ai-agents-for-beginners

(このレッスンのビデオを見るには、上の画像をクリックしてください)
Agentic RAG
このレッスンでは、エージェント的Retrieval-Augmented Generation(Agentic RAG)について包括的に解説します。これは、大規模言語モデル(LLM)が外部ソースから情報を取得しながら次のステップを自主的に計画する新しいAIパラダイムです。静的な取得してから読むパターンとは異なり、Agentic RAGはLLMへの反復呼び出しを含み、その間にツールや関数の呼び出しと構造化された出力が挿入されます。システムは結果を評価し、クエリを洗練し、必要に応じて追加ツールを呼び出し、このサイクルを満足のいく解決策が得られるまで続けます。
はじめに
このレッスンで学ぶ内容:
- Agentic RAGの理解: 外部データソースから情報を取得しつつ、大規模言語モデル(LLM)が自律的に次のステップを計画する新興のAIパラダイムについて学びます。
- 反復的なメーカー・チェッカー方式の理解: ツールや関数呼び出しと構造化された出力をはさみながらLLMを反復的に呼び出すループについて、その正確性向上や不正なクエリ対応のための仕組みを理解します。
- 実用的な応用例の探求: 正確さ重視の環境、複雑なデータベース操作、拡張されたワークフローなど、Agentic RAGが効果を発揮するシナリオを特定します。
学習目標
このレッスンを終えた後、以下のことが理解できるようになります:
- Agentic RAGの理解: 大規模言語モデル(LLM)が外部データソースから情報を自主的に取得しながら次のステップを計画する新たなAIパラダイムを理解します。
- 反復的なメーカー・チェッカー方式の理解: ツールや関数の呼び出しと構造化出力を挟みつつ、LLMを反復呼び出すループの概念を理解し、正確性の向上や不正なクエリ対応を学びます。
- 推論プロセスの所有: システムが自身の推論プロセスを所有し、あらかじめ定義された経路に依存せずに問題解決の方針を決定する能力を理解します。
- ワークフロー理解: エージェントモデルが独自に市場動向レポートの取得、競合データの特定、社内販売指標の相関付け、発見事項の統合、戦略評価を行う流れを理解します。
- 反復ループ、ツール統合、メモリ: 状態とメモリを維持し繰り返しのループを回避、意思決定に活かすシステムのループ型インタラクションパターンについて学びます。
- 障害モードの処理と自己修正: 反復や再クエリ、診断ツールの使用、人間の監督にフォールバックするなど、堅牢な自己修正機構について理解します。
- エージェンシーの境界: エージェンシーの限界、ドメイン固有の自律性、インフラ依存、ガードレールへの遵守について理解します。
- 実用的なユースケースと価値: 正確性優先環境、複雑なデータベース操作、長期的なワークフローなど、Agentic RAGの適用が有効なシナリオを特定します。
- ガバナンス、透明性、信頼: 説明可能な推論、バイアス管理、人間による監督など、ガバナンスと透明性の重要性について学びます。
Agentic RAGとは?
Agentic Retrieval-Augmented Generation(Agentic RAG)は、大規模言語モデル(LLM)が外部から情報を取得しながら、自分自身で次のステップを計画する新興のAIパラダイムです。静的な取得してから読むパターンとは異なり、Agentic RAGはLLMへの反復呼び出しを伴い、ツールや関数呼び出しと構造化された出力が組み合わされます。システムは結果を評価し、クエリを洗練し、必要に応じて追加ツールを呼び出して満足のいく解決策が得られるまでこのサイクルを繰り返します。この反復的な「メーカー・チェッカー」スタイルにより、正確性が向上し、不正なクエリへの対応や高品質な結果の確保が可能になります。
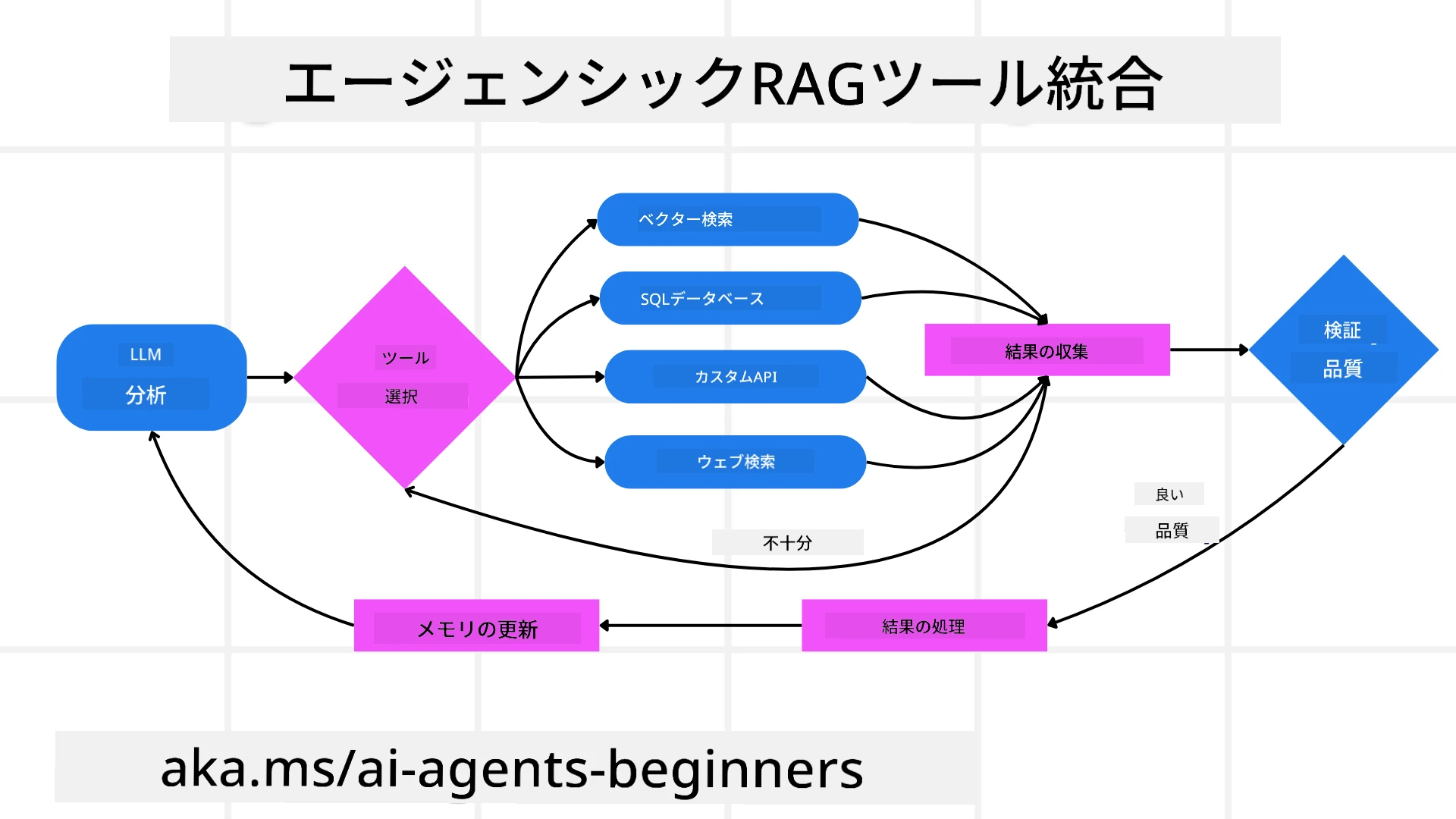
システムは自身の推論プロセスを積極的に所有し、失敗したクエリを書き換え、異なる取得方法を選択し、Azure AI Searchのベクトル検索、SQLデータベース、カスタムAPIなど複数のツールを統合して回答を完成させます。エージェント的なシステムの特徴は、推論プロセスを自ら所有する能力にあります。従来のRAGはあらかじめ定義された経路に依存しますが、Agenticシステムは見つけた情報の質に基づき、ステップの順序を自主的に決定します。
Agentic Retrieval-Augmented Generation(Agentic RAG)の定義
Agentic Retrieval-Augmented Generation(Agentic RAG)は、LLMが外部データソースから情報を取得するだけでなく、自律的に次のステップを計画する新興のAI開発パラダイムです。静的な取得-読取パターンや慎重にスクリプト化されたプロンプトの連鎖と異なり、Agentic RAGはLLMへの反復的な呼び出しのループに、ツールや関数の呼び出しおよび構造化された出力を間に挟みます。毎回、システムは得られた結果を評価し、クエリの洗練が必要か判断し、必要に応じて追加ツールを呼び出し、満足できる解決策が得られるまでこのサイクルを続けます。
この反復的な「メーカー・チェッカー」式の動作は、正確性向上、不正なクエリの対応(例:NL2SQLなど構造化データベースへの不正クエリ)、バランスの取れた高品質な結果の確保を目的としています。慎重に設計されたプロンプトチェーンのみに頼らず、システム自らが推論プロセスを所有しています。失敗したクエリを書き直したり、異なる取得方法を選択し、Azure AI Searchのベクトル検索、SQLデータベース、カスタムAPIなど複数のツールを統合して回答を最終化します。これにより過度に複雑なオーケストレーションフレームワークが不要になり、比較的単純な「LLM呼出 → ツール利用 → LLM呼出 → …」のループで高度かつ確固たる出力が得られます。
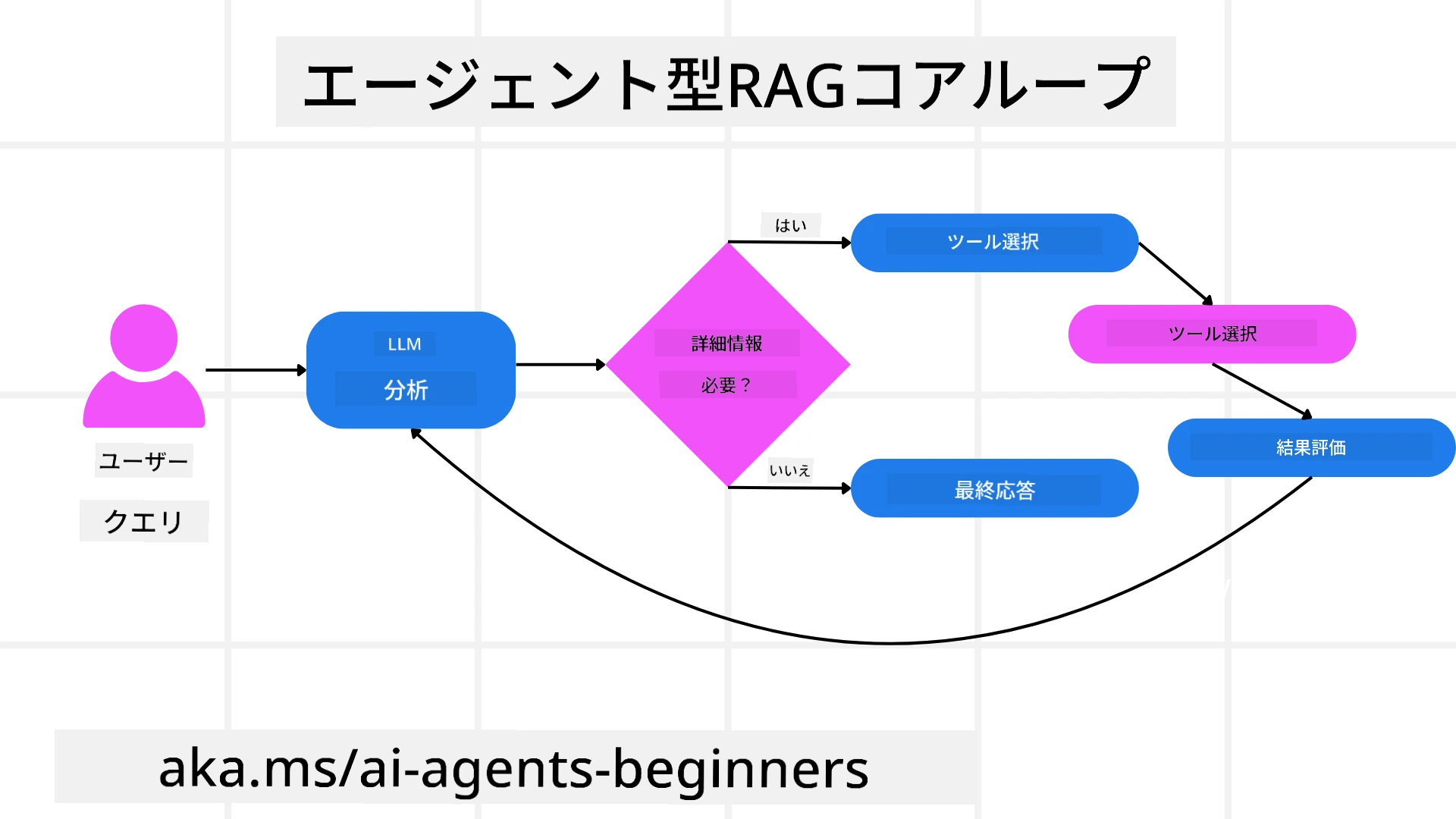
推論プロセスの所有
システムを「エージェント的」にする際立った特徴は、推論プロセスを自ら所有する能力です。従来のRAG実装では、しばしば人間がモデルに対して取得すべき情報やタイミングを示す思考連鎖をあらかじめ定義します。 しかし、本当にエージェント的なシステムは、問題へのアプローチ方法を内部で自律的に決めます。ただのスクリプト実行ではなく、得た情報の質に基づいて手順の順序を自ら判断します。 例えば、製品発売戦略を作成するよう依頼された場合、リサーチや意思決定の全ワークフローを明文化したプロンプトだけに頼らず、エージェント的モデルは以下を独自に決定します。
- Bing Web Groundingを使い最新の市場動向レポートを取得する
- Azure AI Searchを使い関連する競合他社データを特定する
- Azure SQL Databaseで過去の社内販売指標を相関付ける
- Azure OpenAI Service経由で発見事項を統合し一貫した戦略を構築する
- 戦略にギャップや矛盾がないか評価し、必要なら再度情報取得を促す これらすべてのステップは、クエリの洗練や情報源の選択、回答に「満足」するまでの反復を含め、人間による事前スクリプトではなくモデル自身が決定します。
反復ループ、ツール統合、メモリ
エージェント的システムは以下のループ型インタラクションパターンに依存しています:
- 初期呼び出し: ユーザーの目標(ユーザープロンプト)がLLMに渡されます。
- ツール呼び出し: モデルが情報不足や曖昧な指示を検知すると、ベクトルデータベースクエリ(例:プライベートデータに対するAzure AI Search Hybrid検索)や構造化されたSQL呼び出しなどのツールや取得方法を選択し、追加情報を集めます。
- 評価と洗練: 返されたデータをレビューし、情報が十分か判断します。不十分な場合、クエリを洗練、他のツールを試す、またはアプローチを調整します。
- 満足するまで繰り返し: 十分な明確さと証拠が確保でき、最終的な妥当な回答を出せると判断されるまで、サイクルを続けます。
- メモリと状態管理: システムはステップ間で状態と記憶を維持し、過去の試みと結果を呼び戻して反復ループを避けながら、より賢明な判断を下します。
これにより、理解が進化する感覚が生まれ、その結果、複雑で多段階のタスクも人間の継続的な介入やプロンプトの書き換えなしに進行できます。
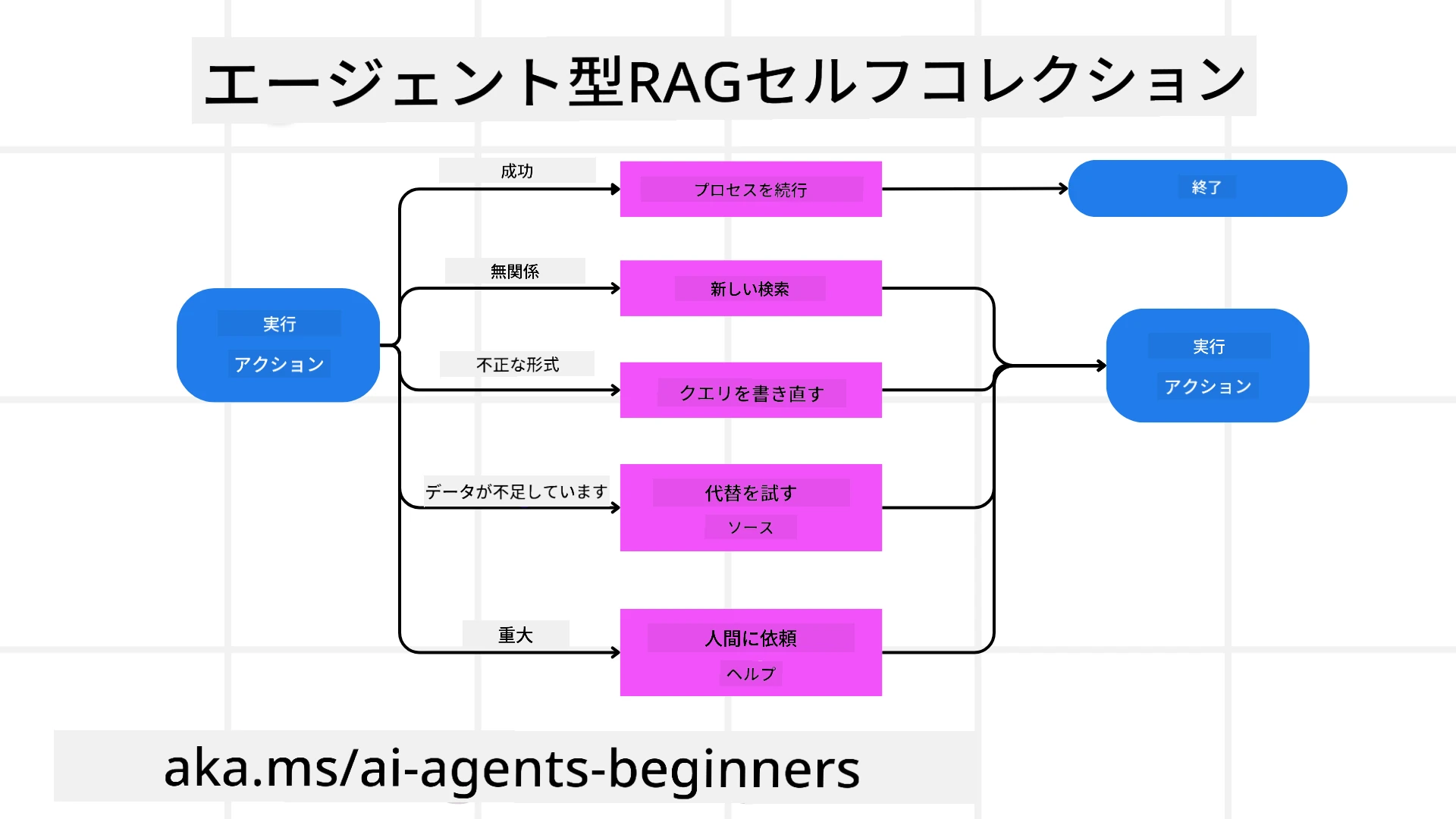
障害モードの処理と自己修正
Agentic RAGの自律性は堅牢な自己修正機構も伴います。システムが行き詰まり(例えば、無関係な文書を取得したり不正なクエリに遭遇した場合)に遭遇すると、以下を行います:
- 反復と再クエリ: 低品質な回答を返す代わりに、新たな検索戦略を試したり、データベースクエリを書き換えたり、別のデータセットを調査したりします。
- 診断ツールの利用: 推論過程のデバッグや取得情報の正確性確認を助ける追加機能を呼び出す場合があります。Azure AI Tracingのようなツールは堅牢な可観測性と監視を実現するために重要です。
- 人間の監督へのフォールバック: 高リスクまたは繰り返し失敗する状況では、不確実性を示して人間の指示を求めることがあります。人間がフィードバックを提供すると、モデルはその学びを今後に反映します。
この反復的かつ動的な方法により、モデルは単発ではなく、セッション中に失敗から継続的に学ぶシステムとなります。
エージェンシーの境界
タスク内での自律性はあっても、Agentic RAGは汎用人工知能(AGI)とは異なります。その「エージェンシー」能力は人間開発者が提供するツール、データソース、ポリシーに限定されています。独自にツールを発明したりドメインの枠を超えたりはできません。逆に、手元のリソースを動的にオーケストレートすることに長けています。 高度なAI形態との主な違いは:
- ドメイン固有の自律性: Agentic RAGシステムは、既知ドメイン内でユーザー定義の目標を達成することに集中し、結果改善のためにクエリ書き換えやツール選択といった手法を活用します。
- インフラ依存: システムの能力は開発者が統合したツールやデータに依存し、それらを超えるには人間の介入が必要です。
- ガードレールの尊重: 倫理指針、遵守規則、ビジネスポリシーは非常に重要であり、エージェントの自由度は安全措置や監督機構によって常に制約されます(願わくば)。
実用的なユースケースと価値
Agentic RAGは反復的な洗練と精度が求められるシナリオで威力を発揮します:
- 正確性優先環境: コンプライアンスチェック、規制分析、法務調査などで、エージェントモデルは事実を繰り返し検証し、多様なソースを参照、クエリを書き換えて徹底的に検証された回答を作ります。
- 複雑なデータベース操作: クエリが失敗しやすい、または調整が必要な構造化データを扱う場面で、Azure SQLやMicrosoft Fabric OneLakeを活用してクエリを自律的に改善し、最終取得がユーザーの意図に合致するようにします。
- 長期化するワークフロー: 長時間にわたるセッションでは、新情報が得られるにつれて戦略を変えつつ継続的にデータを取り入れます。
ガバナンス、透明性、信頼
こうしたシステムが推論をより自律的に行うにあたり、ガバナンスと透明性は不可欠です:
- 説明可能な推論: モデルは自身が行ったクエリ、参照したソース、推論過程のステップの監査証跡を提供できます。Azure AI Content SafetyやAzure AI Tracing / GenAIOpsなどのツールが透明性維持とリスク緩和を支援します。
- バイアス制御とバランスの取れた取得: 開発者はバランスの取れた代表的なデータソースを考慮するよう取得戦略を調整し、Azure Machine Learningを活用する高度なデータサイエンス組織向けのカスタムモデルを使い、出力の偏りや歪みを定期的に監査します。
- 人間の監督とコンプライアンス: 敏感なタスクには人間のレビューが必須です。Agentic RAGは高リスク判断で人間の判断を置き換えるものではなく、検証された選択肢を提供して支援します。
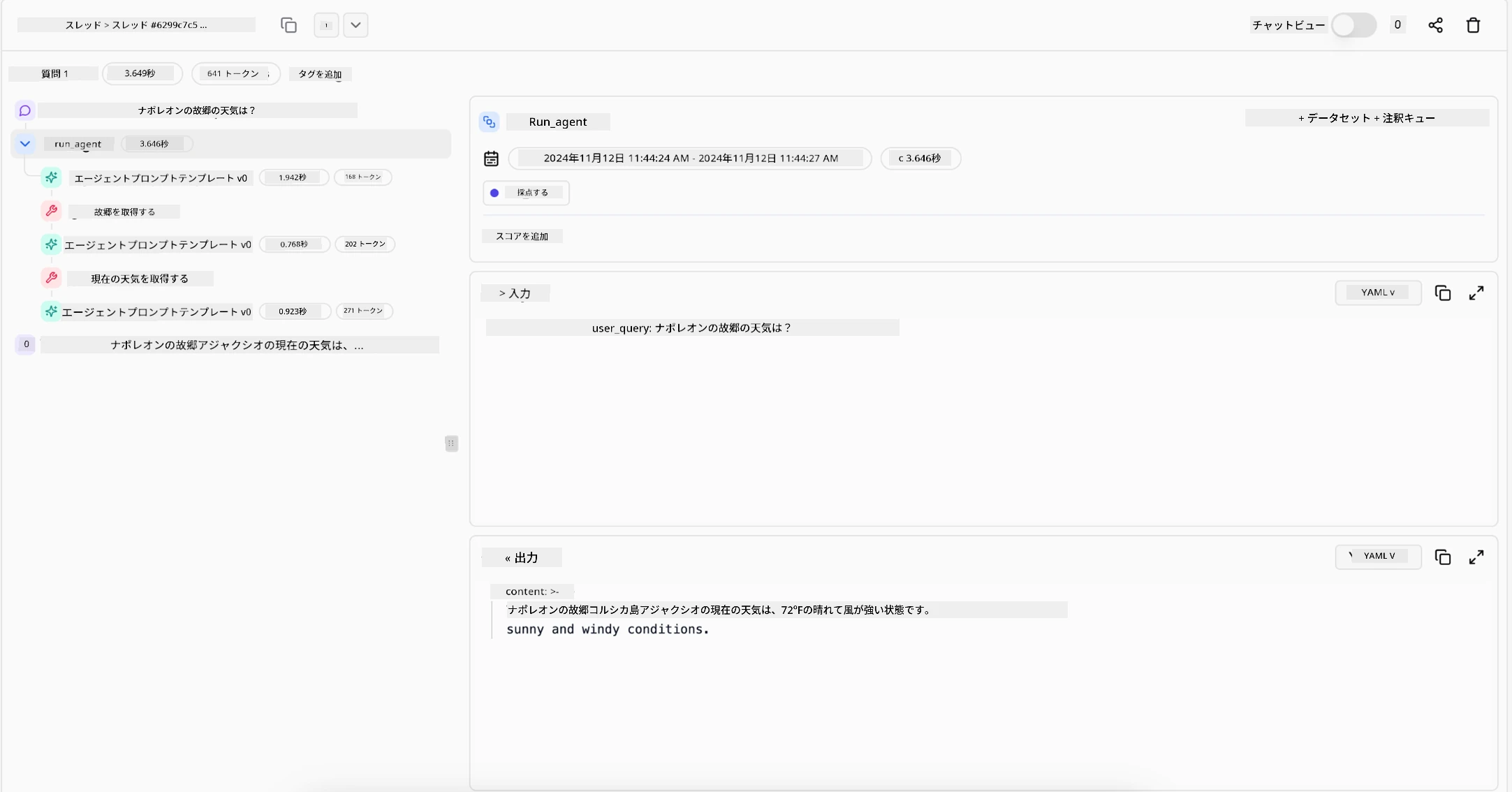
行動の明確な記録を提供できるツールが不可欠です。これがなければ多段階プロセスのデバッグは非常に困難です。Literal AI(Chainlitの背後の会社)によるAgent実行の例を以下に示します:
結論
Agentic RAGは、AIシステムが複雑でデータ集約的なタスクを扱う際の自然な進化形態を表しています。ループ型インタラクションパターンを採用し、自律的にツールを選択し、クエリを洗練しながら高品質な結果を達成することで、静的なプロンプト追従型を超えた、より適応性があり文脈を意識した意思決定者へと進化しました。依然として人間が定義したインフラや倫理指針の枠内にありますが、これらのエージェント的能力により、企業とエンドユーザーの双方にとってより豊かで動的かつ最終的に有用なAIインタラクションを実現します。
Agentic RAGについてさらに質問がありますか?
Microsoft Foundry Discord に参加して、他の学習者と交流したり、オフィスアワーに参加してAIエージェントについて質問してください。
追加リソース
- Azure OpenAIサービスでのリトリーバル強化生成(RAG)の実装: Azure OpenAIサービスで自分のデータを使う方法。このMicrosoft LearnモジュールはRAGの実装に関する包括的なガイドを提供します
- Microsoft Foundryによる生成AIアプリケーションの評価: この記事では、エージェントAIアプリケーションやRAGアーキテクチャを含む公開データセット上でのモデルの評価と比較について説明しています
- エージェントRAGとは | Weaviate
- エージェントRAG: エージェントベースのリトリーバル強化生成の完全ガイド – generation RAGからのニュース
- エージェントRAG: クエリ再形成と自己クエリでRAGを強化!Hugging FaceオープンソースAIクックブック
- RAGにエージェント層を追加する方法
- 知識アシスタントの未来:Jerry Liu
- エージェントRAGシステムの構築方法
- Microsoft Foundry Agent Serviceを使ってAIエージェントをスケールする方法
学術論文
- 2303.17651 Self-Refine: 自己フィードバックによる反復的洗練
- 2303.11366 Reflexion: 言語エージェントの言語強化学習
- 2305.11738 CRITIC: 大規模言語モデルはツールの対話的批評で自己修正できる
- 2501.09136 エージェントリトリーバル強化生成:エージェントRAGに関する調査
前のレッスン
次のレッスン
免責事項:
本書類はAI翻訳サービス「Co-op Translator」(https://github.com/Azure/co-op-translator)を使用して翻訳されました。正確性の確保に努めておりますが、自動翻訳には誤りや不正確な部分が含まれる可能性があります。原文はあくまで公式の情報源としてご参照ください。重要な情報については、専門の人間による翻訳を推奨します。本翻訳の使用により生じたいかなる誤解や誤訳についても、当方は一切の責任を負いかねます。