ai-agents-for-beginners
एजेन्टिक प्रोटोकलहरूको प्रयोग (MCP, A2A र NLWeb)

(यो पाठको भिडियो हेर्न माथिको चित्र क्लिक गर्नुहोस्)
AI एजेन्टहरूको प्रयोग बढ्दै गएसँगै मापदण्ड, सुरक्षा र खुला नवप्रवर्तनलाई सुनिश्चित गर्ने प्रोटोकलहरूको आवश्यकता पनि बढ्छ। यस पाठमा, हामी यस आवश्यकतालाई पूरा गर्न खोज्ने 3 प्रोटोकलहरू — Model Context Protocol (MCP), Agent to Agent (A2A) र Natural Language Web (NLWeb) — कभर गर्नेछौं।
परिचय
यस पाठमा हामीले समेट्ने विषयहरू:
• कसरी MCP ले AI एजेन्टहरूलाई बाह्य उपकरण र डाटा पहुँच गराएर प्रयोगकर्ताका कार्यहरू पूरा गर्न सक्षम बनाउँछ।
• कसरी A2A ले विभिन्न AI एजेन्टहरूबीच संचार र सहकार्य सक्षम बनाउँछ।
• कसरी NLWeb ले कुनै पनि वेबसाइटमा प्राकृतिक भाषा अन्तरफलक ल्याएर AI एजेन्टहरूले सामग्री पत्ता लगाउन र अन्तरक्रिया गर्न सक्षम बनाउँछ।
सिकाइ लक्ष्यहरू
• पहिचान गर्नुहोस् MCP, A2A, र NLWeb को मुख्य उद्देश्य र फाइदाहरू AI एजेन्टहरूको सन्दर्भमा।
• व्याख्या गर्नुहोस् कसरी प्रत्येक प्रोटोकलले LLMs, उपकरणहरू, र अन्य एजेन्टहरूबीच संचार र अन्तरक्रिया सहज बनाउँछ।
• चिन्नुहोस् जटिल एजेन्टिक प्रणालीहरू निर्माण गर्दा प्रत्येक प्रोटोकलले खेलेको पृथक भूमिकाहरू।
मोडेल कन्टेक्स्ट प्रोटोकल
Model Context Protocol (MCP) एउटा खुला मानक हो जसले अनुप्रयोगहरूलाई LLM हरूमा सन्दर्भ र उपकरणहरू प्रदान गर्ने मानकीकृत तरिका उपलब्ध गराउँछ। यसले विभिन्न डाटा स्रोत र उपकरणहरूसँग कनेक्ट हुन AI एजेन्टहरूले प्रयोग गर्न सक्ने “सार्वभौमिक एडाप्टर” सक्षम पार्छ।
अब MCP का कम्पोनेन्टहरू, सिधा API प्रयोगकी तुलनामा लाभहरू, र AI एजेन्टहरूले कसरी MCP सर्भर प्रयोग गर्न सक्छन् भन्ने उदाहरण हेरौं।
MCP मुख्य कम्पोनेन्टहरू
MCP क्लाइєн्ट-सर्भर आर्किटेक्चरमा काम गर्छ र मुख्य कम्पोनेन्टहरू यस्ता छन्:
• Hosts ती LLM अनुप्रयोगहरू हुन् (उदाहरणका लागि VSCode जस्तो कोड सम्पादक) जुन MCP सर्भरसँग कनेक्शन सुरु गर्छन्।
• Clients होस्ट अनुप्रयोग भित्रका त्या घटकहरू हुन् जसले सर्भरहरूसँग एक-देखि-एक कनेक्शनहरू कायम गर्छन्।
• Servers हल्का तौलका प्रोग्रामहरू हुन् जसले विशेष क्षमता प्रदर्शन गर्छन्।
प्रोटोकलमा समावेश तीन मुख्य प्रिमिटिभहरू छन् जुन MCP सर्भरका क्षमता हुन्:
• Tools: यी छुट्टै क्रियाहरू वा कार्यहरू हुन् जुन AI एजेन्टले प्रयोग गरी कुनै कार्य सम्पन्न गर्न सक्छ। उदाहरणका लागि, मौसम सेवा “get weather” टूल प्रदर्शन गर्न सक्छ, वा एक ई-कमर्स सर्भरले “purchase product” टूल प्रदर्शन गर्न सक्छ। MCP सर्भरहरूले आफ्नो क्षमता सूचीमा प्रत्येक टूलको नाम, विवरण, र इनपुट/आउटपुट स्किमा विज्ञापन गर्छन्।
• Resources: यी पढ्न मात्र मिल्ने डाटा वस्तुहरू वा कागजातहरू हुन् जसलाई MCP सर्भरले प्रदान गर्न सक्छ र क्लाइєн्टहरूले मागमा प्राप्त गर्न सक्छन्। उदाहरणहरूमा फाइल सामग्रीहरू, डाटाबेस कागजातहरू, वा लग फाइलहरू समावेश छन्। Resources टेक्स्ट (जस्तै कोड वा JSON) वा बाइनरी (जस्तै छविहरू वा PDFs) हुन सक्छन्।
• Prompts: यी पहिले नै परिभाषित टेम्पलेटहरू हुन् जसले सुझाइएको प्राँप्टहरू प्रदान गर्छन्, जसले बढी जटिल कार्यप्रवाहहरूलाई सजिलो बनाउँछ।
MCP का लाभहरू
MCP ले AI एजेन्टहरूको लागि महत्वपूर्ण फाइदा प्रदान गर्छ:
• डाइनामिक टूल खोज: एजेन्टहरूले सर्भरबाट उपलब्ध टूलहरूको सूची र ती के गर्छन् भन्ने विवरण गतिशील रूपमा प्राप्त गर्न सक्छन्। यो परम्परागत APIs सँग विपरीत हो, जसमा एकीकृत गर्न स्थिर कोडिङ आवश्यक पर्छ र कुनै API परिवर्तन आएमा कोड अपडेट गर्नु पर्छ। MCP ले “एक पटक एकीकृत गर्नुहोस्” दृष्टिकोण प्रदान गर्छ, जसले बढी अनुकूलनीयता दिन्छ।
• विभिन्न LLM हरू बीच अन्तरचलनशीलता: MCP विभिन्न LLM हरूसँग काम गर्छ, जसले प्रदर्शन सुधारका लागि कोर मोडेलहरू परिवर्तन गर्ने लचकता दिन्छ।
• मानकीकृत सुरक्षा: MCP मा मानक प्रमाणीकरण विधि समावेश छ, जसले थप MCP सर्भरहरूमा पहुँच थप्दा स्केलेबिलिटी सुधार्छ। यो विभिन्न परम्परागत API हरूका लागि फरक-फरक कीहरू र प्रमाणीकरण प्रकारहरू व्यवस्थापन गर्नेभन्दा साधारण छ।
MCP उदाहरण
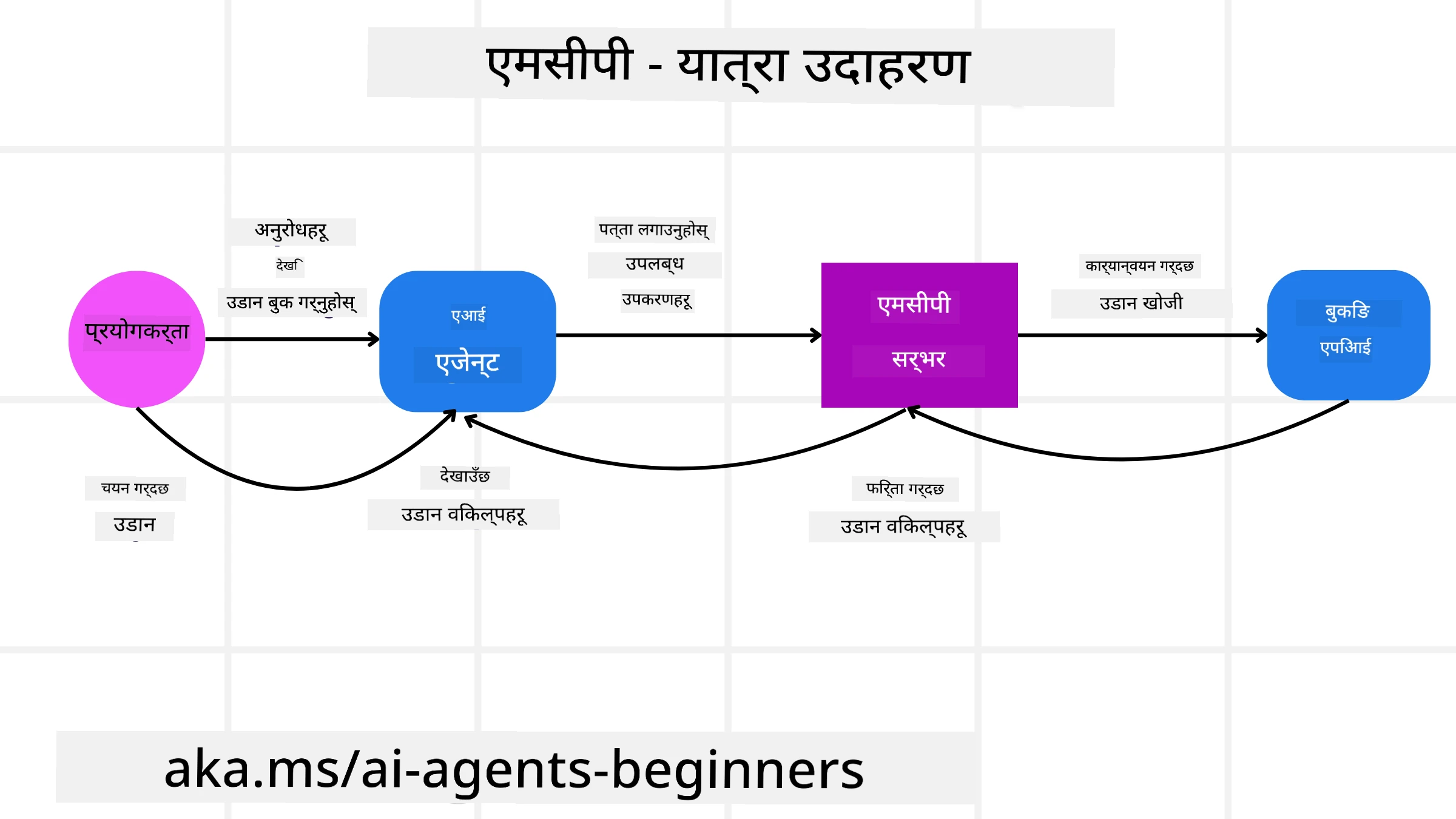
कल्पना गर्नुहोस् कि प्रयोगकर्ताले MCP द्वारा संचालित AI सहायक प्रयोग गरी उडान बुक गर्न चाहन्छ।
-
कनेक्शन: AI सहायक (MCP क्लाइєн्ट) एयरलाइनद्वारा प्रदान गरिएको MCP सर्भरमा जडान गर्छ।
-
टूल डिस्कभरी: क्लाइєн्ट एयरलाइनको MCP सर्भरलाई सोध्छ, “तपाईंहरूसँग कुन-कुन टूलहरू उपलब्ध छन्?” सर्भरले “search flights” र “book flights” जस्ता टूलहरू प्रतिक्रिया स्वरूप प्रदान गर्छ।
-
टूल कल गर्नु: त्यसपछि तपाईं AI सहायकलाई भन्छन्, “कृपया पोर्टल्यान्डबाट होनोलुलुका लागि उडान खोज्नुहोस्।” AI सहायकले आफ्नो LLM प्रयोग गरी आवश्यक टूल “search flights” कल गर्नुपर्ने पहिचान गर्छ र सम्बद्ध प्यारामिटरहरू (origin, destination) MCP सर्भरमा पठाउँछ।
-
कार्यान्वयन र प्रतिक्रिया: MCP सर्भरले रैपरको रूपमा काम गर्दै एयरलाइनको आन्तरिक बुकिङ API मा वास्तविक कल गर्छ। त्यसपछि यसले उडान जानकारी (जस्तै JSON डाटा) प्राप्त गरी AI सहायकलाई पठाउँछ।
-
अर्को अन्तरक्रिया: AI सहायकले उडान विकल्पहरू प्रस्तुत गर्छ। तपाईंले कुनै उडान चयन गरेपछि, सहायकले त्यही MCP सर्भरमा “book flight” टूल invoke गर्न सक्छ र बुकिङ पूरा हुन सक्छ।
एजेन्ट-टु-एजेन्ट प्रोटोकल (A2A)
MCP ले LLM हरूलाई उपकरणहरूसँग जडान गर्न केन्द्रित भएता पनि, Agent-to-Agent (A2A) प्रोटोकल यसलाई अर्को चरणमा पुर्याउँछ — विभिन्न AI एजेन्टहरूबीच संचार र सहकार्य सक्षम बनाउने। A2A ले विभिन्न संस्थाहरू, वातावरणहरू र प्रविधि स्ट्याकहरूमा रहेका AI एजेन्टहरूलाई साझा कार्य पूरा गर्न जडान गर्न सक्षम बनाउँछ।
हामी A2A का कम्पोनेन्टहरू र फाइदाहरू हेर्नेछौं, साथै हाम्रो यात्री अनुप्रयोगमा यसलाई कसरी लागू गर्न सकिन्छ भन्ने उदाहरण पनि प्रस्तुत गर्नेछौं।
A2A का मुख्य कम्पोनेन्टहरू
A2A एजेन्टहरूबीच संचार सक्षम बनाउने र तिनीहरूलाई प्रयोगकर्ताको उप-कार्य पूरा गर्न एकसाथ काम गर्न लगाउनेमा केन्द्रित छ। प्रोटोकलका प्रत्येक कम्पोनेन्टले यसमा योगदान गर्छ:
Agent Card
MCP सर्भरले टूलहरूको सूची साझा गर्ने तरिकासँगै, Agent Card मा हुन्छ:
- एजेन्टको नाम।
- यसले पूरा गर्ने सामान्य कार्यहरूको विवरण।
- विशेष क्षमताहरूको सूची र विवरणहरू जसले अन्य एजेन्टहरू (वा मानव प्रयोगकर्ताहरू) लाई कहिले र किन उक्त एजेन्टलाई कल गर्न चाहिने हो भनेर बुझाउन मद्दत गर्छ।
- एजेन्टको हालको Endpoint URL
- एजेन्टको version र capabilities जस्तै स्ट्रीमिङ प्रतिक्रिया र पुश नोटिफिकेशनहरू।
Agent Executor
Agent Executor को जिम्मेवारी भनेको प्रयोगकर्ता च्याटको सन्दर्भ(remote context) लाई रिमोट एजेन्टसम्म पास गर्ने हो; रिमोट एजेन्टलाई कार्य बुझ्न यसले आवश्यक सन्दर्भ दिन्छ। A2A सर्भरमा, एक एजेन्टले आफ्नो आन्तरिक उपकरणहरू प्रयोग गरेर आउने अनुरोधहरू पार्स गर्न र कार्यहरू निर्वाह गर्न आफ्नै LLM प्रयोग गर्छ।
Artifact
एकपटक रिमोट एजेन्टले अनुरोध गरिएको कार्य पूरा गरेपछि, यसको कामको परिणामलाई आर्टिफ्याक्टको रूपमा सिर्जना गरिन्छ। एउटा आर्टिफ्याक्टले एजेन्टको कामको परिणाम, पूरा गरिएको कुराको विवरण, र प्रोटोकल मार्फत पठाइएको टेक्स्ट सन्दर्भ समावेश गर्छ। आर्टिफ्याक्ट पठाइएपछि, रिमोट एजेन्टसँगको कनेक्शन तबसम्म बन्द गरिन्छ जबसम्म फेरि आवश्यक नपरोस्।
Event Queue
यो कम्पोनेन्ट अपडेटहरू ह्यान्डल गर्ने र सन्देशहरू पास गर्ने का लागि प्रयोग गरिन्छ। यो उत्पादन वातावरणमा एजेन्टिक प्रणालीहरूका लागि विशेष गरी महत्त्वपूर्ण छ ताकि एजेन्टहरू बीचको कनेक्शन कार्य पूरा हुनुअघि बन्द नहोस्, विशेष गरी जब कार्य पूरा हुन लामो समय लाग्न सक्छ।
A2A का लाभहरू
• सुधारिएको सहकार्य: यसले विभिन्न विक्रेता र प्लेटफर्महरूको एजेन्टहरूलाई अन्तरक्रिया, सन्दर्भ साझा, र सँगै काम गर्न सक्षम बनाउँछ, परम्परागत रूपमा अलग सिस्टमहरूबीच सहज अटोनोमेशनलाई बढावा दिन्छ।
• मोडेल चयन लचकता: प्रत्येक A2A एजेन्टले आफ्नो अनुरोध सेवा गर्न कुन LLM प्रयोग गर्ने निर्णय गर्न सक्छ, जसले एजेण्ट अनुसार अनुकूलित वा फाइन-ट्यून गरिएको मोडेलहरू प्रयोग गर्न अनुमति दिन्छ, केही MCP परिदृश्यहरूमा हुने एकल LLM जडानको विपरीत।
• निहित प्रमाणीकरण: प्रमाणीकरण सीधै A2A प्रोटोकलमा एकीकृत गरिएको हुन्छ, जसले एजेन्ट अन्तरक्रियाहरूका लागि बलियो सुरक्षा फ्रेमवर्क प्रदान गर्छ।
A2A उदाहरण
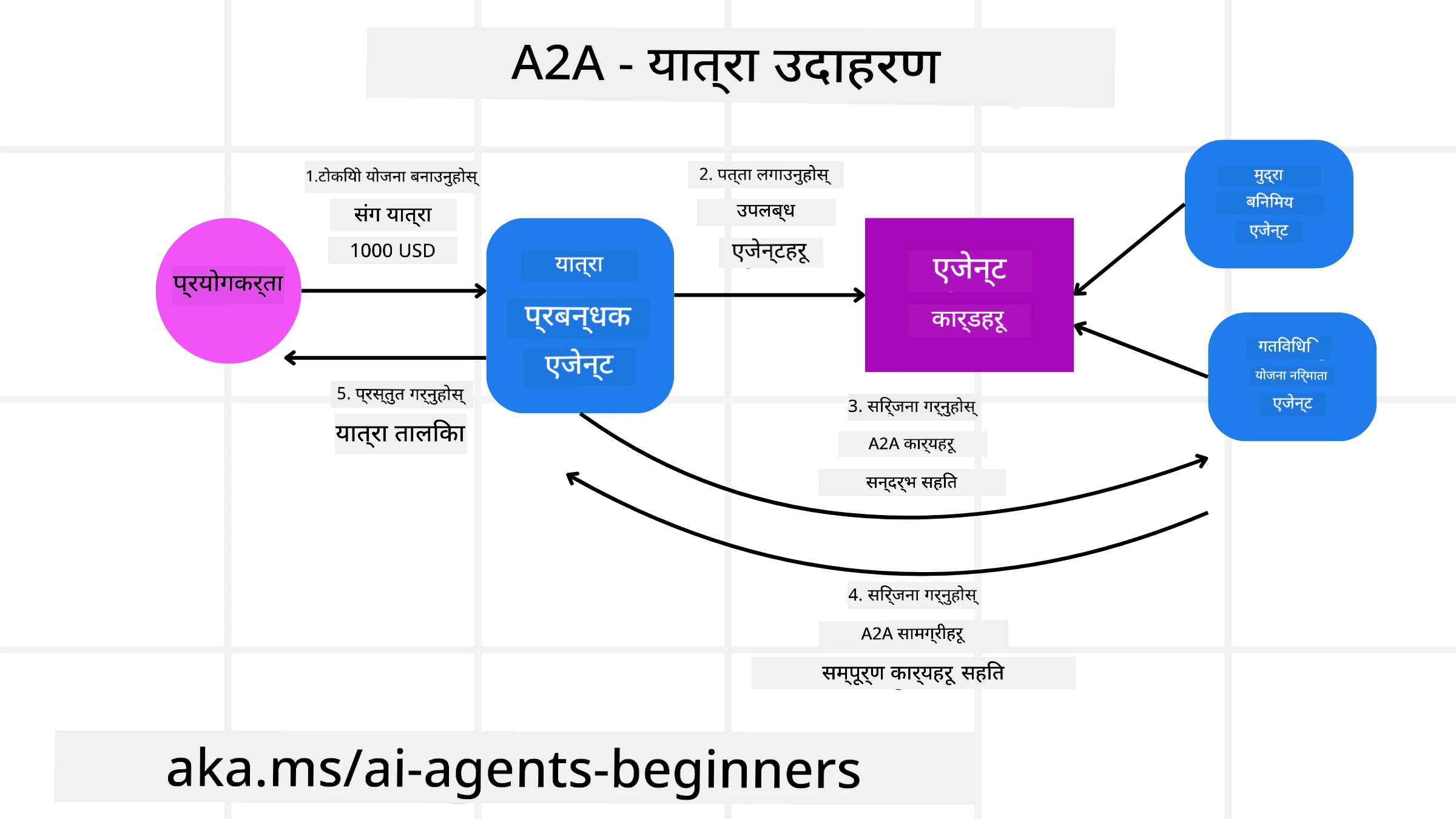
हामी हाम्रो यात्रा बुकिङ परिदृश्य विस्तार गरौं, तर यसपटक A2A प्रयोग गरेर।
-
प्रयोगकर्ताको अनुरोध मल्टी-एजेन्टतर्फ: प्रयोगकर्ता “Travel Agent” A2A क्लाइєн्ट/एजेन्टसँग अन्तरक्रिया गर्छ, सम्भवतः भन्छन्, “कृपया अर्को हप्ताको लागि होनोलुलुमा सम्पूर्ण यात्रा बुक गरीदिनुस्, जिसमें उडान, होटल र भाडाको कार समावेश होस्”।
-
Travel Agent द्वारा आयोजित समन्वय: Travel Agent ले यो जटिल अनुरोध प्राप्त गर्छ। यसले आफ्नो LLM प्रयोग गरी कार्यबारे तर्क गर्छ र अन्य विशिष्ट एजेन्टहरूसँग अन्तरक्रिया गर्न आवश्यक छ भनेर निर्धारण गर्छ।
-
एजेन्टहरूबीचको संचार: त्यसपछि Travel Agent ले A2A प्रोटोकल प्रयोग गरी डाउनस्ट्रीम एजेन्टहरू जस्तै “Airline Agent,” “Hotel Agent,” र “Car Rental Agent” सँग जडान गर्छ, जुन फरक-फरक कम्पनीहरूले सिर्जना गरेका हुन्छन्।
-
हस्तान्तरण गरिएको कार्य कार्यान्वयन: Travel Agent ले यी विशिष्ट एजेन्टहरूलाई स्पष्ट कार्यहरू पठाउँछ (जस्तै, “Find flights to Honolulu,” “Book a hotel,” “Rent a car”)। यी प्रत्येक विशिष्ट एजेन्टहरूले आफ्नै LLM हरू चलाउँदै र आफ्नै उपकरणहरू (जुन MCP सर्भरहरू हुन पनि सक्छन्) प्रयोग गरेर बुकिङको आफ्नो भाग पूरा गर्छन्।
-
एकीकृत प्रतिक्रिया: जब सबै डाउनस्ट्रीम एजेन्टहरूले आफ्ना कार्य पूरा गर्छन्, Travel Agent ले परिणामहरू (उडान विवरण, होटल पुष्टि, कार भाडा बुकिङ) तयार पार्छ र प्रयोगकर्तालाई समग्र, च्याट-शैली बन्ने उत्तर पठाउँछ।
प्राकृतिक भाषा वेब (NLWeb)
वेबसाइटहरू लामो समयदेखि इन्टरनेटभरि प्रयोगकर्ताहरूले जानकारी र डाटा पहुँच गर्न प्राथमिक तरिका रहेका छन्।
अब हामी NLWeb का विभिन्न कम्पोनेन्टहरू, NLWeb का लाभहरू र हाम्रो यात्रा अनुप्रयोग हेरेर NLWeb कसरी काम गर्छ भन्ने उदाहरण हेरौं।
NLWeb का कम्पोनेन्टहरू
-
NLWeb Application (Core Service Code): प्राकृतिक भाषा प्रश्नहरू प्रसोधन गर्ने प्रणाली। यसले प्लेटफर्मका विभिन्न भागहरूलाई जडान गरी प्रतिक्रियाहरू सिर्जना गर्छ। तपाईं यसलाई वेबसाइटका प्राकृतिक भाषा सुविधाहरूलाई चलाउने इन्जिनको रूपमा सोच्न सक्नुहुन्छ।
-
NLWeb Protocol: वेबसाइटहरूसँग प्राकृतिक भाषा अन्तरक्रियाको लागि आधारभूत नियमहरूको सेट। यो JSON ढाँचामा प्रतिक्रिया फर्काउँछ (प्रायः Schema.org प्रयोग गरेर)। यसको उद्देश्य “AI Web” का लागि सरल आधार बनाउनु हो, जसरी HTML ले अनलाइन कागजातहरू साझा गर्न सम्भव बनायो।
-
MCP Server (Model Context Protocol Endpoint): प्रत्येक NLWeb सेटअपले MCP सर्भरको रूपमा पनि काम गर्छ। यसको अर्थ यसले अन्य AI प्रणालीहरूसँग टूलहरू (जस्तै “ask” मेथड) र डेटा साझा गर्न सक्छ। व्यवहारमा, यसले वेबसाइटको सामग्री र क्षमताहरू AI एजेन्टहरूद्वारा प्रयोगयोग्य बनाउँछ, जसले साइटलाई व्यापक “एजेन्ट इकोसिस्टम” को भाग बनाउँछ।
-
Embedding Models: यी मोडेलहरू वेबसाइट सामग्रीलाई भेक्टर (embeddings) भनिने संख्यात्मक प्रतिनिधित्वमा रूपान्तरण गर्न प्रयोग गरिन्छ। यी भेक्टरहरूले कम्प्युटरहरूले तुलना र खोज गर्न मिल्ने तरिकाले अर्थ समात्छन्। तिनीहरू विशेष डाटाबेसमा 저장 गरिन्छन्, र प्रयोगकर्ताहरू कुन embedding मोडेल प्रयोग गर्ने चाहन्छन् भनी छनौट गर्न सक्छन्।
-
Vector Database (Retrieval Mechanism): यो डाटाबेसले वेबसाइट सामग्रीका embeddings स्टोर गर्छ। जब कसैले प्रश्न गर्छ, NLWeb ले भेक्टर डाटाबेस जाँच गर्द्छ र सबभन्दा सम्बन्धित जानकारी छिटो फेला पार्छ। यसले समानताका आधारमा सम्भाव्य उत्तरहरूको द्रुत सूची दिन्छ। NLWeb ले Qdrant, Snowflake, Milvus, Azure AI Search, र Elasticsearch जस्ता विभिन्न भेक्टर भण्डारण प्रणालीहरूसँग काम गर्छ।
NLWeb उदाहरण
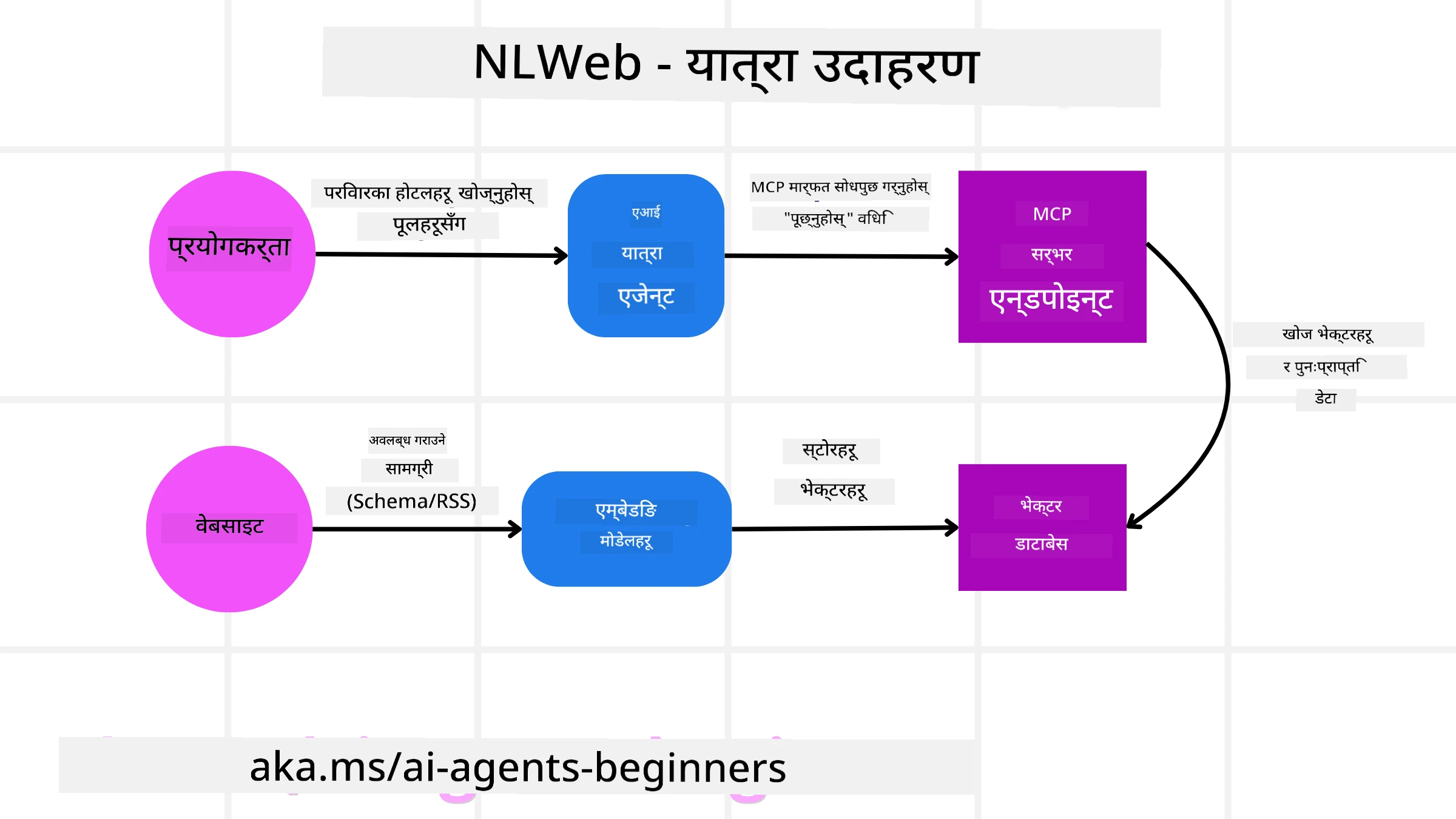
हाम्रो यात्रा बुकिङ वेबसाइटलाई फेरि विचार गर्नुहोस्, तर यसपटक यो NLWeb द्वारा सञ्चालित छ।
-
डाटा इनजेस्टन: यात्रा वेबसाइटका विद्यमान प्रोडक्ट क्याटलगहरू (जस्तै उडान सूची, होटल विवरण, टुर प्याकेजहरू) Schema.org प्रयोग गरेर स्वरूपित गरिन्छ वा RSS फिडहरू मार्फत लोड गरिन्छ। NLWeb का उपकरणहरूले यी संरचित डाटाहरु इनजेस्ट गरेर embeddings सिर्जना गरी स्थानीय वा रिमोट भेक्टर डाटाबेसमा स्टोर गर्छ।
-
प्राकृतिक भाषा प्रश्न (मानव): एक प्रयोगकर्ता वेबसाइट भ्रमण गर्छ र मेनुहरू नेभिगेट गर्ने सट्टा च्याट इन्टरफेसमा टाइप गर्छ: “अर्को हप्ताको लागि होनोलुलुमा पूल भएको परिवारमैत्री होटल फेला पार्नुहोस्”।
-
NLWeb प्रसोधन: NLWeb अनुप्रयोगले यो प्रश्न प्राप्त गर्छ। यसले बुझ्नको लागि सोधलाई LLM मा पठाउँछ र एकै समयमा सम्बन्धित होटल सूचीहरूको लागि भेक्टर डाटाबेसमा खोजी गर्छ।
-
ठिक परिणामहरू: LLM ले डाटाबेसको खोजी परिणामहरू अर्थ्याउन मद्दत गर्छ, “family-friendly,” “pool,” र “Honolulu” मापदण्डहरूको आधारमा उत्तम मेलहरू पहिचान गर्छ, र त्यसपछि प्राकृतिक भाषामा प्रतिक्रिया फर्म्याट गर्छ। महत्वपूर्ण कुरा, जवाफ वेबसाइटको क्याटलगबाट वास्तविक होटलहरूलाई सन्दर्भ गर्दछ, बनावटी जानकारी राख्नेबाट बच्छ।
-
AI एजेन्ट अन्तरक्रिया: किनकि NLWeb एक MCP सर्भरको रूपमा कार्य गर्छ, बाह्य AI यात्रा एजेन्टले पनि यस वेबसाइटको NLWeb इन्स्ट्यान्समा जडान गर्न सक्छ। AI एजेन्टले त्यसपछि
ask("Are there any vegan-friendly restaurants in the Honolulu area recommended by the hotel?")मेथड प्रयोग गरेर सोध्न सक्छ। NLWeb इन्स्ट्यान्सले यसलाई प्रशोधन गर्नेछ, यदि लोड गरिएको छ भने रेस्टुरेन्ट जानकारीको आफ्नो डेटाबेसको लाभ लिएर संरचित JSON प्रतिक्रिया फर्काउनेछ।
MCP/A2A/NLWeb सम्बन्धी थप प्रश्नहरू छन्?
अन्य सिक्नेहरूसँग भेटघाट गर्न, अफिस आवरहरूमा सहभागी हुन र तपाईंका AI एजेन्ट सम्बन्धी प्रश्नहरूको उत्तर पाउन Microsoft Foundry Discord मा सामेल हुनुहोस्।
स्रोतहरू
अस्वीकरण: यो दस्तावेज AI अनुवाद सेवा Co-op Translator (https://github.com/Azure/co-op-translator) प्रयोग गरेर अनुवाद गरिएको हो। हामी शुद्धताका लागि प्रयासरत भए तापनि, कृपया ध्यान दिनुहोस् कि स्वचालित अनुवादहरूमा त्रुटि वा अशुद्धता हुन सक्छ। मूल दस्तावेजलाई यसको मातृभाषामा नै आधिकारिक स्रोत मानिनु पर्छ। महत्वपूर्ण जानकारीका लागि पेशेवर मानव अनुवाद सिफारिस गरिन्छ। यस अनुवादको प्रयोगबाट उत्पन्न भएका कुनै पनि गलतफहमी वा गलत व्याख्याका लागि हामी दायित्व स्वीकार गर्दैनौं।