ai-agents-for-beginners

(ဤသင်ခန်းစာ၏ ဗီဒီယိုကို ကြည့်ရန် အပေါ်ဖော်ပြပါ ပုံကို နှိပ်ပါ)
AI အေးဂျင့်များတွင်း မက်တာကွတ်နီရှင်း
နိဒါန်း
AI အေးဂျင့်များတွင် မက်တာကွတ်နီရှင်းအကြောင်း သင်ခန်းစာသို့ ရောက်ရှိကြိုဆိုပါတယ်! ဤဘာသာအပိုင်းသည် AI အေးဂျင့်များသည် မိမိတို့စဉ်းစားနေသော လုပ်ငန်းစဉ်များကို မည်သို့ စဉ်းစားတတ်ကြောင်း စိတ်ဝင်စားသော စသစ်လည်တန်းသူများအတွက် တည်ဆောက်ထားသည်။ ဤသင်ခန်းစာပြီးဆုံးသောအချိန်တွင် သင့်အား အဓိကအယူအဆများကို နားလည်ပြီး မက်တာကွတ်နီရှင်းကို AI အေးဂျင့် ဒီဇိုင်းတွင် အသုံးပြုနိုင်မည့် လက်တွေ့ ဥပမာများဖြင့် озတ်ဖြတ်နိုင်ပါလိမ့်မည်။
သင်ယူလိုသည့် ရည်မှန်းချက်များ
ဤသင်ခန်းစာအပြီးတွင် သင်အောက်ပါအရာများကို လုပ်ဆောင်နိုင်မည်ဖြစ်သည်-
- အေးဂျင့်သတ်မှတ်ချက်များတွင် သဘောထား အလှည့်ကျသတ်မှတ်ချက်များ၏ အဓိပ္ပါယ်များကို နားလည်ခြင်း။
- ပြင်ဆင်ခြင်းကို ကူညီပေးသည့် စီမံခန့်ခွဲခြင်းနှင့် အကဲဖြတ်နည်းများ အသုံးပြုခြင်း။
- လုပ်ငန်းများ အောင်မြင်အောင် ကုဒ်ကို မူကြိုက်လှုပ်ရှားနိုင်သော ကိုယ်ပိုင်အေးဂျင့်များ ဖန်တီးခြင်း။
မက်တာကွတ်နီရှင်း အကြောင်း နိဒါန်း
မက်တာကွတ်နီရှင်း သည် ကိုယ့်စဉ်းစားမှုကို စဉ်းစားခြင်းနှင့် ဆိုင်သော အဆင့်မြင့် ဉာဏ်ပညာလုပ်ငန်းစဉ်များကို ဆိုလိုသည်။ AI အေးဂျင့်များအတွက် ဆိုရင် မိမိတို့လုပ်ဆောင်ချက်များကို ကိုယ်တိုင်နားလည်ခြင်းနှင့် ယခင်အတွေ့အကြုံများအပေါ် အခြေခံ၍ ပြန်လည်သုံးသပ်ချက် ပြုလုပ်နိုင်စွမ်း ရှိသည်။ “စဉ်းစားခြင်းကို စဉ်းစားခြင်း” ဟူသော မက်တာကွတ်နီရှင်းသည် အေးဂျင့် ရှေ့ဆောင် AI စနစ်များ ဖန်တီးရာတွင် အရေးပါသော အယူအဆဖြစ်သည်။ ၎င်းတွင် AI စနစ်များသည် မိမိတို့၏ အတွင်းစိတ်လုပ်ငန်းစဉ်များကို နားလည်နိုင်ခြင်း၊ ကြီးကြပ်မှု၊ တိုင်ပင်ရှုပြောင်းလဲမှုများ ပြုလုပ်နိုင်ခြင်းတို့ပါဝင်သည်။ အတူတူ ကမ္ဘာကို သတိထားကြည့်သလို သို့မဟုတ် ပြproblem ကို ကြည့်စဉ်းစားသလို ျဖစ္ပါတယ်။ ၎င်းကိုယ်တိုင်နားလည်မှုသည် AI စနစ်များအား ဆုံးဖြတ်ချက် ပိုမိုကောင်းမွန်စေပြီး အမှားများကို ရှာဖွေပြင်ဆင်နိုင်ရန် အခွင့်အလမ်း ပေးသည်၊ စွမ်းဆောင်ရည် တိုးတက်မှုကို လောလောဆယ်၊ နောက်ဆက်တွဲ ဖြစ်ပါသည်- ထပ်မံပြီး Turing စမ်းသပ်မှုနှင့် AI မိတ်ဆက်မှု တိုက်ပွဲအပေါ် ဆက်သွယ်နေသည်။
အေးဂျင့် AI စနစ်များအတွက် မက်တာကွတ်နီရှင်းသည် အောက်ပါ စိန်ခေါ်မှုများကို ဖြေရှင်းရာတွင် ကူညီပေးနိုင်ပါသည်-
- ပွင့်လင်းချက်: AI စနစ်များ၏ သဘောထားများနှင့် ဆုံးဖြတ်ချက်များကို ရှင်းပြနိုင်ရန် ဖြည့်ဆည်းပေးခြင်း။
- သဘောထား: AI စနစ်များကို သတင်းအချက်အလက်များကို ပေါင်းစည်း၍ သင့်တော်သော ဆုံးဖြတ်ချက်များ ပြုလုပ်နိုင်စေရန် တိုးတက်စေခြင်း။
- ချိန်ညှိမှု: AI စနစ်များအား ပတ်ဝန်းကျင် အသစ်များနှင့် အခြေအနေ ပြောင်းလဲမှုများကို ချိန်ညှိနိုင်စေရန် ဖွင့်လှစ်ခြင်း။
- မွမ်းမံခြင်း: AI စနစ်များအနေဖြင့် မျက်မှောက်ရှိဒေတာများကို မှန်ကန်တိကျစွာ ဖော်ထုတ်၍ ဘာသာပြန်နိုင်မှု တိုးတက်စေရန်။
မက်တာကွတ်နီရှင်း ဆိုတာ ဘာလဲ?
မက်တာကွတ်နီရှင်း၊ “စဉ်းစားခြင်းကို စဉ်းစားခြင်း” ဆိုသည်မှာ ကိုယ့်စဉ်းစားမှုလုပ်ငန်းစဉ်များကို ကိုယ်တိုင် နားလည်နိုင်ခြင်းနှင့် ကိုယ်တိုင် ထိန်းချုပ်နိုင်ခြင်း ပါဝင်သည့် အဆင့်မြင့် ဉာဏ်ပညာလုပ်ငန်းစဉ်တစ်ခုဖြစ်သည်။ AI လောကတွင် မက်တာကွတ်နီရှင်းသည် အေးဂျင့်များအား မိမိတို့ စည်းမျဉ်းနည်းလမ်းများနှင့် လုပ်ဆောင်ချက်များကို ပြန်လည်သုံးသပ်ပြောင်းလဲရန် အင်အားပေးသည်၊ ၎င်းသည် ပြproblem လျှောက်လွှာနှင့် ဆုံးဖြတ်ချက်ပြုလုပ်မှု စွမ်းဆောင်ရည်တိုးတက်စေသည်။ မက်တာကွတ်နီရှင်းကို နားလည်ခြင်းဖြင့် လူတို့ထက် ပိုမိုတိုးတက်တဲ့၊ ပိုမိုချိန်ညှိနိုင်ပြီး ထိရောက်သော AI အေးဂျင့်များကို ဒီဇိုင်းဆွဲနိုင်ပါသည်။ အမှန်တကယ် မက်တာကွတ်နီရှင်းတွင် AI သည် မိမိ၏ သဘောထားကို တိတိကျကျ သဘောထားပြုသည့် အခြေအနေ ရှိပါသည်။
ဥပမာ- “ငွေသက်သာသော လေယာဉ်လက်မှတ်များကို ဦးစားပေးခဲ့ပါတယ်… ကျွန်ုပ်သည် တိုက်ရိုက်လေယာဉ်လက်မှတ်များကို လက်လွတ်လိုက်ရေး ဖြစ်နိုင်ပေမယ့် ထပ်စစ်ဆေးမယ်။”
တိကျသော လမ်းကြောင်းကြောင့် အဘယ်ကြောင့် ရွေးချယ်ခဲ့သည်ကို မှတ်သားခြင်း။
- ယခင်တစ်ကြိမ် အသုံးပြုသူ စိတ်ကြိုက် စနစ်အပေါ် အလွန်အမင်း တင်ထားခဲ့တယ့်အတွက် အမှားများ ဖြစ်ခဲ့ပြီး သဘောထားပြောင်းလဲချက်ကို နောက်ဆုံး အကြံပြုချက်မဟုတ်ဘဲ ပြင်ဆင်ခြင်း။
- အိမ်မက်ပုံစံတူ အခြေအနေများကို သိရှိခြင်း၊ “အသုံးပြုသူ ‘အလွန်အဆူရှုပ်’ ဟု ဆိုသည့်အခါ” အရမ်းလူကြိုက်များမှုအလိုက် ‘ထိပ်တန်းဆွဲဆောင်မှုများ’ ရွေးချယ်မှု နည်းလမ်းသည် မမှန်ကန်ကြောင်း ပြန်လည်ဆန့်ကျင်စဉ်းစားရမည်။
AI အေးဂျင့်များအတွက် မက်တာကွတ်နီရှင်း၏ အရေးပါမှု
မက်တာကွတ်နီရှင်းသည် AI အေးဂျင့် ဒီဇိုင်းတွင် အဓိကပါဝင်ပြီး အကြောင်းအရာအနည်းငယ်ရှိပါသည်။
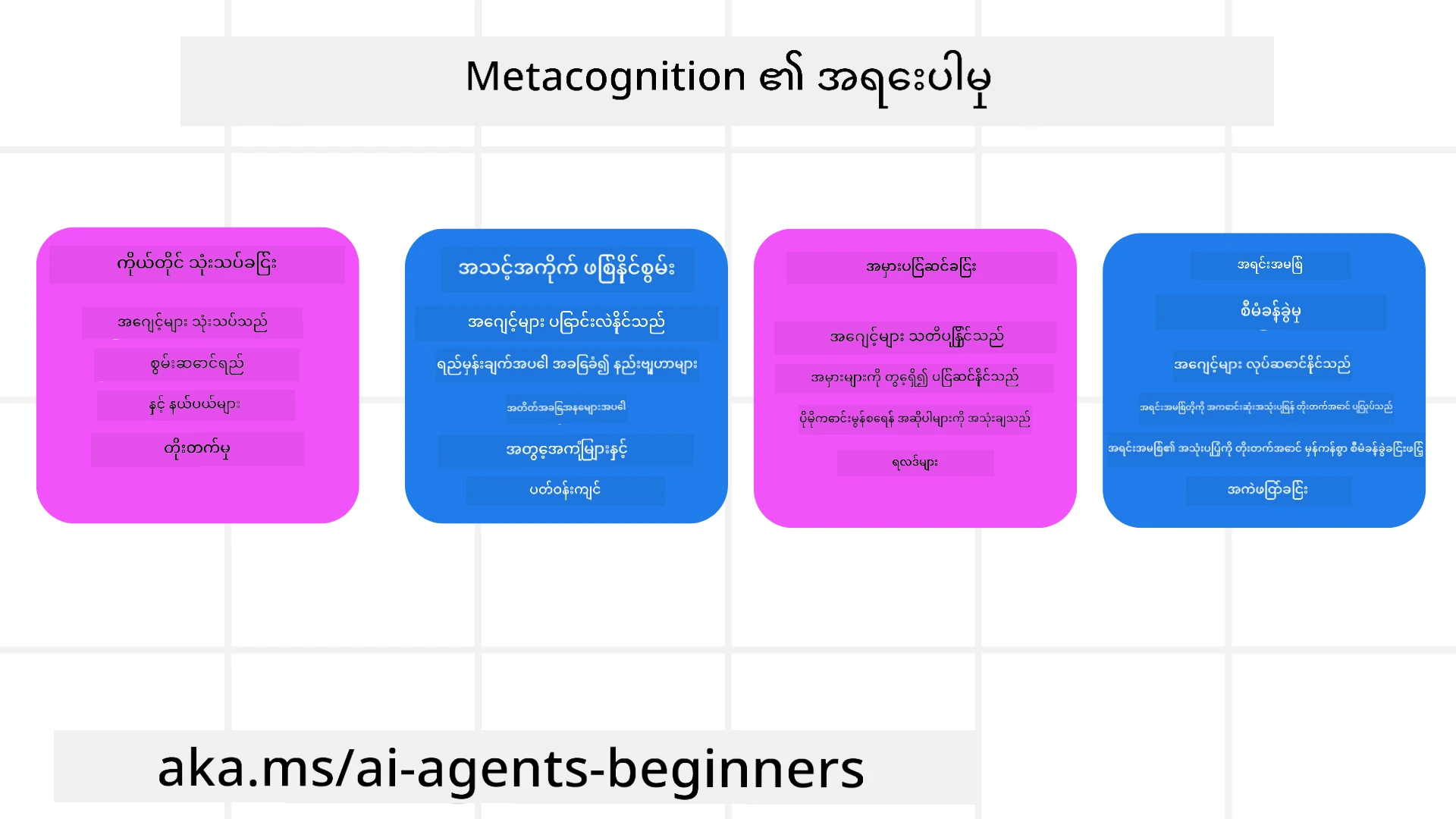
- ကိုယ်တိုင် သုံးသပ်ခြင်း: အေးဂျင့်များသည် မိမိ၏ လုပ်ဆောင်မှုကို သုံးသပ်ကာ တိုးတက်ရန်နေရာများ ရှာဖွေပါသည်။
- အချိန်ညှိနိုင်မှု: အေးဂျင့်များသည် ယခင်အတွေ့အကြုံများနှင့် ပြောင်းလဲနေသော ပတ်ဝန်းကျင်များအပေါ် မှီငြမ်း ပြောင်းလဲနိုင်ပါသည်။
- အမှား ပြင်ဆင်မှု: အေးဂျင့်များသည် အမှားများကို ကိုယ်တိုင် ရှာဖွေပြင်ဆင်နိုင်ကာ ပိုမိုမှန်ကန်သော ရလဒ်များ ရရှိစေပါသည်။
- အရင်းအမြစ် စီမံခန့်ခွဲမှု: အေးဂျင့်များသည် အရင်းအမြစ်များ (အချိန်နှင့် စက်ရုပ်အား) ကို စိစစ်ကာ အကောင်းဆုံး အသုံးပြုနိုင်သည်။
AI အေးဂျင့်၏ အစိတ်အပိုင်းများ
မက်တာကွတ်နီရှင်းလုပ်ငန်းစဉ်များသို့ ဆွဲဆောင်မှု ခေါက်ကာရောက်ရှိရန် မတိုင်မီ AI အေးဂျင့်၏ အခြေခံအစိတ်အပိုင်းများ ကို နားလည်ဖို့ လိုအပ်သည်။ AI အေးဂျင့်တစ်ခု သာမာန်အားဖြင့် ပါဝင်သည်-
- Persona: အသုံးပြုသူများနှင့် အပြန်အလှန် ဆက်ဆံသည့် ပုဂ္ဂိုလ်ရေးနှင့် ဖော်ပြချက်များ။
- Tools: အေးဂျင့်က ပြုလုပ်နိုင်သည့် အရည်အချင်းများနှင့် လုပ်ဆောင်ချက်များ။
- Skills: အေးဂျင့် ရှိသည့် ပညာနှင့် ကျွမ်းကျင်မှု။
ဤအစိတ်အပိုင်းများသည် အထူးပြုလုပ်ငန်းများ ပြုလုပ်နိုင်စေရန် “ကျွမ်းကျင်မှုယူနစ်” အဖြစ် ပေါင်းစည်း၍ လုပ်ဆောင်သည်။
ဥပမာ:
ခရီးသွား အေးဂျင့်တစ်ခုကို စဉ်းစားပါ၊ ၎င်းက သင့်အား ခရီးသွားအစီအစဉ် ဖန်တီးပေးပြီး တကယ် real-time ဒေတာများနှင့် ယခင် ग्राहक ခရီးသွား အတွေ့အကြုံ အပေါ် အသက်သွင်း ပြင်ဆင် ပြုလုပ်နိုင်သည်။
ဥပမာ- ခရီးသွား အေးဂျင့် ဝန်ဆောင်မှုတွင် မက်တာကွတ်နီရှင်း
သင် AI အားဖြင့် စွဲဆောင်ထားသော ခရီးသွား အေးဂျင့် ဝန်ဆောင်မှုကို ဒီဇိုင်းဆွဲနေသော အခါ၊ “Travel Agent” ဟုအမည်ပေးပါ။ ၎င်းသည် အသုံးပြုသူများအား ခရီးအစီအစဉ် စီမံကိန်းရန် ကူညီသည်။ မက်တာကွတ်နီရှင်း ထည့်သွင်းရန်၊ Travel Agent သည် ကိုယ့်အရေးကိုယ်တာကို နားလည်ကာ ယခင်အတွေ့အကြုံများအပေါ် အခြေခံပြန်လည် ပြင်ဆင်ချက်များ ပြုလုပ်နိုင်ရန် လိုအပ်သည်။ ၎င်းဤနေရာတွင် မက်တာကွတ်နီရှင်းသည် အရေးပါသည်-
လက်ရှိ အလုပ်တာဝန်
လက်ရှိအလုပ်သည် အသုံးပြုသူတစ်ဦးအား ပဲရစ်သို့ ခရီးစဉ် စီစဉ်ကူညီရန်ဖြစ်သည်။
အလုပ်ပြီးစီးရန် အဆင့်များ
- အသုံးပြုသူ စိတ်ကြိုက်မှု ရှာဖွေခြင်း: ခရီးသွားနေ့ရက်၊ ဘဏ္ဍာရေး၊ စိတ်ဝင်စားမှုများ (ဥပမာ- ပြတိုက်များ၊ အစားအစာ၊ စျေးဝယ်ခြင်း) နှင့် အထူးလိုအပ်ချက်များကို မေးမြန်းပါ။
- သတင်းအချက်အလက် ရယူခြင်း: အသုံးပြုသူ စိတ်ကြိုက်မှုနှင့် ကိုက်ညီသော လေယာဉ်လက်မှတ်ရွေးချယ်မှုများ၊ နေအိမ်၊ ဆွဲဆောင်မှုများနှင့် ဘားများကို ရှာဖွေလေ့လာပါ။
- အကြံပြုချက် များ ဖန်တီးခြင်း: လေယာဉ်အချက်အလက်များ၊ ဟိုတယ်ဘွတ်ကင်များနှင့် လုပ်ဆောင်ရန် အကြံပြုချက်များ ပါဝင်သည့် ပုဂ္ဂိုလ်ရေး ခရီးစဉ်စာရင်း တင်ပြပါ။
- တုံ့ပြန်ချက် အပေါ် အခြေခံ ပြင်ဆင်ခြင်း: အသုံးပြုသူ၏ တုံ့ပြန်ချက်ကို မေးမြန်းပြီး လိုအပ်သလို ပြင်ဆင်မှုများ ပြုလုပ်ပါ။
လိုအပ်သော အရင်းအမြစ်များ
- လေယာဉ်လက်မှတ်နှင့် ဟိုတယ်ဘွတ်ကင် ဒေတာဘေ့စ်များသို့ ဝင်ရောက်နိုင်မှု။
- ပဲရစ် ဆွဲဆောင်မှုများနှင့် ဘားများအကြောင်း သိရှိမှု။
- ယခင် ဆက်ဆံမှုများမှ အသုံးပြုသူ တုံ့ပြန်ချက် ဒေတာများ။
အတွေ့အကြုံနှင့် ကိုယ်တိုင် သုံးသပ်ခြင်း
Travel Agent သည် မက်တာကွတ်နီရှင်းကို အသုံးပြုကာ လုပ်ဆောင်မှုကို သုံးသပ်ပြီး ယခင် အတွေ့အကြုံတွေမှ သင်ယူသည်။ ဥပမာ-
- အသုံးပြုသူတုံ့ပြန်ချက်ကို စိစစ်ခြင်း: Travel Agent သည် အသုံးပြုသူတုံ့ပြန်ချက်ကို ပြန်လည်သုံးသပ်ကာ အကြံပြုချက်များကောင်းများနှင့် မကောင်းများရရှိသည်ကို ခွဲခြားသည်။ ၎င်းအတိုင်း နောက်တစ်ကြိမ် အကြံပြုချက်များကို ပြောင်းလဲသည်။
- ချိန်ညှိနိုင်မှု: အသုံးပြုသူက ရှုပ်ထွေးပြီးနေတဲ့နေရာများကို မကြိုက်ဘူးဆိုခဲ့ရင် အချိန်ထိပ်ဆုံးနှင့် လူအများကြည့်ရှုသောနေရာများကို ခွဲထုတ်ပေးသည်။
- အမှား ပြင်ဆင်ခြင်း: ယခင်မှာ တစ်ခုသော ဟိုတယ် အိတ်ဆောင်မှု အမှား ဖြစ်ခဲ့ရင်၊ အဲဒီဟိုတယ် သက်တမ်းအတည်ပြုမှုကို ပိုမိုသေချာစွာ စစ်ဆေးရန် သင်ယူသည်။
လက်တွေ့ Developer ဥပမာ
မက်တာကွတ်နီရှင်း ထည့်သွင်းထားသော Travel Agent ကုဒ် တစ်ခု၏ ရိုးရှင်းသပ်ရပ် ဥပမာ-
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
# ဦးစားပေးမှုများအပေါ်အခြေခံပြီး လေကြောင်းလက်မှတ်၊ ဟိုတယ်များနှင့် ဆွဲဆောင်မှုများကို ရှာဖွေပါ
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
# တုံ့ပြန်ချက်များကို လေ့လာပြီး အနာဂတ်အကြံပြုချက်များကို ချိန်ညှိပါ
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# အသုံးပြုမှု နမူနာ
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
မက်တာကွတ်နီရှင်း မည်သို့ အရေးကြီးသလဲ
- ကိုယ်တိုင် သုံးသပ်ခြင်း: အေးဂျင့်များသည် မိမိ၏ လုပ်ဆောင်မှုကို လေ့လာရင်း တိုးတက်စရာ နေရာများ ရှာသည်။
- ချိန်ညှိနိုင်မှု: ပြင်ဆင်ချက်များနှင့် အခြေအနေ ပြောင်းလဲမှုအပေါ် အခြေခံ၍ မဟာဗျူဟာ ပြောင်းလဲသည်။
- အမှား ပြင်ဆင်ခြင်း: အေးဂျင့်များသည် အမှားများကို ကိုယ်တိုင် ရှာဖွေ ပြင်ဆင်နိုင်သည်။
- အရင်းအမြစ် စီမံခန့်ခွဲမှု: အချိန်နှင့် သတ်မွတ်ချက်များကို စီမံချက်ချခြင်းဖြင့် အရင်းအမြစ် အသုံးပြုမှု မြှင့်တင်သည်။
မက်တာကွတ်နီရှင်း ပေါင်းစပ်ခြင်းအားဖြင့် Travel Agent သည် ပိုမိုပုဂ္ဂိုလ်ရေးထောက်ခံချက်နှင့် မှန်ကန်သော ခရီးသွားအကြံပြုချက်များ ပေးနိုင်ပြီး အသုံးပြုသူ အတွေ့အကြုံ တိုးတက်စေပါသည်။
2. အေးဂျင့်များတွင် စီမံကိန်းရေးဆွဲခြင်း
စီမံကိန်းရေးဆွဲခြင်းသည် AI အေးဂျင့် လုပ်ဆောင်ချက်များ၏ အရေးပါသော အစိတ်အပိုင်းတစ်ခုဖြစ်သည်။ ၎င်းသည် ရည်မှန်းချက်တစ်ခုရရှိရန်လိုအပ်သော အဆင့်များကို ရေးသားခြင်းဖြစ်ပြီး လက်ရှိအခြေအနေ၊ အရင်းအမြစ်များနှင့် ဖြစ်နိုင်သော အတားအဆီးများကို တွက်ချက်သည်။
စီမံကိန်းရေးဆွဲမှု အစိတ်အပိုင်းများ
- လက်ရှိ အလုပ်တာဝန်: အလုပ်တာဝန်ကို ထင်ရှားစွာ သတ်မှတ်ပါ။
- အလုပ်ပြီးစီးရန် အဆင့်များ: အလုပ်ကို စီမံမှုတစ်ခုစီ ခွဲခြားပါ။
- လိုအပ်သော အရင်းအမြစ်များ: လိုအပ်သော အရင်းအမြစ်များ သတ်မှတ်ပါ။
- အတွေ့အကြုံ: ယခင်အတွေ့အကြုံများကို အသုံးပြုပါ။
ဥပမာ:
အောက်တွင် Travel Agent သည် အသုံးပြုသူတစ်ဦးအား ထိရောက်စွာ ခရီးစဉ် စီမံကိန်းရေးဆွဲရာတွင် လိုအပ်သော အဆင့်များကို ဖော်ပြသည်-
Travel Agent အတွက် အဆင့်များ
- အသုံးပြုသူ စိတ်ကြိုက်မှု ရှာဖွေခြင်း
- အသုံးပြုသူထံမှ ခရီးသွားရက်များ၊ ဘဏ္ဍာရေး၊ စိတ်ဝင်စားမှုများနှင့် အထူးလိုအပ်ချက်များကို မေးမြန်းပါ။
- ဥပမာများ- “ခရီးသွားရက်များ ဘယ်တော့လဲ?” “ဘဏ္ဍာရေးအကန့်အသတ် ဘယ်လောက်လဲ?” “ခရီးသွားစဉ် ဘာလုပ်နေချင်လဲ?”
- သတင်းအချက်အလက် ရယူခြင်း
- အသုံးပြုသူ စိတ်ကြိုက်မှုအရ ခရီးသွားရွေးချယ်မှုများကို ရှာဖွေရန် စတင်ပါ။
- လေယာဉ်မှုဖြစ်စဉ်: အသုံးပြုသူ ဘဏ္ဍာရေးနှင့် ခရီးသွားရက်ဖြစ်စဉ်အတွင်း ရနိုင်သော လေယာဉ်များကို ရှာပါ။
- နေရာအဆင်ပြေမှု: အသုံးပြုသူ တက်ကြွသော နေရာ၊ စျေးနှုန်းနှင့် အပန်းဖြေရေး စမတ်ရ_LOCATIONတွက်ရန် ဟိုတယ်များ မှဘာသာရပ်နိုင်သည်။
- ဆွဲဆောင်မှုများနှင့် စားသောက်ဆိုင်များ: အသုံးပြုသူစိတ်ဝင်စားမှုအရ လူကြိုက်များသော ဆွဲဆောင်မှုများ အသုံးဝင်ရာစားသောက်ဆိုင်များ ရှာပါ။
- အကြံပြုချက်များ ဖန်တီးခြင်း
- ရရှိသော သတင်းအချက်အလက်များကို ပုဂ္ဂိုလ်ရေး ခရီးစီစဉ်ဘာသာရပ်ဖြင့် စုစည်းပါ။
- အသုံးပြုသူ စိတ်ကြိုက်မှုအရ လေယာဉ်ရွေးစရာများ၊ ဟိုတယ်ဘွတ်ကင်များ၊ တင်ပြသင့်သော လုပ်ဆောင်ရမည့် အကြံပြုချက်များ ပါဝင်စေပါ။
- အသုံးပြုသူထံ ခရီးစဉ် စာရင်း တင်ပြခြင်း
- တင်ပြချက်များကို အသုံးပြုသူ သုံးသပ်ရန် စတင်ပါ။
- ဥပမာ- “ဒီမှာ ပဲရစ်ခရီးအတိုင်စားစာရင်းဖြစ်ပါတယ်။ လေယာဉ်လက်မှတ်၊ ဟိုတယ်ဘွတ်ကင်နှင့် ညွှန်ကြားချက်များ ပါဝင်ပါတယ်။ သင့်ထင်မြင်ချက်ကို ပြောပြပါ။”
- တုံ့ပြန်ချက် စုဆောင်းခြင်း
- ရှင်းပြချက်အပေါ် အသုံးပြုသူဆီက တုံ့ပြန်မှု ကို မေးမြန်းပါ။
- ဥပမာ- “လေယာဉ်ရွေးချယ်မှုကို သဘောကျပါသလား?” “ဟိုတယ် သင့်လိုအပ်ချက်နဲ့ ကိုက်ညီပါသလား?” “ထည့်ချင်သော လုပ်ဆောင်မှုများ ရှိပါသလား?”
- တုံ့ပြန်ချက်အပေါ် အခြေခံ ပြင်ဆင်ခြင်း
- အသုံးပြုသူ၏ တုံ့ပြန်ချက်နှင့် ကိုက်ညီစေရန် ခရီးစဉ်စာရင်းကို ပြင်ဆင်ပါ။
- လေယာဉ်, နေအိမ်, လုပ်ဆောင်မှု အကြံပြုချက်များကို ပြင်ဆင်ပါ။
- နောက်ဆုံးအတည်ပြုချက်
- ပြင်ဆင်ပြီးစာရင်းကို အသုံးပြုသူထံ သတင်းပို့၍ နောက်ဆုံးအတည်ပြုမှု ရယူပါ။
- ဥပမာ-“သင့်တုံ့ပြန်ချက်အရ ပြင်ဆင်ပြီးပါပြီ။ ဒီစာရင်းကို ကြည့်ပြီး အပြီးသတ်ဖြေကြားပါ။”
- ဘွတ်ကင် နှင့် အတည်ပြုမှု ပေးပို့ခြင်း
- အသုံးပြုသူ အတည်ပြုချိန်တွင် လေယာဉ်၊ ဟိုတယ် နေရာများ ဘွတ်ကင်လုပ်ခြင်းနှင့် ကြိုတင်အစီအစဉ် လုပ်ဆောင်မှုများ ပြုလုပ်ပါ။
- အတည်ပြုချက်အချက်အလက်ကို အသုံးပြုသူထံ ပို့ပါ။
- ဆက်လက် ကူညီပံ့ပိုးခြင်း
- ခရီးသွားမှု အတွင်း ပြောင်းလဲဆီးပိတ်မှုများနှင့် အပိုလိုအပ်ချက်များ အတွက် ဆက်လက် ကူညီပေးရန် ရှိပါက ပြင်ဆင်ပေးပါ။
- ဥပမာ- “ခရီးအတွင်းနောက်ထပ် ကူညီစရာ ရှိပါက ဘယ်အချိန်မဆို ဆက်သွယ်နိုင်ပါတယ်!”
ဥပမာ ဆက်ဆံမှု
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# booing တောင်းဆိုမှုအတွင်း အသုံးပြုမှုဥပမာ
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
3. ပြင်ဆင်မှု RAG စနစ်
ပထမဦးဆုံး RAG Tool နှင့် Pre-emptive Context Load ၏ ကွာခြားချက်ကို နားလည်ကြပါစို့
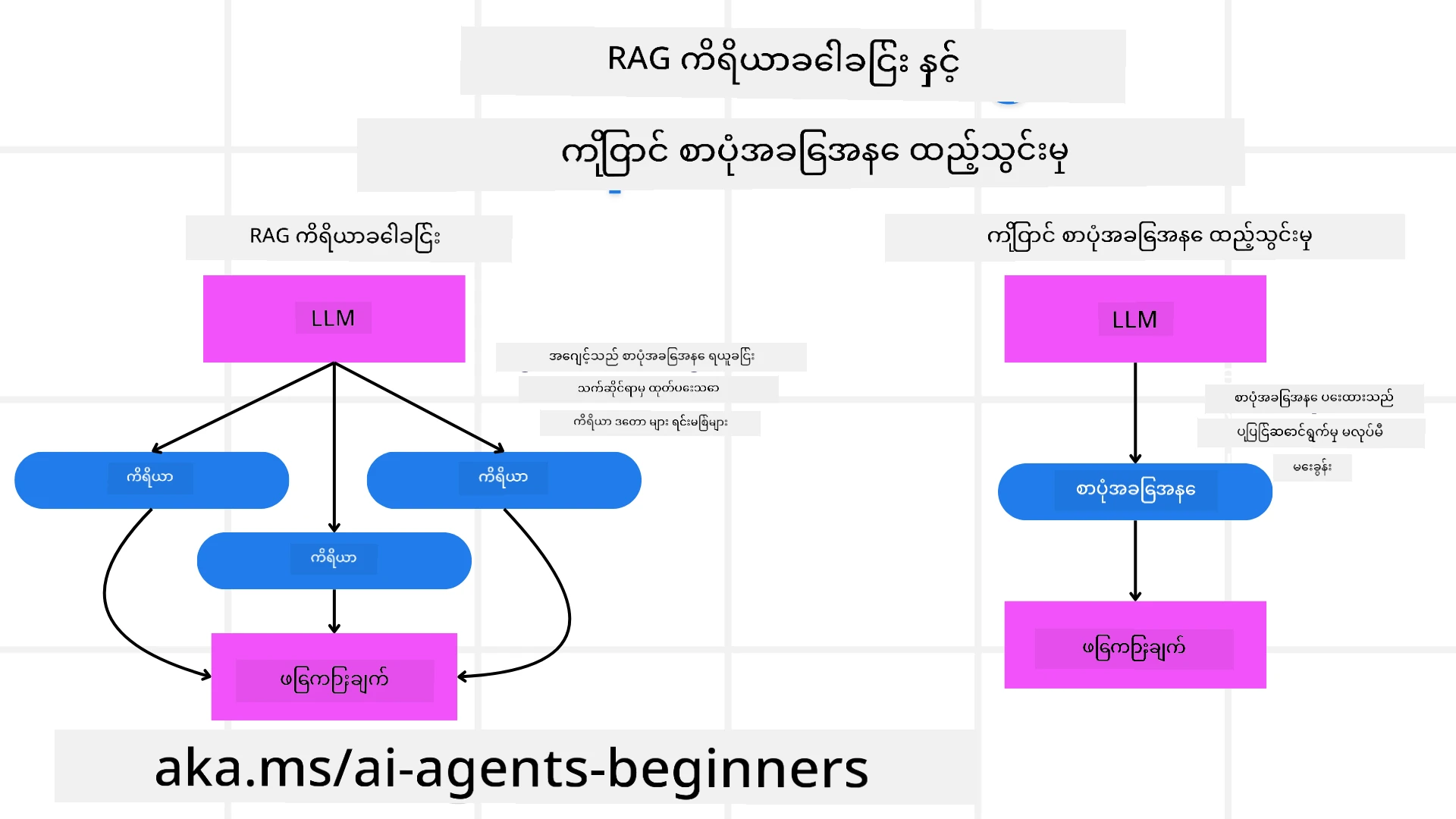
Retrieval-Augmented Generation (RAG)
RAG သည် ရယူရေးစနစ်နှင့် တီထွင်ထုတ်လုပ်မှု မော်ဒယ်ကို ပေါင်းစပ် သုံးစွဲသည်။ မေးခွန်းတစ်ခုတောင်းလာသောအခါ ရယူရေးစနစ်သည် အပြင်အSources မှ သင့်တော်သော စာရွက်စာတမ်းများ သို့ ဒေတာများ ရယူကာ ထုတ်လုပ်ခြင်းမော်ဒယ်ထံ ဖြည့်စွက်ရာတွင် ထာဝရ အသုံးချသည်။ ၎င်းသည် မော်ဒယ်အား မှန်ကန်၍ ပတ်ဝန်းကျင်နှင့် ကိုက်ညီသော တုံ့ပြန်ချက်များ ထုတ်ပေးနိုင်စေရန် ကူညီသည်။
RAG စနစ်တွင် အေးဂျင့်သည် သိပ္ပံနယ်ပယ် အချက်အလက်များ ရယူကာ အနီးကပ်တဲ့ တုံ့ပြန်မှု သို့မဟုတ် လုပ်ဆောင်ချက်များ ဖန်တီးသုံးစွဲသည်။
ပြင်ဆင်မှု RAG နည်းလမ်း
ပြင်ဆင်မှု RAG နည်းလမ်းသည် AI အေးဂျင့်များ၏ အမှားများ ပြင်ဆင်ခြင်းနှင့် မှန်ကန်မှု တိုးတက်စေရန် RAG နည်းလမ်းများကို အသုံးချခြင်းကို ဦးတည်သည်။ ၎င်းတွင် ပါဝင်သည်-
- ကြွေးကြော်ပုံ နည်းလမ်း: အေးဂျင့်အား သင့်တော်သည့် အချက်အလက်များ ရယူခိုင်းရန် ကြွေးကြော်ထားသော ညွှန်ကြားချက်များကို အသုံးပြုခြင်း။
- ကိရိယာ: ရယူထားသည့် သတင်းအချက်အလက်၏ သင့်တော်မှုကို သုံးသပ်ကာ မှန်ကန်သော တုံ့ပြန်ချက်များ ထုတ်နိုင်ရန် အယ်လဂိုရစ်သမ်များနှင့် ဖွဲ့စည်းမှုများ ထည့်သွင်းထားခြင်း။
- အကဲဖြတ်မှု: အေးဂျင့်၏ စွမ်းဆောင်ရည်ကို ဆက်တိုက် ဆန်းစစ်ပြီး မှန်ကန်မှုနှင့် ထိရောက်မှု တိုးတက်စေရန် ပြင်ဆင်ခြင်း။
ဥပမာ- ရှာဖွေသူအေးဂျင့်တွင် ပြင်ဆင်မှု RAG
အသုံးပြုသူ မေးခွန်းများကို ဖြေကြားရန် ဝက်ဘ်မှ အချက်အလက် ရယူသော ရှာဖွေသူအေးဂျင့်ကို သတိပြုပါ။ ပြင်ဆင်မှု RAG နည်းလမ်းတွင်-
- ကြွေးကြော်ပုံ နည်းလမ်း: အသုံးပြုသူ၏ အချက်အလက်အပေါ် အခြေခံ၍ ရှာဖွေစကားများ ဖန်တီးခြင်း။
- ကိရိယာ: သဘာဝဘာသာစကား အလုပ်အမှုဆောင် နည်းပညာနှင့် စက်မှုလေ့လာမှု အယ်လဂိုရစ်သမ်များသုံး၍ ရှာဖွေ မှတ်ချက် အဆင့်ခွဲခြင်းနှင့် ဆင်းကျပ်ခြင်း။
- အကဲဖြတ်: အသုံးပြုသူ တုံ့ပြန်ချက်များကို စိစစ်ကာ ရယူထားသည့် အချက်အလက် မမှန်ကန်မှုများကို ရှာဖွေ ပြင်ဆင်ခြင်း။
ခရီးသွား အေးဂျင့်တွင် ပြင်ဆင်မှု RAG
ပြင်ဆင်မှု RAG (Retrieval-Augmented Generation) သည် AI ၏ သတင်းအချက်အလက် ရယူခြင်းနှင့် ဖန်တီးမှု စွမ်းဆောင်ရည်များကို မြှင့်တင်ပေးပြီး တစ်စုံတစ်ရာမှားယွင်းမှုများကို ပြင်ဆင်ပေးသည်။ Travel Agent သည် ပြင်ဆင်မှု RAG နည်းလမ်း ပြုလုပ်၍ ပိုမိုမှန်ကန်ပြီး သင့်တော်သော ခရီးသွားအကြံပြုချက်များ ပေးနိုင်သည့်နည်းလမ်းကို ကြည့်ပါ။
၎င်းတွင်ပါဝင်သည်-
- ကြွေးကြော်ပုံ နည်းလမ်း: အေးဂျင့်အား သင့်တော်သော အချက်အလက်များ ရယူခိုင်းရန် သတ်မှတ်ထားသော ကြွေးကြော်ချက်များ အသုံးပြုခြင်း။
- ကိရိယာ: ရယူထားသည့် သတင်းအချက်အလက်၏ သင့်တော်မှုကို သုံးသပ်ကာ မှန်ကန်သော တုံ့ပြန်ချက်များ ထုတ်နိုင်ရန် အယ်လဂိုရစ်သမ်နှင့် လုပ်ထုံးလုပ်နည်းများ ထည့်သွင်းခြင်း။
- အကဲဖြတ်မှု: အေးဂျင့်၏ စွမ်းဆောင်ရည်ကို ဆက်တိုက် စိစစ်ကာ မှန်ကန်မှုနှင့် ထိရောက်မှု တိုးတက်အောင် ပြင်ဆင်ခြင်း။
ခရီးသွား အေးဂျင့်တွင် ပြင်ဆင်မှု RAG တပ်ဆင်ခြင်းအဆင့်များ
- အစပိုင်း အသုံးပြုသူ ဆက်သွယ်မှု
- Travel Agent သည် ပထမဆုံးအသုံးပြုသူထံမှ ခရီးသွားရာဒေသ၊ ခရီးသွားရက်များ၊ ဘဏ္ဍာရေးနှင့် စိတ်ဝင်စားမှုများကို စုဆောင်းသည်။
-
ဥပမာ-
preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] }
- သတင်းအချက်အလက် ရယူခြင်း
- Travel Agent သည် အသုံးပြုသူစိတ်ကြိုက်မှုအပေါ် အခြေခံ၍ လေယာဉ်များ၊ နေအိမ်များ၊ ဆွဲဆောင်မှုများနှင့် မိမိနှစ်သက်သော စားသောက်ဆိုင်များကို ရယူသည်။
-
ဥပမာ-
flights = search_flights(preferences) hotels = search_hotels(preferences) attractions = search_attractions(preferences)
- အစပျိုးအကြံပြုချက်များ ဖန်တီးခြင်း
- Travel Agent သည် ရယူထားသည့် သတင်းအချက်အလက်အား အသုံးပြု၍ ပုဂ္ဂိုလ်ရေး ခရီးစဥ် စာရင်း ဖန်တီးသည်။
-
ဥပမာ-
itinerary = create_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary)
- အသုံးပြုသူ တုံ့ပြန်ချက် စုဆောင်းခြင်း
- Travel Agent သည် ပထမအကြံပြုချက်များအပေါ် အသုံးပြုသူတောင်းဆိုမှုကို မေးမြန်းသည်။
-
ဥပမာ-
feedback = { "liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"] }
- ပြင်ဆင်မှု RAG လုပ်ငန်းစဉ်
- ကြွေးကြော်ပုံ နည်းလမ်း: Travel Agent သည် အသုံးပြုသူရဲ့ တုံ့ပြန်ချက်ကို အခြေခံပြီး ရှာဖွေတောင်းဆိုစာများ အသစ် ဖန်တီးသည်။
-
ဥပမာ-
if "disliked" in feedback: preferences["avoid"] = feedback["disliked"]
-
- ကိရိယာ: Travel Agent သည် အသုံးပြုသူ တုံ့ပြန်ချက်အပေါ် အခြေခံကာ ရှာဖွေမှုရလဒ်များကို အဆင့်ခွဲနှင့် စစ်ထုတ်ခြင်း ပြုလုပ်သည်။
-
ဥပမာ-
new_attractions = search_attractions(preferences) new_itinerary = create_itinerary(flights, hotels, new_attractions) print("Updated Itinerary:", new_itinerary)
-
- အကဲဖြတ်မှု: Travel Agent သည် အသုံးပြုသူတုံ့ပြန်ချက်များ ကို စဉ်ဆက်မပြတ် တုံ့ပြန်မှု သင့်တော်မှုအား သုံးသပ်၊ ပြင်ဆင်ခြင်း ပြုလုပ်သည်။
-
ဥပမာ-
def adjust_preferences(preferences, feedback): if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences preferences = adjust_preferences(preferences, feedback)
-
- ကြွေးကြော်ပုံ နည်းလမ်း: Travel Agent သည် အသုံးပြုသူရဲ့ တုံ့ပြန်ချက်ကို အခြေခံပြီး ရှာဖွေတောင်းဆိုစာများ အသစ် ဖန်တီးသည်။
လက်တွေ့ ဥပမာ
Travel Agent တွင် ပြင်ဆင်မှု RAG နည်းလမ်း ဖြည့်စွက်ထားသည့် ရိုးရှင်းသော Python ကုဒ် ဥပမာ-
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
new_itinerary = self.generate_recommendations()
return new_itinerary
# နမူနာအသုံးပြုခြင်း
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
new_itinerary = travel_agent.adjust_based_on_feedback(feedback)
print("Updated Itinerary:", new_itinerary)
Pre-emptive Context Load
Pre-emptive Context Load ဆိုတာမှာ မေးခွန်းတစ်ခုကို ချမှတ်ရာမှာမတိုင်မီ အရေးကြီးတဲ့ နောက်ခံသတင်းအချက်အလက်များ သိမြင်မှုကို မော်ဒယ်ထဲမှာ ကြိုထည့်ပေးခြင်း ဖြစ်ပါတယ်။ ဒီလိုနဲ့ မော်ဒယ်ရဲ့ စတင်ချိန်မှာ သက်ဆိုင်သည့် အချက်အလက်တွေကို ရရှိထားနိုင်လို့၊ အင်္ဂါရပ်အသစ်များကို ပြန်ရှာဖွေရန်လိုအပ်မှုမရှိဘဲ ပိုမို သိမြင်ပြီး တုံ့ပြန်နိုင်ပါတယ်။
Python မှာ ခရီးသွားအေဂျင့် အက်ပ်လီကေးရှင်းအတွက် pre-emptive context load ရဲ့ ရိုးရှင်းတဲ့ ဥပမာက ဒီအတိုင်းဖြစ်ပါတယ် -
class TravelAgent:
def __init__(self):
# လူကြိုက်အများဆုံးနေရာများနှင့် သတင်းအချက်အလက်များကို ကြိုတင်ပေးရန်
self.context = {
"Paris": {"country": "France", "currency": "Euro", "language": "French", "attractions": ["Eiffel Tower", "Louvre Museum"]},
"Tokyo": {"country": "Japan", "currency": "Yen", "language": "Japanese", "attractions": ["Tokyo Tower", "Shibuya Crossing"]},
"New York": {"country": "USA", "currency": "Dollar", "language": "English", "attractions": ["Statue of Liberty", "Times Square"]},
"Sydney": {"country": "Australia", "currency": "Dollar", "language": "English", "attractions": ["Sydney Opera House", "Bondi Beach"]}
}
def get_destination_info(self, destination):
# ကြိုတင်လွှင့်ထားသော အကြောင်းအရာမှ နေရာဆိုင်ရာ သတင်းအချက်အလက်များကို မောင်းနှင်သည်
info = self.context.get(destination)
if info:
return f"{destination}:\nCountry: {info['country']}\nCurrency: {info['currency']}\nLanguage: {info['language']}\nAttractions: {', '.join(info['attractions'])}"
else:
return f"Sorry, we don't have information on {destination}."
# ဥပမာအသုံးပြုမှု
travel_agent = TravelAgent()
print(travel_agent.get_destination_info("Paris"))
print(travel_agent.get_destination_info("Tokyo"))
ရှင်းလင်းချက်
-
စတင်ဖန်တီးခြင်း (
__init__method):TravelAgentclass ကတော့ Paris, Tokyo, New York, Sydney စတဲ့ လူကြိုက်များတဲ့ ခရီးသွားနေရာတွေကို သတင်းအချက်အလက်များပါဝင်တဲ့ dictionary ကို ကြိုတင်ထည့်သွင်းထားပါတယ်။ ဒီ dictionary မှာ နိုင်ငံအမည်၊ ငွေကြေးကြိုး၊ ဘာသာစကားနဲ့ အဓိကဆွဲဆောင်မှုများအကြောင်းပါဝင်ပါတယ်။ -
သတင်းအချက်အလက် ရယူခြင်း (
get_destination_infomethod): အသုံးပြုသူတစ်ဦးက တိကျတဲ့ ခရီးသွားနေရာအကြောင်း မေးမြန်းသောအခါget_destination_infomethod က ကြိုတင်ထည့်သွင်းထားသော dictionary မှ သက်ဆိုင်ရာ သတင်းအချက်အလက်များကို ရယူပေးပါတယ်။
နောက်ခံသတင်းအချက်အလက်ကို ကြိုတင် load လုပ်ခြင်းက ခရီးသွားအေဂျင့်အက်ပ်လီကေးရှင်းကို အသုံးပြုသူမေးခွန်းများကို ပိုမိုမြန်ဆန်စွာ တုံ့ပြန်ပေးနိုင်စေပြီး အပြင်အရင်းအမြစ်ကနေ အချက်အလက်များကို တင်းအားမှ ရှာဖွေရေး မလိုသဖြင့် အချက်အလက် ရယူမှုကို ပိုမိုထိရောက်စေပါတယ်။
ရည်ရွယ်ချက်နဲ့ စပြီး စီမံကိန်းကို Bootstrapping ပြုလုပ်ခြင်း
ရည်ရွယ်ချက်နဲ့ စပြီး စီမံကိန်းကို bootstrapping ပြုလုပ်ခြင်းဆိုသည်မှာ ရည်မှန်းချက် သေချာထားပြီး စတင်ခြင်းဖြစ်ပါတယ်။ ဒီရည်ရွယ်ချက်ကို ရှင်းလင်းသတ်မှတ်ခြင်းက မော်ဒယ်ထိတွေ့မှုတစ်ခုတည်းလည်ပတ်စေရန် လမ်းညွှန်ပေးပြီး နောက်တကြိမ် မှတ်သားမှုတွေမှာ ရည်ရွယ်ချက်အတိုင်း တိုးတက်သွားနိုင်ပါသည်။ ဒီနည်းလမ်းက စီမံကိန်း၏ ထိရောက်မှုနဲ့ အာရုံစိုက်မှုကို မြှင့်တင်ပါသည်။
Python မှာ ခရီးသွားအေဂျင့်အတွက် စီမံကိန်းကို ရည်ရွယ်ချက်နဲ့ စပြီး လှည့်ကြည့်တဲ့ ဥပမာက ဒီအတိုင်းဖြစ်ပါတယ် -
နောက်ခံ
ခရီးသွားအေဂျင့်တစ်ဦးက ဖောက်သည်အတွက် ကိုယ်ပိုင်ထိပ်တန်း ခရီးစဉ်တစ်ခု စီမံချင်ပါတယ်။ ရည်ရွယ်ချက်က ဖောက်သည်၏ စိတ်ကျေနပ်မှုအများဆုံး ဖြစ်အောင် ခရီးစဉ်သည် လူစိတ်နှင့် ဘတ်ဂျက်အရ တိကျစွာ ပြုလုပ်ရန်ဖြစ်ပါတယ်။
အဆင့်များ
- ဖောက်သည် စိတ်ရဲ့နှစ်သက်မှုနဲ့ ဘတ်ဂျက်ကို သတ်မှတ်ပါ။
- ဤနှစ်သက်မှုများအပေါ် အခြေခံပြီး စီမံကိန်းအစကို bootstrapping လုပ်ပါ။
- စီမံကိန်းကို iterate ပြုလုပ်၍ ဖောက်သည် စိတ်နှစ်သက်မှုအပေါ် အသင့်တော်ဆုံးအဖြစ် တိုးတက်အောင်လုပ်ပါ။
Python ကုဒ်
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def bootstrap_plan(self, preferences, budget):
plan = []
total_cost = 0
for destination in self.destinations:
if total_cost + destination['cost'] <= budget and self.match_preferences(destination, preferences):
plan.append(destination)
total_cost += destination['cost']
return plan
def match_preferences(self, destination, preferences):
for key, value in preferences.items():
if destination.get(key) != value:
return False
return True
def iterate_plan(self, plan, preferences, budget):
for i in range(len(plan)):
for destination in self.destinations:
if destination not in plan and self.match_preferences(destination, preferences) and self.calculate_cost(plan, destination) <= budget:
plan[i] = destination
break
return plan
def calculate_cost(self, plan, new_destination):
return sum(destination['cost'] for destination in plan) + new_destination['cost']
# ဥပမာအသုံးပြုမှု
destinations = [
{"name": "Paris", "cost": 1000, "activity": "sightseeing"},
{"name": "Tokyo", "cost": 1200, "activity": "shopping"},
{"name": "New York", "cost": 900, "activity": "sightseeing"},
{"name": "Sydney", "cost": 1100, "activity": "beach"},
]
preferences = {"activity": "sightseeing"}
budget = 2000
travel_agent = TravelAgent(destinations)
initial_plan = travel_agent.bootstrap_plan(preferences, budget)
print("Initial Plan:", initial_plan)
refined_plan = travel_agent.iterate_plan(initial_plan, preferences, budget)
print("Refined Plan:", refined_plan)
ကုဒ် ရှင်းလင်းချက်
-
စတင်ဖန်တီးခြင်း (
__init__method):TravelAgentclass မှာ ခရီးသွားနိုင်ရာနေရာများကို အမည်၊ ကုန်ကျစရိတ်နဲ့ လှုပ်ရှားမှုအမျိုးအစားတို့ ပါဝင်သော စာရင်းနဲ့ စတင်ဖန်တီးထားပါတယ်။ -
စီမံကိန်း bootstrapping (
bootstrap_planmethod): ဖောက်သည်၏ စိတ်နှစ်သက်မှုနဲ့ ဘတ်ဂျက်ကို အခြေခံ၍ စတင်ခရီးစဉ်ကို ဒီ method က ဖန်တီးပေးပါသည်။ နေရာတိုင်းကို စစ်ဆေးပြီး ဖောက်သည်နှစ်သက်တာဖြစ်ပြီး ဘတ်ဂျက်ထဲသွင်းနိုင်လျှင် စီမံကိန်းထဲ ထည့်ပေးပါသည်။ -
နှစ်သက်မှုကို အညီ တွဲဖက်စစ်ဆေးခြင်း (
match_preferencesmethod): ဒီ method ကနေ နေရာတစ်ခုက ဖောက်သည်နှစ်သက်မှုနဲ့ ကိုက်ညီမလား စစ်ဆေးပါတယ်။ -
စီမံကိန်းကို iterate ပြုလုပ်ခြင်း (
iterate_planmethod): စတင်ထားသော စီမံကိန်းကို ပိုမိုကောင်းအောင် ပြင်ဆင်ရန် နေရာတစ်ခုစီကို ပိုမို ကိုက်ညီသော နေရာဖြင့် ဒီ method က အစားထိုး ဖို့ ကြိုးစားပါတယ်။ -
ကုန်ကျစရိတ်တွက်ချက်ခြင်း (
calculate_costmethod): ယခုရှိသော စီမံကိန်း၏ စုစုပေါင်း ကုန်ကျစရိတ်ကို ပိုမိုကောင်းမွန်စေရန် နေရာအသစ်ထည့်သွင်းပြီး တွက်ချက်ပေးပါတယ်။
အသုံးပြုမှုဥပမာ
- စတင်အစီအစဉ်: ခရီးသွားအေဂျင့်က ဖောက်သည်၏ ခရီးသွားရှုမြင်ချင်စိတ်နှင့် $2000 ဘတ်ဂျက်အရ စီမံကိန်းအစ ကို ဖန်တီးပါတယ်။
- ပြင်ဆင်ပြီးဖြစ်သော စီမံကိန်း: ဖောက်သည်၏ မျှော်မှန်းချက်နှင့် ဘတ်ဂျက်အတိုင်း စီမံကိန်းကို iterate လုပ်ပြီး အကောင်းဆုံးအခြေအနေသို့ တိုးတက်အောင် ကြိုးစားပါတယ်။
ရည်ရွယ်ချက်နှင့် စပြီး စီမံကိန်းကို bootstrapping လုပ်ပြီး iterate ပြုလုပ်ခြင်းက ဖောက်သည် စိတ်နှစ်သက်မှုနဲ့ ဘတ်ဂျက်တို့နှင့် ကိုက်ညီသော အပြည့်အဝပြည့်စုံပြီး လိုအပ်ချက်နှင့် တိကျစွာ ပြုလုပ်ပေးနိုင်သော ခရီးစဉ်တစ်ခုကို ဖန်တီးပေးနိုင်သည်။ ဒီနည်းလမ်းက စီမံကိန်းကို စတင်ခြင်းအချိန်မှစပြီး ဖောက်သည်အလိုက်လုပ်ဆောင်မှု နှင့် တိုးတက်မှုကို ကျဆင်းလျော့ပါသောနည်းဖြစ်သည်။
LLM ကို Re-ranking နဲ့ Scoring အတွက် အကျိုးယူခြင်း
ကြီးမားသော ဘာသာစကား မော်ဒယ်များ (LLMs) ကို document များသိုလှောင်ခြင်းနှင့် ပြန်လည် ရေးဆွဲခြင်းများမှာ ရှာဖွေရေးနှင့် ပြန်လည် အဆင့်သတ်မှတ်ရာတွင် အသုံးပြုနိုင်သည်။ အောက်ပါအတိုင်း အလုပ်လုပ်ပါသည် -
ရှာဖွေခြင်း: မူလရရှိသော ရှာဖွေရေး လုပ်ထုံးလုပ်နည်းတွင် မေးခွန်းအပေါ် မူတည်ပြီး အမည်တူ candidates (စာရွက်စာတမ်းများ သို့မဟုတ် တုံ့ပြန်ချက်များ) စုစည်းသည်။
ပြန်လည် အဆင့်သတ်မှတ်ခြင်း: LLM သည် ဤ candidates များကို အဆင့်သတ်မှတ်၍ အဆင့်သတ်မှတ်မှုအရ သီးခြားခွဲခြားသည်။ ဒီအဆင့် သတ်မှတ်ခြင်းက ပြီးဆုံးသည့်အချိန်မှာ အကောင်းဆုံး၊ အဆင့်မြင့်ဆုံး သတင်းအချက်အလက်များ ပထမဆုံးတင်ဆက်ရန် အာမခံပေးသည်။
ဆီဆိုင်ချက်အဆင့်သတ်မှတ်ခြင်း: LLM မှ အကောင်းဆုံးတုံ့ပြန်ချက်ရွေးချယ်နိုင်ရန် နှစ်သက်မှုနဲ့ အရည်အသွေးမှတ်တိုင်များကို ရယူပြီး အဆင့်သတ်မှတ်ပေးသည်။
LLM များကို Re-ranking နဲ့ Scoring များအတွက် အသုံးပြုခြင်းကစနစ်တစ်ခုကို ပိုမို တိကျပြီး သက်ဆိုင်ရာ အချက်အလက်များပေးနိုင်ရန် လမ်းဆောင်သွားပါတယ်၊ အသုံးပြုသူအတွေ့အကြုံကို မြှင့်တင်ပေးပါတယ်။
Python ဖြင့် အသုံးပြုသူနှစ်သက်မှုအပေါ် မူတည်၍ ခရီးသွားနေရာများကို Re-ranking နှင့် Scoring ပြုလုပ်ခြင်းအတွက် Azure OpenAI ဝန်ဆောင်မှုကို အသုံးပြုသော ခရီးသွားအေဂျင့် ဥပမာ -
နောက်ခံ - အသုံးပြုသူနှစ်သက်မှုအပေါ် အခြေခံ ခရီးသွားမှု
ခရီးသွားအေဂျင့် က ဖောက်သည်တစ်ဦးအတွက် သူများနှစ်သက်သည်များအပေါ် အခြေခံ၍ အကောင်းဆုံး ခရီးသွားနေရာများကို အကြံပြုလိုသည်။ LLM ကခြားနားသော ခရီးသွားနေရာများကို ပြန်လည်အဆင့်သတ်မှတ်ပြီး အကောင်းဆုံးဖြစ်အောင် ရမှတ်ပေးပါသည်။
အဆင့်များ
- အသုံးပြုသူနှစ်သက်မှုကို စုဆောင်းပါ။
- ခရီးသွားနေရာလျှောက်လွှာစာရင်းကို ရှာဖွေပါ။
- LLM ကို အသုံးပြုပြီး အဆိုပါနေရာများကို Re-ranking နဲ့ Scoring လုပ်ပါ။
Azure OpenAI Services ကို အသုံးပြုရန် အောက်ပါအတိုင်း နမူနာ ပြင်ဆင်ပုံ -
လိုအပ်ချက်များ
- Azure subscription ရှိရန်လိုအပ်သည်။
- Azure OpenAI ရင်းမြစ်တစ်ခု ဖန်တီးပြီး API key ရယူပါ။
Python ကုဒ် ဥပမာ
import requests
import json
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def get_recommendations(self, preferences, api_key, endpoint):
# Azure OpenAI အတွက် prompt တစ်ခု ဖန်တီးပါ
prompt = self.generate_prompt(preferences)
# တောင်းဆိုမှုအတွက် headers နှင့် payload ကို သတ်မှတ်ပါ
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
payload = {
"prompt": prompt,
"max_tokens": 150,
"temperature": 0.7
}
# Azure OpenAI API ကို ခေါ်ဆိုပြီး re-ranked နှင့် ရမှတ်ပေးထားသော သွားရောက်မည့်နေရာများကို ရယူပါ
response = requests.post(endpoint, headers=headers, json=payload)
response_data = response.json()
# အကြံပြုချက်များကို ခွဲထုတ်ပြီး ပြန်လည်ပေးပို့ပါ
recommendations = response_data['choices'][0]['text'].strip().split('\n')
return recommendations
def generate_prompt(self, preferences):
prompt = "Here are the travel destinations ranked and scored based on the following user preferences:\n"
for key, value in preferences.items():
prompt += f"{key}: {value}\n"
prompt += "\nDestinations:\n"
for destination in self.destinations:
prompt += f"- {destination['name']}: {destination['description']}\n"
return prompt
# ဥပမာအသုံးပြုမှု
destinations = [
{"name": "Paris", "description": "City of lights, known for its art, fashion, and culture."},
{"name": "Tokyo", "description": "Vibrant city, famous for its modernity and traditional temples."},
{"name": "New York", "description": "The city that never sleeps, with iconic landmarks and diverse culture."},
{"name": "Sydney", "description": "Beautiful harbour city, known for its opera house and stunning beaches."},
]
preferences = {"activity": "sightseeing", "culture": "diverse"}
api_key = 'your_azure_openai_api_key'
endpoint = 'https://your-endpoint.com/openai/deployments/your-deployment-name/completions?api-version=2022-12-01'
travel_agent = TravelAgent(destinations)
recommendations = travel_agent.get_recommendations(preferences, api_key, endpoint)
print("Recommended Destinations:")
for rec in recommendations:
print(rec)
ကုဒ် ရှင်းလင်းချက် - Preference Booker
-
စတင်ဖန်တီးခြင်း:
TravelAgentclass ကို ခရီးသွားနိုင်ရာနေရာ စာရင်းဖြင့် စတင်ဖန်တီးထားပြီး နေရာအသီးသီးတွင် အမည်နှင့် ဖော်ပြချက်ပါသည်။ -
အကြံပြုချက်ရယူခြင်း (
get_recommendationsmethod): အသုံးပြုသူနှစ်သက်မှုအပေါ် အခြေခံ၍ Azure OpenAI ဝန်ဆောင်မှုအား prompt တစ်ခုတည်း ဖန်တီးပြီး API မှ POST request လုပ်၍ ပြန်လာသည့် Re-ranking နှင့် Scoring ချမှတ်ထားသော တည်နေရာများ ရယူသည်။ -
Prompt ဖန်တီးခြင်း (
generate_promptmethod): Azure OpenAI အတွက် prompt ကို အသုံးပြုသူနှစ်သက်မှုများနှင့် ခရီးသွားနေရာများစာရင်း ပါဝင်အောင် ဖန်တီးသည်။ ဒီ prompt က မော်ဒယ်ကို နေရာများကို Re-rank နဲ့ scoring ပြုလုပ်ရန် လမ်းညွှန်သည်။ -
API ခေါ်ဆိုမှု:
requests라이ဘ်ရာရီကို အသုံးပြုပြီး Azure OpenAI API endpoint ဖြင့် POST request လုပ်သည်။ ပြန်လာသော ရလဒ်တွင် Re-ranked နှင့် Scored နေရာများ ပါဝင်သည်။ -
အသုံးပြုမှု ဥပမာ: ခရီးသွားအေဂျင့်က အသုံးပြုသူနှစ်သက်မှု (ဥပမာ - ခရီးသွားရှုမြင်သည်မှာစိတ်ဝင်စားခြင်းနှင့် ယဉ်ကျေးမှုကွဲပြားမှု) ကို စုဆောင်းပြီး Azure OpenAI ဝန်ဆောင်မှုမှ Re-ranked နဲ့ scored အကြံပြုချက်များ ရယူသည်။
သင့်ရဲ့ your_azure_openai_api_key ကို သင့်ရဲ့ အမှန်တကယ် Azure OpenAI API key နဲ့ ပြောင်းပါ၊ ဟာ URL (https://your-endpoint.com/...) ကို သင့် Azure OpenAI deployment ၏ အမှန်တကယ် endpoint URL နဲ့ လဲပြောင်းပါ။
LLM ကို Re-ranking နဲ့ Scoring အတွက် အသုံးပြုခြင်းက ခရီးသွားအေဂျင့်ကို ပိုမို လူအလိုက်ကျပြီး သက်ဆိုင်ရာသော ခရီးသွားအကြံပြုချက်များ ပေးနိုင်ပြီး ဖောက်သည်များအတွက် အရည်အသွေးမြင့် အတွေ့အကြုံပေးနိုင်ပါသည်။
RAG: Prompting နည်းဗျူဟာ vs ကိရိယာ
Retrieval-Augmented Generation (RAG) သည် AI agent ဖန်တီးရာတွင် prompting နည်းဗျူဟာ များနှင့် ကိရိယာမိတ်ဆက်ခြင်းအနေဖြင့် နှစ်မျိုးလုံး အသုံးပြုနိုင်သည်။ ယင်း နှစ်ခုအား စိစစ်သိရှိခြင်းဖြင့် သင်၏ စီမံကိန်းများတွင် RAG ကို ပိုမို ထိရောက်စွာ အသုံးချနိုင်ပါသည်။
RAG အနေနဲ့ Prompting နည်းဗျူဟာ
ဘာလဲ?
- Prompting နည်းဗျူဟာ အနေဖြင့် RAG သည် ကြီးမားသော ဒေတာသိုလှောင်ရာ သိုလှောင်ပစ္စည်းမှ သက်ဆိုင်ရာ အချက်အလက် ရှာဖွေရေး အတွက် စွမ်းဆောင် ရန် သေချာသော prompts သို့မဟုတ် မေးခွန်းများ ဖန်တီးခြင်းဖြစ်သည်။ ရရှိသော သတင်းအချက်အလက်များကို ပြန်တုံ့ပြန်မှု သို့မဟုတ် လုပ်ဆောင်ချက်များ ဖန်တီးရာတွင် အသုံးပြုသည်။
အလုပ်လုပ်ပုံ
- Prompt ဖန်တီးခြင်း: တာဝန် သို့ မေးမှန်းထားသော အသုံးပြုသူ input အပေါ် အခြေခံ၍ စနစ်တကျ ဖော်ဆောင်ထားသော prompt များ သို့မဟုတ် မေးခွန်းများ ဖန်တီးပါ။
- သတင်းအချက်အလက် ရရှိခြင်း: အဆိုပါ prompts များဖြင့် ရှာဖွေရေး လုပ်ပြီး ရှာဖွေလိုသည့် သတင်းအချက်အလက်ကို ရယူပါ။
- တုံ့ပြန်မှု ဖန်တီးခြင်း: ရရှိထားသည့် သတင်းအချက်အလက်များနှင့် generative AI မော်ဒယ်များနှင့် ပေါင်းစပ်၍ စုစုပေါင်း ရောဇာတိ တုံ့ပြန်ချက်ကို ဖန်တီးပါ။
ခရီးသွားအေဂျင့် မှ နမူနာ
- အသုံးပြုသူ input: “Paris ရှိ ပြတိုက်တွေကို သွားကြည့်ချင်ပါတယ်။”
- Prompt: “Paris ရှိ ထိပ်တန်းပြတိုက်တွေ ရှာဖွေပါ။”
- ရရှိသော သတင်းအချက်အလက်: Louvre ပြတိုက် ၊ Musée d’Orsay စသဖြင့်
- ဖန်တီးထားသော တုံ့ပြန်ချက်: “Paris ရှိ ထိပ်တန်းပြတိုက်တွေမှာ Louvre ပြတိုက်၊ Musée d’Orsay နဲ့ Centre Pompidou ပါ။”
RAG အနေနဲ့ ကိရိယာ
ဘာလဲ?
- ကိရိယာအနေနဲဲ့ RAG သည် AI agent ကိုယ်စားပြု စနစ်တစ်ခုဖြစ်ပြီး retrieval နဲ့ generation လုပ်ငန်းစဉ်များကို အလိုအလျောက် စီမံခန့်ခွဲနိုင်သော အင်ဂျင်တစ်ရပ် ဖြစ်သည်။ ဒါက developer များအတွက် မေးခွန်းတစ်ခုချင်းစီအတွက် manual prompt မဖန်တီးပဲ လုပ်ဆောင်နိုင်စေသည်။
အလုပ်လုပ်ပုံ
- ပေါင်းစည်းစနစ်ဖြင့် သွင်းဆောင်ခြင်း: AI agent ၏ စနစ်တွင် RAG ကို ဖြည့်သွင်း၍ retrieval နဲ့ generation လုပ်ငန်းစဉ်အား အလိုအလျောက် လုပ်ဆောင်စေသည်။
- အလိုအလျောက်စနစ်: အသုံးပြုသူ input ရလာသည်နှင့်စပြီး နောက်ဆုံးတုံ့ပြန်ချက် ထုတ်ပေးသည့် အချက်အလက်ထုတ်ပေးမှု အဆင့်တိုင်းကို အလိုအလျောက် စီမံခန့်ခွဲပေးသည်။
- ထိရောက်မှုမြှင့်တင်ခြင်း: retrieval နဲ့ generation လုပ်ငန်းစဉ်များကို အရှိန်မြှင့်ပြီး တုံ့ပြန်ချက်များကို ပိုမို ပေါင်းစည်း တိကျစေသည်။
ခရီးသွားအေဂျင့် မှ နမူနာ
- အသုံးပြုသူ input: “Paris ရှိ ပြတိုက်တွေကို သွားကြည့်ချင်ပါတယ်။”
- RAG ကိရိယာ: ပြတိုက်အချက်အလက်များကို အလိုအလျောက် ရှာဖွေပြီး တုံ့ပြန်ချက်အားဖန်တီးသည်။
- ဖန်တီးထားသော တုံ့ပြန်ချက်: “Paris ရှိ ထိပ်တန်းပြတိုက်တွေမှာ Louvre ပြတိုက်၊ Musée d’Orsay နဲ့ Centre Pompidou ပါ။”
နှိုင်းယှဉ်ခြင်း
| အချက်အလက် | Prompting နည်းဗျူဟာ | ကိရိယာ |
|---|---|---|
| Manual vs Automatic | မေးခွန်းတိုင်းအတွက် manual prompt ဖန်တီးခြင်း | Retrieval နဲ့ generation အလိုအလျောက် လုပ်ငန်းစဉ် |
| ထိန်းချုပ်မှု | Retrieval လုပ်ငန်းစဉ်ကို ပိုမို ထိန်းချုပ်နိုင် | Retrieval နဲ့ generation ကို အလိုအလျောက်လုပ်ဆောင်မှု |
| လွယ်ကူမှု | တိကျသော အကြောင်းအရာအပေါ် မူတည် ချိန်ညှိနိုင်ခြင်း | ကြီးမားသော ပရောဂျက်များအတွက် ထိရောက်စွာ အသုံးပြုရန် |
| ရှုပ်ထွေးမှု | Prompt များကို ဖန်တီး ထိန်းသိမ်းရန် လိုအပ် | AI agent architecture ထဲတွင် ပေါင်းစပ်ရန် လွယ်ကူ |
အသုံးပြု နမူနာများ
Prompting နည်းဗျူဟာ နမူနာ
def search_museums_in_paris():
prompt = "Find top museums in Paris"
search_results = search_web(prompt)
return search_results
museums = search_museums_in_paris()
print("Top Museums in Paris:", museums)
ကိရိယာ နမူနာ
class Travel_Agent:
def __init__(self):
self.rag_tool = RAGTool()
def get_museums_in_paris(self):
user_input = "I want to visit museums in Paris."
response = self.rag_tool.retrieve_and_generate(user_input)
return response
travel_agent = Travel_Agent()
museums = travel_agent.get_museums_in_paris()
print("Top Museums in Paris:", museums)
သက်ဆိုင်မှု အကဲဖြတ်ခြင်း
သက်ဆိုင်မှု အကဲဖြတ်ခြင်းသည် AI agent ၏ လုပ်ဆောင်မှုမှာ အရေးကြီးတဲ့ အရှုပစ်တစ်ခုဖြစ်ပြီး ရရှိထားသော သတင်းအချက်အလက်နှင့် ပြန်လည်ဖန်တီးထားသော တုံ့ပြန်ချက်များသည် အသုံးပြုသူအတွက် သင့်တော်ပြီး တိကျမှန်ကန်နေရမည်ကို သေချာစေပါသည်။ AI agent အသုံးပြု၍ သက်ဆိုင်မှု အကဲဖြတ်နည်းလမ်းများနဲ့ နမူနာတွေကို ကြည့်ကြည့်ကြပါစို့။
သက်ဆိုင်မှု အကဲဖြတ်ရာ အဓိက သဘောတရားများ
- Context သတိပြုမှု:
- Agent က အသုံးပြုသူ မေးခွန်း ရဲ့ နောက်ခံcontext ကို သေချာနားလည်၍ သက်ဆိုင်စွာသော သတင်းအချက်အလက်များ ရယူပြန်လည်ထုတ်ပေးရမည်။
- ဥပမာ - “Paris မှာ အကောင်းဆုံးစားသောက်ဆိုင်တွေ” ကို မေးသောအခါ အသုံးပြုသူ စိတ်နှစ်သက်မှု (စားနပ်ရိတ်အမျိုးအစား၊ ဘတ်ဂျက်) များကို ထည့်စဉ်းစားဖို့လိုသည်။
- တိကျမှန်ကန်မှု:
- Agent မှ ပေးသည့် အချက်အလက်များသည် တိကျမှန်ကန်ပြီး လက်ရှိအသုံးပြုနိုင်သည့် အချက်အလက်ဖြစ်ရမည်။
- ဥပမာ - လက်ရှိဖွင့်လှစ်နေသည့် စားသောက်ဆိုင်များကိုသာ အထောက်အပံ့မရှိသည့် သို့မဟုတ် ပိတ်ထားသည့်နေရာများမဟုတ်ဘဲ အကြံပြုခြင်း။
- အသုံးပြုသူ ရည်ရွယ်ချက်:
- Agent မှ အသုံးပြုသူ ရည်ရွယ်ချက် ကို သိရှိပြီး ထိုအတိုင်း သက်ဆိုင်သော အချက်အလက်ပေးရမည်။
- ဥပမာ - “ဘတ်ဂျက်သက်သာသော ဟိုတယ်များ” ကို မေးပါက မိမိစျေးနှုန်းကျသော ဟိုတယ်များကို ဦးစားပေးတင်ပြရန်။
- တုံ့ပြန်မှု Loop:
- အသုံးပြုသူထံမှ feedback များကို ဆက်လက်စုဆောင်း၍ သက်ဆိုင်မှုအကဲဖြတ်မှုကို တိုးတက်တည်ဆောက်ပေးခြင်း။
- ဥပမာ - ယခင်အကြံပြုချက်များအပေါ် အသုံးပြုသူထံမှ rating နှင့် feedback ကောက်ယူပြီး နောက်တလမ်း ကောင်းမွန်စေရန်။
သက်ဆိုင်မှု အကဲဖြတ်နည်းများ
- ထိရောက်မှု အဆင့်သတ်မှတ်ခြင်း:
- ရရှိထားသည့် item တစ်ခုချင်းစီကို အသုံးပြုသူ မေးခွန်းနှင့် နှစ်သက်မှုအပေါ် အခြေခံသည့် သက်ဆိုင်မှု အဆင့် တစ်ခု ချမှတ်သည်။
-
ဥပမာ -
def relevance_score(item, query): score = 0 if item['category'] in query['interests']: score += 1 if item['price'] <= query['budget']: score += 1 if item['location'] == query['destination']: score += 1 return score
- စစ်ထုတ်ခြင်းနှင့် အဆင့်မြှင့်ခြင်း:
- မသက်ဆိုင်သော items များကို ဖယ်ရှားပြီး သက်ဆိုင်မှု အဆင့်အတိုင်း အစဉ်လိုက် စီတန်းသည်။
-
ဥပမာ -
def filter_and_rank(items, query): ranked_items = sorted(items, key=lambda item: relevance_score(item, query), reverse=True) return ranked_items[:10] # ထိပ်တန်း ၁၀ ခုဆက်စပ်သော ပစ္စည်းများကို ပြန်လည်ပေးပို့ပါ။
- ဘာသာစကား အလုပ်ဖြင့် (NLP):
- အသုံးပြုသူ မေးခွန်းကို နားလည်စေရန် NLP နည်းပညာများ အသုံးပြု၍ သက်ဆိုင်သော အချက်အလက် ရှာဖွေသည်။
-
ဥပမာ -
def process_query(query): # အသုံးပြုသူရဲ့မေးခွန်းမှ အဓိကသတင်းအချက်များကို NLP သုံးပြီး ခွဲထုတ်ပါ။ processed_query = nlp(query) return processed_query
- အသုံးပြုသူ feedback ထည့်သွင်းခြင်း:
- ကြိုပြီး ပေးထားသော အကြံပြုချက်များအပေါ် အသုံးပြုသူ မှတ်ချက်များကို စုဆောင်းပြီး နောက်တခါ ထုတ်ပြန်မှုအတွက် သက်ဆိုင်မှု စစ်တမ်းများ ပြင်ဆင်သည်။
-
ဥပမာ -
def adjust_based_on_feedback(feedback, items): for item in items: if item['name'] in feedback['liked']: item['relevance'] += 1 if item['name'] in feedback['disliked']: item['relevance'] -= 1 return items
ဥပမာ - ခရီးသွားအေဂျင့် တွင် သက်ဆိုင်မှု အကဲဖြတ်ခြင်း
ခရီးသွားအေဂျင့်၏ ခရီးသွား အကြံပြုချက်များတွင် သက်ဆိုင်မှု အဆင့်သတ်မှတ်ရန် နမူနာ -
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
ranked_hotels = self.filter_and_rank(hotels, self.user_preferences)
itinerary = create_itinerary(flights, ranked_hotels, attractions)
return itinerary
def filter_and_rank(self, items, query):
ranked_items = sorted(items, key=lambda item: self.relevance_score(item, query), reverse=True)
return ranked_items[:10] # ထိပ်ဆုံး သက်ဆိုင်သော အရာ ၁၀ ခုကို ပြန်လည်ပေးပါ
def relevance_score(self, item, query):
score = 0
if item['category'] in query['interests']:
score += 1
if item['price'] <= query['budget']:
score += 1
if item['location'] == query['destination']:
score += 1
return score
def adjust_based_on_feedback(self, feedback, items):
for item in items:
if item['name'] in feedback['liked']:
item['relevance'] += 1
if item['name'] in feedback['disliked']:
item['relevance'] -= 1
return items
# အသုံးပြုမှု ဥပမာ
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_items = travel_agent.adjust_based_on_feedback(feedback, itinerary['hotels'])
print("Updated Itinerary with Feedback:", updated_items)
ရည်ရွယ်ချက်နှင့် ဟန်ချက်ညီ Search ပြုလုပ်ခြင်း
ရည်ရွယ်ချက်နှင့် ဟန်ချက်ညီ Search ပြုလုပ်ခြင်းဆိုသည်မှာ အသုံးပြုသူမေးခွန်း၏ အောက်ခံ ရည်ရွယ်ချက်၊ ရည်မှန်းချက်နှင့် အဓိက ရည်ရွယ်ချက်ကို နားလည်ဖေါ်ထုတ်ပြီး အဆင်ပြေဆုံး၊ အကျိုးရှိဆုံး သတင်းအချက်အလက်များကို ရယူ ပြန်လည် ဖန်တီးခြင်းဖြစ်သည်။ ဤနည်းသည် Keywords ကိုပဲ တွဲတူညီနေခြင်းထက် ကျော်လွန်၍ အသုံးပြုသူ၏ လိုအပ်ချက်၊ နောက်ခံ စာရင်းကို ပိုမိုနက်ရှိုင်းအောင် နားလည်သည်။
ရည်ရွယ်ချက်နှင့် ဟန်ချက်ညီ Search ရဲ့ အဓိက အစိတ်အပိုင်းများ
- အသုံးပြုသူရဲ့ ရည်ရွယ်ချက် နားလည်ခြင်း:
- အသုံးပြုသူရည်ရွယ်ချက်သည် သတင်းအချက်အလက် ရှာဖွေရေးအတွက် အInformational, Navigational, Transactional အမျိုးအစား သုံးမျိုးခွဲခြားနိုင်သည်။
- Informational Intent: အသုံးပြုသူသည် တစ်ခုခုအကြောင်း သိရှိလိုသည် (ဥပမာ - “Paris ရှိ အကောင်းဆုံးပြတိုက်များက ဘာတွေပါလဲ။”)
- Navigational Intent: အသုံးပြုသူသည် တိတိကျကျ ဝက်ဘ်ဆိုက် သို့မဟုတ် စာမျက်နှာသို့ သွားလိုသည် (ဥပမာ - “Louvre ပြတိုက် ကြေညာစာမျက်နှာ”)
- Transactional Intent: အသုံးပြုသူသည် လုပ်ငန်းစဉ်တစ်ခု ပြုလုပ်ရန် ရည်ရွယ်သည် (ဥပမာ - “Paris သို့ ပျံသန်းကြေးချိတ်စာရင်း”)
- အသုံးပြုသူရည်ရွယ်ချက်သည် သတင်းအချက်အလက် ရှာဖွေရေးအတွက် အInformational, Navigational, Transactional အမျိုးအစား သုံးမျိုးခွဲခြားနိုင်သည်။
- Context သတိပြုမှု:
- အသုံးပြုသူ မေးခွန်းရဲ့ နောက်ခံ context ကို စိစစ်ပြီး ရည်ရွယ်ချက် မှန်ကန်စွာ ကိုယ်စားပြုနိုင်ရန် ပါဝင်သည့် မေးခွန်း၊ ယခင်အတွေ့အကြုံများ၊ အသုံးပြုသူနှစ်သက်မှု စသဖြင့် အချက်အလက်များကို ထည့်စဉ်းစားရန်။
- ဘာသာစကား အလုပ်ဖြင့် (NLP):
- အသုံးပြုသူများထံမှ စကားသဘာဝ စကားလုံးများကို နားလည် ဖေါ်ထုတ်နိုင်ရန် NLP နည်းလမ်းများကို အသုံးပြုသည်။ - Entity recognition, sentiment analysis နှင့် query parsing လုပ်ဆောင်ပါသည်။
- ကိုယ်ပိုင်ဆိုင်ရန် (Personalization):
- အသုံးပြုသူ၏ သမိုင်းကြောင်းနှင့် သဘောကျခြင်းများ၊ feedback များအရ ရလဒ်များကို ကိုယ်ပိုင်ပြုလုပ်ခြင်းက ရလဒ်၏ သက်ဆိုင်မှုကိုမြှင့်တင်ပေးသည်။
ရည်ရွယ်ချက်နှင့် ဟန်ချက်ညီ Search နည်းလမ်းကို ခရီးသွားအေဂျင့်တွင် အသုံးချ နမူနာဖြစ်စေခြင်း
-
အသုံးပြုသူနှစ်သက်မှုစုဆောင်းပါ
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
အသုံးပြုသူရဲ့ ရည်ရွယ်ချက် နားလည်ပါ
def identify_intent(query): if "book" in query or "purchase" in query: return "transactional" elif "website" in query or "official" in query: return "navigational" else: return "informational" -
Context သတိပြုမှု
def analyze_context(query, user_history): # လက်ရှိရှာဖွေရေးကို အသုံးပြုသူ၏ ရှေ့မှတ်တမ်းများနှင့် ပေါင်းစပ်ပြီး အကြောင်းအရာကို နားလည်ရန် context = { "current_query": query, "user_history": user_history } return context -
ရလဒ်ရှာဖှေခြင်းနှင့် ကိုယ်ပိုင်ပြင်ဆင်ခြင်း
def search_with_intent(query, preferences, user_history): intent = identify_intent(query) context = analyze_context(query, user_history) if intent == "informational": search_results = search_information(query, preferences) elif intent == "navigational": search_results = search_navigation(query) elif intent == "transactional": search_results = search_transaction(query, preferences) personalized_results = personalize_results(search_results, user_history) return personalized_results def search_information(query, preferences): # အချက်အလက်ရယူရန်ရည်ရွယ်ချက်အတွက် ရှာဖွေမှုလိုဂစ်အောက်ခံနမူနာ results = search_web(f"best {preferences['interests']} in {preferences['destination']}") return results def search_navigation(query): # လမ်းညွှန်ပေးရန်ရည်ရွယ်ချက်အတွက် ရှာဖွေမှုလိုဂစ်အောက်ခံနမူနာ results = search_web(query) return results def search_transaction(query, preferences): # လုပ်ဆောင်မှုဆိုင်ရာရည်ရွယ်ချက်အတွက် ရှာဖွေမှုလိုဂစ်အောက်ခံနမူနာ results = search_web(f"book {query} to {preferences['destination']}") return results def personalize_results(results, user_history): # ကိုယ်တိုင်သက်ဆိုင်မှုဆိုင်ရာလိုဂစ်အောက်ခံနမူနာ personalized = [result for result in results if result not in user_history] return personalized[:10] # ထိပ်တန်း ၁၀ ခုကို ကိုယ်တိုင်သက်ဆိုင်မှုအရ ပြန်လည်ပေးပို့ပါးခြင်း -
အသုံးပြုမှု ဥပမာ
travel_agent = Travel_Agent() preferences = { "destination": "Paris", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) user_history = ["Louvre Museum website", "Book flight to Paris"] query = "best museums in Paris" results = search_with_intent(query, preferences, user_history) print("Search Results:", results)
4. ကိရိယာအဖြစ် ကုဒ်ဖန်ဆင်းခြင်း
ကုဒ်ဖန်ဆင်းနိုင်သော အေးဂျင့်များသည် AI မော်ဒယ်များကို အသုံးပြုကာ ကုဒ်ရေးခြင်းနှင့် တည်ဆောင်မှုများကို ပြုလုပ်၍ ရှုပ်ထွေးသော ပြဿနာများကို ဖြေရှင်းခြင်းနှင့် အလိုအလျောက် လုပ်ဆောင်မှုများ ပြုလုပ်ပေးသည်။
ကုဒ်ဖန်ဆင်းနိုင်သော အေးဂျင့်များ
ကုဒ်ဖန်ဆင်းနိုင်သော အေးဂျင့်များသည် ဗျုဟာ AI မော်ဒယ်များကို အသုံးပြုကာ ကုဒ်ရေးခြင်းနှင့် တည်ဆောင်မှုများကို ပြုလုပ်သည်။ ဤအေးဂျင့်များက ရှုပ်ထွေးသော ပြဿနာများကို ဖြေရှင်းနိုင်ပြီး၊ လုပ်ငန်းများကို အလိုအလျောက် စနစ်တက် စီမံနိုင်ကာ၊ မတူညီသော programming ဘာသာစကားများဖြင့် ကုဒ်ဖန်ဆင်းအကောင်အထည်ဖော်ခြင်းဖြင့် တန်ဖိုးရှိသော သတင်းအချက်အလက်များကို ပေးစွမ်းနိုင်သည်။
အသုံးပြုနိုင်သည့် လုပ်ဆောင်ချက်များ
- အလိုအလျောက် ကုဒ်ဖန်ဆင်းခြင်း: တိကျသော အလုပ်များအတွက် ကုဒ် snippets များ ဖန်တီးခြင်း၊ ဥပမာ - ဒေတာစစ်ဆေးခြင်း၊ ဝဘ်ဆွက်ခြင်း သို့မဟုတ် စက်သင်ယူမှု။
- SQL ကို RAG အဖြစ် အသုံးပြုခြင်း: ဒေတာဘေ့စ်များမှ ဒေတာ ရယူ၊ ပြင်ဆင်ရန် SQL query များ အသုံးပြုခြင်း။
- ပြဿနာဖြေရှင်းခြင်း: တိကျသည့် ပြဿနာများကို ဖြေရှင်းရန် ကုဒ်ရေးသား၊ တည်ဆောင်ခြင်း၊ ဥပမာ - အယ်လ်ဂိုရिदမ်များ အာရုံစူးစိုက်ခြင်း သို့မဟုတ် ဒေတာစစ်တမ်း။
ဥပမာ: ဒေတာစစ်ဆေးမှုအတွက် ကုဒ်ဖန်ဆင်းနိုင်သော အေးဂျင့်
သင်ဟာ ကုဒ်ဖန်ဆင်းနိုင်သော အေးဂျင့်တစ်ခု ဒီဇိုင်းဆွဲနေသည်ဟု စဉ်းစားပါ။ ၎င်း၏ လုပ်ဆောင်ချက်မှာ -
- တာဝန်: ဒေတာစုစည်းမှုတစ်ခုကို စိစစ်ခွဲခြမ်းပြီး ရုပ်ပြအချက်အလက်နှင့် ပုံစံများ ဖော်ထုတ်ခြင်း။
- ခြေလှမ်းများ:
- ဒေတာစုစည်းမှုကို ဒေတာစစ်ဆေးရေးကိရိယာသို့ loading လုပ်ခြင်း။
- ဒေတာကို စိစစ်ပေးရန် SQL query များ ဖန်တီးခြင်း။
- Query များကို တည်ဆောင်ပြီး ရလဒ်များ ရယူခြင်း။
- ရလဒ်များ ဖြင့် ရုပ်ပြပုံနှင့် သတင်းအချက်အလက်များအား ဖန်တီးခြင်း။
- လိုအပ်သော အရင်းအမြစ်များ: ဒေတာစုစည်းမှု၊ ဒေတာစစ်ဆေးရေးကိရိယာများ၊ SQL အရည်အချင်းများ။
- အတွေ့အကြုံ: အရင်က စိစစ်မှုရလဒ်များကို အသုံးပြုကာ နောက်ပိုင်း စိစစ်မှုများအတွက် တိကျမှုနှင့် ကိုက်ညီမှု မြှင့်တင်ခြင်း။
ဥပမာ: ခရီးသွားအေးဂျင့်အတွက် ကုဒ်ဖန်ဆင်းခြင်း
ဤဥပမာတွင် ကျနော်တို့ ဟာ ခရီးသွားသူများအတွက် ခရီးစဉ် စီစဉ်ရာတွင် အကူအညီပေးနိုင်ရန် ကုဒ်ဖန်ဆင်းနိုင်သော “ခရီးသွားအေးဂျင့်” တစ်ခုကို ဒီဇိုင်းဆွဲပါမည်။ ဤအေးဂျင့်သည် ခရီးစဉ်ရွေးချယ်စရာများ ရယူခြင်း၊ ရလဒ်များ စစ်ထုတ်ခြင်းနှင့် ကျော်ကြားချက် စုစည်းခြင်းတို့ကို AI သုံး generative ကုဒ်ဖြင့် တည်ဆောင်ပေးနိုင်ပါသည်။
ကုဒ်ဖန်ဆင်းနိုင်သော အေးဂျင့်အား အနှစ်ချက်ချုပ်
- အသုံးပြုသူစိတ်ကြိုက် စုစည်းခြင်း: ရောက်မည့်နေရာ၊ ခရီးသွားသည့်ရက်များ၊ ဘတ်ဂျက်၊ ဆန္ဒများ စသဖြင့် အသုံးပြုသူ၏ ဝင်ရောက်ချက်များ စုဆောင်းခြင်း။
- ဒေတာ ရယူရန် ကုဒ် ဖန်ဆင်းခြင်း: လေကြောင်းလှည်း၊ ဟိုටယ်၊ အဆန်းကြီးစရာများ အကြောင်းအရာရယူရန် ကုဒ် snippets များ ဖန်တီးခြင်း။
- ဖန်တီးထားသည့် ကုဒ်များကို တည်ဆောင်ခြင်း: လက်ရှိ အချက်အလက် ရယူရန် ဖန်တီးထားသော ကုဒ်များကို အလိုအလျောက် ပြေးဆွဲပေးခြင်း။
- ခရီးစဉ် ဖန်တီးခြင်း: ရယူထားသော ဒေတာကို ကိုယ်ပိုင်ခရီးစဉ် အစီအစဉ်တစ်ခုအဖြစ် စုပေါင်းခြင်း။
- တုံ့ပြန်ချက်နှင့်အညီ ပြင်ဆင်ခြင်း: အသုံးပြုသူ၏ တုံ့ပြန်ချက် ရယူပြီး လိုအပ်သည့်အခါ ထပ်မံ ကုဒ်ဖန်ဆင်းပြီး ရလဒ်များ ပြင်ဆင်ခြင်း။
ခြေလှမ်းအလိုတစ်ခုချင်း ပြုလုပ်ခြင်း
-
အသုံးပြုသူစိတ်ကြိုက် စုစည်းခြင်း
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
ဒေတာ ရယူရန် ကုဒ် ဖန်ဆင်းခြင်း
def generate_code_to_fetch_data(preferences): # ဥပမာ- အသုံးပြုသူနှစ်သက်မှုအပေါ်အခြေခံပြီး လေကြောင်းခရီးစဉ်များရှာဖွေရန်ကုဒ်ဖန်တီးပါ code = f""" def search_flights(): import requests response = requests.get('https://api.example.com/flights', params={preferences}) return response.json() """ return code def generate_code_to_fetch_hotels(preferences): # ဥပမာ- ဟိုတယ်များကိုရှာဖွေရန်ကုဒ်ဖန်တီးပါ code = f""" def search_hotels(): import requests response = requests.get('https://api.example.com/hotels', params={preferences}) return response.json() """ return code -
ဖန်တီးထားသော ကုဒ်များကို တည်ဆောင်ခြင်း
def execute_code(code): # exec ကိုအသုံးပြု၍ ဖန်တီးထားသောကုတ်အား اجرا ဆောင်ရွက်ပါ။ exec(code) result = locals() return result travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) flight_code = generate_code_to_fetch_data(preferences) hotel_code = generate_code_to_fetch_hotels(preferences) flights = execute_code(flight_code) hotels = execute_code(hotel_code) print("Flight Options:", flights) print("Hotel Options:", hotels) -
ခရီးစဉ် ဖန်တီးခြင်း
def generate_itinerary(flights, hotels, attractions): itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary attractions = search_attractions(preferences) itinerary = generate_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary) -
တုံ့ပြန်ချက်အရ ဖြည့်စွက် ပြင်ဆင်ခြင်း
def adjust_based_on_feedback(feedback, preferences): # အသုံးပြုသူတုံ့ပြန်ချက်အရ သုံးစွဲမှုအနှစ်သာရများကိုချိန်ညှိပါ if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]} updated_preferences = adjust_based_on_feedback(feedback, preferences) # ဖော်ပြထားသောနောက်ဆုံးသတ်မှတ်ချက်များနှင့်အတူ ကုဒ်ကို ထပ်မံထုတ်လုပ်ပြီး အချိန်လိုက်ဆောင်ရွက်ပါ updated_flight_code = generate_code_to_fetch_data(updated_preferences) updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences) updated_flights = execute_code(updated_flight_code) updated_hotels = execute_code(updated_hotel_code) updated_itinerary = generate_itinerary(updated_flights, updated_hotels, attractions) print("Updated Itinerary:", updated_itinerary)
ပတ်ဝန်းကျင်သတိထားမှုနှင့် သဘောထားအခြေခံ ထုတ်လွှင့်မှု အသုံးချခြင်း
ဇယား schema ကို အသုံးပြု၍ သတိထားမှုနှင့် သဘောထားအခြေခံ ထုတ်လွှင့်မှုကို မြှင့်တင်ပေးခြင်းဖြင့် query ဖန်တီးမှုကို တိုးတက်စေပါသည်။
ဥပမာ:
- Schema ကို နားလည်ခြင်း: စနစ်သည် ဇယားစကီမားကို နားလည်ကာ query ဖန်တီးမှုအခြေ အထားကို ဖွဲ့စည်းပေးသည်။
- တုံ့ပြန်ချက်အပေါ် အခြေခံ ပြင်ဆင်ခြင်း: အသုံးပြုသူတုံ့ပြန်ချက်အပေါ် အခြေခံကာ schema ထဲတွင် ဘယ် field များပြင်ဆင်ရန်လိုသည်ကို သဘောထားထုတ်သည်။
- Query ဖန်တီးခြင်းနှင့် တည်ဆောင်ခြင်း: အသစ်ပြင်ဆင်ထားသော ဆန္ဒများအပေါ် အခြေခံကာ လေကြောင်းလှည်းနှင့် ဟိုတယ် ဒေတာကို ရှာဖွေရန် query များ ဖန်တီး၊ တည်ဆောင်ခြင်း။
ဤအတွေးများကို ထည့်သွင်းထားသည့် Python ကုဒ်နမူနာ -
def adjust_based_on_feedback(feedback, preferences, schema):
# အသုံးပြုသူတုံ့ပြန်ချက်အခြေပြု၍ နေရာချမှတ်ချက်များကို ချိန်ညှိပါ
if "liked" in feedback:
preferences["favorites"] = feedback["liked"]
if "disliked" in feedback:
preferences["avoid"] = feedback["disliked"]
# အခြားဆက်စပ်နေရာချမှတ်ချက်များကို ချိန်ညှိရန် schema အပေါ် အကြောင်းရင်းရှင်းလင်းချက်
for field in schema:
if field in preferences:
preferences[field] = adjust_based_on_environment(feedback, field, schema)
return preferences
def adjust_based_on_environment(feedback, field, schema):
# schema နှင့် တုံ့ပြန်ချက်များအပေါ် မှီခို၍ နေရာချမှတ်ချက်များကို ချိန်ညှိရန် ကိုယ်ပိုင် လက်ရှိမှု
if field in feedback["liked"]:
return schema[field]["positive_adjustment"]
elif field in feedback["disliked"]:
return schema[field]["negative_adjustment"]
return schema[field]["default"]
def generate_code_to_fetch_data(preferences):
# နေရာချမှတ်ချက်အသစ်များအပေါ်မှီ၍ စက်ပျော်မော်တော်ကွင်းအချက်အလက် ရယူရန်ကုဒ်ထုတ်လုပ်သည်
return f"fetch_flights(preferences={preferences})"
def generate_code_to_fetch_hotels(preferences):
# နေရာချမှတ်ချက်အသစ်များအပေါ်မှီ၍ ဟိုတယ်အချက်အလက် ရယူရန်ကုဒ်ထုတ်လုပ်သည်
return f"fetch_hotels(preferences={preferences})"
def execute_code(code):
# ကုဒ်စမ်းသပ် လည်ပတ်မှုကို အတုအယောင်ပြုပြီး ဒေတာတု များပြန်ပေးသည်
return {"data": f"Executed: {code}"}
def generate_itinerary(flights, hotels, attractions):
# လေကြောင်း၊ ဟိုတယ်နှင့် ဆွဲဆောင်မှုများကို အခြေခံ၍ ခရီးစဉ် ပြုစုသည်
return {"flights": flights, "hotels": hotels, "attractions": attractions}
# schema နမူနာ
schema = {
"favorites": {"positive_adjustment": "increase", "negative_adjustment": "decrease", "default": "neutral"},
"avoid": {"positive_adjustment": "decrease", "negative_adjustment": "increase", "default": "neutral"}
}
# အသုံးပြုနမူနာ
preferences = {"favorites": "sightseeing", "avoid": "crowded places"}
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_preferences = adjust_based_on_feedback(feedback, preferences, schema)
# နေရာချမှတ်ချက်အသစ်များနှင့် နောက်မပေါ်လည်ကုဒ်ကို ထပ်မံပြုလုပ် လည်ပတ်သည်
updated_flight_code = generate_code_to_fetch_data(updated_preferences)
updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences)
updated_flights = execute_code(updated_flight_code)
updated_hotels = execute_code(updated_hotel_code)
updated_itinerary = generate_itinerary(updated_flights, updated_hotels, feedback["liked"])
print("Updated Itinerary:", updated_itinerary)
သွားစဉ် တံု့ပြန်ချက်ပေါ် အခြေခံ ရောကြပ်မှု ရှင်းလင်းချက်
- Schema သတိထားမှု:
schemadictionary သည် တုံ့ပြန်ချက်အပေါ် အခြေခံကာ စိတ်ကြိုက်ပြင်ဆင်မှုများကို ဖော်ပြသည်။ favorites နှင့် avoid ကဲ့သို့သော field များပါဝင်သည်။ - စိတ်ကြိုက် ပြင်ဆင်ခြင်း (
adjust_based_on_feedbackmethod): ဤနည်းလမ်းမှ စိတ်ကြိုက်ပြင်ဆင်မှုများကို အသုံးပြုသူတုံ့ပြန်ချက်အပေါ် အခြေခံပြီး ပြင်ဆင်သည်။ - ပတ်ဝန်းကျင်အခြေခံ ပြင်ဆင်ခြင်း (
adjust_based_on_environmentmethod): schema နှင့် တုံ့ပြန်ချက်အပေါ် မူတည်၍ ပြင်ဆင်ခြင်းကို စိတ်ကြိုက် ပြုလုပ်သည်။ - Query ဖန်တီးခြင်းနှင့် တည်ဆောင်ခြင်း: ပြင်ဆင်ပြီးသော စိတ်ကြိုက်ဆန္ဒအပေါ် အခြေခံကာ လေကြောင်းနှင့် ဟိုတယ်ဒေတာရယူရန် code ဖန်တီးပြီး query များကို စိတ်ကူးကောင်းစွာ တည်ဆောင်ကြသည်။
- ခရီးစဉ် ဖန်တီးခြင်း: လေကြောင်း၊ ဟိုတယ်နှင့် အတန်းစားနေရာဒေတာအသစ် ကို အခြေခံကာ ခရီးစဉ် အသစ် ဖန်တီးပေးသည်။
စနစ်ကို ပတ်ဝန်းကျင်သတိထားမှုနှင့် schema အပေါ် အခြေခံသဘောထားဖြင့် လုပ်ဆောင်ရန်ရေးသားခြင်းဖြင့် နှိုင်းယှဉ်တိုင်း query များပိုတိကျပြီး user အတွက် ပိုမိုကိုက်ညီသည့် ခရီးညွှန်ကြားချက်များ ရရှိစေပါသည်။
SQL ကို Retrieval-Augmented Generation (RAG) နည်းဖြင့် အသုံးပြုခြင်း
SQL (Structured Query Language) သည် ဒေတာဘေ့စ်များနှင့် ပူးပေါင်းဆောင်ရွက်ရန် အင်အားကြီးသော ကိရိယာဖြစ်သည်။ RAG နည်းစနစ်၏ တစ်စိတ်တစ်ပိုင်းအဖြစ် အသုံးပြုသည့်အခါ SQL သည် ဒေတာဘေ့စ်မှ သက်ဆိုင်ရာ ဒေတာကို ရယူ၍ AI အေးဂျင့်များအနေဖြင့် တုံ့ပြန်ချက် များဖြစ်ပေါ်စေရန် သို့မဟုတ် လုပ်ဆောင်ချက်များ ထုတ်လုပ်နိုင်ရန် အသုံးပြုသည်။ ခရီးသွားအေးဂျင့်၏ သဘောတရားတွင် SQL ကို RAG နည်းဖြစ် သုံးပုံကို လေ့လာကြရအောင်။
အဓိက သဘောထားများ
- ဒေတာဘေ့စ် ပူးပေါင်းခြင်း:
- SQL ကို ဒေတာဘေ့စ်များ query ချရန် အသုံးပြုကာ သက်ဆိုင်ရာ သတင်းအချက်အလက်များ ရယူသည်။
- ဥပမာ - လေကြောင်းသတင်းအချက်အလက်၊ ဟိုတယ်အချက်အလက်နှင့် အလိုအလျောက်သွားရောက်သင့်ရာနေရာများ ရယူခြင်း။
- RAG နှင့် ပေါင်းစပ်ခြင်း:
- အသုံးပြုသူ၏ ဝင်ရောက်ချက် နှင့် စိတ်ကြိုက်များအပေါ် အခြေခံကာ SQL query များ ဖန်တီးသည်။
- ရယူထားသည့် ဒေတာကို ကိုယ်ပိုင် အကြံပြုချက် သို့မဟုတ် လုပ်ဆောင်ချက်များ ဖန်တီးရန် အသုံးပြုသည်။
- Dynamic Query ဖန်တီးခြင်း:
- AI အေးဂျင့်သည် အခြေအနေ နှင့် အသုံးပြုသူ လိုအပ်ချက်များအပေါ် အခြေခံကာ dynamic SQL query များ ဖန်တီးသည်။
- ဥပမာ - ဘတ်ဂျက်၊ ရက်များနှင့် စိတ်ဝင်စားမှုများအပေါ် အခြေခံကာ query များ စိတ်ကြိုက်လုပ်ဆောင်ခြင်း။
အသုံးပြုမှုများ
- အလိုအလျောက် ကုဒ်ဖန်တီးခြင်း: တိကျသော တာဝန်များအတွက် code snippets များ ဖန်တီးခြင်း။
- SQL ကို RAG အဖြစ်အသုံးပြုခြင်း: ဒေတာ ပြင်ဆင်မှုလုပ်ရပ်များအတွက် SQL query များ အသုံးပြုခြင်း။
- ပြဿနာဖြေရှင်းခြင်း: ပြဿနာများကို ဖြေရှင်းရန် ကုဒ်ဖန်တီးခြင်းနှင့် တည်ဆောင်ခြင်း။
ဥပမာ: ဒေတာစစ်ဆေးရေးအေးဂျင့် -
- တာဝန်: ဒေတာစုစည်းမှုကို စိစစ်ပြီး နောက်တိုးတက်မှုများ ရှာဖွေခြင်း။
- ခြေလှမ်းများ:
- ဒေတာစုစည်းမှုကို load လုပ်ခြင်း။
- ဒေတာကို စစ်ထုတ်ရန် SQL query များ ဖန်တီးခြင်း။
- Query များ ထုတ်ကာ ရလဒ် ရယူခြင်း။
- ရုပ်ပြပုံနှင့် သတင်းအချက်အလက်များ ဖန်တီးခြင်း။
- အရင်းအမြစ်များ: ဒေတာစုစည်းမှုရယူခွင့်၊ SQL အရည်အချင်း။
- အတွေ့အကြုံ: ယခင် ရလဒ်များကို အသုံးပြုကာ နောက်တိုးတက်မှုများအတွက်အဆင်ပြေ ပြုပြင်ခြင်း။
ဒီဇိုင်းဥပမာ: ခရီးသွားအေးဂျင့်တွင် SQL အသုံးပြုခြင်း
-
အသုံးပြုသူ စိတ်ကြိုက် စုစည်းခြင်း
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
SQL Query များ ဖန်တီးခြင်း
def generate_sql_query(table, preferences): query = f"SELECT * FROM {table} WHERE " conditions = [] for key, value in preferences.items(): conditions.append(f"{key}='{value}'") query += " AND ".join(conditions) return query -
SQL Query များ တည်ဆောင်ခြင်း
import sqlite3 def execute_sql_query(query, database="travel.db"): connection = sqlite3.connect(database) cursor = connection.cursor() cursor.execute(query) results = cursor.fetchall() connection.close() return results -
အကြံပြုချက်များ ဖန်တီးခြင်း
def generate_recommendations(preferences): flight_query = generate_sql_query("flights", preferences) hotel_query = generate_sql_query("hotels", preferences) attraction_query = generate_sql_query("attractions", preferences) flights = execute_sql_query(flight_query) hotels = execute_sql_query(hotel_query) attractions = execute_sql_query(attraction_query) itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) itinerary = generate_recommendations(preferences) print("Suggested Itinerary:", itinerary)
SQL Query များ ဥပမာ
-
လေကြောင်း Query
SELECT * FROM flights WHERE destination='Paris' AND dates='2025-04-01 to 2025-04-10' AND budget='moderate'; -
ဟိုတယ် Query
SELECT * FROM hotels WHERE destination='Paris' AND budget='moderate'; -
အဆန်းကြီးနေရာ Query
SELECT * FROM attractions WHERE destination='Paris' AND interests='museums, cuisine';
SQL ကို Retrieval-Augmented Generation (RAG) နည်းစနစ်၏ တစိတ်တစိတ်အဖြစ် အသုံးပြုခြင်းအားဖြင့် ခရီးသွားအေးဂျင့်များက သက်ဆိုင်ရာ ဒေတာကို dynamic ရယူသုံးစွဲကာ မျှော်မှန်းချက်မှန်ကန်ပြီး ကိုယ်ပိုင် ပြင်ဆင်မှုများ ပေးစွမ်းနိုင်သည်။
Metacognition ၏ ဥပမာ
ဒါဆို metacognition ကို အကောင်အထည်ဖော်မည့် အနည်းငယ် ရေးဆွဲသူအေးဂျင့်တစ်ခု ဖန်တီးကြမယ်၊ ၎င်းသည် ပြဿနာတစ်ခုကို ဖြေရှင်းရာ ရွေးချယ်မှုလုပ်ငန်းစဉ်ကို သွားရောက် ကြည့်ရှု သုံးသပ်ပြီး စနစ်တကျ ပြင်ဆင်သည်။
ဤဥပမာတွင် အေးဂျင့်သည် စျေးနှုန်း နှင့် အရည်အသွေးပြည့်စုံမှုတို့ကို အခြေခံပြီး ဟိုတယ်ရွေးချယ်သည်၊ ဒါပေမယ့် ၎င်း၏ ဆုံးဖြတ်မှုများကို “reflect” ပြုလုပ်ကာ မမှန်ကန်မှု သို့မဟုတ် ထိရောက်မှု နည်းပါးမှုရှိသည်ဆိုပါက ၎င်း၏ နည်းစနစ်ကို ပြန်လည်ပြင်ဆင်သည်။
ဤသွားရာ၌ -
- ပထမဆုံးဆုံးဖြတ်ချက်: အထိအရေးအနည်းဆုံး ဟိုတယ်ကို ရွေးချယ်သည်၊ အရည်အသွေးအပေါ် သဘော မသိဘဲ။
- သုံးသပ် စဉ်းစားမှု: ပထမဆုံးရွေးချယ်မှု ပြီးနောက်၊ အသုံးပြုသူတုံ့ပြန်ချက်အရ ဟိုတယ်၏ အရည်အသွေး မကောင်းမှု ရှိသလား စစ်ဆေးသည်။
- နည်းစနစ်ပြင်ဆင်ခြင်း: သုံးသပ်မှုအပေါ် အခြေခံကာ နည်းစနစ် ပြင်ဆင်ပြီး “အနည်းဆုံးစျေး” မှ “အရည်အသွေးအမြင့်ဆုံး” သို့ ပြောင်းပြီး ရွေးချယ်မှု ကောင်းမွန်အောင် တိုးတက်စေသည်။
ဥပမာ -
class HotelRecommendationAgent:
def __init__(self):
self.previous_choices = [] # ယခင်ကရွေးချယ်ခဲ့သောဟိုတယ်များကိုသိမ်းဆည်းထားသည်
self.corrected_choices = [] # ပြင်ဆင်ထားသောရွေးချယ်မှုများကိုသိမ်းဆည်းထားသည်
self.recommendation_strategies = ['cheapest', 'highest_quality'] # ရနိုင်သော မဟာဗျူဟာများ
def recommend_hotel(self, hotels, strategy):
"""
Recommend a hotel based on the chosen strategy.
The strategy can either be 'cheapest' or 'highest_quality'.
"""
if strategy == 'cheapest':
recommended = min(hotels, key=lambda x: x['price'])
elif strategy == 'highest_quality':
recommended = max(hotels, key=lambda x: x['quality'])
else:
recommended = None
self.previous_choices.append((strategy, recommended))
return recommended
def reflect_on_choice(self):
"""
Reflect on the last choice made and decide if the agent should adjust its strategy.
The agent considers if the previous choice led to a poor outcome.
"""
if not self.previous_choices:
return "No choices made yet."
last_choice_strategy, last_choice = self.previous_choices[-1]
# ယခင်ရွေးချယ်မှုကောင်းမှ မကောင်းမှ များကို အသုံးပြုသူမှတုံ့ပြန်ချက်ရှိသည်ဟု ဦးစားပေးစဉ်းစားကြမည်
user_feedback = self.get_user_feedback(last_choice)
if user_feedback == "bad":
# ယခင်ရွေးချယ်မှု မကျေနပ်သည့်အချိန် မဟာဗျူဟာကိုတပ်ဆင်သည်
new_strategy = 'highest_quality' if last_choice_strategy == 'cheapest' else 'cheapest'
self.corrected_choices.append((new_strategy, last_choice))
return f"Reflecting on choice. Adjusting strategy to {new_strategy}."
else:
return "The choice was good. No need to adjust."
def get_user_feedback(self, hotel):
"""
Simulate user feedback based on hotel attributes.
For simplicity, assume if the hotel is too cheap, the feedback is "bad".
If the hotel has quality less than 7, feedback is "bad".
"""
if hotel['price'] < 100 or hotel['quality'] < 7:
return "bad"
return "good"
# ဟိုတယ်စာရင်း (စျေးနှုန်းနှင့် အရည်အသွေး) ကို မှော်တုဆောင်ရန်
hotels = [
{'name': 'Budget Inn', 'price': 80, 'quality': 6},
{'name': 'Comfort Suites', 'price': 120, 'quality': 8},
{'name': 'Luxury Stay', 'price': 200, 'quality': 9}
]
# မိတ်ဆက်ထားသော တာဝန်ရှိသူအား ဖန်တီးရန်
agent = HotelRecommendationAgent()
# ခြေလှမ်း ၁: တာဝန်ရှိသူသည် "အဆင့်ဆုံးစျေးနှုန်း" မဟာဗျူဟာဖြင့် ဟိုတယ်တစ်ခုကို အကြံပြုသည်
recommended_hotel = agent.recommend_hotel(hotels, 'cheapest')
print(f"Recommended hotel (cheapest): {recommended_hotel['name']}")
# ခြေလှမ်း ၂: တာဝန်ရှိသူသည် ရွေးချယ်မှုအား သုံးသပ်ပြီး လိုအပ်လျှင် မဟာဗျူဟာကို ပြန်လည်သွားကြသည်
reflection_result = agent.reflect_on_choice()
print(reflection_result)
# ခြေလှမ်း ၃: တာဝန်ရှိသူသည် ပြင်ဆင်ထားသော မဟာဗျူဟာဖြင့် ထပ်မံအကြံပြုသည်
adjusted_recommendation = agent.recommend_hotel(hotels, 'highest_quality')
print(f"Adjusted hotel recommendation (highest_quality): {adjusted_recommendation['name']}")
အေးဂျင့်၏ Metacognition တတ်မှုများ
အဓိကမှာ အေးဂျင့်သည် -
- ၎င်း၏ ယခင်ရွေးချယ်မှုများနှင့် ဆုံးဖြတ်မှုလုပ်ငန်းစဉ်ကို သုံးသပ်နိုင်မှု။
- သုံးသပ်ခြင်းကို အခြေခံကာ နည်းစနစ် ပြင်ဆင်စေရန့် တတ်နိုင်မှုဖြစ်သည်။
ဤသည်သည် စနစ်အတွင်း feedback ပေါ်မူတည်၍ ၎င်း၏ သဘောထားကို ပြင်ဆင်နိုင်သည့် metacognition ၏ ရိုးရှင်းဆုံးပုံစံတစ်ခုဖြစ်သည်။
နိဂုံးချုပ်
Metacognition သည် AI အေးဂျင့်များ၏ စွမ်းရည်များ အား တိုးတက်စေသည့် အင်အားကြီးသော ကိရိယာဖြစ်သည်။ metacognitive လုပ်ငန်းစဉ်များကို ထည့်သွင်းခြင်းဖြင့် ပိုမို ဉာဏ်မြင့်ပြီး၊ လိုက်လျောညီထွေရှိသော ရလဒ်များ ထုတ်ပေးနိုင်သော အေးဂျင့်များ ဖန်တီးနိုင်သည်။ metacognition ၏ စိတ်ဝင်စားဖွယ် အကမ္ဘာအတွင်း ပို၍ လေ့လာလိုပါက ထပ်မံ ရရှိနိုင်သည့် အရင်းအမြစ်များကို အသုံးချပါ။
Metacognition ဒီဇိုင်း ပုံစံနှင့် ပတ်သက်၍ မေးခွန်းများ ရှိပါသလား?
သင်တန်းသား အခြားများနှင့် တွေ့ဆုံရန်၊ office hours တွင် တက်ရောက်ရန်နှင့် AI အေးဂျင့်များနှင့် ပတ်သက်သည့် မေးခွန်းများ ဖြေကြားလိုပါက Microsoft Foundry Discord တွင် ပါဝင်ဆွေးနွေးနိုင်သည်။
ယခင် ဘာသာရပ်
နောက်ဖြစ်မည့် ဘာသာရပ်
AI အေးဂျင့်များ ထုတ်လုပ်ရာတွင်
အတည်မပြုချက်
ဤစာတမ်းကို AI ဘာသာပြန်မှုဝန်ဆောင်မှု Co-op Translator အား အသုံးပြု၍ ဘာသာပြန်ထားပါသည်။ မှန်ကန်မှုကို ကြိုးစားသော်လည်း၊ အလိုအလျောက် ဘာသာပြန်ချက်များတွင် အမှား သို့မဟုတ် မမြင်သာမှုများ ရှိနိုင်ကြောင်း သတိပြုပါရန် တောင်းဆိုပါသည်။ မူလစာတမ်းကို မူလဘာသာစကားဖြင့်သာ အတည်ပြုအသိအမှတ်ပြုရမည့် အရင်းအမြစ်အဖြစ်ယူဆရန် လိုအပ်ပါသည်။ အရေးပါသည့် အချက်အလက်များအတွက် သင့်တော်သော လူကိုယ်တိုင် ဘာသာပြန်မှုကို အကြံပြုပါသည်။ ဤဘာသာပြန်ချက်ကို အသုံးပြုရာမှ ဖြစ်ပေါ်သော မမှန်ကန်မှုများ သို့မဟုတ် မနားမလည်မှုများအတွက် ကျွန်ုပ်တို့သည် တာဝန်မယူပါ။