ai-agents-for-beginners
Ingénierie du contexte pour les agents IA

(Cliquez sur l’image ci-dessus pour voir la vidéo de cette leçon)
Comprendre la complexité de l’application pour laquelle vous construisez un agent IA est important pour en faire un agent fiable. Nous devons construire des agents IA qui gèrent efficacement l’information pour répondre à des besoins complexes au-delà de l’ingénierie des invites.
Dans cette leçon, nous allons examiner ce qu’est l’ingénierie du contexte et son rôle dans la construction d’agents IA.
Introduction
Cette leçon couvrira :
• Ce qu’est l’ingénierie du contexte et pourquoi elle est différente de l’ingénierie des invites.
• Des stratégies pour une ingénierie du contexte efficace, notamment comment écrire, sélectionner, compresser et isoler l’information.
• Les échecs courants liés au contexte qui peuvent faire dérailler votre agent IA et comment les corriger.
Objectifs d’apprentissage
Après avoir terminé cette leçon, vous saurez comprendre comment :
• Définir l’ingénierie du contexte et la différencier de l’ingénierie des invites.
• Identifier les composants clés du contexte dans les applications de grands modèles de langage (LLM).
• Appliquer des stratégies pour écrire, sélectionner, compresser et isoler le contexte afin d’améliorer les performances de l’agent.
• Reconnaître les échecs courants du contexte tels que la contamination, la distraction, la confusion et le conflit, et mettre en œuvre des techniques d’atténuation.
Qu’est-ce que l’ingénierie du contexte ?
Pour les agents IA, le contexte est ce qui guide la planification d’un agent IA pour entreprendre certaines actions. L’ingénierie du contexte est la pratique qui consiste à s’assurer que l’agent IA dispose de la bonne information pour compléter l’étape suivante de la tâche. La fenêtre de contexte est limitée en taille, donc en tant que concepteurs d’agents, nous devons construire des systèmes et des processus pour gérer l’ajout, la suppression et la condensation de l’information dans cette fenêtre de contexte.
Ingénierie des invites vs Ingénierie du contexte
L’ingénierie des invites se concentre sur un ensemble statique unique d’instructions pour guider efficacement les agents IA avec un ensemble de règles. L’ingénierie du contexte concerne la gestion d’un ensemble dynamique d’informations, y compris l’invite initiale, pour s’assurer que l’agent IA dispose de ce dont il a besoin au fil du temps. L’idée principale autour de l’ingénierie du contexte est de rendre ce processus répétable et fiable.
Types de contexte
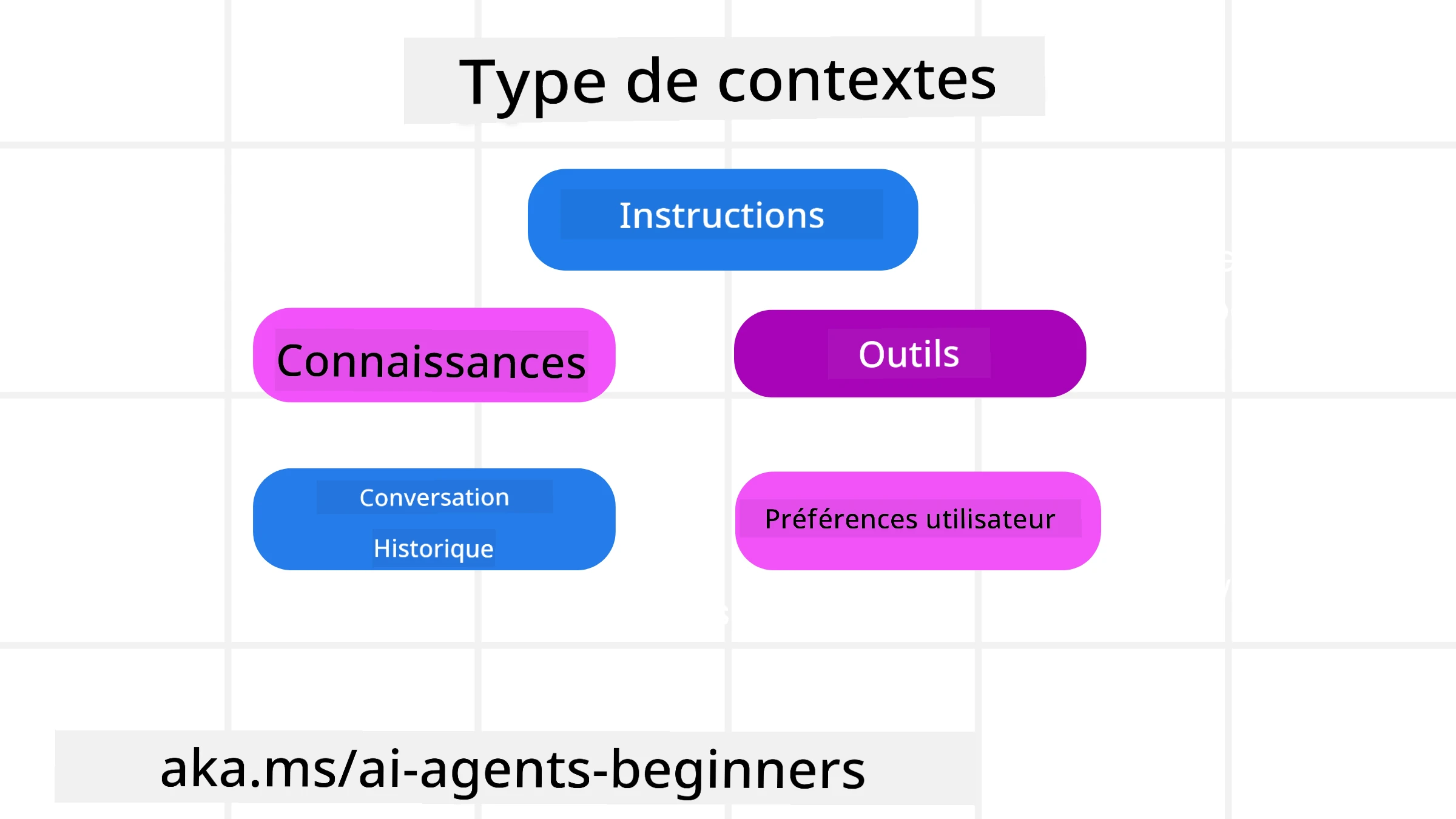
Il est important de se rappeler que le contexte n’est pas une seule chose. L’information dont l’agent IA a besoin peut provenir de diverses sources et il nous revient de veiller à ce que l’agent y ait accès :
Les types de contexte qu’un agent IA pourrait devoir gérer incluent :
• Instructions : Ce sont comme les « règles » de l’agent – des invites, des messages système, des exemples few-shot (montrant à l’IA comment faire quelque chose) et des descriptions des outils qu’il peut utiliser. C’est là où la focalisation de l’ingénierie des invites se combine avec celle de l’ingénierie du contexte.
• Connaissances : Cela couvre les faits, les informations extraites de bases de données ou les mémoires à long terme accumulées par l’agent. Cela inclut l’intégration d’un système de génération augmentée par récupération (RAG) si l’agent a besoin d’accéder à différentes bases de connaissances et bases de données.
• Outils : Ce sont les définitions de fonctions externes, APIs et serveurs MCP que l’agent peut appeler, ainsi que le retour (résultats) qu’il obtient de leur utilisation.
• Historique de conversation : Le dialogue en cours avec un utilisateur. Au fil du temps, ces conversations deviennent plus longues et complexes, ce qui signifie qu’elles occupent de l’espace dans la fenêtre de contexte.
• Préférences utilisateur : Informations apprises sur les goûts ou les dégoûts de l’utilisateur au fil du temps. Celles-ci peuvent être stockées et appelées lors de la prise de décisions clés pour aider l’utilisateur.
Stratégies pour une ingénierie du contexte efficace
Stratégies de planification
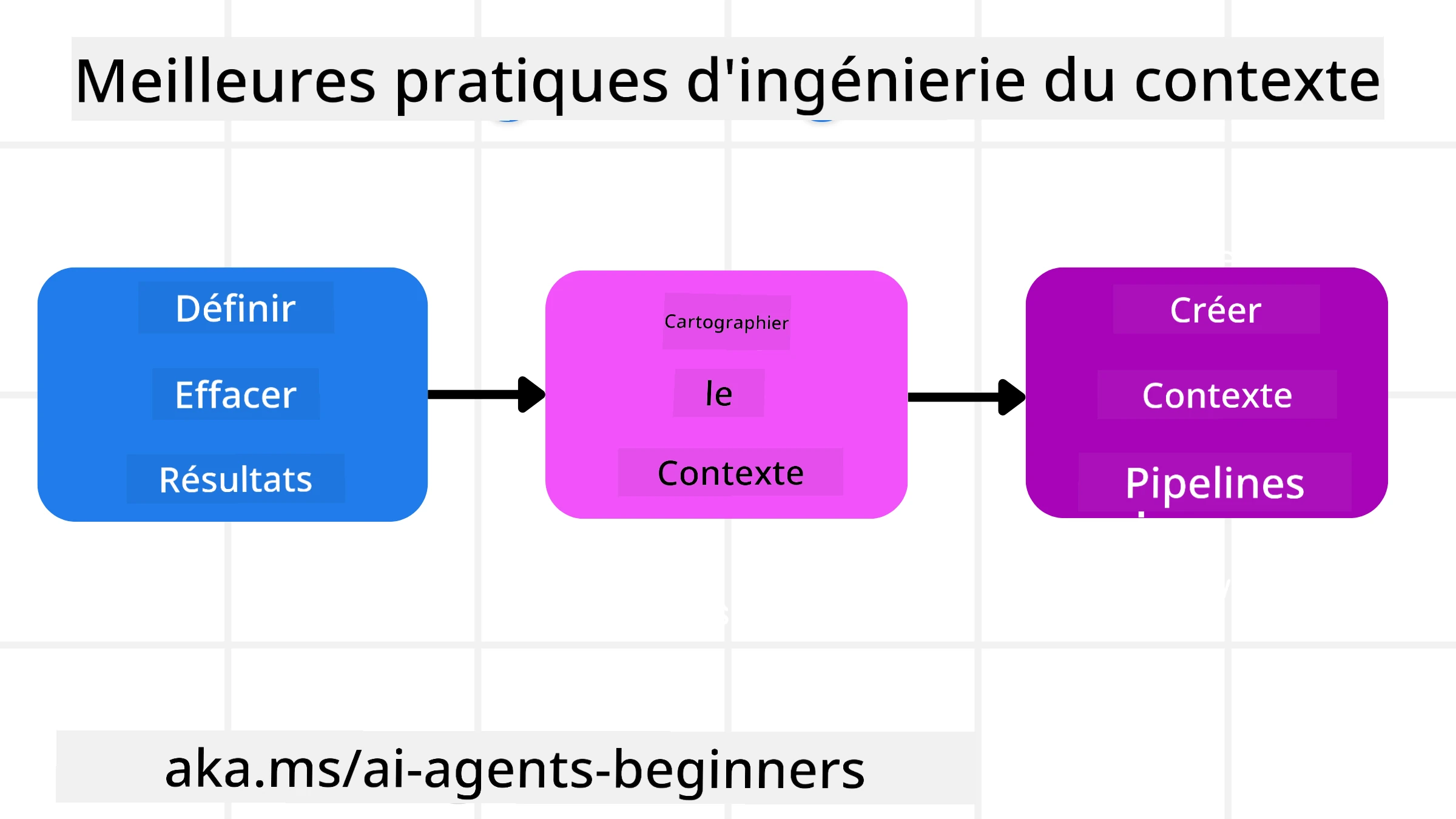
Une bonne ingénierie du contexte commence par une bonne planification. Voici une approche qui vous aidera à commencer à penser à la façon d’appliquer le concept d’ingénierie du contexte :
- Définir des résultats clairs - Les résultats des tâches qui seront assignées aux agents IA doivent être clairement définis. Répondez à la question - « À quoi ressemblera le monde lorsque l’agent IA aura terminé sa tâche ? » En d’autres termes, quel changement, quelle information ou quelle réponse l’utilisateur devrait-il avoir après avoir interagi avec l’agent IA.
- Cartographier le contexte - Une fois que vous avez défini les résultats de l’agent IA, vous devez répondre à la question « Quelles informations l’agent IA doit-il avoir pour accomplir cette tâche ? ». Ainsi, vous pouvez commencer à cartographier le contexte de l’endroit où ces informations peuvent se trouver.
- Créer des pipelines de contexte - Maintenant que vous savez où sont les informations, vous devez répondre à la question « Comment l’agent obtiendra-t-il ces informations ? ». Cela peut être fait de diverses façons, y compris le RAG, l’utilisation de serveurs MCP et d’autres outils.
Stratégies pratiques
La planification est importante mais une fois que l’information commence à affluer dans la fenêtre de contexte de notre agent, nous devons avoir des stratégies pratiques pour la gérer :
Gestion du contexte
Alors que certaines informations seront ajoutées automatiquement à la fenêtre de contexte, l’ingénierie du contexte consiste à prendre un rôle plus actif dans cette information, ce qui peut se faire par quelques stratégies :
-
Bloc-notes de l’agent
Cela permet à un agent IA de prendre des notes sur les informations pertinentes concernant les tâches en cours et les interactions avec l’utilisateur durant une seule session. Cela devrait exister en dehors de la fenêtre de contexte dans un fichier ou un objet d’exécution que l’agent peut ensuite récupérer durant cette session si nécessaire. -
Mémoires
Les bloc-notes sont utiles pour gérer l’information hors de la fenêtre de contexte d’une seule session. Les mémoires permettent aux agents de stocker et récupérer des informations pertinentes sur plusieurs sessions. Cela pourrait inclure des résumés, des préférences utilisateur et des retours pour des améliorations futures. -
Compression du contexte
Une fois que la fenêtre de contexte grandit et approche de sa limite, des techniques telles que la summarisation et la réduction peuvent être utilisées. Cela comprend soit garder seulement l’information la plus pertinente, soit supprimer les messages plus anciens. -
Systèmes multi-agents
Le développement de systèmes multi-agents est une forme d’ingénierie du contexte car chaque agent a sa propre fenêtre de contexte. La façon dont ce contexte est partagé et transmis aux différents agents est une autre chose à planifier lors de la construction de ces systèmes. -
Environnements Sandbox
Si un agent doit exécuter du code ou traiter de grandes quantités d’informations dans un document, cela peut prendre un grand nombre de tokens pour traiter les résultats. Plutôt que d’avoir tout cela stocké dans la fenêtre de contexte, l’agent peut utiliser un environnement sandbox capable d’exécuter ce code et ne lire que les résultats et autres informations pertinentes. -
Objets d’état d’exécution
Cela se fait en créant des conteneurs d’informations pour gérer les situations où l’agent doit avoir accès à certaines informations. Pour une tâche complexe, cela permettrait à un agent de stocker les résultats de chaque sous-tâche étape par étape, permettant au contexte de rester connecté uniquement à cette sous-tâche spécifique.
Exemple d’ingénierie du contexte
Disons que nous voulons qu’un agent IA « Me réserve un voyage à Paris. »
• Un agent simple utilisant uniquement l’ingénierie des invites pourrait simplement répondre : « D’accord, quand voulez-vous aller à Paris ? » Il a seulement traité votre question directe au moment où l’utilisateur l’a posée.
• Un agent utilisant les stratégies d’ingénierie du contexte abordées ferait beaucoup plus. Avant même de répondre, son système pourrait :
◦ Vérifier votre calendrier pour les dates disponibles (récupérant des données en temps réel).
◦ Se souvenir des préférences de voyage passées (à partir de la mémoire à long terme) comme votre compagnie aérienne préférée, votre budget, ou si vous préférez les vols directs.
◦ Identifier les outils disponibles pour la réservation de vols et d’hôtels.
- Ensuite, une réponse d’exemple pourrait être : « Salut [Votre Nom] ! Je vois que vous êtes libre la première semaine d’octobre. Dois-je chercher des vols directs vers Paris sur [Compagnie préférée] dans votre budget habituel de [Budget] ? ». Cette réponse plus riche et consciente du contexte montre la puissance de l’ingénierie du contexte.
Échecs courants liés au contexte
Contamination du contexte
Qu’est-ce que c’est : Lorsqu’une hallucination (information fausse générée par le LLM) ou une erreur entre dans le contexte et est référencée à répétition, ce qui pousse l’agent à poursuivre des objectifs impossibles ou à développer des stratégies absurdes.
Que faire : Mettre en place la validation du contexte et la mise en quarantaine. Validez les informations avant qu’elles ne soient ajoutées à la mémoire à long terme. Si une contamination potentielle est détectée, démarrez des fils de contexte neufs pour empêcher la propagation de la mauvaise information.
Exemple de réservation de voyage : Votre agent hallucine un vol direct depuis un petit aéroport local vers une grande ville internationale lointaine qui ne propose pas en réalité ce type de vol. Ce détail de vol inexistant est sauvegardé dans le contexte. Plus tard, lorsque vous demandez à l’agent de réserver, il continue d’essayer de trouver des billets pour cette route impossible, provoquant des erreurs répétées.
Solution : Implémenter une étape qui valide l’existence et les routes des vols avec une API en temps réel avant d’ajouter le détail du vol au contexte de travail de l’agent. Si la validation échoue, l’information erronée est « mise en quarantaine » et plus utilisée.
Distraction du contexte
Qu’est-ce que c’est : Lorsque le contexte devient si volumineux que le modèle se concentre trop sur l’historique accumulé au lieu d’utiliser ce qu’il a appris lors de l’entraînement, ce qui mène à des actions répétitives ou inutiles. Les modèles peuvent commencer à faire des erreurs même avant que la fenêtre de contexte soit pleine.
Que faire : Utiliser la summarisation du contexte. Compresser périodiquement l’information accumulée en résumés plus courts, en gardant les détails importants tout en supprimant l’historique redondant. Cela aide à « réinitialiser » l’attention.
Exemple de réservation de voyage : Vous discutez depuis longtemps de diverses destinations de rêve, y compris un récit détaillé de votre voyage en sac à dos d’il y a deux ans. Lorsque vous demandez finalement à « trouver un vol pas cher pour le mois prochain », l’agent se perd dans d’anciens détails hors sujet et continue de poser des questions sur votre équipement de randonnée ou vos anciens itinéraires, négligeant votre demande actuelle.
Solution : Après un certain nombre de tours ou lorsque le contexte devient trop lourd, l’agent doit résumer les parties les plus récentes et pertinentes de la conversation – en se concentrant sur vos dates et destination de voyage actuelles – et utiliser ce résumé condensé pour le prochain appel au LLM, en rejetant la conversation historique moins pertinente.
Confusion du contexte
Qu’est-ce que c’est : Lorsque du contexte inutile, souvent sous la forme d’un trop grand nombre d’outils disponibles, fait que le modèle génère de mauvaises réponses ou appelle des outils non pertinents. Les modèles plus petits sont particulièrement sujets à ce problème.
Que faire : Mettre en place la gestion de la charge d’outils en utilisant les techniques RAG. Stockez les descriptions d’outils dans une base de données vectorielle et sélectionnez seulement les outils les plus pertinents pour chaque tâche spécifique. La recherche montre qu’il faut limiter la sélection d’outils à moins de 30.
Exemple de réservation de voyage : Votre agent a accès à des dizaines d’outils : book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, etc. Vous demandez, « Quel est le meilleur moyen de se déplacer à Paris ? » En raison du nombre d’outils, l’agent se perd et tente d’appeler book_flight dans Paris, ou rent_car même si vous préférez les transports publics, parce que les descriptions d’outils peuvent se chevaucher ou il ne peut tout simplement pas discerner le meilleur choix.
Solution : Utiliser le RAG sur les descriptions des outils. Lorsque vous demandez comment se déplacer à Paris, le système récupère dynamiquement seulement les outils les plus pertinents comme rent_car ou public_transport_info en fonction de votre requête, présentant une « sélection » d’outils ciblée au LLM.
Conflit dans le contexte
Qu’est-ce que c’est : Lorsqu’il existe des informations contradictoires dans le contexte, ce qui conduit à un raisonnement incohérent ou à de mauvaises réponses finales. Cela se produit souvent lorsque l’information arrive en étapes et que les premières hypothèses incorrectes restent dans le contexte.
Que faire : Utiliser la taille du contexte et la délégation. La taille signifie retirer les informations obsolètes ou conflictuelles à mesure que de nouveaux détails arrivent. La délégation donne au modèle un espace “scratchpad” séparé pour traiter l’information sans encombrer le contexte principal.
Exemple de réservation de voyage : Vous dites initialement à votre agent, « Je veux voler en classe économique. » Plus tard dans la conversation, vous changez d’avis et dites, « En fait, pour ce voyage, prenons la classe affaires. » Si les deux instructions restent dans le contexte, l’agent pourrait recevoir des résultats contradictoires ou être confus quant à la préférence prioritaire.
Solution : Mettre en œuvre la taille du contexte. Lorsqu’une nouvelle instruction contredit une ancienne, l’ancienne est supprimée ou explicitement remplacée dans le contexte. Alternativement, l’agent peut utiliser un bloc-notes pour concilier les préférences conflictuelles avant de décider, garantissant que seule l’instruction finale cohérente guide ses actions.
Vous avez d’autres questions sur l’ingénierie du contexte ?
Rejoignez le Microsoft Foundry Discord pour rencontrer d’autres apprenants, assister aux heures de bureau et obtenir des réponses à vos questions sur les agents IA.
Avertissement :
Ce document a été traduit à l’aide du service de traduction automatique Co-op Translator. Bien que nous nous efforcions d’assurer l’exactitude, veuillez noter que les traductions automatiques peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue d’origine doit être considéré comme la source faisant foi. Pour les informations critiques, il est recommandé de recourir à une traduction professionnelle réalisée par un humain. Nous déclinons toute responsabilité en cas de malentendus ou de mauvaises interprétations résultant de l’utilisation de cette traduction.