan MCP-palvelimeen.
-
Työkalujen löytäminen: Client kysyy lentoyhtiön MCP-palvelimelta: “Mitä työkaluja teillä on käytettävissä?” Palvelin vastaa työkaluilla kuten “hae lentoja” ja “varaa lentoja”.
-
Työkalun kutsuminen: Sitten pyydät tekoälyavustajaa: “Etsi lento Portlandista Honoluluun.” Tekoälyavustaja, käyttäen LLM:ään, tunnistaa, että sen täytyy kutsua “hae lentoja” -työkalua ja välittää MCP-palvelimelle tarvittavat parametrit (lähtöpaikka, määränpää).
-
Suoritus ja vastaus: MCP-palvelin, toimien kääreenä, tekee varsinaisen kutsun lentoyhtiön sisäiseen varaus-API:iin. Se vastaanottaa lentotiedot (esim. JSON-dataa) ja lähettää ne takaisin tekoälyavustajalle.
-
Lisävuorovaikutus: Tekoälyavustaja esittää lentovaihtoehdot. Kun valitset lennon, avustaja voi kutsua samaan MCP-palvelimeen kuuluvaa “varaa lento” -työkalua, jolloin varaus saadaan päätökseen.
Agent-to-Agent -protokolla (A2A)
Kun MCP keskittyy LLM:ien yhdistämiseen työkaluihin, Agent-to-Agent (A2A) vie sen askeleen pidemmälle mahdollistamalla viestinnän ja yhteistyön eri tekoälyagenttien välillä. A2A yhdistää tekoälyagentteja eri organisaatioiden, ympäristöjen ja teknologiakantojen välillä suorittaakseen yhteisen tehtävän.
Tutkimme A2A:n komponentteja ja etuja sekä esimerkkiä siitä, miten sitä voitaisiin soveltaa matkavarauksen sovelluksessamme.
A2A:n ydinkomponentit
A2A keskittyy mahdollistamaan agenttien välisen viestinnän ja niiden yhteistyön käyttäjän alatehtävän suorittamiseksi. Jokainen protokollan komponentti vaikuttaa tähän:
Agenttikortti
Samalla tavalla kuin MCP-palvelin jakaa luettelon työkaluista, Agenttikortti sisältää:
- Agentin nimi .
- Kuvaus yleisistä tehtävistä joita se suorittaa.
- Luettelo erityisistä taidoista kuvauksineen, jotka auttavat muita agenteja (tai jopa ihmiskäyttäjiä) ymmärtämään milloin ja miksi heidän kannattaa kutsua kyseistä agenttia.
- Agentin nykyinen Endpoint URL
- Agentin versio ja ominaisuudet, kuten striimaavat vastaukset ja push-ilmoitukset.
Agentin suorittaja
Agentin suorittaja on vastuussa käyttäjäkeskustelun kontekstin välittämisestä etäagentille, etäagentti tarvitsee tätä ymmärtääkseen suorittettavan tehtävän. A2A-palvelimessa agentti käyttää omaa suurta kielimalliensa (LLM) versiota jäsentääkseen saapuvat pyynnöt ja suorittaakseen tehtäviä käyttämällä omia sisäisiä työkalujaan.
Artefakti
Kun etäagentti on suorittanut pyydetyn tehtävän, sen työn tulos luodaan artefaktina. Artefakti sisältää agentin työn tuloksen, kuvauksen siitä, mitä tehtiin, ja tekstikontekstin, joka lähetetään protokollan kautta. Kun artefakti on lähetetty, yhteys etäagenttiin suljetaan, kunnes sitä taas tarvitaan.
Tapahtumajono
Tätä komponenttia käytetään päivitysten käsittelyyn ja viestien välittämiseen. Se on erityisen tärkeä tuotannossa agenttijärjestelmille estämään agenttien välisen yhteyden sulkeutuminen ennen tehtävän valmistumista, etenkin kun tehtävien suorittamisaika voi olla pidempi.
A2A:n edut
• Parantunut yhteistyö: Se mahdollistaa eri toimittajien ja alustojen agenttien välisen vuorovaikutuksen, kontekstin jakamisen ja yhteistyön, mikä helpottaa saumattomia automaatioita perinteisesti erillisten järjestelmien välillä.
• Mallin valinnan joustavuus: Jokainen A2A-agentti voi päättää, mitä LLM:iä se käyttää palvellakseen pyyntöjään, jolloin agenttikohtaisesti voidaan käyttää optimoituja tai hienosäädettyjä malleja, toisin kuin joissain MCP-skenaarioissa yhden LLM-yhteyden käyttö.
• Sisäänrakennettu todennus: Todennus on integroitu suoraan A2A-protokollaan, mikä tarjoaa vankan tietoturvakokonaisuuden agenttien välisille vuorovaikutuksille.
A2A-esimerkki
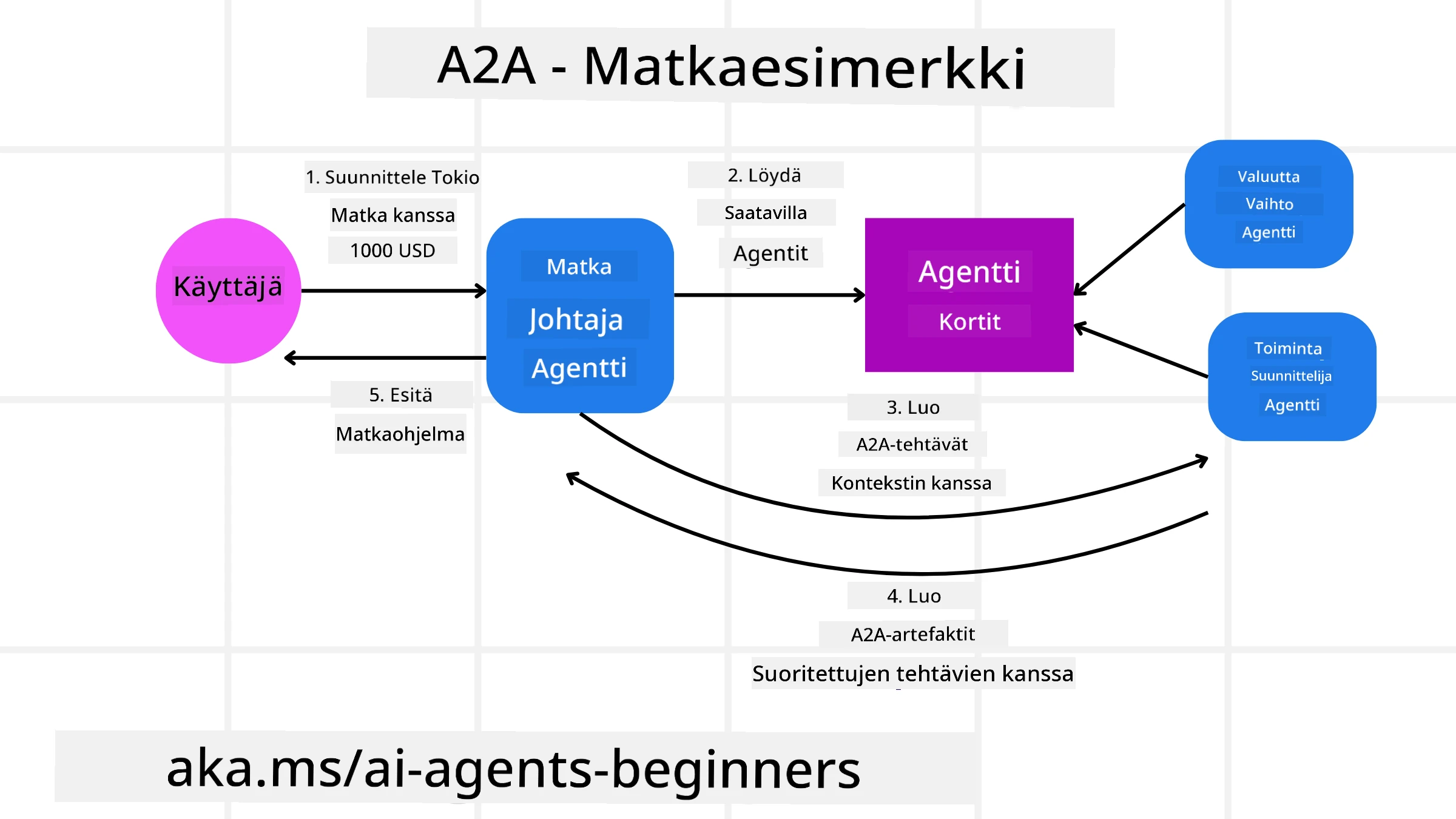
Laajennetaan matkavarausehdotustamme käyttäen nyt A2A:ta.
-
Käyttäjän pyyntö moniantturiin: Käyttäjä on vuorovaikutuksessa “Matka-agentin” A2A-client/agentin kanssa, esimerkiksi sanoen: “Varaa koko matka Honoluluun ensi viikoksi, mukaan lukien lennot, hotelli ja vuokra-auto”.
-
Matka-agentin orkestrointi: Matka-agentti vastaanottaa tämän monimutkaisen pyynnön. Se käyttää LLM:ään pohtiakseen tehtävää ja päättää, että sen täytyy olla yhteydessä muihin erikoistuneisiin agenteihin.
-
Agenttien välinen viestintä: Matka-agentti käyttää sitten A2A-protokollaa yhdistääkseen alavirran agenteihin, kuten “Lentoyhtiö-agenttiin”, “Hotelli-agenttiin” ja “Autovuokra-agenttiin”, jotka ovat eri yritysten tekemiä.
-
Tehtävän delegointi: Matka-agentti lähettää näille erikoistuneille agenteille tarkat tehtävät (esim. “Etsi lennot Honoluluun”, “Varaa hotelli”, “Vuokraa auto”). Kukin näistä erikoistuneista agenteista, ajettaessa omilla LLM:illään ja käyttäen omia työkalujaan (joista osa voi olla MCP-palvelimia), suorittaa oman osansa varauksesta.
-
Koottu vastaus: Kun kaikki alavirran agentit ovat suorittaneet tehtävänsä, Matka-agentti kokoaa tulokset (lentotiedot, hotellivahvistus, autovuokrausvaraus) ja lähettää käyttäjälle kattavan, keskustelutyylisen vastauksen.
Natural Language Web (NLWeb)
Verkkosivustot ovat pitkään olleet ensisijainen tapa, jolla käyttäjät pääsevät käsiksi tietoihin ja dataan internetissä.
Katsotaan NLWebin eri komponentteja, NLWebin etuja ja esimerkki siitä, miten NLWeb toimii matkavarauksen sovelluksessamme.
NLWebin komponentit
-
NLWeb Application (Core Service Code): Järjestelmä, joka käsittelee luonnollisen kielen kysymyksiä. Se yhdistää alustan eri osat luodakseen vastauksia. Voit ajatella sitä verkkosivuston luonnollisen kielen ominaisuuksien moottorina.
-
NLWeb Protocol: Tämä on perustava sääntöjoukko luonnollisen kielen vuorovaikutukselle verkkosivuston kanssa. Se palauttaa vastauksia JSON-muodossa (usein käyttäen Schema.orgia). Tavoitteena on luoda yksinkertainen perusta “AI-webille” samalla tavalla kuin HTML teki mahdolliseksi dokumenttien jakamisen verkossa.
-
MCP Server (Model Context Protocol Endpoint): Jokainen NLWeb-asennus toimii myös MCP-palvelimena. Tämä tarkoittaa, että se voi jakaa työkaluja (kuten “ask”-metodin) ja dataa muiden AI-järjestelmien kanssa. Käytännössä tämä tekee sivuston sisällöstä ja toiminnoista käytettävissä olevia tekoälyagenteille, jolloin sivusto voi tulla osaksi laajempaa “agenttiekosysteemiä”.
-
Embedding Models: Näitä malleja käytetään muuntamaan verkkosivuston sisältö numeerisiksi esityksiksi, niin kutsutuiksi vektoreiksi (upotuksiksi). Nämä vektorit kuvaavat merkitystä tavalla, jonka avulla tietokoneet voivat vertailla ja hakea niitä. Ne tallennetaan erikoistuneeseen tietokantaan, ja käyttäjät voivat valita, mitä upotusmallia he haluavat käyttää.
-
Vector Database (Retrieval Mechanism): Tämä tietokanta tallentaa verkkosivuston sisällön upotukset. Kun joku esittää kysymyksen, NLWeb tarkistaa vektoritietokannan löytääkseen nopeasti relevantin tiedon. Se palauttaa nopean listan mahdollisista vastauksista, lajiteltuna samankaltaisuuden mukaan. NLWeb toimii eri vektorivarastojärjestelmien kanssa, kuten Qdrant, Snowflake, Milvus, Azure AI Search ja Elasticsearch.
NLWeb-esimerkki
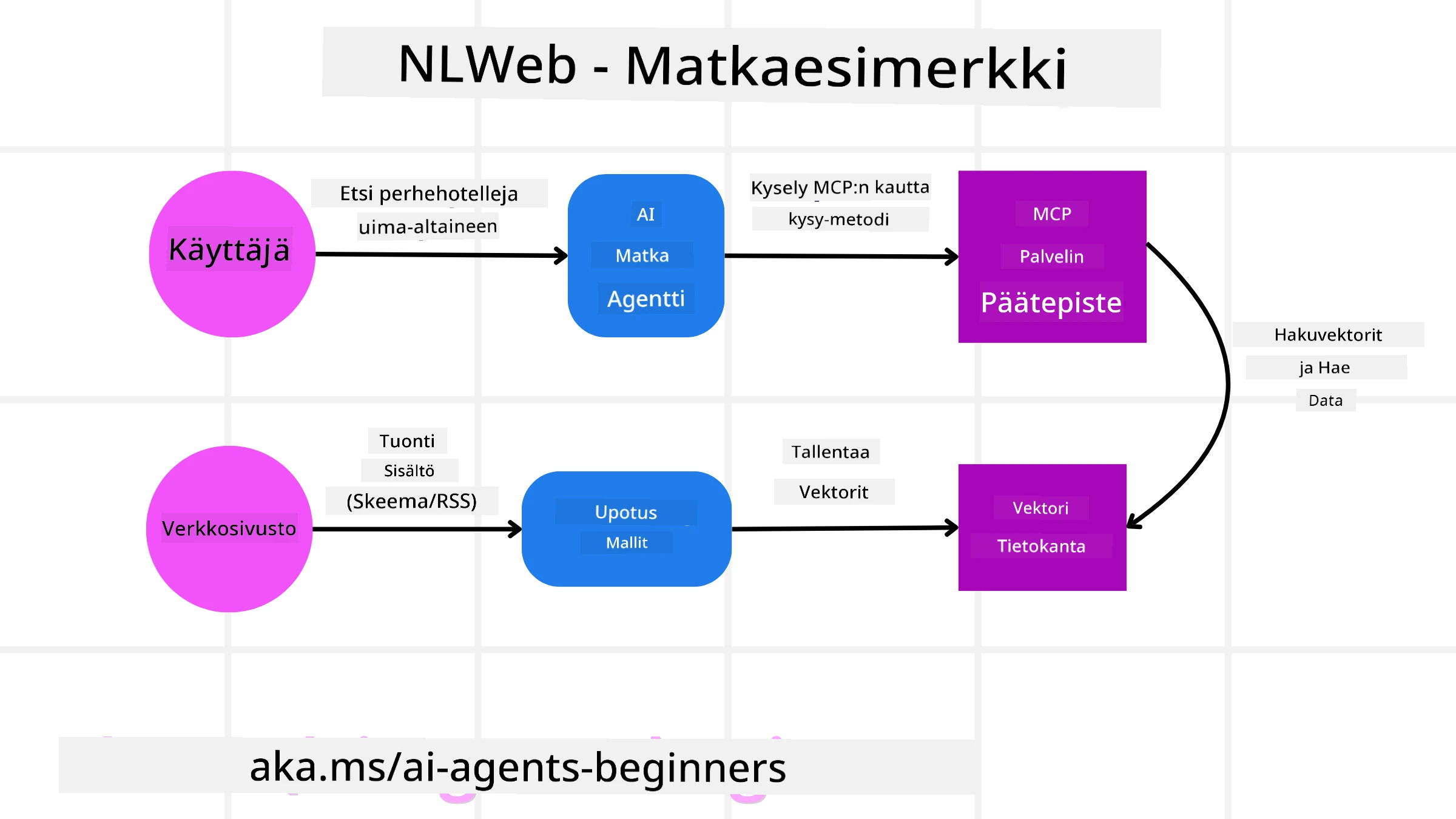
Ajatellaan jälleen matkavarauksen verkkosivustoamme, mutta tällä kertaa se on käytössä NLWebin avulla.
-
Datan tuonti: Matkailusivuston olemassa olevat tuotekatalogit (esim. lentoluettelot, hotellikuvaustekstit, retkipaketit) muotoillaan käyttämällä Schema.orgia tai tuodaan RSS-syötteiden kautta. NLWebin työkalut imevät tätä jäsenneltyä dataa, luovat upotuksia ja tallentavat ne paikalliseen tai etätallennukseen vektoripankkiin.
-
Luonnollisen kielen kysely (ihminen): Käyttäjä vierailee sivustolla ja sen sijaan, että selaisi valikoita, kirjoittaa keskusteluikkunaan: “Etsi perheystävällinen hotelli Honolulusta, jossa on uima-allas ensi viikoksi”.
-
NLWebin käsittely: NLWeb-sovellus vastaanottaa tämän kyselyn. Se lähettää kyselyn ymmärtämistä varten LLM:lle ja samanaikaisesti hakee vektoritietokannastaan relevantteja hotellimerkintöjä.
-
Tarkat tulokset: LLM auttaa tulkitsemaan tietokannasta saadut hakutulokset, tunnistamaan parhaat osumat kriteerien “perheystävällinen”, “uima-allas” ja “Honolulu” perusteella, ja muotoilemaan luonnollisenkielisen vastauksen. Oleellista on, että vastaus viittaa sivuston katalogista löytyviin todellisiin hotelleihin, välttäen keksittyä tietoa.
-
AI-agenttien vuorovaikutus: Koska NLWeb toimii MCP-palvelimena, ulkoinen AI-matka-agentti voisi myös muodostaa yhteyden tämän sivuston NLWeb-instanssiin. AI-agentti voisi sitten käyttää
ask-MCP-metodia kysyäkseen sivustolta suoraan:ask("Are there any vegan-friendly restaurants in the Honolulu area recommended by the hotel?"). NLWeb-instanssi käsittelisi tämän hyödyntäen omaa ravintolatietokantaansa (jos se on ladattu) ja palauttaisi jäsennellyn JSON-vastauksen.
Onko sinulla lisää kysymyksiä MCP/A2A/NLWeb?
Liity Microsoft Foundry Discord tapaat muita oppijoita, osallistut toimistoaikoihin ja saat vastauksia AI-agenttikysymyksiisi.
Resurssit
Vastuuvapauslauseke: Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator (https://github.com/Azure/co-op-translator). Vaikka pyrimme tarkkuuteen, huomioithan, että automatisoidut käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäistä asiakirjaa sen alkuperäisellä kielellä tulee pitää pätevänä lähteenä. Tärkeiden tietojen kohdalla suositellaan ammattimaisen ihmiskääntäjän tekemää käännöstä. Emme ole vastuussa mistään tämän käännöksen käytöstä johtuvista väärinymmärryksistä tai virheillisistä tulkinnoista.