ai-agents-for-beginners
Kontekstisuunnittelu tekoälyagenteille

(Napsauta yllä olevaa kuvaa katsoaksesi tämän oppitunnin videon)
Kontekstin monimutkaisuuden ymmärtäminen sovelluksessa, jota rakennat tekoälyagentille, on tärkeää luotettavan agentin tekemiseksi. Meidän täytyy rakentaa tekoälyagentteja, jotka hallitsevat tietoa tehokkaasti käsittelemään monimutkaisempia tarpeita kuin pelkkä kehotteiden suunnittelu.
Tässä oppitunnissa tarkastelemme, mitä kontekstisuunnittelu on ja mikä rooli sillä on tekoälyagenttien rakentamisessa.
Johdanto
Tässä oppitunnissa käsitellään:
• Mitä kontekstisuunnittelu on ja miksi se eroaa kehotteiden suunnittelusta.
• Tehokkaan kontekstisuunnittelun strategiat, mukaan lukien kuinka kirjoittaa, valita, tiivistää ja eristää tietoa.
• Yleiset kontekstivirheet, jotka voivat sabotoida tekoälyagenttisi, ja miten korjata ne.
Oppimistavoitteet
Tämän oppitunnin suorittamisen jälkeen osaat:
• Määritellä kontekstisuunnittelun ja erottaa sen kehotteiden suunnittelusta.
• Tunnistaa kontekstin keskeiset osat suurten kielimallien (LLM) sovelluksissa.
• Soveltaa strategioita kontekstin kirjoittamiseen, valintaan, tiivistämiseen ja eristämiseen agentin suorituskyvyn parantamiseksi.
• Tunnistaa yleiset kontekstivirheet kuten saastuminen, häiriö, sekaannus ja ristiriita, sekä ottaa käyttöön lieventämistekniikoita.
Mikä on kontekstisuunnittelu?
Konteksti on se, mikä ohjaa tekoälyagentin suunnittelua suorittamaan tiettyjä toimia. Kontekstisuunnittelu on käytäntö, jossa varmistetaan, että tekoälyagentilla on oikeat tiedot tehtävän seuraavan vaiheen suorittamiseksi. Kontekstivyöhyke on kooltaan rajallinen, joten agenttien rakentajina meidän on luotava järjestelmiä ja prosesseja, jotka hallitsevat tiedon lisäämistä, poistamista ja tiivistämistä kontekstivyöhykkeessä.
Kehotteen suunnittelu vs kontekstisuunnittelu
Kehotteen suunnittelu keskittyy yhteen joukkoon staattisia ohjeita, jotka ohjaavat tekoälyagentteja säännöstön avulla. Kontekstisuunnittelu puolestaan käsittelee dynaamisen tietokokonaisuuden hallintaa, mukaan lukien alkuperäinen kehotteen sisältö, varmistaen että tekoälyagentilla on tarvittavat tiedot ajan myötä. Keskeinen ajatus kontekstisuunnittelussa on tehdä tästä prosessista toistettava ja luotettava.
Kontekstin tyypit
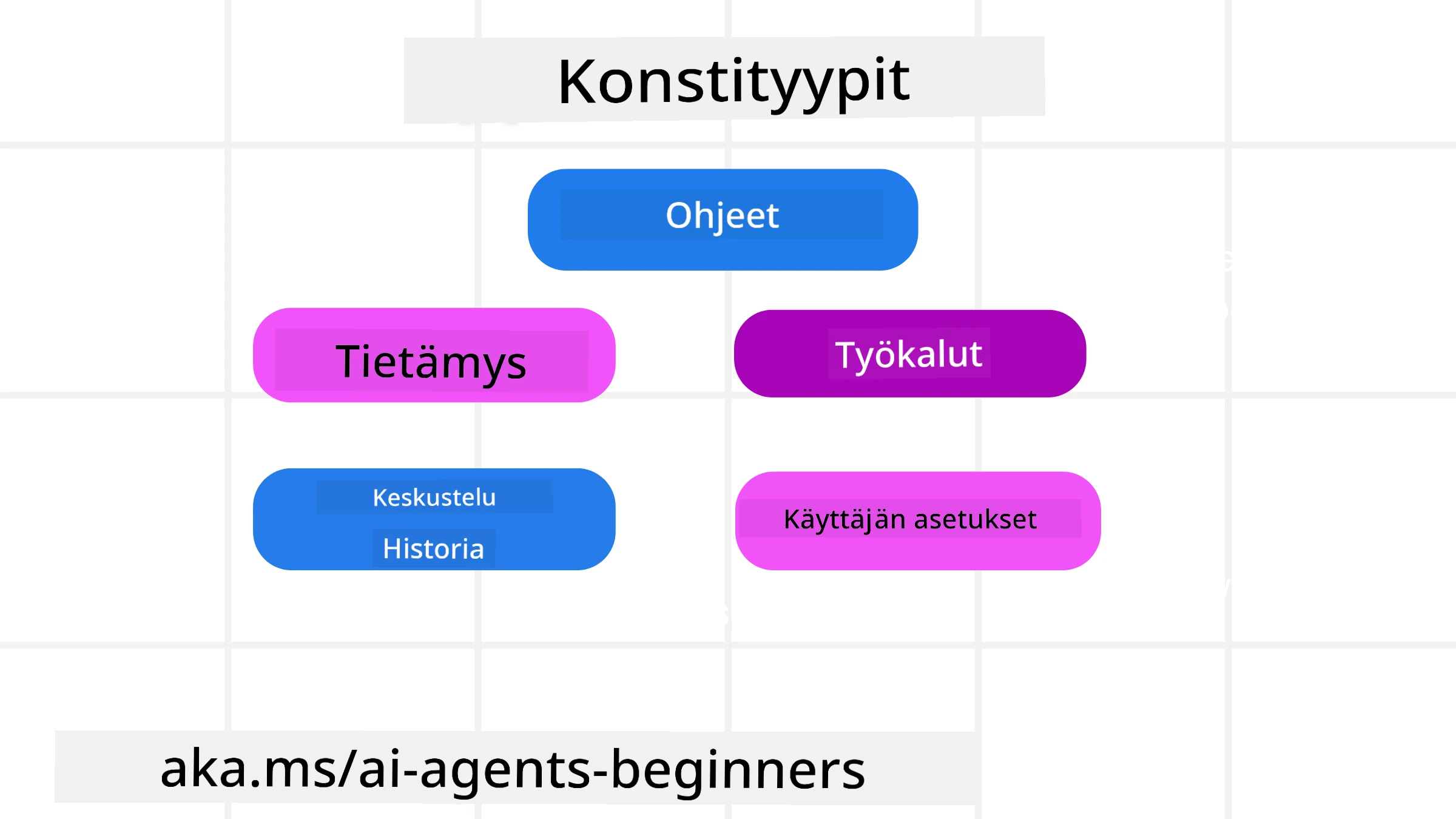
On tärkeää muistaa, että konteksti ei ole vain yksi asia. Tieto jota tekoälyagentti tarvitsee voi tulla monista eri lähteistä, ja meidän vastuullamme on varmistaa, että agentilla on pääsy näihin lähteisiin:
Kontekstin tyypit, joita tekoälyagentin pitää hallita, sisältävät:
• Ohjeet: Nämä ovat kuin agentin “säännöt” – kehotteet, järjestelmäviestit, few-shot-esimerkit (näyttäen tekoälylle, miten tehdä jotain) ja kuvaukset työkaluista, joita se voi käyttää. Tässä kehotteiden suunnittelun ja kontekstisuunnittelun painopisteet yhdistyvät.
• Tietämys: Tämä kattaa faktat, tietokannoista haetun tiedon tai agentin keräämät pitkäaikaiset muistot. Tämä voi sisältää Retrieval Augmented Generation (RAG) -järjestelmän integroinnin, jos agentin täytyy päästä eri tietovarastoihin ja tietokantoihin.
• Työkalut: Nämä ovat ulkoisten funktioiden, API:en ja MCP Servers -palvelimien määritelmiä, joita agentti voi kutsua, sekä palaute (tulokset), jonka se saa niiden käytöstä.
• Keskusteluhistoria: Käyttäjän kanssa käytävä jatkuva vuoropuhelu. Ajan kuluessa nämä keskustelut pitenevät ja monimutkaistuvat, mikä vie tilaa kontekstivyöhykkeeltä.
• Käyttäjän mieltymykset: Tietoja käyttäjän mieltymyksistä tai epämiellyttävyydestä ajan myötä. Näitä voidaan tallentaa ja kutsua esiin tehdessä keskeisiä päätöksiä käyttäjän auttamiseksi.
Tehokkaan kontekstisuunnittelun strategiat
Suunnittelustrategiat
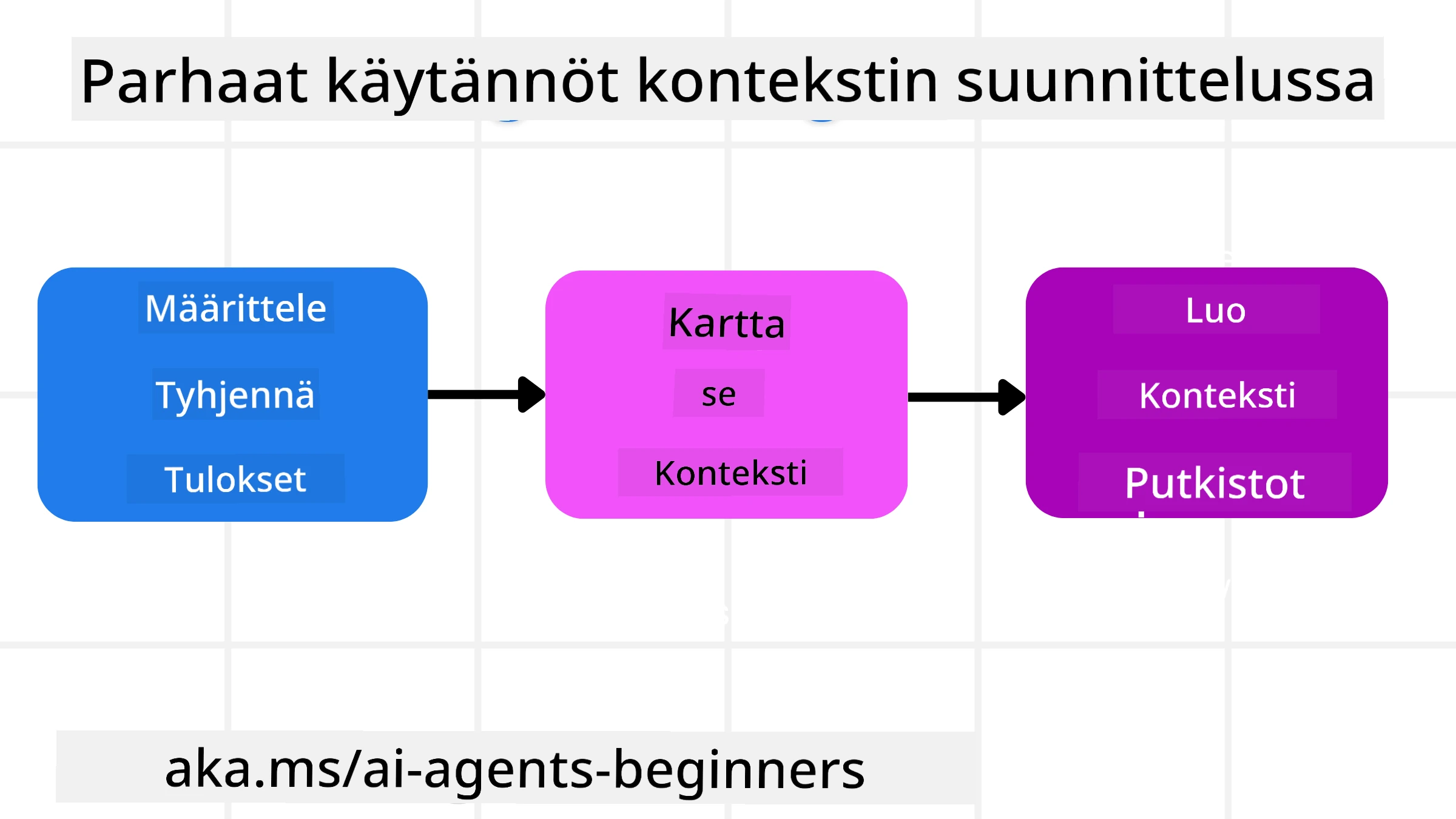
Hyvä kontekstisuunnittelu alkaa hyvästä suunnittelusta. Tässä lähestymistapa, joka auttaa sinua miettimään, miten soveltaa kontekstisuunnittelun käsitettä:
- Määrittele selkeät tulokset - Ne tehtävän tulokset, jotka tekoälyagenteille annetaan, tulisi määritellä selkeästi. Vastaa kysymykseen - “Miltä maailma näyttää, kun tekoälyagentti on suorittanut tehtävänsä?” Toisin sanoen, mikä muutos, tieto tai vastaus käyttäjälle tulisi jäädä vuorovaikutuksen jälkeen.
- Kartoitus kontekstista - Kun olet määritellyt tekoälyagentin tulokset, sinun pitää vastata kysymykseen “Mitä tietoja tekoälyagentti tarvitsee tämän tehtävän suorittamiseksi?”. Näin voit alkaa kartoittaa, mistä nämä tiedot löytyvät.
- Luo kontekstiputkistot - Kun tiedät, mistä tieto löytyy, sinun on vastattava kysymykseen “Miten agentti saa nämä tiedot?”. Tämä voidaan tehdä monin tavoin, mukaan lukien RAG, MCP-palvelimien ja muiden työkalujen käyttö.
Käytännön strategiat
Suunnittelu on tärkeää, mutta kun tieto alkaa virrata agentin kontekstivyöhykkeelle, tarvitsemme käytännön strategioita sen hallintaan:
Kontekstin hallinta
Vaikka osa tiedoista lisätään kontekstivyöhykkeelle automaattisesti, kontekstisuunnittelu tarkoittaa aktiiviisempaa roolia tämän tiedon hallinnassa, mikä voidaan toteuttaa muutamilla strategioilla:
-
Agentin muistilehtiö Tämä mahdollistaa tekoälyagentin ottaa muistiinpanoja tehtävien ja käyttäjävuorovaikutusten kannalta merkityksellisistä tiedoista yhden istunnon aikana. Tämän tulisi sijaita kontekstivyöhykkeen ulkopuolella tiedostossa tai ajonaikaisessa objektissa, jonka agentti voi myöhemmin noutaa tämän istunnon aikana tarvittaessa.
-
Muistot Muistilehtiöt ovat hyviä hallitsemaan tietoa yhden istunnon kontekstivyöhykkeen ulkopuolella. Muistot mahdollistavat agenttien tallentaa ja hakea merkityksellistä tietoa useiden istuntojen yli. Tämä voi sisältää tiivistelmiä, käyttäjäpreferenssejä ja palautetta tulevia parannuksia varten.
-
Kontekstin tiivistäminen Kun kontekstivyöhyke kasvaa ja on lähellä rajaa, voidaan käyttää tekniikoita kuten tiivistämistä ja karsimista. Tämä sisältää joko vain olennaisimpien tietojen säilyttämisen tai vanhempien viestien poistamisen.
-
Moniagenttijärjestelmät Moniagenttijärjestelmän kehittäminen on eräänlaista kontekstisuunnittelua, koska jokaisella agentilla on oma kontekstivyöhykkeensä. Miten tuo konteksti jaetaan ja välitetään eri agenteille on toinen asia, joka on suunniteltava näitä järjestelmiä rakennettaessa.
-
Hiekkalaatikkoympäristöt Jos agentin pitää suorittaa koodia tai käsitellä suuria määriä tietoa dokumentissa, tulosten käsittely voi vaatia paljon tokeneita. Sen sijaan, että kaikki tallennettaisiin kontekstivyöhykkeelle, agentti voi käyttää hiekkalaatikkoympäristöä, joka pystyy ajamaan koodin ja lukemaan vain tulokset ja muun relevantin tiedon.
-
Suoritusajan tilaobjektit Tämä toteutetaan luomalla tietosisältöjen säiliöitä hallitsemaan tilanteita, joissa agentin pitää päästä tiettyihin tietoihin käsiksi. Monimutkaisessa tehtävässä tämä mahdollistaisi agentin tallentaa kunkin alitehtävän tulokset vaiheittain, jolloin konteksti pysyy yhteydessä vain kyseiseen alitehtävään.
Esimerkki kontekstisuunnittelusta
Let’s say we want an AI agent to “Varaa minulle matka Pariisiin.”
• A simple agent using only prompt engineering might just respond: “Selvä, milloin haluaisit matkustaa Pariisiin?”. Se käsitteli vain suoraa kysymystäsi sillä hetkellä, kun käyttäjä esitti sen.
• An agent using the context engineering strategies covered would do much more. Before even responding, its system might:
◦ Tarkistaa kalenterisi saatavilla olevien päivämäärien varalta (haettaessa reaaliaikaista dataa).
◦ Muistaa aiemmat matkailumieltymyksesi (pitkäaikaisesta muistista), kuten suosikkilentoyhtiösi, budjetin tai pidätkö suorista lennoista.
◦ Tunnistaa käytettävissä olevat työkalut lento- ja hotellivarauksia varten.
- Then, an example response could be: “Hei [Your Name]! Näen, että olet vapaa lokakuun ensimmäisellä viikolla. Haluatko, että etsin suoria lentoja Pariisiin [Preferred Airline] -yhtiöltä tavanomaisessa budjetissasi [Budget]?”. Tämä rikkaampi, kontekstia hyödyntävä vastaus havainnollistaa kontekstisuunnittelun voimaa.
Yleiset kontekstivirheet
Kontekstin saastuminen
Mitä se on: Kun hallusinaatio (LLM:n tuottama virheellinen tieto) tai virhe pääsee kontekstiin ja siihen viitataan jatkuvasti, agentti saattaa pyrkiä mahdottomiin tavoitteisiin tai kehittää järjettömiä strategioita.
Mitä tehdä: Ota käyttöön kontekstin validointi ja eristäminen. Vahvista tieto ennen sen lisäämistä pitkäaikaiseen muistiin. Jos mahdollinen saastuminen havaitaan, aloita uudesta kontekstisäikeestä estääksesi virheellisen tiedon leviämisen.
Matkanvarausesimerkki: Agenttisi havainnoi hallusinaationa suoran lennon pieneltä paikalliselta lentokentältä kaukana olevaan kansainväliseen kaupunkiin, joka ei todellisuudessa tarjoa kansainvälisiä lentoja. Tämä olematon lentotieto tallennetaan kontekstiin. Myöhemmin, kun pyydät agenttia varaamaan, se jatkaa mahdottoman reitin lippujen etsimistä, mikä johtaa toistuviin virheisiin.
Ratkaisu: Ota käyttöön vaihe, joka vahvistaa lennon olemassaolon ja reitit reaaliaikaisen API:n avulla ennen lennon yksityiskohtien lisäämistä agentin työskentelykontekstiin. Jos validointi epäonnistuu, virheellinen tieto “eristetään” eikä sitä käytetä jatkossa.
Kontekstihäiriö
Mitä se on: Kun konteksti kasvaa niin suureksi, että malli keskittyy liikaa kertynyttä historiaa kohtaan sen sijaan, että käyttäisi koulutuksessa oppimiaan asioita, mikä johtaa toistuviin tai hyödyttömiin toimintoihin. Mallit saattavat alkaa tehdä virheitä jo ennen kuin kontekstivyöhyke on täynnä.
Mitä tehdä: Käytä kontekstin tiivistämistä. Purista kertyneet tiedot säännöllisesti lyhyemmiksi tiivistelmiksi, säilyttäen tärkeät yksityiskohdat ja poistaen toistuvan historian. Tämä auttaa “nollaamaan” fokuksen.
Matkanvarausesimerkki: Olet keskustellut pitkään erilaisista unelmakohteista, mukaan lukien yksityiskohtainen kertomus rinkka- matkasta kaksi vuotta sitten. Kun lopulta pyydät **“etsi minulle edullinen lento ensi kuukaudelle,” agentti jumittuu vanhoihin, epäolennaisiin yksityiskohtiin ja jatkaa kyselyjä rinkkavarusteistasi tai aiemmista reitityksistä, laiminlyöden nykyisen pyyntösi.
Ratkaisu: Tietyn määrän vuorovaikutusten jälkeen tai kun konteksti kasvaa liian suureksi, agentin tulisi tiivistää keskustelun viimeisimmät ja olennaisimmat osat – keskittyen nykyisiin matkustuspäivämääriin ja määränpäähän – ja käyttää tätä tiivistettyä yhteenvetoa seuraavaa LLM-kutsua varten ja hylätä vähemmän relevantti historiallinen keskustelu.
Kontekstin sekaannus
Mitä se on: Kun tarpeeton konteksti, usein monien käytettävissä olevien työkalujen muodossa, saa mallin tuottamaan huonoja vastauksia tai kutsumaan epäolennaisia työkaluja. Pienemmät mallit ovat erityisen alttiita tälle.
Mitä tehdä: Toteuta työkalujen kuormanhallinta RAG-tekniikoita käyttäen. Tallenna työkalujen kuvaukset vektoritietokantaan ja valitse vain tehtävään kaikkein relevantimmat työkalut. Tutkimukset osoittavat, että työkalujen valinnan rajoittaminen alle 30:een on hyödyllistä.
Matkanvarausesimerkki: Agentillasi on pääsy kymmeniintuhansiin työkaluihin: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, etc. Kysyt: “Mikä on paras tapa liikkua Pariisissa?” Työkalujen lukumäärän vuoksi agentti hämmentyy ja yrittää kutsua book_flight Pariisin sisällä, tai rent_car vaikka suosisit julkista liikennettä, koska työkalukuvaukset saattavat olla päällekkäisiä tai se ei yksinkertaisesti pysty erottamaan parasta vaihtoehtoa.
Ratkaisu: Käytä RAG:ia työkalukuvausten yli. Kun kysyt liikkumismahdollisuuksista Pariisissa, järjestelmä hakee dynaamisesti vain relevantit työkalut kuten rent_car tai public_transport_info kyselysi perusteella ja esittää LLM:lle fokusoidun työkalukuormituksen.
Kontekstin ristiriita
Mitä se on: Kun kontekstissa on ristiriitaista tietoa, mikä johtaa epäjohdonmukaiseen päättelyyn tai huonoihin lopullisiin vastauksiin. Tämä tapahtuu usein, kun tieto saapuu vaiheittain ja aikaisemmat, virheelliset oletukset pysyvät kontekstissa.
Mitä tehdä: Käytä kontekstin karsintaa ja ulkoistamista. Karsinta tarkoittaa vanhentuneen tai ristiriitaisen tiedon poistamista uusien tietojen saapuessa. Ulkoistaminen tarkoittaa, että mallille annetaan erillinen “muistilehtiö”-työtila käsitellä tietoja ilman, että se sotkee pääkontekstia.
Matkanvarausesimerkki: Alkuun kerrot agentillesi, “Haluan lentää economy-luokassa.” Myöhemmin keskustelussa muutat mielesi ja sanot, “Itse asiassa tälle matkalle mennään business-luokkaan.” Jos molemmat ohjeet säilyvät kontekstissa, agentti saattaa saada ristiriitaisia hakutuloksia tai hämmentyä siitä, kumman mieltymyksen asettaa etusijalle.
Ratkaisu: Toteuta kontekstin karsinta. Kun uusi ohje on ristiriidassa vanhan kanssa, vanha ohje poistetaan tai korvataan eksplisiittisesti kontekstissa. Vaihtoehtoisesti agentti voi käyttää muistilehtiötä sovitellakseen ristiriitaisia mieltymyksiä ennen päätöksentekoa, varmistaen että vain lopullinen, yhtenäinen ohje ohjaa sen toimintaa.
Haluatko lisää kysymyksiä kontekstisuunnittelusta?
Liity Microsoft Foundry Discord tapaamaan muita oppijoita, osallistumaan toimistoaikoihin ja saamaan vastauksia tekoälyagentteihisi liittyviin kysymyksiin.
Vastuuvapauslauseke: Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator (https://github.com/Azure/co-op-translator). Vaikka pyrimme tarkkuuteen, ota huomioon, että automaattisissa käännöksissä saattaa esiintyä virheitä tai epätarkkuuksia. Alkuperäistä asiakirjaa sen alkuperäisellä kielellä tulee pitää pätevänä lähteenä. Kriittisten tietojen osalta suositellaan ammattikääntäjän tekemää käännöstä. Emme ole vastuussa mistään väärinymmärryksistä tai virhetulkinnoista, jotka johtuvat tämän käännöksen käytöstä.