ai-agents-for-beginners
ಏಜೆಂಟಿಕ್ ಪ್ರೋಟೋಕಾಲ್ಗಳ ಬಳಕೆ (MCP, A2A ಮತ್ತು NLWeb)

(ಈ ಪಾಠದ ವಿಡಿಯೋವನ್ನು ವೀಕ್ಷಿಸಲು ಮೇಲಿನ ಚಿತ್ರವನ್ನು ಕ್ಲಿಕ್ ಮಾಡಿ)
AI ಏಜೆಂಟ்களின் ಬಳಕೆ ವೃದ್ಧಿಯಾಗುತ್ತಿರೊದಷ್ಟೇ, ಮಾನಕೀಕರಣ, ಭದ್ರತೆ ಮತ್ತು ಮುಕ್ತ ನವೀನತೆಯನ್ನು ಬೆಂಬಲಿಸುವ ಪ್ರೋಟೋಕಾಲ್ಗಳ ಅಗತ್ಯವೂ ಹೆಚ್ಚುತ್ತ ಹೋಗುತ್ತದೆ. ಈ ಪಾಠದಲ್ಲಿ, ನಾವು ಈ ಅಗತ್ಯವನ್ನು ಪೂರೈಸಲು ಪ್ರಯತ್ನಿಸುವ ಮೂರು ಪ್ರೋಟೋಕಾಲ್ಗಳನ್ನು ನೋಡುತ್ತೇವೆ — Model Context Protocol (MCP), Agent to Agent (A2A) ಮತ್ತು Natural Language Web (NLWeb).
ಪರಿಚಯ
ಈ ಪಾಠದಲ್ಲಿ ನಾವು ಈ ಕೆಳಕಂಡ ವಿಷಯಗಳನ್ನು ಚರ್ಚಿಸುವೆವು:
• ಹೇಗೆ MCP AI ಏಜೆಂಟ್ಗಳಿಗೆ ಹೊರಗಿನ ಸಾಧನಗಳು ಮತ್ತು ಡೇಟಾಗಳನ್ನು ಪ್ರವೇಶಿಸಲು ಅನುಮತಿಸುತ್ತಿದ್ದು ಬಳಕೆದಾರರ ಕಾರ್ಯಗಳನ್ನು ಪೂರ್ಣಗೊಳಿಸಲು ಸಹಾಯ ಮಾಡುತ್ತದೆ.
• ಹೇಗೆ A2A ವಿಭಿನ್ನ AI ಏಜೆಂಟ್ಗಳ ನಡುವೆ ಸಂವಹನ ಮತ್ತು ಸಹಕಾರವನ್ನು ಸಾಧ್ಯಮಾಡುತ್ತದೆ.
• ಹೇಗೆ NLWeb ಯಾವುದೇ ವೆಬ್ಸೈಟ್ಗೆ ನೈಸರ್ಗಿಕ ಭಾಷಾ ಇಂಟರ್ಫೇಸ್ಗಳನ್ನು ತರುತ್ತದೆ ಮತ್ತು AI ಏಜೆಂಟ್ಗಳು ವಿಷಯವನ್ನು ಕಂಡುಹಿಡಿದು ಅದുമായി ಸಂವಹನ ಮಾಡಲು ನೆರವಾಗುತ್ತದೆ.
ಕಲಿಕೆಯ ಉದ್ದೇಶಗಳು
• ಗುರುತಿಸು MCP, A2A ಮತ್ತು NLWeb ನ ಮುಖ್ಯ ಉದ್ದೇಶ ಮತ್ತು ಪ್ರಯೋಜನಗಳನ್ನು AI ಏಜೆಂಟ್ಗಳ контೆಕ್ಸ್ಟ್ನಲ್ಲಿ.
• ವಿವರಿಸು ಪ್ರತಿ ಪ್ರೋಟೋಕಾಲ್ ಹೇಗೆ LLMಗಳು, ಸಾಧನಗಳು ಮತ್ತು ಇತರ ಏಜೆಂಟ್ಗಳ ನಡುವೆ ಸಂವಹನ ಮತ್ತು ಪರಸ್ಪರ ಕ್ರಿಯೆಯನ್ನು ಸುಗಮಗೊಳಿಸುತ್ತದೆ.
• ಗುರುತಿಸು ಸಂಕೀರ್ಣ ಏಜೆಂಟಿಕ್ ವ್ಯವಸ್ಥೆಗಳನ್ನು ನಿರ್ಮಿಸುವಾಗ ಪ್ರತಿ ಪ್ರೋಟೋಕಾಲ್ ವಹಿಸುವ ವಿಭಿನ್ನ ಪಾತ್ರಗಳನ್ನು.
ಮಾದರಿ ಸಂದರ್ಭ ಪ್ರೋಟೋಕಾಲ್
Model Context Protocol (MCP) ಒಂದು ಓಪನ್ ಸ್ಟ್ಯಾಂಡರ್ಡ್ ಆಗಿದ್ದು, ಅಪ್ಲಿಕೇಶನ್ಗಳಿಗೆ LLMಗಳಿಗೆ ಸಂಪ್ರದಾಯ ಮತ್ತು ಸಾಧನಗಳನ್ನು ನೀಡಲು ಮಾನಕೃತವಾದ ವಿಧಾನವನ್ನು ಒದಗಿಸುತ್ತದೆ. ಇದು ವಿಭಿನ್ನ ಡೇಟಾ ಮೂಲಗಳು ಮತ್ತು ಸಾಧನಗಳಿಗೆ “ವಿಶ್ವವ್ಯಾಪಿ ಅಡಾಪ್ಟರ್” ಅನ್ನು ಸಾಧ್ಯಮಾಡುತ್ತದೆ, ಇದನ್ನು AI ಏಜೆಂಟ್ಗಳು ಸुसಂಬಂಧ ರೀತಿಯಲ್ಲಿ ಸಂಪರ್ಕಿಸಬಹುದು.
ಈಗ MCP ಯ घटಕಗಳು, ನೇರ API ಬಳಕೆಯೊಂದಿಗೆ ಹೊಂದಿರುವ ಲಾಭಗಳು, ಮತ್ತು AI ಏಜೆಂಟ್ಗಳು ಹೇಗೆ MCP ಸರ್ವರ್ ಬಳಸಿ ಕೆಲಸ ಮಾಡಬಹುದು ಎಂಬ ಉದಾಹರಣೆಯನ್ನು ನೋಡೋಣ.
MCP ಮೂಲ ಘಟಕಗಳು
MCP ಒಂದು client-server architecture ಮೇಲೆ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ ಮತ್ತು ಮೂಲ ಘಟಕಗಳು ಇವೆ:
• Hosts ಎಂಬವು LLM ಅಪ್ಲಿಕೇಶನ್ಗಳು (ಉದಾಹರಣೆಗೆ VSCode వంటి ಕೋಡ್ ಸಂಪಾದಕ) ಆಗಿದ್ದು ಅವು MCP ಸರ್ವರ್ಗೆ ಸಂಪರ್ಕಗಳನ್ನು ಪ್ರಾರಂಭಿಸುತ್ತವೆ.
• Clients ಎಂಬವು host ಅಪ್ಲಿಕೇಶನ್ದಲ್ಲಿ ಇರೋ ಘಟಕಗಳು ಆಗಿದ್ದು, ಸರ್ವರ್ಗಳೊಂದಿಗೆ ಒಂದರಿಂದ ಒಂದರ ಸಂಪರ್ಕಗಳನ್ನು ನಿರ್ವಹಿಸುತ್ತವೆ.
• Servers ಎಂಬವು ವಿಶೇಷ ಸಾಮರ್ಥ್ಯಗಳನ್ನು ಪ್ರದರ್ಶಿಸುವ ತೂಕ ಕಡಿಮೆ ಪ್ರೋಗ್ರಾಮ್ಗಳು.
ಪ್ರೋಟೋಕಾಲ್ನಲ್ಲಿ ಸೇರಿಸಿರುವ ಮೂರು ಮೂಲ ಪ್ರಿಮಿಟಿವ್ಗಳು MCP ಸರ್ವರ್ನ ಸಾಮರ್ಥ್ಯಗಳಾಗಿವೆ:
• Tools: AI ಏಜೆಂಟ್ ಕರೆಯಲು ಸಾದ್ಯವಾಗುವ ವಿಭಿನ್ನ ಕ್ರಿಯೆಗಳು ಅಥವಾ ಕಾರ್ಯಗಳು. ಉದಾಹರಣೆಗೆ, ಒಂದು ಹವಾಮಾನ ಸೇವೆ “get weather” tool ಅನ್ನು ಪ್ರದರ್ಶಿಸಬಹುದು, ಅಥವಾ e-commerce ಸರ್ವರ್ “purchase product” tool ಅನ್ನು ಪ್ರದರ್ಶಿಸಬಹುದು. MCP ಸರ್ವರ್ಗಳು ಪ್ರತಿಯೊಂದು ಸಾಧನದ ಹೆಸರು, ವಿವರಣೆ ಮತ್ತು ಇನ್ಪುಟ್/ಆುಟ್ಪುಟ್ ಸ್ಕೀಮಾವನ್ನು ತಮ್ಮ ಸಾಮರ್ಥ್ಯಗಳ ಪಟ್ಟಿಯಲ್ಲಿ ಜಾಹಿರಿಸುತ್ತವೆ.
• Resources: MCP ಸರ್ವರ್ ಒದಗಿಸಬಲ್ಲ ಓದಿಕೊಳ್ಳಲು ಮಾತ್ರವಾದ ಡೇಟಾ ಐಟಂಗಳು ಅಥವಾ ದಾಖಲೆಗಳು, ಮತ್ತು ಕ್ಲೈಯಿಂಟ್ಗಳು ಅವನ್ನು ಬೇಡಿಕೆಯಿಂದ ಪಡೆದುಕೊಳ್ಳಬಹುದು. ಉದಾಹರಣೆಗಳಾಗಿ ಫೈಲ್ ವಿಷಯಗಳು, ಡೇಟಾಬೇಸ್ ದಾಖಲೆಗಳು ಅಥವಾ ಲಾಗ್ ಫೈಲ್ಗಳು. Resources ಪಠ್ಯ (ಕೋಡ್ ಅಥವಾ JSON) ಅಥವಾ ಬೈನರಿ (ಚಿತ್ರಗಳು ಅಥವಾ PDFಗಳು) ಆಗಿರಬಹುದು.
• Prompts: ಮುಂಚಿತವಾಗಿ ನಿದರ್ಶನವಾಗಿರುವ ಟೆಂಪ್ಲೇಟ್ಗಳು, ಪದೇ ಪದೇ ಬಳಸಿ ಸಂಕೀರ್ಣ ಕಾರ್ಯಪ್ರವಾಹಗಳಿಗೆ ಸೂಚಿತ ಪ್ರಾಂಪ್ಟ್ಗಳನ್ನು ಒದಗಿಸುತ್ತವೆ.
MCP ನ ಪ್ರಯೋಜನಗಳು
MCP AI ಏಜೆಂಟ್ಗಳಿಗಾಗಿ ಮಹತ್ವದ ಲಾಭಗಳನ್ನು ನೀಡುತ್ತದೆ:
• Dynamic Tool Discovery: ಏಜೆಂಟ್ಗಳು ಸರ್ವರ್ನಿಂದ ಲಭ್ಯವಿರುವ ಸಾಧನಗಳ ಪಟ್ಟಿಯನ್ನು ವರ್ಣನೆಗಳೊಂದಿಗೆ ಡೈನಾಮಿಕ್ ಆಗಿ ಸ್ವೀಕರಿಸಬಹುದು. ಇದು ಪರಂಪರಾ APIಗಳೊಂದಿಗೆ ಏಕೆ ವಿಶೇಷವೆಂದರೆ, ಅವುಗಳ ಸಂಯೋಜನೆಗಳಿಗೆ ಸ್ಥಿರ ಕೋಡಿಯ ವಿಷಯವನ್ನು ಅಗತ್ಯಪಡಿಸುತ್ತವೆ, ಅಂದರೆ ಯಾವುದೇ API ಬದಲಾವಣೆಗೆ ಕೋಡ್ புதUPDATE ಬೇಕಾಗುತ್ತದೆ. MCP “integrate once” ವಿಧಾನವನ್ನು ನೀಡಿದ್ದಾರೆ, ಇದರಿಂದ ಹೆಚ್ಚು ಹೊಂದಿಕೊಳ್ಳಬಲ್ಲಿಕೆ ಸಿಗುತ್ತದೆ.
• Interoperability Across LLMs: MCP ವಿಭಿನ್ನ LLMಗಳ ಮೇಲೆ ಕೆಲಸ ಮಾಡುತ್ತದೆ, ಉತ್ತಮ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಪರಿಗಣಿಸಲು ಕೋರ್ ಮಾದರಿಗಳನ್ನು ಬದಲಾಯಿಸಲು ಸೌಕರ್ಯ ಒದಗಿಸುತ್ತದೆ.
• Standardized Security: MCP ಒಂದು ಮಾನಕೃತ ದೃಢೀಕರಣ ವಿಧಾನವನ್ನು ಒಳಗೊಂಡಿದೆ, ಹೆಚ್ಚುವರಿ MCP ಸರ್ವರ್ಗಳಿಗೆ ಪ್ರವೇಶವನ್ನು ಸೇರಿಸುವಾಗ ವಿಸ್ತರಣೆ ಸುಲಭಗೊಳ್ಳುತ್ತದೆ. ಇದು ವಿವಿಧ ಪರಂಪರಾ APIಗಳಿಗಾಗಿ ವಿಭಿನ್ನ ಕೀಗಳು ಮತ್ತು ದೃಢೀಕರಣ ವಿಧಗಳನ್ನು ನಿರ್ವಹಿಸುವುದಕ್ಕಿಂತ ಸರಳವಾಗಿದೆ.
MCP ಉದಾಹರಣೆ
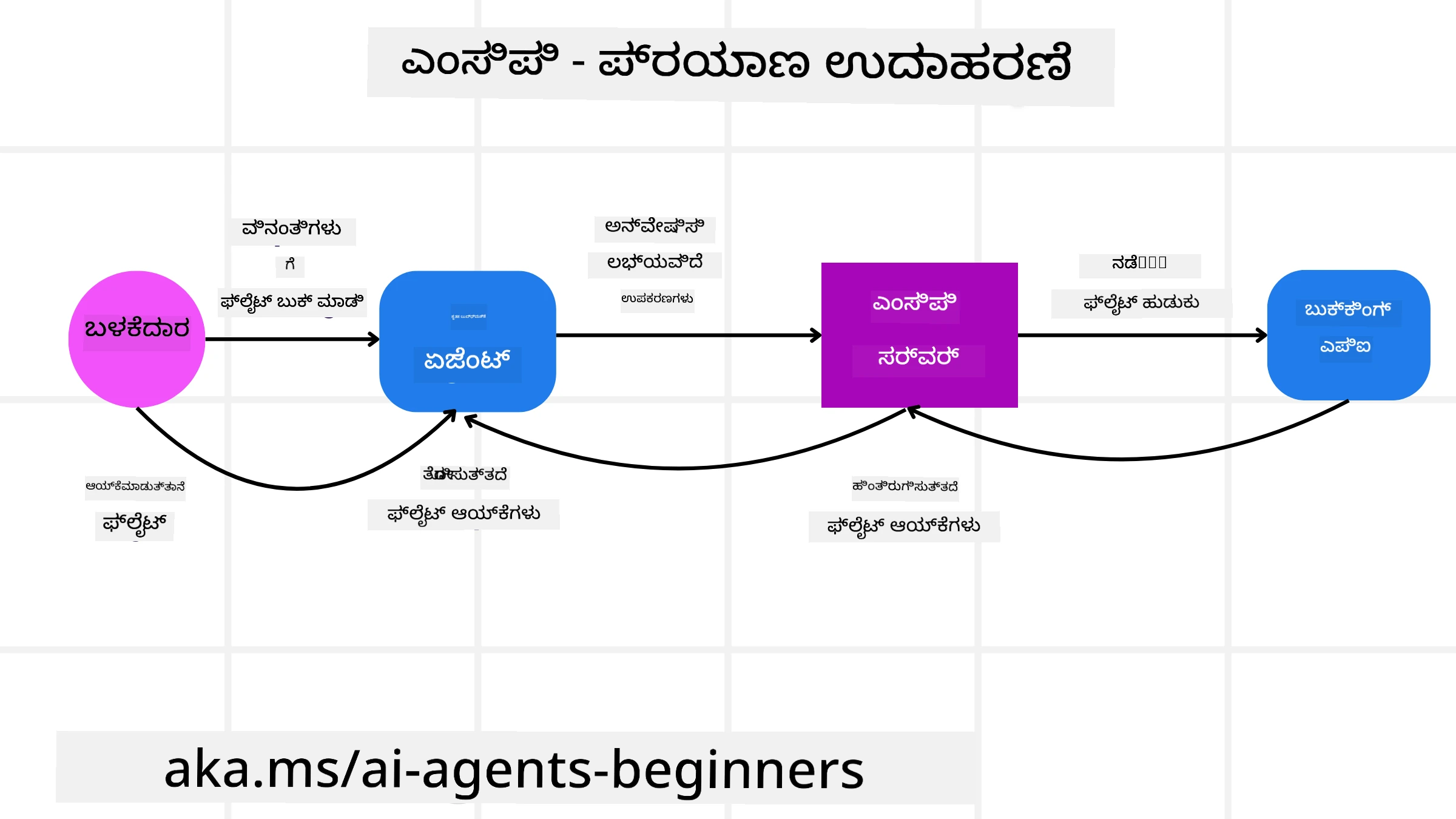
ಒಬ್ಬ ಬಳಕೆದಾರ MCP ಮೂಲಕ ಚಾಲಿತ AI ಸಹಾಯಕವನ್ನು ಬಳಸಿ ವಿಮಾನ ಟಿಕೆಟ್ ಕಾಯ್ದಿರಿಸಲು ಬಯಸುತ್ತಾನೆ ಎಂದು تصورಮಾಡಿ.
-
Connection: AI ಸಹಾಯಕ (MCP ಕ್ಲೈಯಿಂಟ್)一家 ವಿಮಾನ ಕಂಪನಿಯು ಒದಗಿಸಿದ MCP ಸರ್ವರ್ಗೆ ಸಂಪರ್ಕ ಮಾಡುತ್ತದೆ.
-
Tool Discovery: ಕ್ಲೈಯಿಂಟ್ ವಿಮಾನ公司的 MCP ಸರ್ವರ್ಗೆ ಕೇಳುತ್ತದೆ, “What tools do you have available?” ಸರ್ವರ್ “search flights” ಮತ್ತು “book flights” ಜ್ಞಾಪಕಾರ್ಹ ಸಾಧನಗಳಂತೆ ಉತ್ತರಿಸುತ್ತದೆ.
-
Tool Invocation: ನೀವು AI ಸಹಾಯಕನಿಗೆ ಕೇಳುತ್ತೀರಿ, “Please search for a flight from Portland to Honolulu.” AI ಸಹಾಯಕ ತನ್ನ LLM ಬಳಸಿಕೊಂಡು ಇದು “search flights” tool ಅನ್ನು ಕರೆಬೇಕೆಂದು ಗುರುತಿಸಿ ಸಂಬಂಧಿತ ಪರಿಮಾಣಗಳನ್ನು (origin, destination) MCP ಸರ್ವರ್ಗೆ ಪಾಸ್ ಮಾಡುತ್ತದೆ.
-
Execution and Response: MCP ಸರ್ವರ್ wrapper ಆಗಿ ನಿಜವಾದ ವಿಮಾನ公司的 ಆಂತರಿಕ ಬುಕಿಂಗ್ API ಗೆ ಕರೆ ಮಾಡುತ್ತದೆ. ಅದು ವಿಮಾನ ಮಾಹಿತಿ (ಉದಾಹರಣೆಗೆ JSON ಡೇಟಾ) ಸ್ವೀಕರಿಸಿ, AI ಸಹಾಯಕನಿಗೆ ಕಳುಹಿಸುತ್ತದೆ.
-
Further Interaction: AI ಸಹಾಯಕ ವಿಮಾನ ಆಯ್ಕೆಗಳನ್ನು ಪ್ರಸ್ತುತಪಡಿಸುತ್ತದೆ. ನೀವು ಒಂದು ವಿಮಾನವನ್ನು ಆಯ್ಕೆಮಾಡಿದ ನಂತರ, ಸಹಾಯಕ ಅದೇ MCP ಸರ್ವರ್ನಲ್ಲಿ “book flight” tool ಅನ್ನು invoke ಮಾಡಿ, ಬುಕ್ಕಿಂಗ್ ಪೂರ್ಣಗೊಳಿಸಬಹುದು.
ಏಜೆಂಟ್-ಟು-ಏಜೆಂಟ್ ಪ್ರೋಟೋಕಾಲ್ (A2A)
MCP LLMಗಳನ್ನು ಸಾಧನಗಳಿಗೆ ಸಂಪರ್ಕಿಸುವದನ್ನು ಕೇಂದ್ರೀಕರಿಸುತ್ತಿದ್ದರೆ, Agent-to-Agent (A2A) ಪ್ರೋಟೋಕಾಲ್ ಇದನ್ನು ಮುಂದಕ್ಕೆ ತೆಗೆದು ಹೋಗುತ್ತದೆ ಮತ್ತು ವಿಭಿನ್ನ AI ಏಜೆಂಟ್ಗಳ ನಡುವೆ ಸಂವಹನ ಮತ್ತು ಸಹಕಾರವನ್ನು ಸಾಧ್ಯಮಾಡುತ್ತದೆ. A2A ವಿಭಿನ್ನ ಸಂಸ್ಥೆಗಳು, ಪರಿಸರಗಳು ಮತ್ತು ತಂತ್ರಜ್ಞಾನ ಸ್ಟ್ಯಾಕ್ಗಳಲ್ಲಿನ AI ಏಜೆಂಟ್ಗಳನ್ನು ಸೇರಿಸಿ ಸ್ಥಿರಿತ ಕಾರ್ಯವನ್ನು ಪೂರ್ಣಗೊಳಿಸುವಂತೆ ಸಂಯೋಜಿಸುತ್ತದೆ.
ನಾವು A2A ಯ ಘಟಕಗಳು ಮತ್ತು ಪ್ರಯೋಜನಗಳನ್ನು ಪರಿಶೀಲಿಸುತ್ತೇವೆ, ಜೊತೆಗೆ ನಮ್ಮ ಪ್ರವಾಸ ಅಪ್ಲಿಕೇಶನ್ನಲ್ಲಿ ಇದು ಹೇಗೆ ಅನ್ವಯಿಸಬಹುದು ಎಂಬ ಉದಾಹರಣೆಯೂ ನೋಡುವೆವು.
A2A ಮೂಲ ಘಟಕಗಳು
A2A ಏಜೆಂಟ್ಗಳ ನಡುವೆ ಸಂವಹನ ಸಾಧ್ಯವಾಗಿಸುವುದು ಮತ್ತು ಬಳಕೆದಾರನ ಉಪಕಾರ್ಯದ ಒಂದು ಉಪಕಾರ್ಯವನ್ನು ಪೂರ್ಣಗೊಳಿಸಲು ಅವುಗಳನ್ನು ಪರಸ್ಪರ ಕೆಲಸಮಾಡಿಸುವುದನ್ನು ಕೇಂದ್ರೀಕರಿಸುತ್ತದೆ. ಪ್ರೋಟೋಕಾಲ್ನ ಪ್ರತಿ ಘಟಕ ಇದಕ್ಕೆ ಕೊಡುಗೆ ನೀಡುತ್ತದೆ:
Agent Card
MCP ಸರ್ವರ್ ಹೇಗೆ ಸಾಧನಗಳ ಪಟ್ಟಿಯನ್ನು ಹಂಚಿಕೊಳ್ಳುತ್ತದೆ ಎಂದು ಸಾದೃಶ್ಯವಾಗಿ, Agent Card ನಲ್ಲಿ ಇವೆ:
- ಏಜೆಂಟ್ನ ಹೆಸರು .
- ಅದು ಪೂರ್ಣಗೊಳಿಸುವ ಸಾಮಾನ್ಯ ಕೆಲಸಗಳ ವಿವರಣೆ.
- ಇತರ ಏಜೆಂಟ್ಗಳು (ಅಥವಾ ಮಾನವ ಬಳಕೆದಾರರು) ಯಾವಾಗ ಮತ್ತು ಏಕೆ ಆ ಏಜೆಂಟ್ ಅನ್ನು ಕರೆಮಾಡಬೇಕು ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು ಸಹಾಯ ಮಾಡುವ ವಿವರಣೆಗಳೊಂದಿಗೆ ನಿರ್ದಿಷ್ಟ ಕೌಶಲ್ಯಗಳ ಪಟ್ಟಿ.
- ಏಜೆಂಟ್ನ ಪ್ರಸ್ತುತ Endpoint URL
- ಏಜೆಂಟ್ನ ಆವೃತ್ತಿ ಮತ್ತು ಸಾಮರ್ಥ್ಯಗಳು ಉದಾಹರಣೆಗೆ ಸ್ಟ್ರೀಮಿಂಗ್ ಪ್ರತಿಕ್ರಿಯೆಗಳು ಮತ್ತು ಪುಶ್ ನೋಟಿಫಿಕೇಶನ್ಗಳು.
Agent Executor
Agent Executor ಜವಾಬ್ದಾರಿಯುತವಾಗಿದೆ ಬಳಕೆದಾರದ ಚಾಟ್ ಸಂಪ್ರದಾಯವನ್ನು ದೂರದ ಏಜೆಂಟ್ಗೆ ಹೆಪ್ಪಿಸಲು, ದೂರದ ಏಜೆಂಟ್ ಈ ಕಾರ್ಯವನ್ನು ಪೂರ್ಣಗೊಳಿಸಲು ಅದು ಏನು ಮಾಡಬೇಕು ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು ಇದೊಂದು ಅಗತ್ಯ. A2A ಸರ್ವರ್ನಲ್ಲಿ, ಒಂದು ಏಜೆಂಟ್ ತನ್ನದೇ ಆದ Large Language Model (LLM) ಅನ್ನು ಬಳಸಿಕೊಂಡು ಇನ್ಕಮಿಂಗ್ ವಿನಂತಿಗಳನ್ನು ವಿವೇಚಿಸಿ ತನ್ನ ಆಂತರಿಕ ಸಾಧನಗಳನ್ನು ಬಳಸಿ ಕಾರ್ಯಗಳನ್ನು ನಿರ್ವಹಿಸುತ್ತದೆ.
Artifact
ഒരു ದೂರದ ಏಜೆಂಟ್ ವಿನಂತಿಸಲಾದ ಕಾರ್ಯವನ್ನು ಪೂರ್ಣಗೊಳಿಸಿದ ನಂತರ, ಅದರ ಕಾರ್ಯಫಲವನ್ನು ಒಂದು ಆರ್ಟಿಫ್ಯಾಕ್ಟ್గా ನಿರ್ಮಿಸಲಾಗುತ್ತದೆ. ಒಂದು ಆರ್ಟಿಫ್ಯಾಕ್ಟ್ನಲ್ಲಿ ಏಜೆಂಟ್ನ ಕೆಲಸದ ಫಲಿತಾಂಶವನ್ನು ಸೇರಿಸಲಾಗುತ್ತದೆ, ಏನು ಪೂರ್ಣಗೊಳಿಸಲಾಯಿತು ಎಂಬ ವಿವರಣೆ ಮತ್ತು ಪ್ರೋಟೋಕಾಲ್ ಮೂಲಕ ಕಳುಹಿಸಲಾದ ಪಠ್ಯ ಸಂಪ್ರದಾಯ ಇರುತ್ತದೆ. ಆರ್ಟಿಫ್ಯಾಕ್ಟ್ ಕಳುಹಿಸಿದ ನಂತರ, ಅವಶ್ಯಕತೆ ಬರುವವರೆಗೂ ದೂರದ ಏಜೆಂಟ್ನೊಂದಿಗೆ ಸಂಪರ್ಕವನ್ನು ನಿಲ್ಲಿಸಲಾಗುತ್ತದೆ.
Event Queue
ಈ ಘಟಕವು ಅัป್ಡೇಟ್ಗಳು ನಿರ್ವಹಿಸುವುದು ಮತ್ತು ಸಂದೇಶಗಳನ್ನು ಹಂಚುವದುಗಾಗಿ ಬಳಸಲಾಗುತ್ತದೆ. ಕಾರ್ಯ ಪೂರ್ಣಗೊಳ್ಳುವವರೆಗೆ ಏಜೆಂಟ್ಗಳ ನಡುವಿನ ಸಂಪರ್ಕ ಮುಚ್ಚಿಸದಂತೆ, ವಿಶೇಷವಾಗಿ ಕಾರ್ಯ ಪೂರ್ಣಗೊಳ್ಳಲು ಹೆಚ್ಚು ಕಾಲ ತೆಗೆದುಕೊಳ್ಳಬಹುದು ಎಂಬ ಸಂದರ್ಭದಲ್ಲಿ, ಅದು ಉತ್ಪಾದನೆಯಲ್ಲಿ ಭಾರೀಗೌರವಯುತವಾಗಿದೆ.
A2A ನ ಪ್ರಯೋಜನಗಳು
• ವೃದ್ಧಿತ ಸಹಕಾರ: ವಿಭಿನ್ನ ವಿತರಕರ ಮತ್ತು ವೇದಿಕೆಗಳ ಏಜೆಂಟ್ಗಳು ಪರಸ್ಪರ ಸಂವಹನ ಮಾಡುವುದು, ಸಮಗ್ರКонтೆಕ್ಸ್ಟ್ ಹಂಚಿಕೊಳ್ಳುವುದು ಮತ್ತು ಪರಸ್ಪರ ಕೆಲಸಮಾಡುವುದು ಸಾಧ್ಯಮಾಡುತ್ತದೆ, ಇದರಿಂದ ಸಾಮಾನ್ಯವಾಗಿ ಬೇರ್ಪಟ್ಟ ವ್ಯವಸ್ಥೆಗಳ ನಡುವೆ ಸಲೀಸು ಸ್ವಯಂಚಾಲನ ಸಾಧ್ಯವಾಗುತ್ತದೆ.
• ಮಾದರಿ ಆಯ್ಕೆ ನಿರ್ವಹಣಾ ಉಸ್ತುವಾರಿ: ಪ್ರತಿ A2A ಏಜೆಂಟ್ ತನ್ನ ವಿನಂತಿಗಳ ಸೇವೆಗಾಗಿ ಯಾವ LLM ಅನ್ನು ಬಳಸುವುದು ಎಂದು ನಿರ್ಧರಿಸಬಹುದು, ಇದು ಪ್ರತಿ ಏಜೆಂಟ್ಗೆ ಅತ್ಯುತ್ತಮ ಅಥವಾ ಫೈನ್-ಟ್ಯೂನ್ ಮಾಡಲಾದ ಮಾದರಿಗಳನ್ನು ಬಳಸುವ ಅವಕಾಶವನ್ನು ನೀಡುತ್ತದೆ, ಕೆಲವು MCP ದೃಶ್ಯಗಳಲ್ಲಿ ಒಂದೇ LLM ಸಂಪರ್ಕದಾಗಿರೋ ಸ್ಥಿತಿಯನ್ನು ಮೀರಿ.
• ನೆರೆಯಲ್ಲಿರುವ ದೃಢೀಕರಣ: ದೃಢೀಕರಣ ನೇರವಾಗಿ A2A ಪ್ರೋಟೋಕಾಲ್ಗೆ ಒಳಗೊಂಡಿದೆ, ಏಜೆಂಟ್ ಸಂವಹನಗಳಿಗೆ ಬಲಿಷ್ಠ ಭದ್ರತಾ ಫ್ರೇಮ್ವರ್ಕ್ ಒದಗಿಸುತ್ತದೆ.
A2A ಉದಾಹರಣೆ
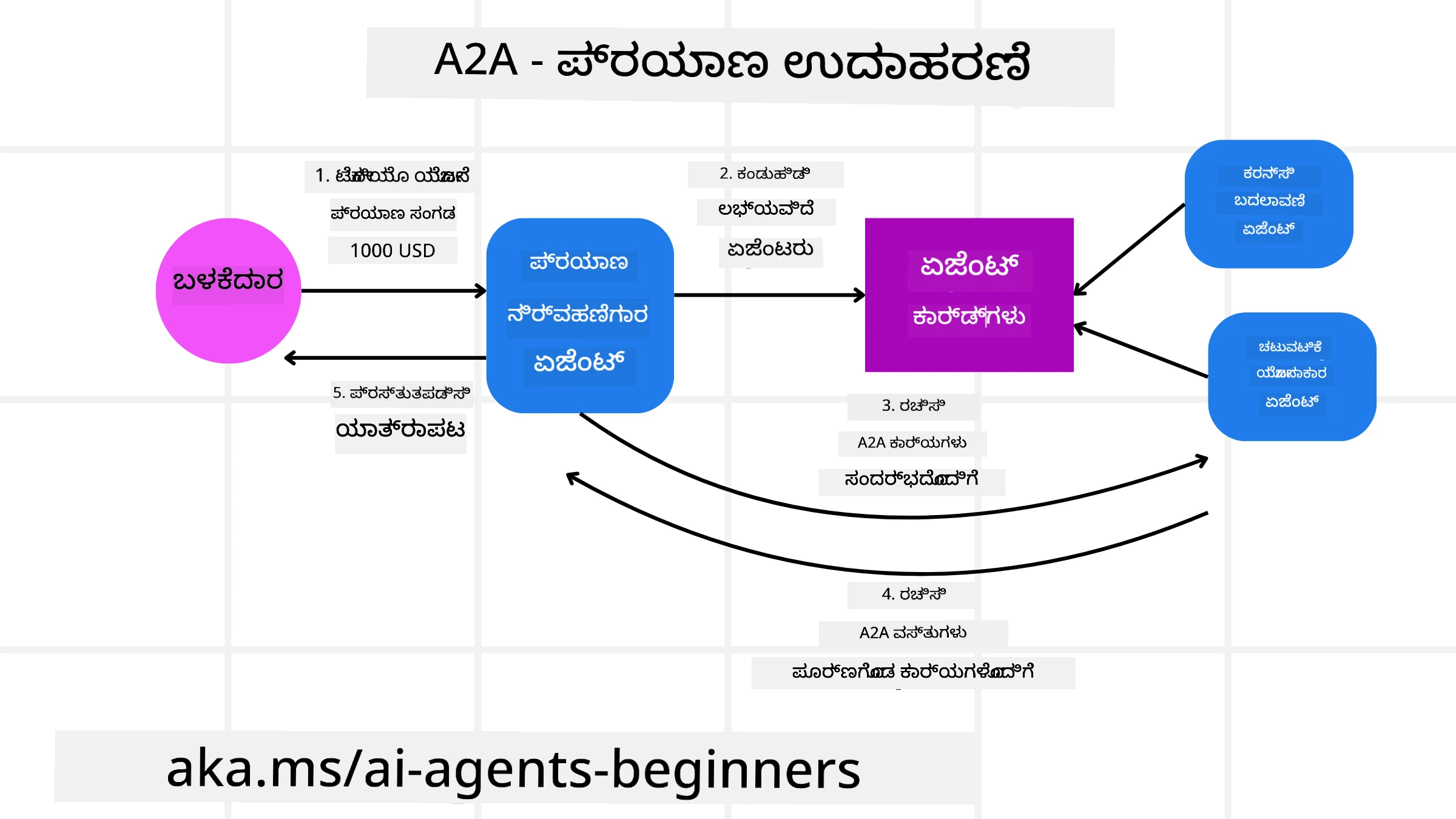
ನಮ್ಮ ಪ್ರವಾಸ ಬುಕ್ಕಿಂಗ್ ದೃಶ್ಯವನ್ನು A2A ಬಳಸಿಕೊಂಡು ವಿಸ್ತರಿಸೋಣ.
-
User Request to Multi-Agent: ಬಳಕೆದಾರನು “Travel Agent” A2A ಕ್ಲೈಯಿಂಟ್/ಏಜೆಂಟ್ನ್ನು ಸಂಪರ್ಕಿಸಿ, “Please book an entire trip to Honolulu for next week, including flights, a hotel, and a rental car” ಎಂದು ಕೇಳುತ್ತಾನೆ.
-
Orchestration by Travel Agent: Travel Agent ಈ ಸಂಕೀರ್ಣ ವಿನಂತಿಯನ್ನು ಪಡೆದ ಮೇಲೆ, ತನ್ನ LLM ಅನ್ನು ಬಳಸಿಕೊಂಡು ಕಾರ್ಯದ ಬಗ್ಗೆ ತಾರ್ಕಿಕವಾಗಿ ಆಲೋಚಿಸಿ ಅದು ಕೆಲವು ವಿಶೇಷ ಏಜೆಂಟ್ಗಳೊಂದಿಗೆ ಸಂವಹನ ಮಾಡಬೇಕೆಂದು ನಿರ್ಧರಿಸುತ್ತದೆ.
-
Inter-Agent Communication: Travel Agent ನಂತರ A2A ಪ್ರೋಟೋಕಾಲ್ ಅನ್ನು ಬಳಸಿ ಡೌನ್ಸ್ಟ್ರೀಮ್ ಏಜೆಂಟ್ಗಳೊಂದಿಗೆ ಸಂಪರ್ಕ ಮಾಡುತ್ತದೆ, ಉದಾಹರಣೆಗೆ ವಿಭಿನ್ನ ಕಂಪನಿಗಳು ರಚಿಸಿದ “Airline Agent”, “Hotel Agent”, ಮತ್ತು “Car Rental Agent”.
-
Delegated Task Execution: Travel Agent ಪ್ರತಿ ವಿಶೇಷ ಏಜೆಂಟ್ಗೆ ನಿರ್ದಿಷ್ಟ ಕಾರ್ಯಗಳನ್ನು ಕಳುಹಿಸುತ್ತದೆ (ಉದಾಹರಣೆಗೆ, “Find flights to Honolulu”, “Book a hotel”, “Rent a car”). ಪ್ರತಿಯೊಂದು ವಿಶೇಷ ಏಜೆಂಟ್ ತನ್ನದೇ ಆದ LLMಗಳನ್ನು ನಡೆಸುತ್ತ ಮತ್ತು ತನ್ನ ಅಂತರ್ತಂಕ ಸಾಧನಗಳನ್ನು ಬಳಸಿ (ಯಾವವು MCP ಸರ್ವರ್ಗಳಾಗಿರಬಹುದು) ಅದರ ನಿರ್ದಿಷ್ಟ ಭಾಗವನ್ನು ನಿರ್ವಹಿಸುತ್ತದೆ.
-
Consolidated Response: ಎಲ್ಲಾ ಡೌನ್ಸ್ಟ್ರೀಮ್ ಏಜೆಂಟ್ಗಳು ತಮ್ಮ ಕಾರ್ಯಗಳನ್ನು ಪೂರ್ಣಗೊಳಿಸಿದ ನಂತರ, Travel Agent ಫಲಿತಾಂಶಗಳನ್ನು (ವಿಮಾನ ವಿವರಗಳು, ಹೋಟೆಲ್ ದೃಢೀಕರಣ, ಕಾರ್ ರೆಂಟಲ್ ಬುಕ್ಕಿಂಗ್) ಸಂಯೋಜಿಸಿ ಬಳಕೆದಾರನಿಗೆ ಚಾಟ್ ಶೈಲಿಯಲ್ಲಿ ಸಮಗ್ರ ಪ್ರತಿಕ್ರಿಯೆ ಕಳುಹಿಸುತ್ತದೆ.
ನೈಸರ್ಗಿಕ ಭಾಷೆ ವೆಬ್ (NLWeb)
ವೆಬ್ಸೈಟ್ಗಳು ಉದ್ದಾನದಿಂದಲೋ ಬಳಕೆದಾರರು ಇಂಟರ್ನೆಟ್ ಅಂಚులో ಮಾಹಿತಿ ಮತ್ತು ಡೇಟಾ ಪ್ರಾಪ್ತಿಗೊಳಿಸಲು ಮುಖ್ಯ ಮಾರ್ಗವಾಗಿಯೇ ಇದ್ದವೆ.
ಇದೀಗ NLWeb 的 ವಿಭಿನ್ನ ಘಟಕಗಳನ್ನು, NLWeb ನ ಪ್ರಯೋಜನಗಳನ್ನು ಮತ್ತು ನಮ್ಮ ಪ್ರವಾಸ ಅಪ್ಲಿಕೇಶನ್ ಮೂಲಕ ನಮ್ಮ NLWeb ಹೇಗೆ ಕೆಲಸ ಮಾಡುತ್ತದೆ ಎಂಬುದರ ಉದಾಹರಣೆಯನ್ನು ನೋಡೋಣ.
NLWeb ಘಟಕಗಳು
-
NLWeb Application (Core Service Code): ನೈಸರ್ಗಿಕ ಭಾಷೆ ಪ್ರಶ್ನೆಗಳನ್ನು ಪ್ರಕ್ರಿಯಗೊಳಿಸುವ ವ್ಯವಸ್ಥೆ. ಇದು ವೇದಿಕೆಯ ವಿಭಿನ್ನ ಭಾಗಗಳನ್ನು ಸಂಯೋಜಿಸಿ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ರಚಿಸುತ್ತದೆ. ನೀವು ಇದನ್ನು ವೆಬ್ಸೈಟ್ನ ನೈಸರ್ಗಿಕ ಭಾಷಾ ವೈಶಿಷ್ಟ್ಯಗಳಿಗೆ ಶಕ್ತಿ ಒದಗಿಸುವ ಇಂಜಿನ್ ಎಂದು கரತ್ಕೊಳ್ಳಬಹುದು.
-
NLWeb Protocol: ವೆಬ್ಸೈಟ್ಗಳೊಂದಿಗೆ ನೈಸರ್ಗಿಕ ಭಾಷೆ ಪರಸ್ಪರ ಕ್ರಿಯೆಗೆ ಮೂಲಭೂತ ನಿಯಮಗಳ ಸಮೂಹ. ಇದು ಪ್ರತ್ಯುತ್ತರಗಳನ್ನು JSON ಫಾರ್ಮ್ಯಾಟ್ನಲ್ಲಿ (ಸಾಮಾನ್ಯವಾಗಿ Schema.org ಅನ್ನು ಬಳಸಿ) ಕಳುಹಿಸುತ್ತದೆ. ಇದರ ಉದ್ದೇಶ “AI Web” ಅನ್ನು ರಚಿಸಲು ಸರಳ ನೆಲೆಯನ್ನೇ ಒದಗಿಸುವುದು, ಹೇಗೆ HTML ಆನ್ಲೈನ್ನಲ್ಲಿ ದಸ್ತಾವೇಜುಗಳನ್ನು ಹಂಚಿಕೊಳ್ಳಲು ಸಾಧ್ಯಮಾಡಿತು ಎಂದು ಇಹೇಗೇ.
-
MCP Server (Model Context Protocol Endpoint): ಪ್ರತಿ NLWeb ಸೆಟ್ಅಪ್ ಕೂಡ MCP ಸರ್ವರ್ ಆಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ. ಇದರರ್ಥ ಅದು ಇತರ AI ವ್ಯವಸ್ಥೆಗಳೊಂದಿಗೆ ಸಾಧನಗಳನ್ನು (ಉದಾಹರಣೆಗೆ “ask” ವಿಧಾನ) ಮತ್ತು ಡೇಟಾ ಹಂಚಿಕೊಳ್ಳಲು ಸಾಧ್ಯವಾಗುತ್ತದೆ. ಅಭ್ಯಾಸದಲ್ಲಿ, ಇದರಿಂದ ವೆಬ್ಸೈಟ್ನ ವಿಷಯ ಮತ್ತು ಸಾಮರ್ಥ್ಯಗಳು AI ಏಜೆಂಟ್ಗಳ ಬಳಕೆದಾರ್ಯೋಗ್ಯವಾಗುತ್ತವೆ, ಮತ್ತು ಸೈಟ್ ದೊಡ್ಡ “ಏಜೆಂಟ್ ಪರಿಸರ” ಭಾಗವಾಗುತ್ತದೆ.
-
Embedding Models: ಈ ಮಾದರಿಗಳು ವೆಬ್ಸೈಟ್ ವಿಷಯವನ್ನು ವೆಕ್ಟರ್ಗಳು (embeddings) ಎಂದು ಕರೆಯಲ್ಪಡುವ ಸಂಖ್ಯಾತ್ಮಕ ಪ್ರತಿನಿಧಿಗಳಾಗಿ ರূপಾಂತರಿಸಲು ಬಳಸಲ್ಪಡುತ್ತವೆ. ಈ ವೆಕ್ಟರ್ಗಳು ಕಂಪ್ಯೂಟರ್ಗಳು ಹೋಲಿಸಿ ಹುಡುಕುವ ರೀತಿಯಲ್ಲಿ ಅರ್ಥವನ್ನು ಹಿಡಿದಿಟ್ಟುಕೊಳ್ಳುತ್ತವೆ. ಅವುಗಳನ್ನು ವಿಶೇಷ ಡೇಟಾಬೇಸ್ನಲ್ಲಿ ಸಂಗ್ರಹಿಸಲಾಗುತ್ತದೆ, ಮತ್ತು ಬಳಕೆದಾರರು ಯಾವ embedding ಮಾದರಿಯನ್ನು ಬಳಸಬೇಕೆಂದು ಆಯ್ಕೆಮಾಡಬಹುದು.
-
Vector Database (Retrieval Mechanism): ಈ ಡೇಟಾಬೇಸ್ ವೆಬ್ಸೈಟ್ ವಿಷಯದ embeddings ಅನ್ನು ಸಂಗ್ರಹಿಸುತ್ತದೆ. ಯಾರಾದರೂ ಪ್ರಶ್ನೆ ಕೇಳಿದಾಗ, NLWeb ತ್ವರಿತವಾಗಿ ಅತ್ಯಂತ ಸಮಂಜಸ ಮಾಹಿತಿಯನ್ನು ಕಂಡುಹಿಡಿಯಲು ವೆಕ್ಟರ್ ಡೇಟಾಬೇಸ್ ಅನ್ನು ಪರಿಶೀಲಿಸುತ್ತದೆ. ಇದು ಸಮಾನತೆ ಆಧಾರಿತವಾಗಿ ಶ್ರೇಣೀಕರಿಸಲಾದ ಸಾಧ್ಯಉತ್ತರಗಳ ವೇಗದ ಪಟ್ಟಿಯನ್ನು ನೀಡುತ್ತದೆ. NLWeb Qdrant, Snowflake, Milvus, Azure AI Search, ಮತ್ತು Elasticsearch ಸೇರಿದಂತೆ ವಿಭಿನ್ನ ವೆಕ್ಟರ್ ಸ್ಟೋರೇಜ್ ಸಿಸ್ಟಮ್ಗಳೊಂದಿಗೆ ಕೆಲಸ ಮಾಡುತ್ತದೆ.
NLWeb ಉದಾಹರಣೆಯ ಮೂಲಕ
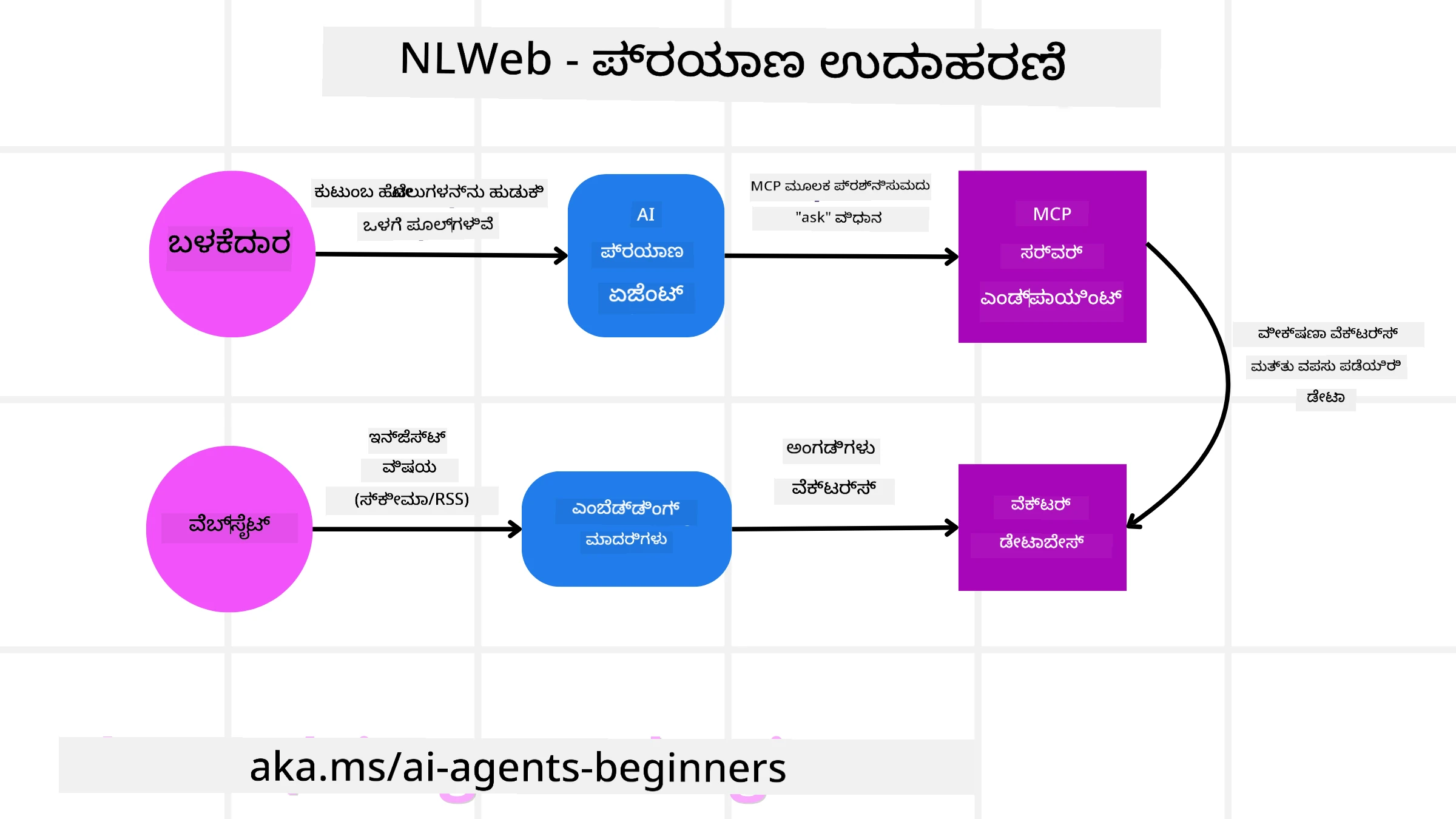
ನಮ್ಮ ಪ್ರವಾಸ ಬುಕ್ಕಿಂಗ್ ವೆಬ್ಸೈಟ್ವನ್ನು ಮತ್ತೆ ಪರಿಗಣಿಸಿರಿ, ಆದರೆ ಇ ครั้ง ಇದು NLWeb ಮೂಲಕ ಚಾಲಿತವಾಗಿದೆ.
-
Data Ingestion: ಪ್ರವಾಸ ವೆಬ್ಸೈಟ್ನ നിലവಿನ ಉತ್ಪನ್ನ ಕ್ಯಾಟಲೋಗ್ಗಳು (ಉದಾಹರಣೆಗೆ ವಿಮಾನ ಪಟ್ಟಿ, ಹೋಟೆಲ್ ವರ್ಣನೆಗಳು, ಪ್ರವಾಸ ಪ್ಯಾಕೇಜ್ಗಳು) Schema.org ಬಳಸಿ ಸ್ವರೂಪಗೊಳಿಸಲಾಗುತ್ತವೆ ಅಥವಾ RSS ಫೀಡ್ಗಳ ಮೂಲಕ ಲೋಡ್ ಮಾಡಲಾಗುತ್ತವೆ. NLWeb ನ ಸಲಕರಣೆಗಳು ಈ ಸಂರಚಿತ ಡೇಟಾವನ್ನು దిగಿಸಿ, embeddings ರಚಿಸಿ ಮತ್ತು ಅವುಗಳನ್ನು ಸ್ಥಳೀಯ ಅಥವಾ ರಿಮೋಟ್ ವೆಕ್ಟರ್ ಡೇಟಾಬೇಸ್ನಲ್ಲಿ ಸಂಗ್ರಹಿಸಬೇಕೆಂದು ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತವೆ.
-
Natural Language Query (Human): ಬಳಕೆದಾರ ವೆಬ್ಸೈಟ್ಗೆ ಭೇಟಿ ನೀಡುತ್ತಾನೆ ಮತ್ತು ಮೆನುಗಳನ್ನು ತಿರುವುಗೊಳಿಸ ಬದಲು ಚಾಟ್ ಇಂಟರ್ಫೇಸ್ನಲ್ಲಿ ಟೈಪ್ ಮಾಡುತ್ತಾನೆ: “Find me a family-friendly hotel in Honolulu with a pool for next week”.
-
NLWeb Processing: NLWeb ಅಪ್ಲಿಕೇಶನ್ ಈ ಪ್ರಶ್ನೆಯನ್ನು ಸ್ವೀಕರಿಸುತ್ತದೆ. ಇದು ಇಂಗಿತವನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು ಪ್ರಶ್ನೆಯನ್ನು LLM ಗೆ ಕಳುಹಿಸುತ್ತದೆ ಮತ್ತು ಸಮಕಾಲೀನವಾಗಿ ತನ್ನ ವೆಕ್ಟರ್ ಡೇಟಾಬೇಸ್ ಅನ್ನು ಸರ್ಸುತ್ ಮಾಡುತ್ತಲೆ ಸಂಬಂಧಿತ ಹೋಟೆಲ್ ಪಟ್ಟಿ ಗಳು ಕಂಡುಹಿಡಿಯುತ್ತದೆ.
-
Accurate Results: LLM ಡೇಟಾಬೇಸ್ನ ಹುಡುಕಾಟ ಫಲಿತಾಂಶಗಳನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು ಸಹಾಯ ಮಾಡುತ್ತದೆ, “family-friendly”, “pool”, ಮತ್ತು “Honolulu” ಮಾನದಂಡಗಳ ಆಧಾರದ ಮೇಲೆ ಉತ್ತಮ ಹೊಂದಾಣಿಕೆಯನ್ನು ಗುರುತಿಸುತ್ತದೆ, ಮತ್ತು ನಂತರ ನೈಸರ್ಗಿಕ ಭಾಷೆಯಲ್ಲಿನ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ರೂಪಿಸುತ್ತದೆ. ಬಹುತೇಕ ಮಹತ್ವದ ವಿಷಯವೆಂದರೆ, ಪ್ರತಿಕ್ರಿಯೆ ವೆಬ್ಸೈಟ್ನ ಕ್ಯಾಟಲೋಗ್ನ ನಿಜವಾದ ಹೋಟೆಲ್ಗಳನ್ನು ಉಲ್ಲೇಖಿಸುತ್ತದೆ ಮತ್ತು ಕಲ್ಪಿತ ಮಾಹಿತಿಯನ್ನು ತಪ್ಪಿಸುತ್ತದೆ.
-
AI Agent Interaction: NLWeb MCP ಸರ್ವರ್ ಆಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸಿದ್ದರಿಂದ, ಹೊರೆಯ AI ಪ್ರವಾಸ ಏಜೆಂಟ್ ಕೂಡ ಈ ವೆಬ್ಸೈಟ್ನ NLWeb ಘಟಕಕ್ಕೆ ಸಂಪರ್ಕಿಸಬಹುದು. AI ಏಜೆಂಟ್ ನಂತರ
ask("Are there any vegan-friendly restaurants in the Honolulu area recommended by the hotel?")MCP ವಿಧಾನವನ್ನು ಬಳಸಿಕೊಂಡು ವೆಬ್ಸೈಟ್ಗೆ ನೇರವಾಗಿ ಪ್ರಶ್ನೆ ಕೇಳಬಹುದು. NLWeb ಘಟಕವು ಇದನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಿ, ತನ್ನ ರೆಸ್ಟೌರೆಂಟ್ ಮಾಹಿತಿಯ ಡೇಟಾಬೇಸ್ (ಲೋಡ್ ಮಾಡಿದ್ದರೆ) ಅನ್ನು ಬಳಸಿಕೊಂಡು ರಚನಾತ್ಮಕ JSON ಪ್ರತಿಕ್ರಿಯೆ ನೀಡುತ್ತದೆ.
MCP/A2A/NLWeb ಬಗ್ಗೆ ಇನ್ನೂ ಹೆಚ್ಚಿನ ಪ್ರಶ್ನೆಗಳಿವೆಯೇ?
Join the Microsoft Foundry Discord to meet with other learners, attend office hours and get your AI Agents questions answered.
ಸಂಪನ್ಮೂಲಗಳು
ನಿರಾಕರಣೆ: ಈ ದಸ್ತಾವೇಜನ್ನು AI ಅನುವಾದ ಸೇವೆ Co-op Translator ಬಳಸಿ ಅನುವಾದಿಸಲಾಗಿದೆ. ನಾವು ನಿಖರತೆಗೆ ಪ್ರಯತ್ನಿಸಿದರೂ, ಸ್ವಯಂಚಾಲಿತ ಅನುವಾದಗಳಲ್ಲಿ తప్పುಗಳು ಅಥವಾ ಅಸಮರ್ಪಕತೆಗಳು ಇರುವ ಸಾಧ್ಯತೆ ಇದೆ ಎಂಬುದನ್ನು ದಯವಿಟ್ಟು ಗಮನಿಸಿ. ಮೂಲ ಭಾಷೆಯಲ್ಲಿರುವ ಮೂಲ ದಸ್ತಾವೇಜನ್ನು ಅಧಿಕೃತ ಮತ್ತು ನಾಮಮಾತ್ರವಾದ ಮೂಲವಾಗಿ ಪರಿಗಣಿಸಬೇಕು. ಗಂಭೀರ ಅಥವಾ حیತ್ವಪೂರ್ಣ ಮಾಹಿತಿಗಾಗಿ ವೃತ್ತಿಪರ ಮಾನವ ಅನುವಾದವನ್ನು ಶಿಫಾರಸು ಮಾಡಲಾಗುತ್ತದೆ. ಈ ಅನುವಾದದ ಬಳಕೆಯಿಂದ ಉಂಟಾಗುವ ಯಾವುದೇ ತಪ್ಪು ಗ್ರಹಿಕೆಗಳು ಅಥವಾ ತಪ್ಪು ವ್ಯಾಖ್ಯಾನಗಳಿಗಾಗಿ ನಾವು ಹೊಣೆಗಾರರಾಗುವುದಿಲ್ಲ.