ai-agents-for-beginners
AI एजंट्ससाठी संदर्भ अभियांत्रिकी

(या धड्याचा व्हिडीओ पाहण्यासाठी वरील प्रतिमा क्लिक करा)
तुम्ही ज्यासाठी AI एजंट तयार करत आहात त्या अनुप्रयोगाच्या क्लिष्टतेचे समजणे विश्वासार्ह एजंट बनवण्यासाठी महत्त्वाचे आहे. आमच्या गरजांनुसार प्रभावीपणे माहिती व्यवस्थापित करण्यासाठी AI एजंट तयार करणे आवश्यक आहे जे फक्त प्रॉम्प्ट अभियांत्रिकीपुरते मर्यादित नाहीत.
या धड्यात, आपण संदर्भ अभियांत्रिकी म्हणजे काय आणि AI एजंट्स तयार करताना त्याची भूमिका काय आहे हे पाहू.
परिचय
हा धडा खालील गोष्टी समजावून सांगेल:
• संदर्भ अभियांत्रिकी म्हणजे काय आणि ती प्रॉम्प्ट अभियांत्रिकीपेक्षा का वेगळी आहे.
• प्रभावी संदर्भ अभियांत्रिकीसाठी रणनीती, जसे की माहिती लिहिणे, निवडणे, संक्षेप करणे आणि वेगळे करण्याबाबत.
• सामान्य संदर्भ त्रुटी ज्यामुळे तुमचा AI एजंट अयशस्वी होऊ शकतो आणि त्यांना कसे दुरुस्त करावे.
शिकण्याचे उद्दिष्टे
हा धडा पूर्ण केल्यानंतर, तुम्हाला समजेल की:
• संदर्भ अभियांत्रिकीची व्याख्या करा आणि ती प्रॉम्प्ट अभियांत्रिकीपेक्षा कशी वेगळी आहे ते ओळखा.
• मोठ्या भाषा मॉडेल (LLM) अनुप्रयोगांमध्ये संदर्भाचे प्रमुख घटक ओळखा.
• एजंटची कार्यक्षमता सुधारण्यासाठी संदर्भ लिहिणे, निवडणे, संक्षेप करणे आणि वेगळे करण्याच्या रणनीती लागू करा.
• सामान्य संदर्भ त्रुटी जसे की विषबाधा, विचलन, गोंधळ आणि संघर्ष ओळखा, आणि त्यावर उपाययोजना करा.
संदर्भ अभियांत्रिकी म्हणजे काय?
AI एजंटसाठी संदर्भ म्हणजे AI एजंटची आखणी पुढील क्रिया घेण्यासाठी चालवणारी माहिती. संदर्भ अभियांत्रिकी म्हणजे AI एजंटला कार्याच्या पुढील टप्पा पूर्ण करण्यासाठी योग्य माहिती असणे सुनिश्चित करण्याचा सराव. संदर्भ विंडोची मर्यादा असते, म्हणून एजंट तयार करणाऱ्यांनी संदर्भ विंडोमध्ये माहिती वाढवणे, काढणे आणि संक्षेप करणे यासाठी प्रणाली आणि प्रक्रिया तयार करणे आवश्यक आहे.
प्रॉम्प्ट अभियांत्रिकी वि. संदर्भ अभियांत्रिकी
प्रॉम्प्ट अभियांत्रिकी एक स्थिर सूचनांचा संच वापरून AI एजंट्सना प्रभावी मार्गदर्शन करण्यावर लक्ष केंद्रित करते. संदर्भ अभियांत्रिकी म्हणजे सुरुवातीच्या प्रॉम्प्टसह अंतर्भूत डायनॅमिक माहिती संचावर नियंत्रण ठेवण्याचा मार्ग, ज्यामुळे AI एजंटला वेळेनुसार हवे ते मिळते. संदर्भ अभियांत्रिकीचा मुख्य उद्देश ही प्रक्रिया पुनर्रचित आणि विश्वसनीय बनवणे आहे.
संदर्भाचे प्रकार
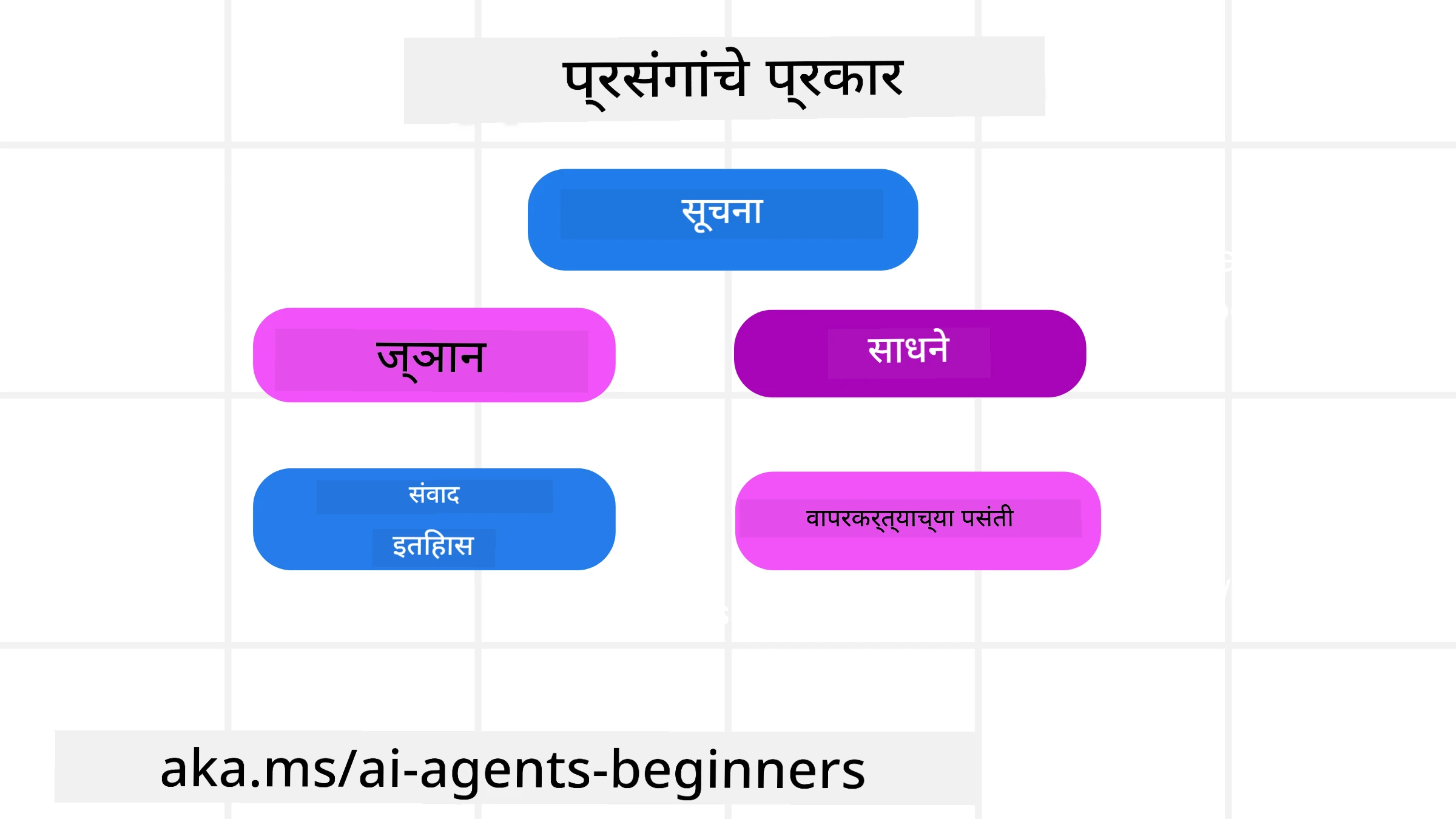
हे लक्षात ठेवणे महत्त्वाचे आहे की संदर्भ फक्त एकच गोष्ट नाही. AI एजंटला हवासी असलेल्या माहितीस विविध स्रोतांमधून मिळू शकते आणि एजंटला या स्रोतांचा प्रवेश असेल याची आम्हाला काळजी घ्यावी लागते:
AI एजंटला व्यवस्थापित करावी लागणाऱ्या संदर्भाचे प्रकार खालीलप्रमाणे आहेत:
• सूचना: एजंटचे “नियम”सारखे असतात – प्रॉम्प्ट, सिस्टम मेसेजेस, फ्यू-शॉट उदाहरणे (AI ला कसे करण्याचे दाखवणे), आणि तो वापरू शकणाऱ्या साधनांचे वर्णन. प्रॉम्प्ट अभियांत्रिकी आणि संदर्भ अभियांत्रिकी येथे एकत्रित होतात.
• ज्ञान: तथ्ये, डेटाबेसमधून मिळालेली माहिती किंवा एजंटकडे असलेली दीर्घकालीन आठवण. यदि एजंटला वेगवेगळ्या ज्ञान साठा आणि डेटाबेसमध्ये प्रवेश हवा असेल, तर Retrieval Augmented Generation (RAG) प्रणालीचा समावेश केला जातो.
• साधने: बाह्य फंक्शन्स, APIs आणि MCP सर्व्हर्सची व्याख्या जी एजंट कॉल करू शकतो, तसेच त्यांचे फीडबॅक (परिणाम).
• संवाद इतिहास: वापरकर्त्याबरोबर चालू संवाद. वेळ जशी जाते, संवाद जास्त आणि क्लिष्ट होतात, ज्यामुळे संदर्भ विंडोमध्ये जागा घेतली जाते.
• वापरकर्त्याच्या प्राधान्यक्रम: काळजीपूर्वक वापरकर्त्याच्या आवडी-निवडींबाबत शिकलेली माहिती. ही माहिती जतन केली जाऊ शकते आणि महत्त्वाच्या निर्णयांसाठी वापरली जाऊ शकते.
प्रभावी संदर्भ अभियांत्रिकीसाठी रणनीती
नियोजन रणनीती
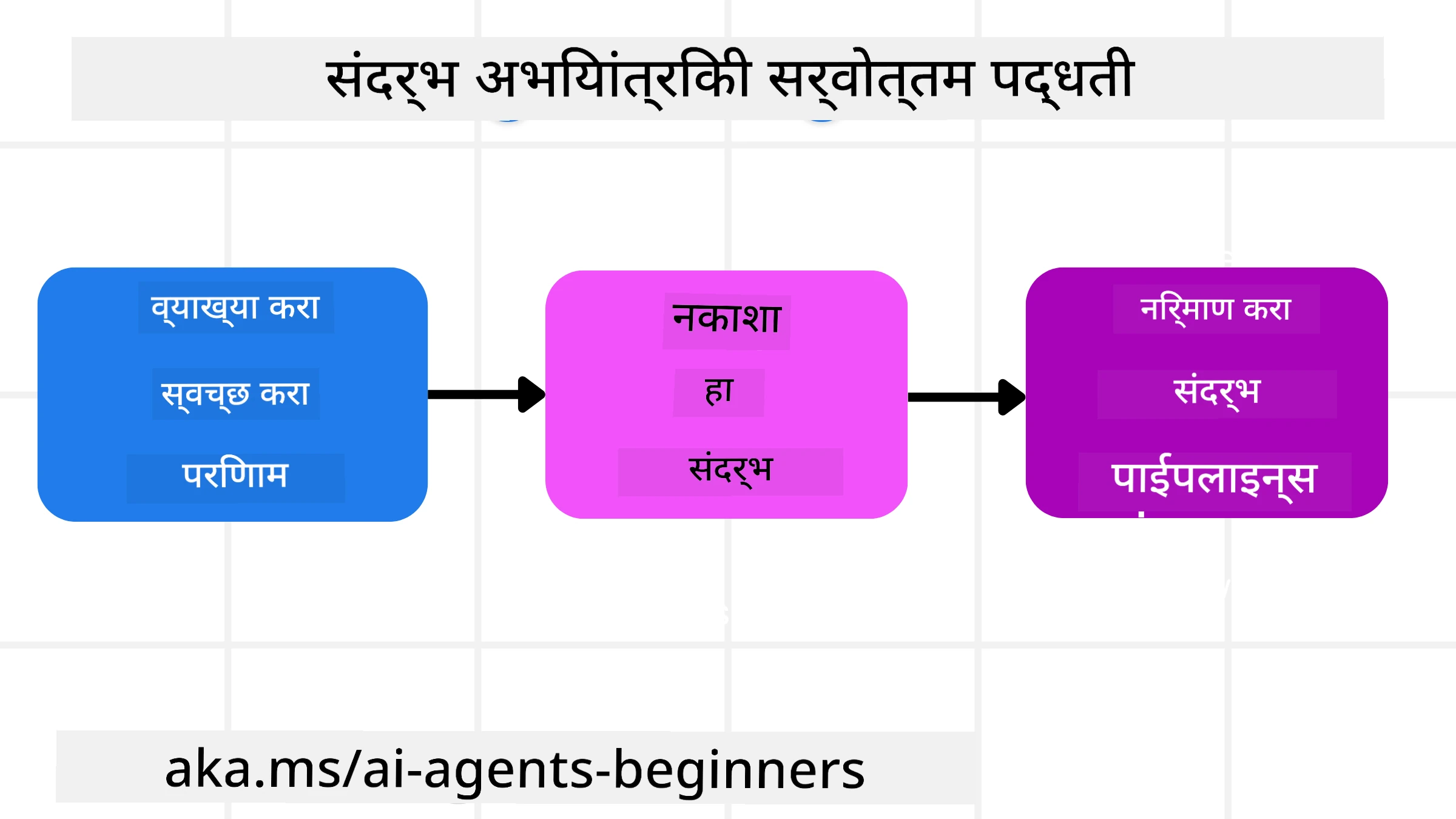
चांगली संदर्भ अभियांत्रिकी चांगल्या नियोजनाने सुरू होते. संदर्भ अभियांत्रिकीची संकल्पना कशी लागू करावी याबाबत विचार सुरू करण्यासाठी येथे एक पद्धत आहे:
- स्पष्ट परिणाम ठरवा – AI एजंट्सना दिलेल्या कामांचे परिणाम स्पष्टपणे ठरवलेले असावे. प्रश्न विचाराः “जेव्हा AI एजंट त्याचे कार्य पूर्ण करेल तेव्हा जग कसे दिसेल?” म्हणजे वापरकर्त्याला AI एजंटशी संवाद केल्यानंतर काय बदल, माहिती किंवा प्रतिसाद मिळावा.
- संदर्भाचा नकाशा तयार करा – AI एजंटचे परिणाम ठरवल्यानंतर, प्रश्न विचाराः “AI एजंटला हा कार्य पूर्ण करण्यासाठी कोणती माहिती हवी आहे?” अशा प्रकारे या माहितीचा संदर्भ कुठे असू शकतो याचा नकाशा तयार करा.
- संदर्भ पाइपलाईन्स तयार करा – माहिती कुठे आहे हे लक्षात आल्यावर, प्रश्न विचाराः “एजंट कशी ही माहिती मिळवेल?” हे अनेक मार्गांनी केले जाऊ शकते, जसे की RAG, MCP सर्व्हर्स व इतर साधने वापरणे.
प्रत्यक्ष रणनीती
नियोजन महत्त्वाचे आहे परंतु जेव्हा माहिती आमच्या एजंटच्या संदर्भ विंडोमध्ये येऊ लागते, तेव्हा ती व्यवस्थापित करण्यासाठी प्रत्यक्षstrategie आवश्यक आहेत:
संदर्भ व्यवस्थापन
काही माहिती संदर्भ विंडोमध्ये आपोआप जोडली जाईल, पण संदर्भ अभियांत्रिकी म्हणजे या माहितीवर सक्रिय नियंत्रण ठेवणे खालील काही रणनीतींनी केले जाते:
-
एजंट स्क्रॅचपॅड
AI एजंटला सत्रादरम्यान चालू काम आणि वापरकर्ता संवादांच्या संदर्भातील महत्त्वाची नोंद ठेवण्याची संधी देते. हे संदर्भ विंडोच्या बाहेर असावे, फाईल किंवा रनटाइम ऑब्जेक्टमध्ये, जे एजंट नंतर हवे असल्यास पुनर्संचयित करू शकतो. -
आठवणी
स्क्रॅचपॅड एका सत्राबाहेरील माहिती व्यवस्थापनासाठी चांगले आहेत. आठवणी एजंटसना अनेक सत्रांमध्ये संबंधित माहिती जतन आणि पुनर्प्राप्त करण्याची क्षमता देतात. यात सारांश, वापरकर्त्याचे प्राधान्यक्रम आणि सुधारणा अभिप्राय समाविष्ट असू शकतात. -
संदर्भ संक्षेपित करणे
संदर्भ विंडो वाढत असल्यास आणि मर्यादेच्या जवळ येत असल्यास, सारांश करणे आणि कापणी सारख्या तंत्रांचा वापर केला जाऊ शकतो. यात केवळ सर्वात संबंधित माहिती ठेवणे किंवा जुनी संदेश काढून टाकणे यांचा समावेश आहे. -
बहु-अजंट प्रणालीं
बहु-अजंट प्रणाली विकसित करणे संदर्भ अभियांत्रिकीचाच एक प्रकार आहे कारण प्रत्येक एजंटची स्वतंत्र संदर्भ विंडो असते. ही माहिती कशी शेअर आणि वेगवेगळ्या एजंट्सना कशी दिली जाईल हे नियोजन करणे आवश्यक आहे. -
सँडबॉक्स पर्यावरण
जर एजंटला काही कोड चालवायचा असेल किंवा मोठ्या प्रमाणात माहिती प्रक्रिया करायची असेल, तर परिणामी टोकन्स खूप लागतात. त्याऐवजी एजंट सँडबॉक्स पर्यावरण वापरू शकतो जे कोड चालवू शकते आणि केवळ निकाल आणि इतर संबंधित माहिती वाचू शकते. -
रनटाईम स्टेट ऑब्जेक्ट्स
हे संदर्भाच्या विशिष्ट भागांमध्ये प्रवेश आवश्यक असलेल्या परिस्थितींसाठी माहिती कंटेनर तयार करून करता येते. क्लिष्ट कार्यासाठी प्रत्येक उपटास्कचे निकाल स्टेप-बाय-स्टेप जतन करण्याची सुविधा मिळते, ज्यामुळे संदर्भ त्या विशिष्ट उपटास्कशीच राहतो.
संदर्भ अभियांत्रिकीचे उदाहरण
समजा तुम्हाला AI एजंटकडे म्हणायचे आहे “पॅरिसला माझ्यासाठी प्रवास बुक करा.”
• फक्त प्रॉम्प्ट अभियांत्रिकी वापरणारा साधा एजंट फक्त म्हणेल: “ठीक आहे, तुम्हाला पॅरिसला कोणत्या दिवशी जायचे आहे?” तो फक्त तुमचा थेट प्रश्न त्या वेळी प्रक्रियात आणेल.
• संदर्भ अभियांत्रिकीच्या रणनीती वापरणारा एजंट खूप अधिक करेल. प्रतिसाद देण्याआधी त्याची प्रणाली कदाचित:
◦ तुमचा कॅलेंडर तपासेल उपलब्ध तारखा शोधण्यासाठी (प्रत्यक्ष डेटा मिळवणे).
◦ मागील प्रवास प्राधान्य पुन्हा आठवेल (दीर्घकालीन आठवणीतून) जसे तुमच्या पसंतीची एअरलाइन्स, बजेट, किंवा थेट फ्लाइट्सची इच्छा.
◦ उपलब्ध साधने ओळखेल फ्लाइट आणि हॉटेल बुकिंगसाठी.
- मग, एक उदाहरण प्रतिसाद असू शकतो: “हायक [तुमचे नाव]! मला दिसते की तुम्ही ऑक्टोबरच्या पहिल्या आठवड्यात मोकळे आहात. मी तुमच्या सामान्य बजेटमध्ये [पसंत एअरलाइन्स] वरून पॅरिससाठी थेट फ्लाइट्स शोधू का?” हा सामर्थ्यशाली, संदर्भ-समजूतदार प्रतिसाद संदर्भ अभियांत्रिकीची ताकद दर्शवतो.
सामान्य संदर्भ त्रुटी
संदर्भ विषबाधा
काय आहे: जेंव्हा LLM कडून तयार झालेल्या चुकीच्या माहिती किंवा चुकीचे संदर्भांमध्ये येतात आणि सतत त्याचा संदर्भ दिला जातो, ज्यामुळे एजंट अशक्य ध्येयांच्या किंवा मूर्खधंदा धोरणांचा पाठपुरावा करतो.
काय करावे: संदर्भ सत्यापन आणि क्वारंटाइन लागू करा. दीर्घकालीन आठवणीत माहिती जोडण्याआधी सत्यापन करा. विषबाधा आढळल्यास, खराब माहिती पसरू नये म्हणून नवीन संदर्भ धागे सुरू करा.
प्रवास बुकिंग उदाहरण: तुमचा एजंट गैरहजर एखाद्या लहान स्थानिक विमानतळावरून दूरच्या आंतरराष्ट्रीय शहरासाठी थेट फ्लाइट असल्याचा भ्रम निर्माण करतो, जे प्रत्यक्षात आंतरराष्ट्रीय फ्लाइट्स देत नाही. ही अस्तित्त्वात नसलेली माहिती संदर्भात साठवली जाते. नंतर जेव्हा तुम्ही बुकिंगसाठी विचारता, तो नेहमी त्या अशक्य मार्गासाठी तिकिटे शोधण्याचा प्रयत्न करतो, सतत चुका होते.
उपाय: फ्लाइट अस्तित्त्व आणि मार्गांची सत्यता त्वरित API द्वारा सत्यापित करा पूर्वीच ही फ्लाइट माहिती एजंटच्या कार्य संदर्भात जोडल्यानंतर. सत्यापन अयशस्वी झाल्यास, चुकीची माहिती “क्वारंटाइन” केली जाते आणि पुढे वापरली जात नाही.
संदर्भ विचलन
काय आहे: संदर्भ खूप मोठा झाल्यानंतर मॉडेल प्रशिक्षणादरम्यान शिकलेल्या गोष्टी ऐवजी जमा संवादावर खूप लक्ष केंद्रित करते, ज्यामुळे पुनरावृत्ती किंवा उपयुक्त नसलेल्या कृती होतात. संदर्भ विंडो पूर्ण होण्याआधी देखील चुका होऊ शकतात.
काय करावे: संदर्भ सारांश वापरून. जमा माहिती वेळोवेळी संक्षेप करा, महत्त्वाच्या तपशील ठेवा आणि अनावश्यक इतिहास काढून टाका. यामुळे लक्ष पुनः सेट होते.
प्रवास बुकिंग उदाहरण: तुम्ही बराच वेळ स्वप्न पडलेले प्रवासस्थाने आणि दोन वर्षांपूर्वीचा तुमचा बॅकपॅकिंग ट्रिप सविस्तर चर्चा केली आहे. जेव्हा तुम्ही अखेरीस विचारता, “परवाच्या महिन्यासाठी स्वस्त फ्लाइट शोधा,” एजंट जुन्या आणि अनावश्यक तपशीलांत गुंततो आणि तुम्हाला बॅकपॅकिंग सामान किंवा मागील प्रवास याबाबत प्रश्न विचारत राहतो, तुमच्या आधीच्या विनंतीचा दुर्लक्ष करतो.
उपाय: काही वेळा किंवा संदर्भ मोठा झाल्यावर एजंटला सर्वात अलीकडील आणि संबंधित भागांचा सारांश तयार करावा – तुमच्या वर्तमान प्रवासाच्या तारखा आणि ठिकाणावर लक्ष केंद्रित करून – आणि त्या संक्षिप्त सारांशाचा पुढील LLM कॉलसाठी वापर करा, ऐतिहासिक महत्वाचे नसलेले संभाषण वगळा.
संदर्भ गोंधळ
काय आहे: अनावश्यक संदर्भ, विशेषतः खूप जास्त उपलब्ध साधनांमुळे, मॉडेल चुकीचे प्रतिसाद देऊ शकते किंवा उपयुक्त नसलेली साधने कॉल करू शकते. लहान मॉडेल्स यासाठी अधिक संवेदनशील असतात.
काय करावे: RAG तंत्रज्ञान वापरून साधनांची लोडआउट व्यवस्थापन करा. साधनांचे वर्णन व्हेक्टर डेटाबेसमध्ये साठवा आणि विशिष्ट कामासाठी फक्त सर्वात संबंधित साधने निवडा. संशोधन दर्शवते की साधनांची संख्या ३० पेक्षा कमी ठेवावी.
प्रवास बुकिंग उदाहरण: एजंटकडे डझनभर साधने उपलब्ध आहेत: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations इत्यादी. तुम्ही विचारता, “पॅरिसमध्ये प्रवास करण्याचा सर्वोत्तम मार्ग काय?” साधनांची संख्या एवढी जास्त असल्यामुळे, एजंट गोंधळून पडतो आणि book_flight किंवा rent_car सारखी साधने कॉल करण्याचा प्रयत्न करतो, जरी तुम्हाला सार्वजनिक वाहतूक हवी आहे, कारण साधनांच्या वर्णनांमध्ये ओवरलॅप किंवा योग्य साधन ओळखण्यात अपयश येते.
उपाय: साधनांच्या वर्णनांवर RAG वापरा. जेव्हा तुम्ही पॅरिसमध्ये प्रवासाबाबत विचारता, तेव्हा प्रणाली फक्त संबंधित साधने जसे की rent_car किंवा public_transport_info ओळखून LLM साठी लक्ष केंद्रित केलेली “लोडआउट” प्रदान करते.
संदर्भ संघर्ष
काय आहे: संदर्भात विरोधाभासी माहिती असणे, ज्यामुळे तर्कसंगतता विसंगत होते किंवा अंतिम प्रतिसाद खालावतो. ही समस्या तब्बल तऱ्हेने माहिती टप्प्याटप्प्याने मिळाल्यामुळे होते, ज्यात जुनी चुकीची गृहीतके संदर्भात राहतात.
काय करावे: संदर्भ छाटणी आणि ऑफलोडिंग वापरा. छाटणी म्हणजे नवीन माहिती आल्यावर जुनी किंवा विरोधाभासी माहिती काढून टाकणे. ऑफलोडिंग म्हणजे मॉडेलला स्वतंत्र “स्क्रॅचपॅड” कार्यक्षेत्र देणे ज्यात ते माहिती प्रक्रियेत करू शकते, मुख्य संदर्भात गोंधळ टाळता येतो.
प्रवास बुकिंग उदाहरण: आधी तुम्ही एजंटला सांगता, “मला इकॉनॉमी क्लासमध्ये प्रवास हवा आहे.” नंतर संवादात बदल करता: “खरं तर, या प्रवासासाठी बिझनेस क्लास पाहूया.” जर दोन्ही सूचना संदर्भात राहिल्या, तर एजंट गोंधळून पडू शकतो की कोणत्या प्राधान्याला प्राधान्य द्यावे.
उपाय: संदर्भ छाटणी लागू करा. जेव्हा नवीन सूचना जुन्या सूचनेशी विरोधाभासी असते, तेव्हा जुनी सूचना काढून टाका किंवा संदर्भात स्पष्टपणे ओव्हरराईड करा. किंवा एजंट विरोधाभासी प्राधान्ये समजून घेण्यासाठी स्क्रॅचपॅड वापरू शकतो, जेणेकरून फक्त अंतिम, सुसंगत सूचना त्याच्या कार्यांचे मार्गदर्शन करतील.
संदर्भ अभियांत्रिकीबाबत अधिक प्रश्न आहेत?
Microsoft Foundry Discord मध्ये सहभागी व्हा, अन्य शिकणाऱ्यांशी भेटा, ऑफिस आवर्समध्ये सहभागी व्हा आणि तुमचे AI एजंट्सचे प्रश्न विचारावेत.
सूचना: हा दस्तऐवज AI अनुवाद सेवा Co-op Translator वापरून अनुवादित केला आहे. आम्ही अचूकतेचा प्रयत्न करतो, तरी कृपया लक्षात घ्या की स्वयंचलित अनुवादांमध्ये चुका किंवा विसंगती असू शकतात. मूळ दस्तऐवज आपल्या स्थानिक भाषेत अधिकृत स्रोत म्हणून मानले जाणे आवश्यक आहे. महत्त्वाच्या माहितीसाठी व्यावसायिक मानवी अनुवाद करण्याचा सल्ला दिला जातो. या अनुवादाच्या वापरामुळे उद्भवलेल्या कोणत्याही गैरसमज किंवा चुकीच्या अर्थापासून आम्ही जबाबदार नाही.