ai-agents-for-beginners
एजेंटिक प्रोटोकॉल का उपयोग (MCP, A2A और NLWeb)

(ऊपर की छवि पर क्लिक करके इस पाठ का वीडियो देखें)
जैसे-जैसे AI एजेंटों का उपयोग बढ़ रहा है, मानकीकरण, सुरक्षा और खुला नवाचार सुनिश्चित करने के लिए प्रोटोकॉल की भी आवश्यकता बढ़ रही है। इस पाठ में, हम इस आवश्यकता को पूरा करने की कोशिश करने वाले 3 प्रोटोकॉल कवर करेंगे - Model Context Protocol (MCP), Agent to Agent (A2A) और Natural Language Web (NLWeb)।
परिचय
इस पाठ में, हम कवर करेंगे:
• कैसे MCP AI एजेंटों को उपयोगकर्ता कार्यों को पूरा करने के लिए बाहरी उपकरणों और डेटा तक पहुँचने की अनुमति देता है।
• कैसे A2A विभिन्न AI एजेंटों के बीच संचार और सहयोग सक्षम करता है।
• कैसे NLWeb किसी भी वेबसाइट पर प्राकृतिक भाषा इंटरफेस लाकर AI एजेंटों को सामग्री की खोज और उसके साथ इंटरैक्ट करने में सक्षम बनाता है।
सीखने के लक्ष्य
• Identify AI एजेंटों के संदर्भ में MCP, A2A, और NLWeb के मुख्य उद्देश्य और लाभों की पहचान करें।
• Explain कि प्रत्येक प्रोटोकॉल कैसे LLMs, उपकरणों, और अन्य एजेंटों के बीच संचार और इंटरैक्शन की सुविधा प्रदान करता है।
• Recognize जटिल एजेंटिक सिस्टम बनाने में प्रत्येक प्रोटोकॉल की अलग भूमिकाओं को पहचानें।
Model Context Protocol
Model Context Protocol (MCP) एक खुला मानक है जो अनुप्रयोगों को LLMs को संदर्भ और उपकरण प्रदान करने का मानकीकृत तरीका प्रदान करता है। यह अलग-अलग डेटा स्रोतों और उपकरणों के लिए एक “यूनिवर्सल एडैप्टर” सक्षम करता है जिनसे AI एजेंट एक सुसंगत तरीके से कनेक्ट कर सकते हैं।
आइए MCP के घटकों, सीधे API उपयोग की तुलना में लाभों, और एक उदाहरण पर नज़र डालें कि AI एजेंट MCP सर्वर का उपयोग कैसे कर सकते हैं।
MCP कोर घटक
MCP एक क्लाइंट-सर्वर आर्किटेक्चर पर काम करता है और कोर घटक हैं:
• Hosts वे LLM अनुप्रयोग हैं (उदाहरण के लिए VSCode जैसे कोड संपादक) जो MCP सर्वर के साथ कनेक्शन शुरू करते हैं।
• Clients होस्ट एप्लिकेशन के भीतर के घटक हैं जो सर्वरों के साथ एक-से-एक कनेक्शन बनाए रखते हैं।
• Servers हल्के प्रोग्राम हैं जो विशिष्ट क्षमताओं को एक्सपोज़ करते हैं।
प्रोटोकॉल में तीन मुख्य प्रिमिटिव शामिल हैं जो एक MCP सर्वर की क्षमताएँ हैं:
• Tools: ये वे पृथक क्रियाएँ या फ़ंक्शन हैं जिन्हें एक AI एजेंट किसी क्रिया को निष्पादित करने के लिए कॉल कर सकता है। उदाहरण के लिए, एक मौसम सेवा “get weather” टूल एक्सपोज़ कर सकती है, या एक ई-कॉमर्स सर्वर “purchase product” टूल एक्सपोज़ कर सकता है। MCP सर्वर अपनी क्षमताओं की सूची में प्रत्येक टूल का नाम, विवरण, और इनपुट/आउटपुट स्कीमा विज्ञापित करते हैं।
• Resources: ये केवल-पढ़ने योग्य डेटा आइटम या दस्तावेज़ हैं जो एक MCP सर्वर प्रदान कर सकता है, और क्लाइंट उन्हें मांग पर पुनः प्राप्त कर सकते हैं। उदाहरणों में फ़ाइल सामग्री, डेटाबेस रिकॉर्ड, या लॉग फ़ाइलें शामिल हैं। Resources टेक्स्ट (जैसे कोड या JSON) या बाइनरी (जैसे छवियाँ या PDFs) हो सकते हैं।
• Prompts: ये पूर्व-परिभाषित टेम्पलेट हैं जो सुझाए गए प्रॉम्प्ट प्रदान करते हैं, जिससे अधिक जटिल वर्कफ़्लो संभव होते हैं।
MCP के लाभ
MCP AI एजेंटों के लिए महत्वपूर्ण लाभ प्रदान करता है:
• Dynamic Tool Discovery: एजेंट सर्वर से उपलब्ध टूल्स की सूची और उनके करने का विवरण डायनामिक रूप से प्राप्त कर सकते हैं। यह पारंपरिक APIs के विपरीत है, जो अक्सर इंटीग्रेशन के लिए स्थैतिक कोडिंग की आवश्यकता करते हैं, जिसका अर्थ है कि किसी भी API परिवर्तन के लिए कोड अपडेट की आवश्यकता होती है। MCP “एक बार इंटीग्रेट करें” का दृष्टिकोण प्रदान करता है, जिससे अधिक अनुकूलनशीलता मिलती है।
• Interoperability Across LLMs: MCP विभिन्न LLMs के बीच काम करता है, बेहतर प्रदर्शन के लिए कोर मॉडल बदलने की लचीलापन प्रदान करता है।
• Standardized Security: MCP एक मानक प्रमाणीकरण विधि शामिल करता है, जो अतिरिक्त MCP सर्वरों तक पहुँच जोड़ने पर स्केलेबिलिटी में सुधार करता है। यह विभिन्न पारंपरिक APIs के लिए अलग-अलग कुंजियों और प्रमाणीकरण प्रकारों का प्रबंधन करने से सरल है।
MCP उदाहरण
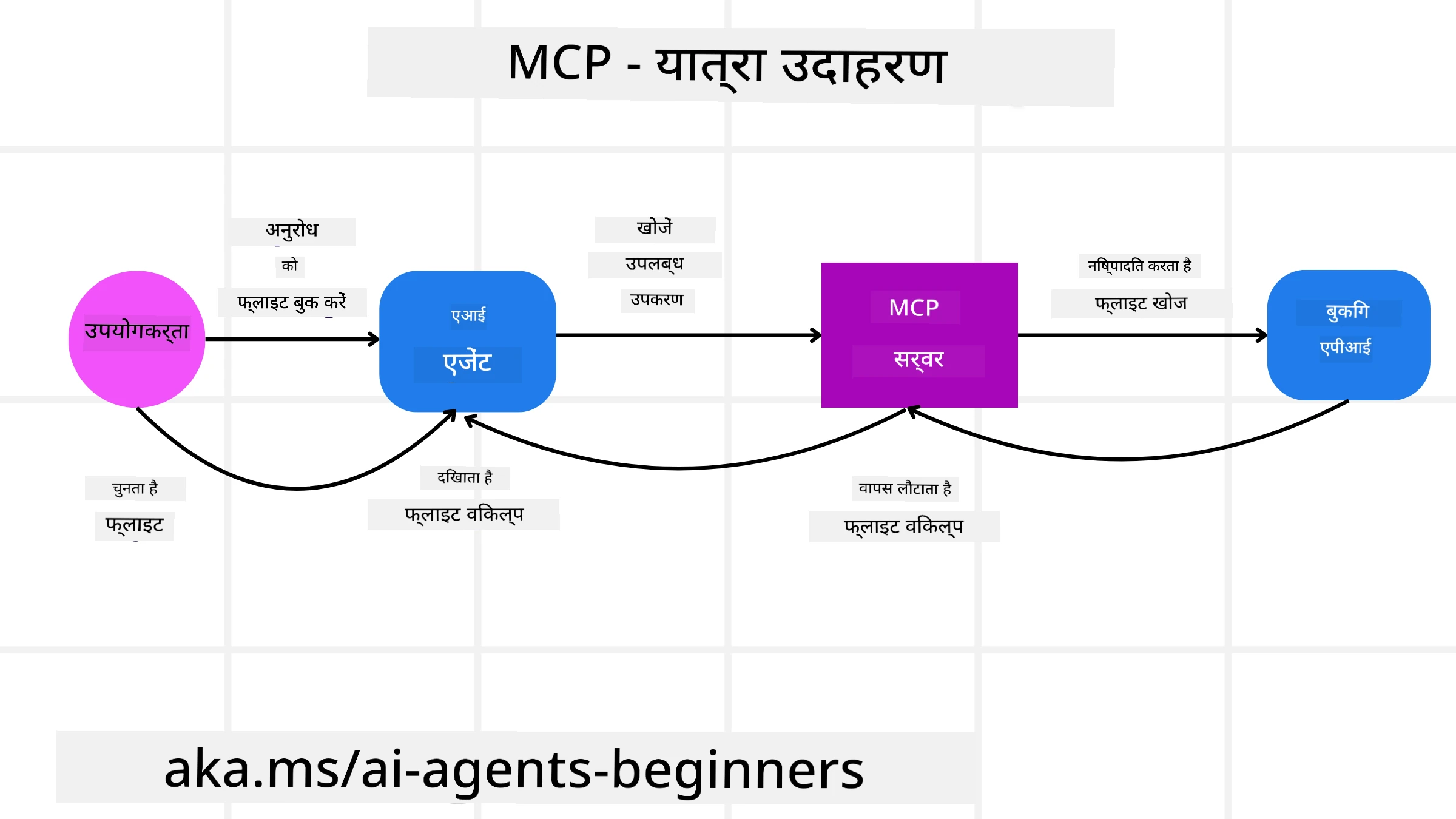
कल्पना कीजिए कि एक उपयोगकर्ता MCP द्वारा संचालित AI सहायक का उपयोग करके फ्लाइट बुक करना चाहता है।
-
Connection: AI सहायक (MCP क्लाइंट) एक एयरलाइन द्वारा प्रदान किए गए MCP सर्वर से कनेक्ट होता है।
-
Tool Discovery: क्लाइंट एयरलाइन के MCP सर्वर से पूछता है, “आपके पास कौन-कौन से टूल उपलब्ध हैं?” सर्वर “search flights” और “book flights” जैसे टूल के साथ जवाब देता है।
-
Tool Invocation: आप फिर AI सहायक से कहते हैं, “कृपया Portland से Honolulu के लिए उड़ान खोजें।” AI सहायक, अपने LLM का उपयोग करते हुए, पहचानता है कि उसे “search flights” टूल को कॉल करने की आवश्यकता है और संबंधित पैरामीटर्स (origin, destination) MCP सर्वर को पास करता है।
-
Execution and Response: MCP सर्वर, एक रैपर के रूप में कार्य करते हुए, एयरलाइन के आंतरिक बुकिंग API को वास्तविक कॉल करता है। इसके बाद यह फ्लाइट जानकारी (उदा., JSON डेटा) प्राप्त करता है और इसे AI सहायक को वापस भेजता है।
-
Further Interaction: AI सहायक फ्लाइट विकल्प प्रस्तुत करता है। एक बार आप एक फ्लाइट चुन लेते हैं, सहायक उसी MCP सर्वर पर “book flight” टूल को इनवोक कर सकता है, और बुकिंग पूरी हो जाती है।
Agent-to-Agent Protocol (A2A)
जहाँ MCP LLMs को टूल्स से जोड़ने पर ध्यान केंद्रित करता है, वहीं Agent-to-Agent (A2A) प्रोटोकॉल इसे एक कदम आगे बढ़ाता है और विभिन्न AI एजेंटों के बीच संचार और सहयोग को सक्षम करता है। A2A विभिन्न संगठनों, वातावरणों और टेक स्टैक्स में AI एजेंटों को साझा कार्य पूरा करने के लिए जोड़ता है।
हम A2A के घटकों और लाभों की परीक्षा करेंगे, साथ ही हमारे ट्रैवल एप्लिकेशन में इसका उपयोग कैसे किया जा सकता है इसका एक उदाहरण देखेंगे।
A2A कोर घटक
A2A एजेंटों के बीच संचार सक्षम करने और उन्हें उपयोगकर्ता के एक उप-कार्य को पूरा करने के लिए साथ काम कराना केंद्रीय फोकस है। प्रोटोकॉल का प्रत्येक घटक इसमें योगदान देता है:
Agent Card
जिस तरह एक MCP सर्वर टूल्स की सूची साझा करता है, एक Agent Card में होता है:
- The Name of the Agent .
- एक सामान्य कार्यों का विवरण जो यह पूरा करता है।
- विशिष्ट कौशलों की एक सूची विवरणों के साथ ताकि अन्य एजेंट (या यहां तक कि मानव उपयोगकर्ता) समझ सकें कि उन्हें कब और क्यों उस एजेंट को कॉल करना चाहिए।
- एजेंट का वर्तमान Endpoint URL
- एजेंट का version और capabilities जैसे स्ट्रीमिंग प्रतिक्रियाएँ और पुश सूचनाएँ।
Agent Executor
Agent Executor उत्तरदायी है उपयोगकर्ता चैट के संदर्भ को रिमोट एजेंट को पारित करने के लिए, रिमोट एजेंट को यह समझने के लिए इसकी आवश्यकता होती है कि पूरा किया जाने वाला कार्य क्या है। एक A2A सर्वर में, एक एजेंट अपने स्वयं के Large Language Model (LLM) का उपयोग इनकमिंग अनुरोधों को पार्स करने और अपने आंतरिक उपकरणों का उपयोग करके कार्यों को निष्पादित करने के लिए करता है।
Artifact
एक बार जब रिमोट एजेंट अनुरोधित कार्य पूरा कर लेता है, तो उसका कार्य-उत्पाद एक artifact के रूप में बनाया जाता है। एक artifact में एजेंट के कार्य का परिणाम, जो पूरा किया गया उसका वर्णन, और वह टेक्स्ट संदर्भ शामिल होता है जो प्रोटोकॉल के माध्यम से भेजा गया होता है। artifact भेजे जाने के बाद, रिमोट एजेंट के साथ कनेक्शन तब तक बंद कर दिया जाता है जब तक इसकी फिर से आवश्यकता न हो।
Event Queue
यह घटक अपडेट्स और संदेश पास करने के लिए उपयोग किया जाता है। यह उत्पादन में एजेंटिक सिस्टम्स के लिए विशेष रूप से महत्वपूर्ण है ताकि एजेंटों के बीच का कनेक्शन उस कार्य के पूरा होने से पहले बंद न हो जाए, खासकर जब कार्य पूरा होने में लंबा समय लग सकता है।
A2A के लाभ
• Enhanced Collaboration: यह विभिन्न विक्रेताओं और प्लेटफार्मों के एजेंटों को इंटरैक्ट करने, संदर्भ साझा करने और साथ काम करने में सक्षम बनाता है, पारंपरिक तौर पर अलग सिस्टम्स के बीच सहज स्वचालन की सुविधा प्रदान करता है।
• Model Selection Flexibility: प्रत्येक A2A एजेंट निर्णय ले सकता है कि वह अपने अनुरोधों की सेवा के लिए कौन सा LLM उपयोग करता है, जिससे प्रति एजेंट अनुकूलित या फाइन-ट्यून मॉडल संभव होते हैं, जो कुछ MCP परिदृश्यों में एकल LLM कनेक्शन के विपरीत है।
• Built-in Authentication: प्रमाणीकरण सीधे A2A प्रोटोकॉल में एकीकृत है, जो एजेंट इंटरैक्शन के लिए एक मजबूत सुरक्षा ढांचा प्रदान करता है।
A2A उदाहरण
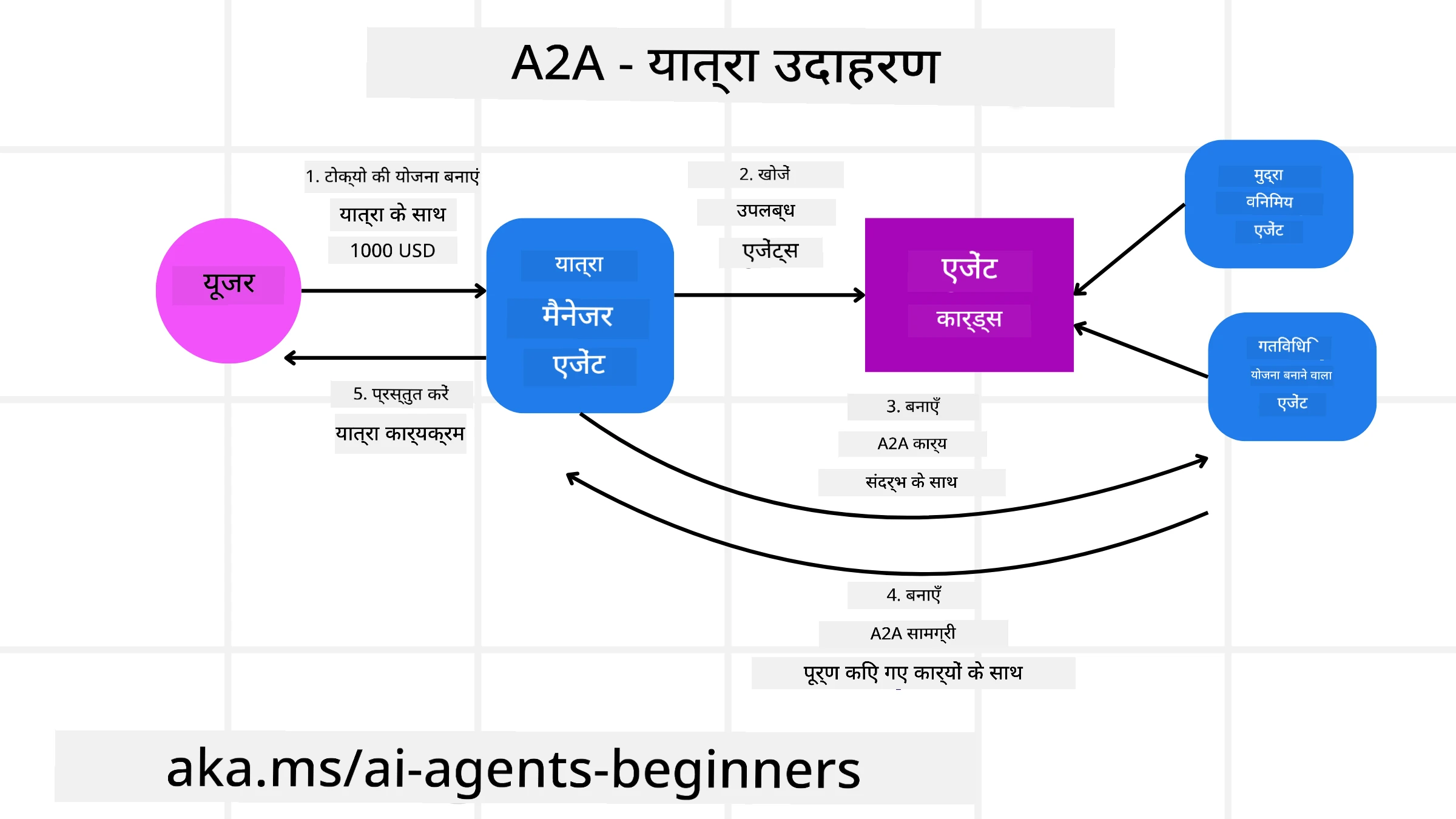
आइए हमारे ट्रैवल बुकिंग परिदृश्य को विस्तारित करें, लेकिन इस बार A2A का उपयोग करके।
-
User Request to Multi-Agent: एक उपयोगकर्ता “Travel Agent” A2A क्लाइंट/एजेंट के साथ इंटरैक्ट करता है, शायद कहकर, “कृपया अगले सप्ताह के लिए Honolulu के लिए पूरी यात्रा बुक करें, जिसमें फ्लाइट, होटल, और रेंटल कार शामिल हो”।
-
Orchestration by Travel Agent: Travel Agent इस जटिल अनुरोध को प्राप्त करता है। यह अपने LLM का उपयोग करके कार्य के बारे में तर्क करता है और निर्धारित करता है कि इसे अन्य विशेषज्ञ एजेंटों के साथ इंटरैक्ट करने की आवश्यकता है।
-
Inter-Agent Communication: Travel Agent फिर A2A प्रोटोकॉल का उपयोग करके डाउनस्ट्रीम एजेंट्स से कनेक्ट होता है, जैसे कि “Airline Agent,” “Hotel Agent,” और “Car Rental Agent” जो विभिन्न कंपनियों द्वारा बनाए गए हैं।
-
Delegated Task Execution: Travel Agent इन विशेषज्ञ एजेंटों को विशिष्ट कार्य भेजता है (उदा., “Find flights to Honolulu,” “Book a hotel,” “Rent a car”)। इनमें से प्रत्येक विशेषज्ञ एजेंट, अपने स्वयं के LLMs चला रहे होते हैं और अपने टूल्स का उपयोग कर रहे होते हैं (जो स्वयं MCP सर्वर भी हो सकते हैं), बुकिंग का अपना विशिष्ट हिस्सा पूरा करता है।
-
Consolidated Response: एक बार सभी डाउनस्ट्रीम एजेंट अपने कार्यों को पूरा कर लेते हैं, Travel Agent परिणामों (फ्लाइट विवरण, होटल पुष्टि, कार रेंटल बुकिंग) को सम्मिलित करके उपयोगकर्ता को एक समेकित, चैट-शैली उत्तर भेजता है।
Natural Language Web (NLWeb)
वेबसाइट्स लंबे समय से इंटरनेट पर जानकारी और डेटा तक पहुँचने का प्राथमिक तरीका रही हैं।
आइए NLWeb के विभिन्न घटकों, NLWeb के लाभों और हमारे ट्रैवल एप्लिकेशन द्वारा NLWeb कैसे काम करता है इसका एक उदाहरण देखें।
NLWeb के घटक
-
NLWeb Application (Core Service Code): वह सिस्टम जो प्राकृतिक भाषा प्रश्नों को प्रोसेस करता है। यह प्लेटफ़ॉर्म के विभिन्न हिस्सों को जोड़कर प्रतिक्रियाएँ बनाता है। आप इसे किसी वेबसाइट की प्राकृतिक भाषा सुविधाओं को संचालित करने वाला इंजन समझ सकते हैं।
-
NLWeb Protocol: यह वेबसाइट के साथ प्राकृतिक भाषा इंटरैक्शन के लिए एक मूल नियमों का सेट है। यह JSON फ़ॉर्मेट में प्रतिक्रियाएँ वापस भेजता है (अक्सर Schema.org का उपयोग करते हुए)। इसका उद्देश्य “AI Web” के लिए एक सरल आधार बनाना है, उसी तरह जैसे HTML ने ऑनलाइन दस्तावेज़ साझा करना संभव किया।
-
MCP Server (Model Context Protocol Endpoint): प्रत्येक NLWeb सेटअप एक MCP सर्वर के रूप में भी काम करता है। इसका अर्थ है कि यह अन्य AI सिस्टम्स के साथ टूल्स (जैसे एक “ask” मेथड) और डेटा साझा कर सकता है। व्यावहार में, यह वेबसाइट की सामग्री और क्षमताओं को AI एजेंटों द्वारा उपयोग करने योग्य बनाता है, जिससे साइट व्यापक “एजेंट इकोसिस्टम” का हिस्सा बन सकती है।
-
Embedding Models: ये मॉडल वेबसाइट सामग्री को न्यूमेरिकल रिप्रेज़ेंटेशन जिसे वेक्टर कहा जाता है (embeddings) में बदलने के लिए उपयोग किए जाते हैं। ये वेक्टर कंप्यूटर्स के लिए तुलना और खोज को सक्षम करने के लिए अर्थ को कैप्चर करते हैं। इन्हें एक विशेष डेटाबेस में संग्रहीत किया जाता है, और उपयोगकर्ता यह चुन सकते हैं कि वे कौन सा embedding मॉडल उपयोग करना चाहते हैं।
-
Vector Database (Retrieval Mechanism): यह डेटाबेस वेबसाइट सामग्री के embeddings स्टोर करता है। जब कोई प्रश्न करता है, NLWeb सबसे प्रासंगिक जानकारी जल्दी से खोजने के लिए वेक्टर डेटाबेस की जाँच करता है। यह समानता के आधार पर संभावित उत्तरों की एक तेज़ सूची देता है। NLWeb Qdrant, Snowflake, Milvus, Azure AI Search, और Elasticsearch जैसे विभिन्न वेक्टर स्टोरेज सिस्टम्स के साथ काम करता है।
NLWeb द्वारा उदाहरण
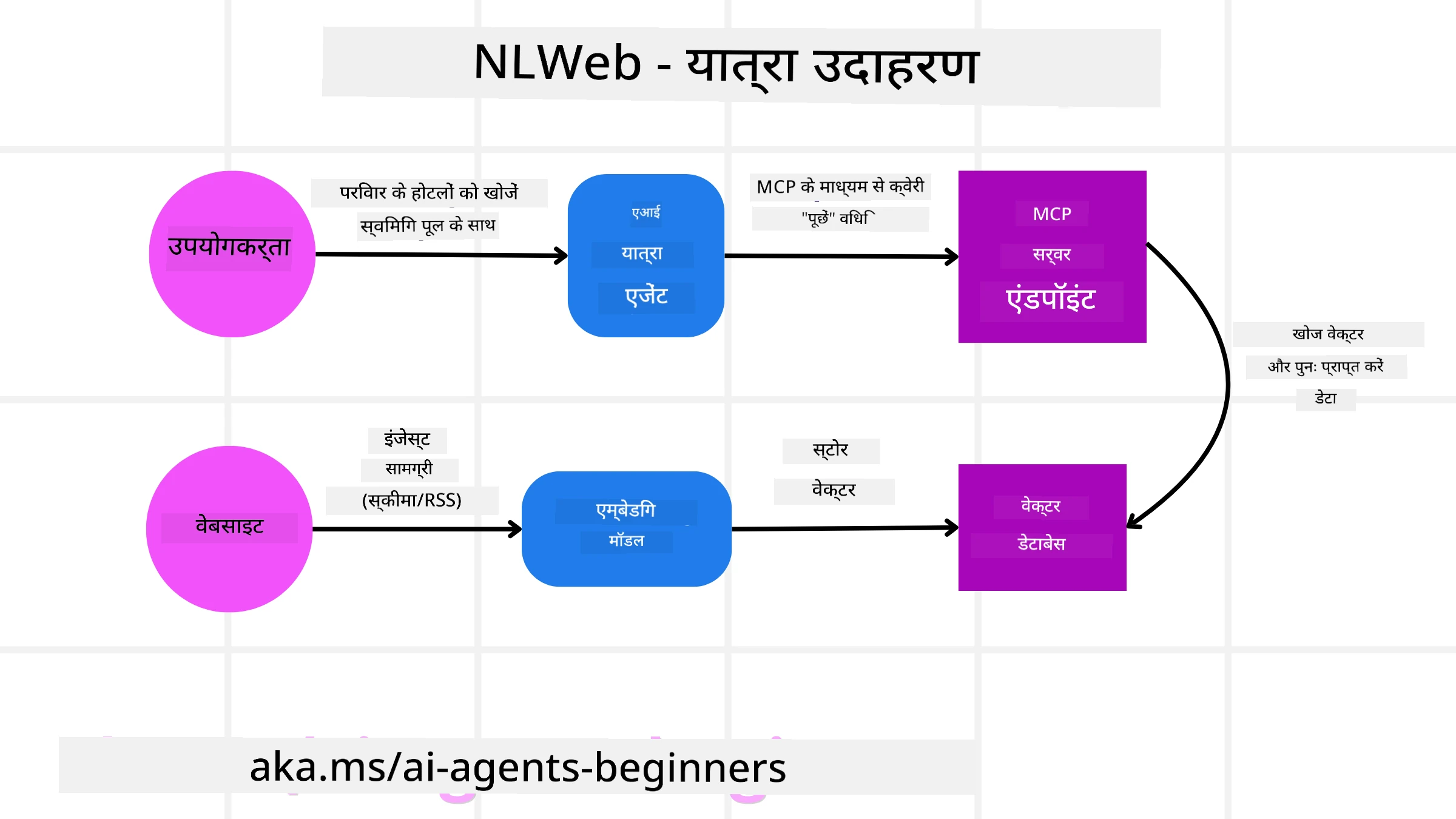
फिर से हमारा ट्रैवल बुकिंग वेबसाइट मान लीजिए, लेकिन इस बार यह NLWeb द्वारा संचालित है।
-
Data Ingestion: ट्रैवल वेबसाइट के मौजूदा प्रोडक्ट कैटलॉग (उदा., फ्लाइट लिस्टिंग, होटल के विवरण, टूर पैकेज) को Schema.org का उपयोग करके फॉर्मेट किया जाता है या RSS फीड्स के माध्यम से लोड किया जाता है। NLWeb के टूल्स इस संरचित डेटा को इनजेस्ट करते हैं, embeddings बनाते हैं, और उन्हें स्थानीय या रिमोट वेक्टर डेटाबेस में संग्रहीत करते हैं।
-
Natural Language Query (Human): एक उपयोगकर्ता वेबसाइट पर आता है और मेन्यू नेविगेट करने के बजाय चैट इंटरफ़ेस में टाइप करता है: “Find me a family-friendly hotel in Honolulu with a pool for next week”।
-
NLWeb Processing: NLWeb एप्लिकेशन इस प्रश्न को प्राप्त करता है। यह समझने के लिए प्रश्न को एक LLM को भेजता है और एक साथ ही अपने वेक्टर डेटाबेस में प्रासंगिक होटल लिस्टिंग्स की खोज करता है।
-
Accurate Results: LLM डेटाबेस से खोज परिणामों की व्याख्या करने में मदद करता है, “family-friendly,” “pool,” और “Honolulu” मापदण्डों के आधार पर सबसे अच्छा मेल पहचानता है, और फिर एक प्राकृतिक भाषा प्रतिक्रिया स्वरूपित करता है। महत्वपूर्ण बात यह है कि प्रतिक्रिया वेबसाइट के कैटलॉग के वास्तविक होटलों का संदर्भ देती है, काल्पनिक जानकारी से बचते हुए।
-
AI Agent Interaction: क्योंकि NLWeb एक MCP सर्वर के रूप में कार्य करता है, एक बाहरी AI ट्रैवल एजेंट भी इस वेबसाइट की NLWeb इंस्टेंस से कनेक्ट कर सकता है। AI एजेंट तब सीधे वेबसाइट से क्वेरी करने के लिए
ask("Are there any vegan-friendly restaurants in the Honolulu area recommended by the hotel?")MCP मेथड का उपयोग कर सकता है। NLWeb इंस्टेंस इसे प्रोसेस करेगा, यदि लोड किया गया हो तो अपने रेस्तरां जानकारी के डेटाबेस का लाभ उठाएगा, और एक संरचित JSON प्रतिक्रिया लौटाएगा।
MCP/A2A/NLWeb के बारे में और प्रश्न हैं?
Microsoft Foundry Discord में शामिल हों ताकि अन्य शिक्षार्थियों से मिल सकें, ऑफिस आवर्स में भाग लें और अपने AI Agents से संबंधित प्रश्नों का उत्तर प्राप्त करें।
संसाधन
अस्वीकरण: यह दस्तावेज़ एआई अनुवाद सेवा Co-op Translator (https://github.com/Azure/co-op-translator) का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता के लिए प्रयास करते हैं, कृपया ध्यान रखें कि स्वचालित अनुवादों में त्रुटियाँ या अशुद्धियाँ हो सकती हैं। मूल दस्तावेज़ अपनी मूल भाषा में ही आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।