ai-agents-for-beginners
AIエージェントのためのコンテキストエンジニアリング

(上の画像をクリックしてこのレッスンのビデオを視聴できます)
AIエージェントが対象とするアプリケーションの複雑さを理解することは、信頼できるエージェントを作るために重要です。プロンプトエンジニアリングを超えて、複雑なニーズに対処するために情報を効果的に管理するAIエージェントを構築する必要があります。
このレッスンでは、コンテキストエンジニアリングとは何かと、それがAIエージェント構築において果たす役割を見ていきます。
はじめに
このレッスンでは次の内容を扱います:
• コンテキストエンジニアリングとは何か と、なぜそれがプロンプトエンジニアリングと異なるのか。
• 効果的なコンテキストエンジニアリングの戦略(情報の書き方、選択、圧縮、分離の方法を含む)。
• AIエージェントを脱線させる可能性のある一般的なコンテキストの失敗 と、それらの修正方法。
学習目標
このレッスンを修了すると、次のことを理解できるようになります:
• コンテキストエンジニアリングを定義する とプロンプトエンジニアリングとの違いを区別する方法。
• LLMアプリケーションにおけるコンテキストの主要な構成要素を特定する 方法。
• エージェントのパフォーマンスを向上させるために、コンテキストの書き方、選択、圧縮、分離の戦略を適用する 方法。
• ポイズニング、気晴らし、混乱、衝突 などの一般的なコンテキストの失敗を認識し、軽減技術を実装する方法。
コンテキストエンジニアリングとは何か?
AIエージェントにとって、コンテキストはエージェントが特定の行動を計画する原動力です。コンテキストエンジニアリングは、AIエージェントが次のタスクのステップを完了するために正しい情報を持つようにする実践です。コンテキストウィンドウはサイズに制限があるため、エージェント構築者としてはコンテキストウィンドウに情報を追加、削除、凝縮するためのシステムやプロセスを構築する必要があります。
プロンプトエンジニアリング vs コンテキストエンジニアリング
プロンプトエンジニアリングは、エージェントを効果的に導く一連の静的な指示に焦点を当てています。コンテキストエンジニアリングは、初期プロンプトを含む動的な情報のセットをどのように管理し、時間を通じてAIエージェントが必要とするものを確保するかに関するものです。コンテキストエンジニアリングの主な考え方は、このプロセスを再現可能で信頼できるものにすることです。
コンテキストの種類
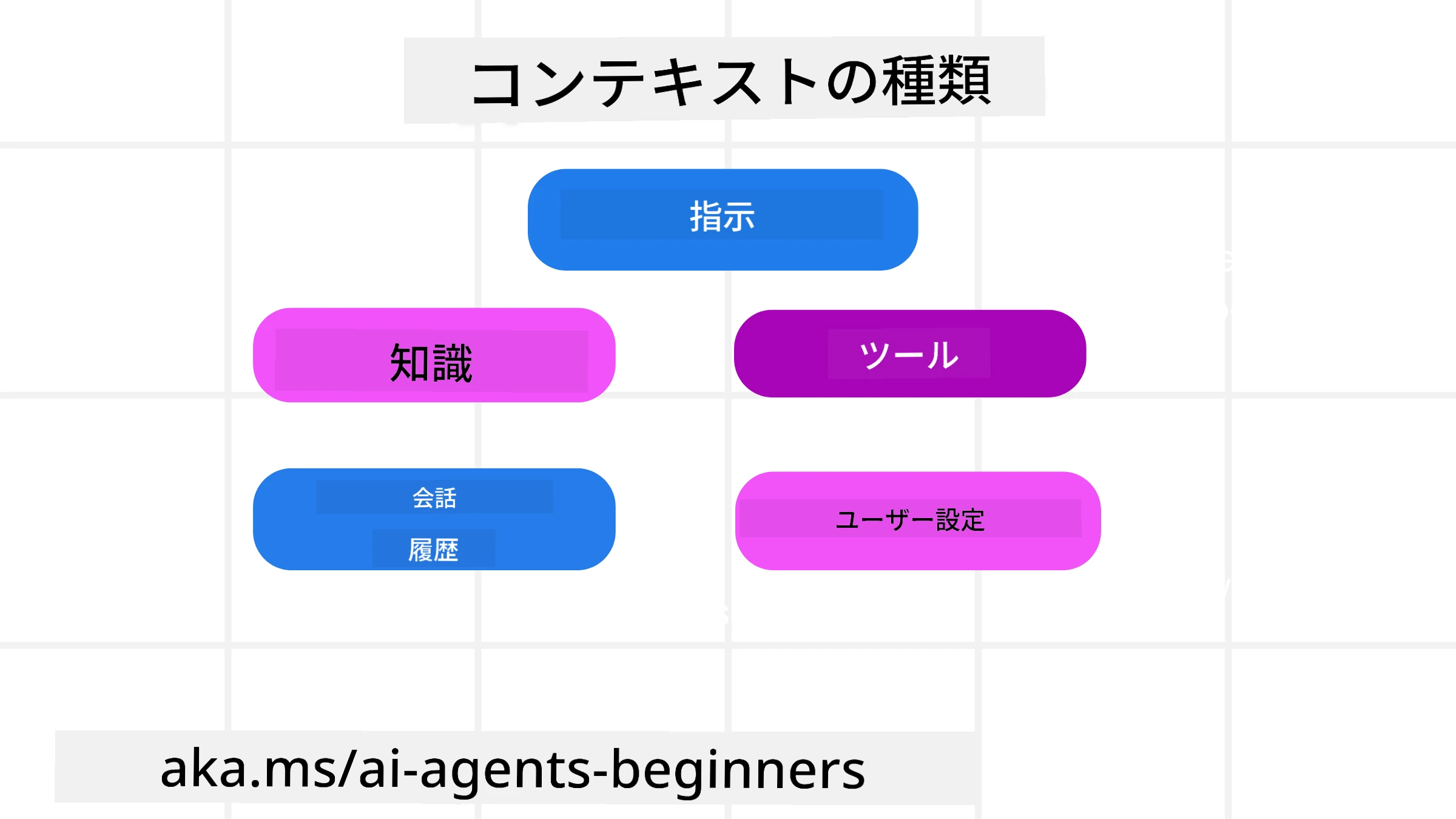
コンテキストは一つのものではないことを忘れてはいけません。AIエージェントが必要とする情報はさまざまな異なるソースから来る可能性があり、エージェントがこれらのソースにアクセスできるようにするのは私たちの責任です:
AIエージェントが管理する必要があるコンテキストの種類には以下が含まれます:
• 指示: これはエージェントの「ルール」のようなもので、プロンプト、システムメッセージ、few-shotの例(AIに何をするかを示す例)、および使用できるツールの説明が含まれます。ここがプロンプトエンジニアリングとコンテキストエンジニアリングが結びつく場所です。
• 知識: 事実、データベースから取得された情報、またはエージェントが蓄積した長期的な記憶をカバーします。エージェントが異なる知識ストアやデータベースにアクセスする必要がある場合は、Retrieval Augmented Generation (RAG) システムの統合を含みます。
• ツール: エージェントが呼び出せる外部関数、API、MCPサーバーの定義と、それらを使用した際に得られるフィードバック(結果)です。
• 会話履歴: ユーザーとの継続的な対話。時間が経つにつれてこれらの会話は長く複雑になり、コンテキストウィンドウのスペースを占有します。
• ユーザーの好み: 時間をかけて学習されたユーザーの好みや嫌いなものに関する情報。重要な意思決定時にユーザーを助けるために保存・呼び出される可能性があります。
効果的なコンテキストエンジニアリングの戦略
計画戦略
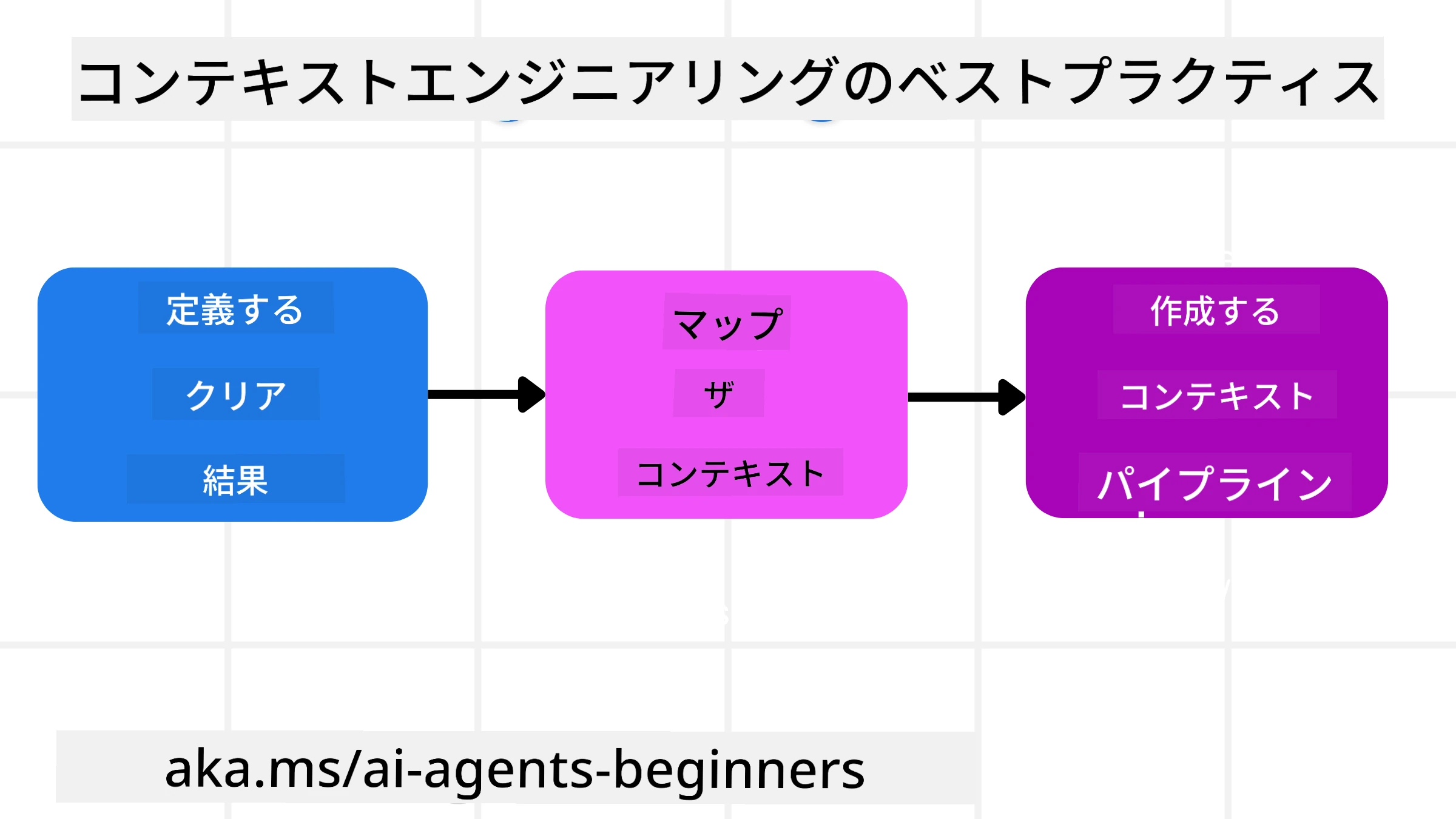
良いコンテキストエンジニアリングは良い計画から始まります。ここでは、コンテキストエンジニアリングの概念をどのように適用するかを考え始めるのに役立つアプローチを示します:
- 明確な結果を定義する - AIエージェントに与えられるタスクの結果は明確に定義する必要があります。次の質問に答えてください — 「AIエージェントがタスクを完了したとき、世界はどのようになっているべきか?」 言い換えれば、ユーザーがAIエージェントとやり取りした後、どのような変更、情報、または応答を得るべきかです。
- コンテキストをマッピングする - AIエージェントの結果を定義したら、「このタスクを完了するためにAIエージェントはどの情報を必要とするか?」という質問に答える必要があります。これにより、その情報がどこにあるかのコンテキストをマッピングし始めることができます。
- コンテキストパイプラインを作成する - 情報がどこにあるかが分かったら、「エージェントはこの情報をどのように取得するか?」という質問に答える必要があります。これはRAG、MCPサーバーの使用、その他のツールなど、さまざまな方法で行うことができます。
実践的な戦略
計画は重要ですが、情報がエージェントのコンテキストウィンドウに流れ込み始めたら、それを管理するための実践的な戦略が必要です:
コンテキストの管理
一部の情報はコンテキストウィンドウに自動的に追加されますが、コンテキストエンジニアリングはこの情報に対してより積極的な役割を取ることに関するもので、いくつかの戦略で行うことができます:
-
エージェントのスクラッチパッド これは、AIエージェントが単一セッション中の現在のタスクやユーザーとのやり取りに関する関連情報をメモすることを可能にします。これはコンテキストウィンドウの外部にファイルやランタイムオブジェクトとして存在し、必要に応じてセッション中にエージェントが後で取り出せるようにするべきです。
-
メモリ スクラッチパッドは単一セッションのコンテキストウィンドウ外で情報を管理するのに適しています。メモリはエージェントが複数のセッションにわたって関連情報を保存および取得できるようにします。これには要約、ユーザーの好み、将来の改善のためのフィードバックが含まれる可能性があります。
-
コンテキストの圧縮 コンテキストウィンドウが増大して制限に近づいたときは、要約やトリミングなどの技術を使用できます。これには最も関連性の高い情報のみを保持するか、古いメッセージを削除することが含まれます。
-
マルチエージェントシステム マルチエージェントシステムを開発することはコンテキストエンジニアリングの一形態です。各エージェントは独自のコンテキストウィンドウを持ち、それらのコンテキストをどのように共有し異なるエージェントに渡すかを計画する必要があります。
-
サンドボックス環境 エージェントがコードを実行したり、大量のドキュメント情報を処理する必要がある場合、結果を処理するのに大量のトークンを消費することがあります。これをすべてコンテキストウィンドウに保存する代わりに、エージェントはこのコードを実行できるサンドボックス環境を使用し、結果とその他の関連情報のみを読み取ることができます。
-
ランタイムステートオブジェクト これは、エージェントが特定の情報にアクセスする必要がある状況を管理するための情報コンテナを作成することによって行われます。複雑なタスクでは、各サブタスクの結果を段階的に保存し、コンテキストがその特定のサブタスクにのみ接続されたままでいることを可能にします。
コンテキストエンジニアリングの例
例えば、AIエージェントに “Book me a trip to Paris.” と依頼したいとしましょう。
• A simple agent using only prompt engineering might just respond: “Okay, when would you like to go to Paris?”. 単にユーザーが尋ねた時点での直接的な質問しか処理しません。
• An agent using the context engineering strategies covered would do much more. Before even responding, its system might:
◦ カレンダーを確認する 利用可能な日付を確認する(リアルタイムデータの取得)。
◦ 過去の旅行の好みを想起する(長期メモリから)お好みの航空会社、予算、直行便の好みなど。
◦ 利用可能なツールを特定する フライトとホテルの予約のためのツールなど。
- Then, an example response could be: “Hey [Your Name]! I see you’re free the first week of October. Shall I look for direct flights to Paris on [Preferred Airline] within your usual budget of [Budget]?”. このように、より豊かなコンテキスト認識に基づく応答は、コンテキストエンジニアリングの力を示しています。
よくあるコンテキストの失敗
コンテキストポイズニング
何か: LLMが生成した幻覚(誤情報)やエラーがコンテキストに入り、それが繰り返し参照されることで、エージェントが不可能な目標を追求したりナンセンスな戦略を展開したりすること。
対処法: コンテキスト検証 と 隔離(隔離領域) を実装します。情報を長期メモリに追加する前に検証します。ポイズニングの可能性が検出された場合は、悪い情報が広がらないように新しいコンテキストスレッドから始めます。
旅行予約の例: エージェントが実際には国際線を提供していない小さな地方空港から遠い国際都市への 直行便を幻覚 してしまい、この存在しないフライトの詳細がコンテキストに保存されます。後で予約を依頼すると、この不可能なルートのチケットを探し続け、繰り返しエラーを引き起こします。
解決策: フライト詳細をエージェントの作業コンテキストに追加する 前に、実際のリアルタイムAPIでフライトの存在と経路を検証する ステップを実装します。検証に失敗した場合、誤った情報は「隔離」され、それ以上使用されません。
コンテキストの気晴らし(Distraction)
何か: コンテキストが非常に大きくなりすぎて、モデルがトレーニングで学んだことよりも蓄積された履歴に過度に集中してしまい、反復的または役に立たない行動を取るようになること。モデルはコンテキストウィンドウがいっぱいになる前でもミスをし始めることがあります。
対処法: コンテキストの要約 を使用します。蓄積された情報を定期的により短い要約に圧縮し、重要な詳細を保持しつつ冗長な履歴を削除します。これによりフォーカスを「リセット」できます。
旅行予約の例: 長期間にわたって夢の旅行先について議論しており、2年前のバックパッキング旅行の詳細な話まで含まれているとします。最終的に 「来月の安いフライトを探して」 と尋ねると、エージェントは古い無関係な詳細に引きずられてバックパッキング用の装備や過去の旅程について何度も尋ね、現在のリクエストを無視してしまいます。
解決策: 一定のターン数またはコンテキストが大きくなりすぎた場合、エージェントは 会話の最新かつ関連性の高い部分を要約 し、現在の旅行日程と目的地に焦点を当てた凝縮された要約を次のLLM呼び出しに使用し、重要度の低い過去のチャットは破棄します。
コンテキストの混乱(Confusion)
何か: 不必要なコンテキスト、しばしば利用可能なツールが多すぎることから、モデルが誤った応答を生成したり無関係なツールを呼び出したりすること。小規模なモデルは特にこれに弱いです。
対処法: RAG技術を用いた ツールのロードアウト管理 を実装します。ツールの説明をベクトルデータベースに保存し、特定のタスクごとに最も関連性の高いツールだけを選択します。研究ではツール選択を30未満に制限することが示唆されています。
旅行予約の例: エージェントが多数のツールにアクセスできるとします: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations など。あなたが 「パリで一番良い移動手段は何?」 と尋ねたとき、ツールの数が多すぎてエージェントは混乱し、パリ国内で book_flight を呼び出そうとしたり、あなたが公共交通機関を好むにもかかわらず rent_car を呼び出そうとしたりします。これはツールの説明が重複しているか、単にどれが最適か判断できないためです。
解決策: ツール説明に対するRAG を使用します。パリでの移動について尋ねると、システムはクエリに基づいて rent_car や public_transport_info のような最も関連性の高いツールだけを動的に取得し、LLMに対して焦点を絞った「ロードアウト」を提示します。
コンテキストの衝突(Clash)
何か: コンテキスト内に矛盾する情報が存在することで、一貫性のない推論や悪い最終応答を生むこと。これは情報が段階的に到着し、初期の誤った仮定がコンテキストに残るときにしばしば発生します。
対処法: コンテキストの剪定(プルーニング) と オフロード を使用します。プルーニングは新しい詳細が到着したときに古くなったり矛盾する情報を削除することを意味します。オフロードは、メインのコンテキストを散らかさないようにモデルに別の「スクラッチパッド」ワークスペースを与えて情報を処理させます。
旅行予約の例: 最初にエージェントに 「エコノミークラスで行きたい」 と伝え、会話の後半で 「実は今回の旅行はビジネスクラスにしよう」 と変更したとします。両方の指示がコンテキストに残っていると、エージェントは矛盾する検索結果を受け取り、どの優先順位を適用すべきか混乱する可能性があります。
解決策: コンテキストのプルーニング を実装します。新しい指示が古い指示と矛盾する場合、古い指示は削除されるか明示的に上書きされます。あるいは、エージェントは スクラッチパッド を使用して矛盾する好みを調整し、最終的に一貫した指示だけが行動を導くようにします。
コンテキストエンジニアリングについてさらに質問がありますか?
Join the Microsoft Foundry Discord to meet with other learners, attend office hours and get your AI Agents questions answered.
免責事項: 本書は AI 翻訳サービス Co-op Translator を用いて翻訳されました。正確性には努めておりますが、自動翻訳には誤りや不正確な表現が含まれる可能性があることをご承知おきください。重要な情報については、原文(原言語)の文書を権威ある情報源として扱ってください。重要な内容に関しては、専門の人間による翻訳を推奨します。本翻訳の利用により生じたいかなる誤解や解釈の相違についても、当方は責任を負いません。