ai-agents-for-beginners
Context အင်ဂျင်နီယာ အတွက် AI Agents

(ဒီပုံကို နှိပ်၍ သင်ခန်းစာ၏ ဗီဒီယိုကို ကြည့်ပါ)
သင်တည်ဆောက်လိုက်တဲ့ AI agent အတွက် အက်ပလီကေးရှင်းရဲ့ ရှုပ်ထွေးမှုကို နားလည်ခြင်းဟာ ယုံကြည်စိတ်ချရတဲ့ agent တစ်ခု တည်ဆောက်ဖို့ အရေးကြီးပါတယ်။ prompt engineering ထက် ပို၍ ကျယ်ပြန့်သော လိုအပ်ချက်များကို ဖြေရှင်းနိုင်ရန်အတွက် သတင်းအချက်အလက်ကို ထိရောက်စွာ စီမံနိုင်တဲ့ AI Agents များ ဖန်တီးရမှာ ဖြစ်ပါတယ်။
ဒီသင်ခန်းစာမှာ context engineering ဆိုတာဘာလဲ၊ AI agents တည်ဆောက်ရာမှာ ၎င်းရဲ့ တာဝန်ဘာလဲ ဆိုတာများကို ကြည့်ရှုပါမယ်။
နိဒါန်း
ဒီသင်ခန်းစာမှာ ဖော်ပြမယ့်အချက်များမှာ -
• Context အင်ဂျင်နီယာ ဆိုတာ ဘာလဲ နှင့် prompt engineering ထက် မတူကွဲပြားမှု။
• ထိရောက်တဲ့ Context အင်ဂျင်နီယာ့နည်းလမ်းများ — အချက်အလက်ရေးသားခြင်း၊ ရွေးချယ်ခြင်း၊ ဖိချုပ်ခြင်းနှင့် သီးခြားထားခြင်းတို့ကို ဘယ်လိုလုပ်မလဲ။
• AI agent များအတွက် ဖြစ်တတ်တဲ့ context ပျက်ကွက်မှုများ နှင့် ၎င်းတို့ကို ဘယ်လိုပြင်ဆင်မလဲ။
သင်ယူမည့်ရည်မှန်းချက်များ
ဒီသင်ခန်းစာကိုပြီးမြောက်ပြီးနောက် သင်မှာ သိရှိနိုင်ပါမယ် -
• context အင်ဂျင်နီယာကို အဓိပ္ပါယ် ချမှတ်ခြင်း နှင့် prompt engineering ထက် ဘယ်လိုကွာခြားသလဲဆိုတာ ခြားနားစွာ ဖော်ထုတ်နိုင်ခြင်း။
• Large Language Model (LLM) အပလီကေးရှင်းများတွင် context ၏ အဓိက အစိတ်အပိုင်းများကို ဖော်ထုတ်နိုင်ခြင်း။
• agent စွမ်းဆောင်ရည် တိုးတက်အောင် context ကို ရေးသား၊ ရွေးချယ်၊ ဖိချုပ်နှင့် သီးခြားထားခြင်းနည်းလမ်းများကို အသုံးချနိုင်ခြင်း။
• context poisoning, distraction, confusion, နှင့် clash ကဲ့သို့သော ပျက်ကွက်ချက်များကို အလင်းပေးသိရှိပြီး ထိန်းချုပ်နည်းများကို အကောင်အထည်ဖော်နိုင်ခြင်း။
Context အင်ဂျင်နီယာ ဆိုတာ ဘာလဲ?
AI Agents အတွက် context ဆိုတာက AI Agent သည် အချိန်ပေါ်အာဏာပေးပြီး အချိုးအစားတခုချင်းဆီ သက်ဆိုင်ရာ လုပ်ဆောင်ချက်များ ဆောင်ရွက်ဖို့ စီမံချက်များကို ဖြန့်ချိစေသော သတင်းအချက်အလက်များ ဖြစ်ပါတယ်။ Context အင်ဂျင်နီယာ ဆိုတာက AI Agent အဖို့ နောက်တစ်ခြေ လုပ်ဆောင်ရန် လိုအပ်သည့် မွန်ကန်တဲ့ သတင်းအချက်အလက်တွေကို သေချာစေရန် အလုပ်လုပ်ခြင်း ဖြစ်ပါတယ်။ Context window ကိုယ်ပိုင် အရွယ်အစားက ကန့်သတ်ထားလို့ agent တည်ဆောက်သူများအနေနဲ့ context window ထဲသို့ သတင်းအချက်အလက် ထည့်ခြင်း၊ ဖယ်ရှားခြင်း နှင့် စုပေါင်းဖိချုပ်ခြင်းတို့ကို စီမံခန့်ခွဲဖို့ စနစ်များနှင့် လုပ်ထုံးလုပ်နည်းများကို ဖန်တီးရပါမယ်။
Prompt အင်ဂျင်နီယာ နှင့် Context အင်ဂျင်နီယာ
Prompt အင်ဂျင်နီယာ ဟာ တစ်ခါသတ်မှတ်ထားသော static အညွှန်းတစ်ခုဆီကို အာရုံစိုက်ပြီး AI Agents ကို စည်းမျဉ်းတွေဖြင့် ထိရောက်စွာ ဦးတည်ပေးရန် အလေးပေးပါတယ်။ Context အင်ဂျင်နီယာ ကတော့ အစပြု prompt ကိုလည်းပါဝင်စေပြီး အချိန်တလျှောက်တွင် agent ကို လိုအပ်သလို ထောက်ပံ့ဖို့ dynamic အချက်အလက်အစုအဝေးကို မည်သို့ စီမံမလဲ ဆိုတာပေါ် အာရုံစိုက်ပါတယ်။ Context အင်ဂျင်နီယာ၏ အဓိက ရည်ရွယ်ချက်မှာ ဒီလုပ်ငန်းစဉ်ကို မကြာမီ ထပ်ဆင့်ကျွမ်းကျင်စေပြီး ယုံကြည်စိတ်ချစေရန် ဖြစ်ပါတယ်။
Context အမျိုးအစားများ
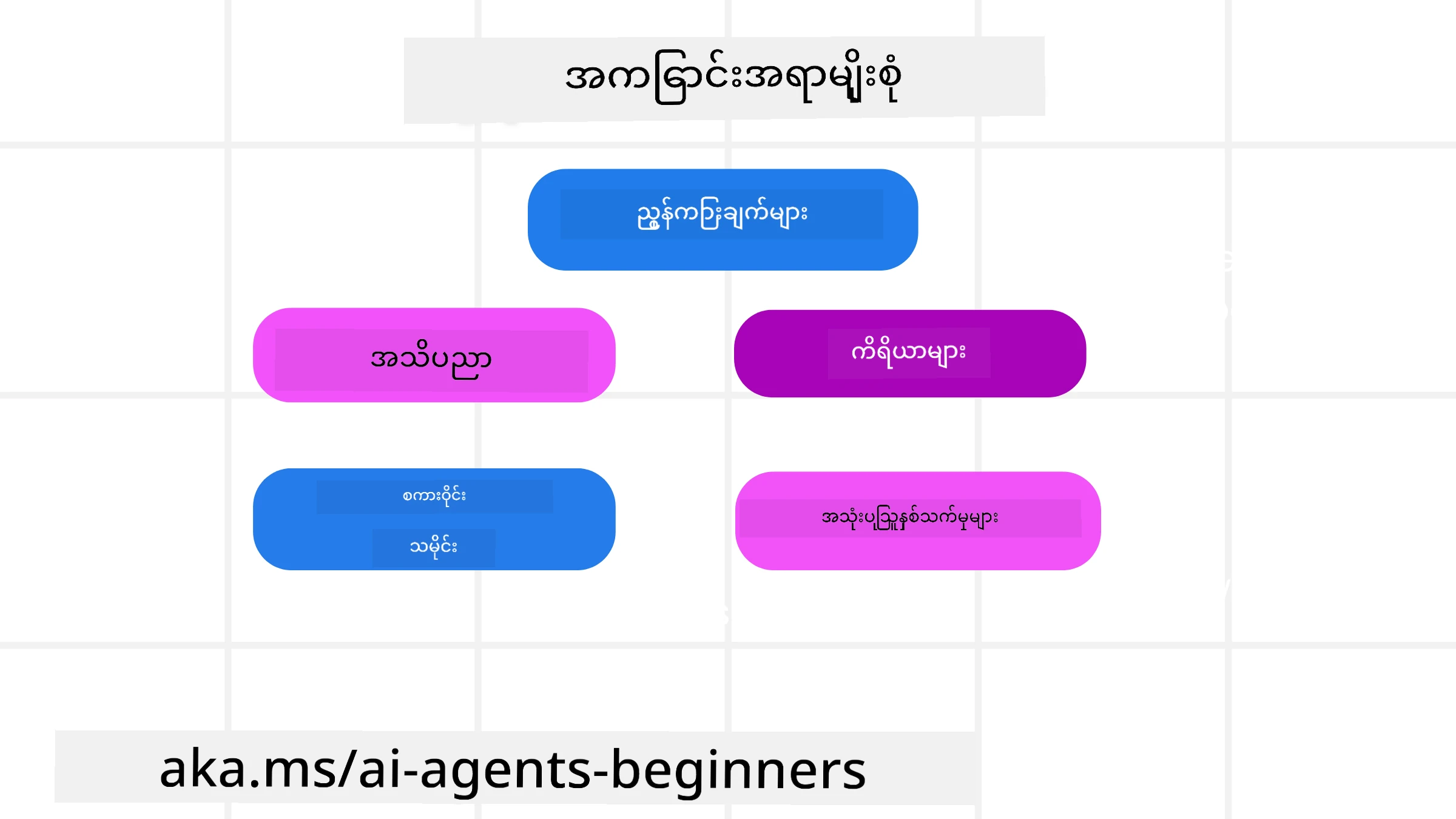
Context ဟာ တစ်မျိုးတည်းမဟုတ်ဘူး ဆိုတာကို သတိပြုရပါမယ်။ AI Agent ရဲ့ လိုအပ်ချက်အတွက် သတင်းအချက်အ လက်တွေ ဆိုသည်မှာ မတူညီတဲ့ အရင်းအမြစ်များကနေ ရရှိနိုင်ပြီး agent ကို ၎င်းအရင်းအမြစ်တွေကို ရရှိခွင့်ကောင်းစေဖို့ ကျွန်တော်တို့ဆောင်ရွက်ရပါမယ်။
AI agent တစ်ခု စီမံရလိမ့်မည့် context အမျိုးအစားများမှာ -
• အညွှန်းများ (Instructions): ၎င်းတွေက agent ရဲ့ “စည်းမျဉ်း” တွေလိုပါပဲ — prompts, system messages, few-shot examples (AI ကို ဘယ်လိုလုပ်ရမလဲ ဆိုတာ ပြသပေးသည့် နမူနာများ), နှင့် ၎င်းအသုံးချနိုင်မည့် tools များကို ဖော်ပြထားသော ဖော်ပြချက်များ။ ဤနေရာမှာ prompt engineering ၏ အချက်အလက်များနှင့် context engineering ၏ အလေးထားချက်တွေ ပေါင်းစပ်နေပါတယ်။
• အသိပညာ (Knowledge): အချက်အလက်များ၊ ဒေတာဘေ့စ်များမှ ရယူထားသော သတင်းအချက်အလက်များ သို့မဟုတ် agent ရဲ့ ရေရှည်မှတ်ဉာဏ်များပါဝင်ပါတယ်။ agent သည် မတူညီသော knowledge store များနှင့် ဒေတာဘေ့စ်များကို အသုံးချရန် လိုအပ်ပါက Retrieval Augmented Generation (RAG) စနစ်ကို ပေါင်းစည်းထားနိုင်ပါတယ်။
• Tools: ၎င်းတို့က agent သုံးနိုင်သော မိတ်ဆက်ပြထားသော functions အပြင် APIs နှင့် MCP Servers များ၏ นิยามများ ဖြစ်ပြီး၊ သုံးစွဲပြီးရလဒ်များကိုလည်း ပြန်လည်ထောက်ပြပေးပါတယ်။
• စကားလက်ခံမှတ်တမ်း (Conversation History): အသုံးပြုသူနှင့် ဆက်သွယ်နေသည့် ongoing ဆက်သွယ်မှုများ။ အချိန်ကြာလာရာနှင့်အမျှ ဤစကားလက်ခံမှတ်တမ်းများဟာ အရှည်များလာပြီး ပိုမိုရှုပ်ထွေးလာပြီး context window မှာနေရာယူလာပါတယ်။
• အသုံးပြုသူ အသိပညာနှစ်သက်ချက်များ (User Preferences): အချိန်ကြာလာခြင်းနှင့်အမျှ အသုံးပြုသူ၏ နှစ်သက်ငြိမ်းချမ်းမှုများကို သင်ယူထားသော အချက်အလက်များ။ ဤအချက်အလက်များကို သိမ်းဆည်းထားပြီး အချက်အလက်အရေးပါဆုံးဆုံးသော ဆုံးဖြတ်ချက်များမှာ အသုံးပြုသူအတွက် အသုံးချနိုင်သည်။
ထိရောက်တဲ့ Context အင်ဂျင်နီယာ အတွက် နည်းဗျုဟာများ
စီစဉ်ရေးရာ နည်းဗျုဟာများ
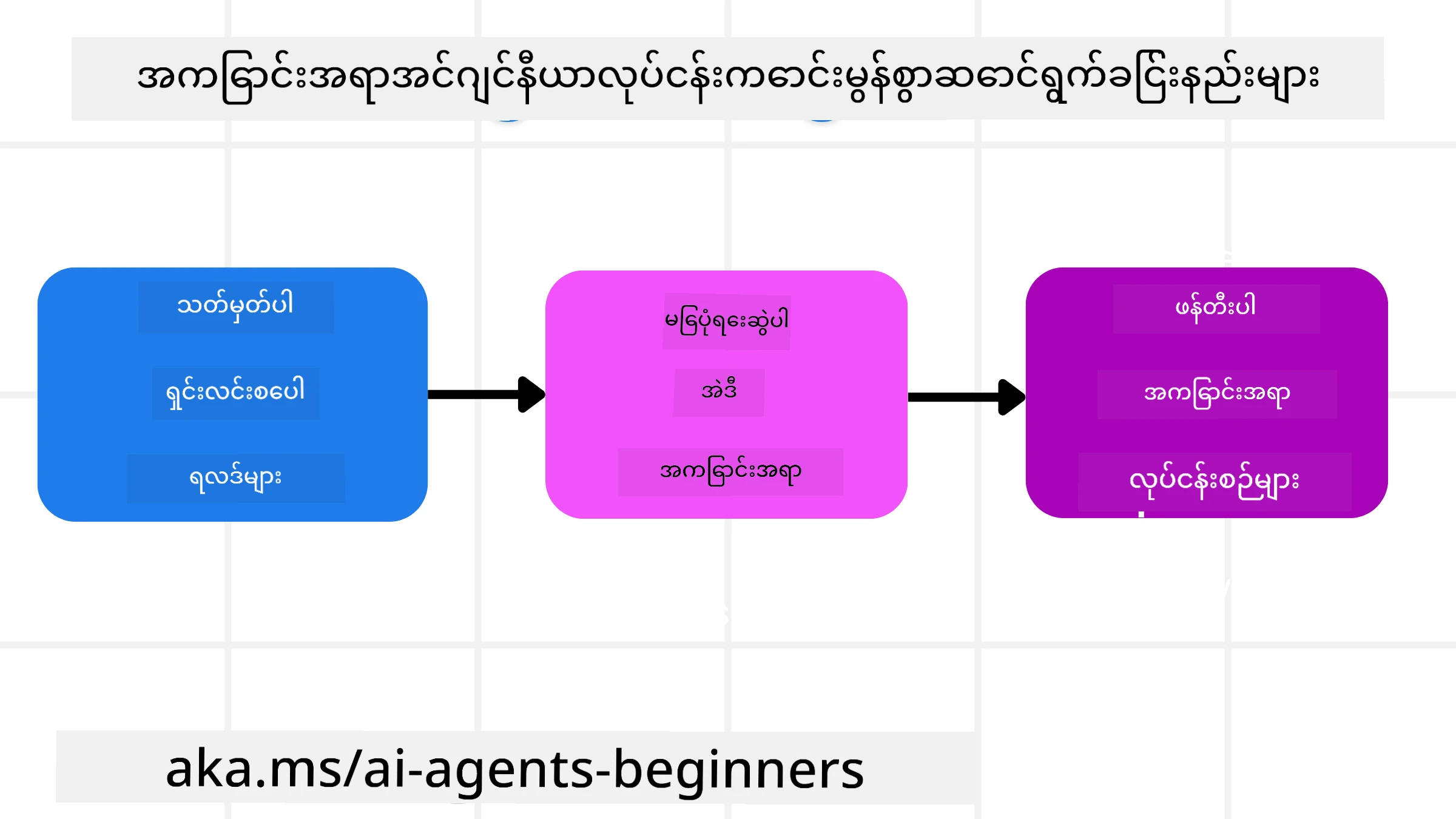
ကောင်းမွန်တဲ့ context အင်ဂျင်နီယာဟာ ကောင်းမွန်တဲ့ စီစဉ်ရေးမှ စတင်ပါသည်။ context အင်ဂျင်နီယာ ကို အကောင်အထည်ဖော်ဖို့ စဉ်းစားရမယ့် နည်းလမ်းတစ်ခုကတော့ အောက်ပါပုံစံဖြစ်ပါတယ် -
- ရလဒ်အသေအချာ သတ်မှတ်ပါ - AI Agents များ ကို ပေးအပ်မယ့် လုပ်ငန်းရလဒ်များကို ရှင်းလင်းသတ်မှတ်ထားရပါမယ်။ “AI Agent ထားလက်အလုပ်ပြီးဆုံးတဲ့အခါ ကမ္ဘာကြီး ဘယ်လိုဖြစ်နေပါလိမ့်မလဲ?” ဆိုတဲ့ မေးခွန်းကို ဖြေရှင်းပါ။ အနက်တစ်ခုပြောရမယ်ဆိုရင် အသုံးပြုသူသည် AI Agent နှင့် မထိတွေ့ခင်နှင့် ပြီးနောက် ဘာပြောင်းလဲမှု၊ သတင်းအချက်အလက် သို့မဟုတ် မည်သည့် တုံ့ပြန်ချက်ကို ရရှိသင့်သလဲ ဆိုတာကို ကိုယ်စားပြုပါတယ်။
- Context ကို မြေပုံဆွဲပါ - AI Agent ရဲ့ ရလဒ်များကို သတ်မှတ်ထားပြီးနောက် “AI Agent က ဒီလုပ်ငန်းကို ပြီးမြောက်ရန် ဘယ်အချက်အလက်တွေ လိုအပ်လဲ?” ဆိုတဲ့ မေးခွန်းကို ဖြေရှင်းရပါမယ်။ ဒီလိုနဲ့ သင့်အား ထိုသတင်းအချက်အလက်တွေ ဘယ်မှာ ရှိနိုင်လဲ ဆိုတာကို မြေပုံအနေနဲ့ ဆွဲထုတ်နိုင်မှာဖြစ်ပါတယ်။
- Context Pipelines ဖန်တီးပါ - သင်သိရှိထားတဲ့ သတင်းအချက်အလက်တွေ ဘယ်လို Agent ထံရောက်မလဲဆိုတာကို ဖြေရှင်းရပါမယ်။ ဤလုပ်ငန်းကို RAG, MCP servers အသုံးပြုခြင်းနှင့် အခြား tools များစသဖြင့် မတူညီသော နည်းလမ်းများဖြင့် ဖန်တီးနိုင်ပါတယ်။
လက်တွေ့အသုံးပြုနိုင်သော နည်းဗျုဟာများ
စီစဉ်ရေးက အရေးကြီးပေမယ့် သတင်းအချက်အလက်တွေက agent ရဲ့ context window ထဲသို့ စီးဆင်းလာသော်လည်း၊ ၎င်းအား စီမံရန် လက်တွေ့နည်းလမ်းများလိုအပ်ပါတယ်။
Context ကို စီမံခြင်း
အချို့သော သတင်းအချက်အလက်များကို context window ထဲသို့ အလိုအလျောက်ထည့်သွင်းမည်ဖြစ်သော်လည်း context အင်ဂျင်နီယာက ဒီသတင်းအချက်အလက်တွေကို ပိုမိုတက်ကြွစွာ စီမံခြင်းအပေါ် အာရုံစိုက်ပါတယ်၊ ၎င်းကို အောက်ပါ နည်းလမ်းအချို့ဖြင့်လုပ်ဆောင်နိုင်ပါသည် -
-
Agent Scratchpad ဤနည်းလမ်းက AI Agent တစ်ခုအနေဖြင့် single session အတွင်း ချိန်ဆွဲမှုများနှင့် အသုံးပြုသူအပြန်အလှန်များအကြောင်း သက်ဆိုင်ရာ မှတ်စုများ ယူနိုင်စေပါတယ်။ ဤ scratchpad သည် context window အပြင် ဖိုင်တစ်ခု သို့မဟုတ် runtime object တစ်ခုအဖြစ် ရှိသင့်ပြီး အစုံအရာလိုအပ်ချိန်တွင် agent က ထုတ်ယူနိုင်ရပါမယ်။
-
Memories Scratchpad များက single session ၏ context window ထဲမှာ မဟုတ်ဘဲ အချက်အလက်များကို စီမံရာ အကောင်းဆုံးဖြစ်ပါတယ်။ Memories များက agent များကို အစဉ်အမြဲ အပတ်စဉ် session များအကြား သက်ဆိုင်ရာ အချက်အလက်များကို သိမ်းစည်းပြီး ပြန်လည်ရယူနိုင်စေပါသည်။ ဥပမာ အကျဉ်းချုံးများ၊ အသုံးပြုသူနှစ်သက်ချက်များ၊ တိုးတက်မှုအတွက် တုံ့ပြန်ချက်များစသဖြင့် ထည့်သွင်းနိုင်ပါသည်။
-
Context ဖိချုပ်ခြင်း (Compressing Context) Context window ကြီးလာပြီး ကန့်သတ်ချက်ထိနီးလာသောအခါ အကျဉ်းချုပ်ခြင်း၊ ဖြတ်တောက်ခြင်း စသည်တို့ကို အသုံးပြုနိုင်သည်။ ၎င်းတွင် အရေးကြီးဆုံး အချက်အလက်များကိုသာ ထိန်းသိမ်းထားခြင်း သို့မဟုတ် အဟောင်းမလိုလားသော စကားဝိုင်းများကို ဖယ်ရှားခြင်း တို့ ပါဝင်သည်။
-
Multi-Agent Systems မူလ agent တစ်ခုထက် မျိုးစုံသော agent များ ဖန်တီးခြင်းဟာ context အင်ဂျင်နီယာ၏ တစ်မျိုးလည်း ဖြစ်ပါတယ်၊ အကြောင်းက အချင်းချင်း ထိန်းသိမ်းထားသော context window များကွဲပြားပြီး ၎င်းကို မည်သို့ မျှဝေ ရမည်နှင့် မည်သို့ ပို့ဆောင်မည်ဆိုတာကို စီစဉ်ရပါမယ်။
-
Sandbox Environments Agent တစ်ခုက ကုဒ်တစ်ချို့ ပြေးရန် သို့မဟုတ် စာရွက်စာတမ်းပမာဏ ကြီးမားသော အချက်အလက်များကို ပါဝင်ပြုလုပ်ရန် လိုအပ်ပါက ၎င်းကို 처리 ဖို့ token များတော်တော်များများ လိုအပ်နိုင်ပါတယ်။ ဤအား context window ထဲမှာ တင်ထားခြင်းမပြုဘဲ၊ sandbox environment တစ်ခုကို အသုံးပြုပြီး ကုဒ်ကို ပြေးစေပြီး ရလဒ်များနှင့် သက်ဆိုင်ရာ အချက်အလက်များသာ ဖတ်ရှုမည်ဖြစ်စေပါသည်။
-
Runtime State Objects ဤနည်းလမ်းက Agent အချို့ အချက်အလက်များကို အသုံးထားရန် လိုအပ်သော අවခ်က်လက်များအတွက် အချက်အလက် ကွန်တိန်နာများ ဖန်တီးပေးခြင်းဖြစ်သည်။ ရှုပ်ထွေးသော တာဝန်တစ်ခုအတွက် Agent သည် အပို-လုပ်ငန်းအဆင့်ချင်းစီ၏ ရလဒ်များကို အဆင့်လိုက် သိမ်းဆည်းနိုင်သလို context ကို ထိုအထူးသီးသန့် အပို-လုပ်ငန်းနှင့်သာ ဆက်သွယ်ထားနိုင်စေပါသည်။
Context အင်ဂျင်နီယာ ရဲ့ နမူနာ
ကျွန်တော်တို့ အလိုရှိတာက AI agent ကို “ကျွန်တော်ကို ပါရီ သို့ ခရီးစဉ် တစ်ခု စီပေးပါ။” ဆိုတာကို လုပ်ပေးစေချင်တယ်လို့ စဉ်းစားပါစို့။
• Prompt အင်ဂျင်နီယာ သာ အသုံးပြုသည့် စနစ်တစ်ခုလျှင် တစ်ခါတည်း ရိုးရိုးစင်းစင်း တုံ့ပြန်ပြီး “အိုကေ၊ မင်းဘယ်အချိန် က ပါရီသို့ သွားချင်လဲ?” ဆိုပြီးသာ တုံ့ပြန်နိုင်ပါမည်။ ၎င်းသည် အသုံးပြုသူက မေးမြန်းချိန်ထင်ရှားသည့် မေးခွန်းကိုသာ ပြန်လည်လုပ်ဆောင်ခဲ့သည်။
• Context အင်ဂျင်နီယာ့နည်းလမ်းများကို အသုံးပြုသည့် agent တစ်ခုကတော့ ပိုမိုကျယ်ပြန့်စွာ လုပ်ဆောင်ပါလိမ့်မယ်။ တုံ့ပြန်ခင်မှာပင် ၎င်း၏ system သည် -
◦ သင့် မှတ်တမ်းဇယားကို စစ်ကြည့်မယ် — ရက်စွဲများ (real-time data) ကို ရယူစစ်ဆေးရန်။
◦ အတိတ် ခရီးသွားနှစ်သက်ချက်များကို သတိရမည် — ရေရှည်မှတ်ဉာဏ်မှ သင်၏ နှစ်သက်သော လေကြောင်းလိုင်း၊ ဘတ်ဂျက် သို့မဟုတ် တိုက်ရိုက်လေယာဉ်များကို ကြို preferring ထားသည်ကို ပြန်လည်ဆွဲယူရန်။
◦ လေယာဉ်နှင့် ဟိုတယ် အပ်ရန် သင့်ရဲ့ သုံးနိုင်မယ့် tools များကို ဖော်ထုတ်မည်။
- ထို့နောက် တုံ့ပြန်ချက်ဥပမာတစ်ခုကတော့ - “Hey [Your Name]! I see you’re free the first week of October. Shall I look for direct flights to Paris on [Preferred Airline] within your usual budget of [Budget]?” ဆိုပြီး ပိုမိုသိရှိနိုင်စွမ်းရှိတဲ့ context-aware တုံ့ပြန်ချက်တစ်ခု ဖြစ်နိုင်ပါသည်။ ဤအချိုးဖြစ်သော တုံ့ပြန်ချက်က context အင်ဂျင်နီယာ၏ အင်အားကို ပြသသည်။
Context ပျက်ကွက်မှုများ (Common Context Failures)
Context Poisoning
ဘာလဲ: LLM မှ ဖန်တီးသော hallucination (အမှားသတင်းအချက်အလက်) သို့မဟုတ် အမှားတစ်ခုက context ထဲဝင်သည့်အခါ၊ ၎င်းကို မကြာခဏ ကိုးကားလိုက်သောအခါ agent က မဖြစ်နိုင်မည့် ရည်မှန်းချက်များကို လိုက်နာသွားနိုင်ပြီး အဓိပ္ပါယ်မရှိတဲ့ မဟုတ်သော မဟာဗျူဟာများ ဖွံ့ဖြိုးလိမ့်မည်။
ပြုလုပ်ရန်: context validation နှင့် quarantine ကို အကောင်အထည်ဖော်ပါ။ သတင်းအချက်အလက်များကို ရေရှည်မှတ်ဉာဏ်ထဲ ထည့်မီ စစ်ဆေးပါ။ ပြpotential poisoning သံသယရှိလျှင် အမှားသော အချက်အလက်များ မပြန့်နှံ့ရန် context အသစ်များ စတင်ဖန်တီးပါ။
ခရီး တည်းခရီး ဥပမာ: သင့် agent က တိုင်းဒေသကျေးလက်လေဆိပ်တစ်ခုကနေ နိုင်ငံခြား အလားတူ မြို့ကြီးတစ်မြို့သို့ တိုက်ရိုက် လေယာဉ်ရှိတယ် ဆိုတဲ့ hallucination တစ်ခုဖန်တီးလိုက်တယ်။ ၎င်းမရှိသည့် လေကြောင်းလမ်းကြောင်း အချက်အလက်ကို context ထဲသိမ်းဆည်းလိုက်သည်။ နောက်ပိုင်း သင် agent ကို ခရီးစာရင်းလုပ်ဖို့ မေးတဲ့အခါ agent က ၎င်းမဖြစ်နိုင်သော လမ်းကြောင်းအပေါ် အဆက်မပြတ် လိုက်ယာဖြစ်နေပြီး ပြန်ဆိုစရာ အမှားများ ဖြစ်စေနိုင်သည်။
ဖြေရှင်းနည်း: လေယာဉ်ရဲ့ ရှိ/မရှိနှင့် လမ်းကြောင်းများကို agent ရဲ့ လက်ရှိ context ထဲသို့ ထည့်မီ အမှန်တကယ် ရေရှည် API ဖြင့် စစ်ဆေးရန် အဆင့်တစ်ခု ထည့်ပါ။ စစ်ဆေးမှု မအောင်မြင်ပါက အမှားသော အချက်အလက်ကို “quarantine” လုပ်၍ ထပ်မသုံးပါ။
Context Distraction
ဘာလဲ: Context က များလွန်းသို့မဟုတ် ပုံချုပ်ထားသဖြင့် model ဆီက အတည်ပြုသင်ယူထားသည့် အရာများထက် စကားဝိုင်းမှ စုစည်းစုစံထားရှိသည့် သမိုင်းအချက်အလက်များကို ပို၍ အာရုံစိုက်သွားပြီး ထပ်တလဲလဲ မထိရောက်သော လုပ်ဆောင်ချက်များ သို့မဟုတ် အလမ်းလျှောက်မှု မဟုတ်သော တုံ့ပြန်မှုများ ဖြစ်စေတတ်သည်။ Model များက context window ပြည့်ခင်မှာပင် အမှားလုပ်တတ်သည်။
ပြုလုပ်ရန်: context အကျဉ်းချုပ် (summarization) ကို အသုံးပြုပါ။ စုစုပေါင်းထားရှိသည့် အချက်အလက်များကို ကြာချိန်ကာလတိုင်း သို့မဟုတ် အချိန်မီ အကျဉ်းချုပ်ထားပြီး အကျဉ်းချုံးထားသော အချက်အလက်များကိုသာ ထည့်သွင်းပါ။ ဤနည်းလမ်းက attention ကို “reset” လုပ်ရန် အထောက်အကူပြုပါသည်။
ခရီး တည်းခရီး ဥပမာ: မင်းက အချိန်ကြာကထိ ကနေ သင့်ရဲ့ အိပ်မက် ခရီးစီးကြောင်းများကို ရှင်းလင်းစွာ ဆွေးနွေးခဲ့ပီး နှစ်နှစ်က backpacking ခရီးစဉ်အကြောင်းကို အသေးစိတ် ပြောကြားခဲ့တယ်။ မင်း “လာမယ့်လအတွက် စျေးถูกတဲ့ လေယာဉ်တစ်စင်း ရှာပေးပါ”라고 မေးတဲ့အခါ agent ဟာ အဟောင်း၊ မသက်ဆိုင်တဲ့ အသေးစိတ် အချက်အလက်များထဲမှာ ပိတ်မိသွားပြီး မင်းရဲ့ ခုနှစ်ရက် ခရီးစဉ် ဆက်သွယ်ချက်ကို ငြင်းပယ်တင်စားပြီး ခရီးနှင့်မသက်ဆိုင်ပဲ သင့်ရဲ့ backpacking ကိရိယာများကို မေးမြန်းနေဖို့ ဖြစ်နိုင်တယ်။
ဖြေရှင်းနည်း: turns အရေအတွက် တစ်ချို့ကျော်သွားသည်နှင့် context ကြီးလာသည့်အခါ agent က စကားဝိုင်း၏ နောက်ဆုံးနှင့် သက်ဆိုင်မှုအများဆုံး အပိုင်းများကို အကျဉ်းချုပ် ပြုလုပ်ပြီး — သင့်ရဲ့ လက်ရှိ ခရီးရက်များနှင့် ဥပဒေကို အလေးပေးကာ — ထိုအကျဉ်းချုပ်ကို နောက်တစ်ခါ LLM ကိုခေါ်တဲ့အခါ အသုံးပြု၍ သက်ဆိုင်မှုနည်းတဲ့ ပျက်ကွက်သမိုင်းကို ဖယ်ရှားသင့်သည်။
Context Confusion
ဘာလဲ: မလိုအပ်သော context၊ အထူးသဖြင့် ရနိုင်သော tools များစွာ ရှိခြင်းက model ကို မမှန်ကန်သော တုံ့ပြန်မှုများ ထုတ်ပေးစေနိုင်သည် သို့မဟုတ် မသင့်အပ်သော tools ကို ခေါ်သုံးစေတတ်သည်။ သေးငယ်သည့် model များတွင် ဤအခြေအနေ ပိုမိုပေါ့ပါးတတ်သည်။
ပြုလုပ်ရန်: RAG နည်းဗျုဟာများကို အသုံးပြု၍ tool loadout management ကို အကောင်အထည်ဖော်ပါ။ Tool ဖော်ပြချက်များကို vector database ထဲသို့ သိမ်းဆည်းထားပြီး အလုပ်တစ်ခုစီအတွက် အရေးကြီးဆုံး tool များကို တစ်ခုချင်းစီ ရွေးချယ်ပါ။ သုတေသနက tool ရွေးချယ်မှုကို 30 ထက်နည်းစေရန် အကွာအဝေး ရှိကြောင်း ဖော်ပြသည်။
ခရီး တည်းခရီး ဥပမာ: သင့် agent ကို tools အတော်များများ လက်လှမ်းယူနိုင်ပါတယ်: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations စသည်။ မင်း “ပဲရီမှာ သွားလာဖို့ အကောင်းဆုံး နည်းလမ်း ဘာလဲ?” ဆိုတဲ့ မေးခွန်း မေးလိုက်တိုင်း tool များ အများအပြား ရှိနေတဲ့အတွက် agent က book_flight ကို ပဲရီ အတွင်းပဲ ခေါ်ယူဖို့ သို့မဟုတ် သင့်ဟန်ချက်အတိုင်း public transport ကို နှစ်သက်သော်လည်း rent_car ကို ခေါ်ခွင့်ပြုတတ်တဲ့ စနစ် ပေါ်မူတည်ပြီး တောထွက်မှုဖြစ်စေတတ်ပါသည်။
ဖြေရှင်းနည်း: tool ဖော်ပြချက်များပေါ် RAG ကို အသုံးပြုပါ။ မင်း ပဲရီမှာ သွားလာဖို့အကြောင်း မေးတဲ့အခါ စနစ်က မင်းမေးတဲ့ မေးခွန်းအပေါ် အခြေခံပြီး rent_car သို့မဟုတ် public_transport_info ကဲ့သို့ သက်ဆိုင်မှုရှိသော tools အနည်းငယ်ကို dynamic အနေနဲ့ ရယူပြီး LLM သို့ လက်ခံမယ့် “loadout” ကို အာရုံစိုက်စေပါ။
Context Clash
ဘာလဲ: Context အတွင်း ဆန့်ကျင်နေသော သတင်းအချက်အလက်များ ရှိနေသည့်အခါ မှတ်ဥာဏ်အမှား သို့မဟုတ် မမှန်ကန်သော နောက်ဆုံးတုံ့ပြန်ချက်များ ဖြစ်ပေါ်စေနိုင်သည်။ ဤအခြေအနေသည် သတင်းအချက်အလက်များ အဆင့်ဆင့် ရောက်လာသောအခါ အထူးသဖြင့် ကြုံရတတ်ပြီး အစပိုင်းမှ မမှန်သော ခန့်မှန်းချက်များ context ထဲတွင် နှစ်လည်ကျန်နေသည်။
ပြုလုပ်ရန်: context pruning နှင့် offloading ကို အသုံးပြုပါ။ Pruning က အဟောင်း သို့မဟုတ် ဆန့်ကျင်သော အချက်အလက်များကို ပယ်ဖျက်ခြင်းဖြစ်သည်။ Offloading က မူလ context ကို မထိခိုက်စေဘဲ သတင်းအချက်အလက်ကို စစ်ဆေးရန် အခြား “scratchpad” ဝန်ဆောင်မှုကို ပေးသည်။
ခရီး တည်းခရီး ဥပမာ: မင်းအစမှာ agent ကို “Economy class နဲ့ တင်ပို့ပါ။” လို့ ပြောခဲ့တယ်။ နောက်ပိုင်းမှာ မင်းပြန်ပြောပြီး “ဒီခရီးအတွက်တော့ Business class စိတ်ကြိုက်ပါ။” လို့ ပြောင်းလဲလိုက်တယ်။ အဲဒီနှစ်ခု instruction များရှိနေသေးရင် agent က ရှာဖွေမှုတွင် ဆန့်ကျင်တဲ့ ရလဒ်တွေ ရရှိစေပြီး မင်းဘယ်တာကို ဦးစားပေးရမယ်ဆိုတာ ရှင်းမလင်းနိုင်တော့ပါ။
ဖြေရှင်းနည်း: context pruning ကို ထည့်သုံးပါ။ အတုတည်းဦးတည်ချက်အား ဆန့်ကျင်သော အမှုတစ်ခု နောက်တစ်ခု များလာလျှင် အဟောင်း instruction ကို ဖယ်ရှားသို့မဟုတ် ပွင့်လင်းစွာ override လုပ်ပါ။ နောက်တစ်ဖက်မှာ agent သည် scratchpad တစ်ခု အသုံးပြုပြီး ဆန့်ကျင်နေတဲ့ နှစ်သက်ချက်များကို ဖြေရှင်းပြီး နောက်ဆုံးနှင့် တိုက်ရိုက်ဆက်စပ်သော instruction တစ်ခုကိုသာ လမ်းညွှန်ခွင့်ပေးနိုင်သည်။
Context အင်ဂျင်နီယာအကြောင်း မေးစရာများ ရှိသေးလား?
Microsoft Foundry Discord တွင် တက်ရောက်ကာ အခြား သင်ယူသူများနှင့် တွေ့ဆုံပြီး office hours များတက်ရောက်နိုင်ပြီး သင့် AI Agents မေးခွန်းများကို ဖြေရှင်းနိုင်ပါတယ်။
သတိပေးချက် - ဤစာရွက်စာတမ်းကို AI ဘာသာပြန်ဝန်ဆောင်မှု Co-op Translator (https://github.com/Azure/co-op-translator) ကူညီပြီး ဘာသာပြန်ထားပါသည်။ ကျွန်ုပ်တို့သည် တိကျမှန်ကန်မှုကို ကြိုးပမ်းပါသော်လည်း အလိုအလျောက် ပြုလုပ်ပါသော ဘာသာပြန်ချက်များတွင် အမှားများ သို့မဟုတ် မှန်ကန်မှုမကျေကြောင်းများ ပါဝင်နိုင်သည်ကို မှတ်သားပါ။ မူလစာရွက်စာတမ်းကို မူရင်းဘာသာစကားဖြင့် သတ်မှတ်ထားသည့် အာဏာရှိသော အရင်းအမြစ်အဖြစ်ယူဆရပါမည်။ အရေးကြီးသော အချက်အလက်များအတွက် လူသား ပရော်ဖက်ရှင်နယ် ဘာသာပြန်ဆောင်ရွက်မှုကို အကြံပြုပါသည်။ ဤဘာသာပြန်ချက်အရ ဖြစ်ပေါ်နိုင်သည့် နားမလည်မှုများ သို့မဟုတ် မှားဖော်ပြမှုများအတွက် ကျွန်ုပ်တို့၏ တာဝန်မရှိပါ။