ai-agents-for-beginners
Contextengineering voor AI-agenten

(Klik op de afbeelding hierboven om de video van deze les te bekijken)
Het begrijpen van de complexiteit van de toepassing waarvoor je een AI-agent bouwt is belangrijk om er een betrouwbare van te maken. We moeten AI-agenten bouwen die informatie effectief beheren om complexe behoeften aan te pakken, verder dan prompt-engineering.
In deze les bekijken we wat contextengineering is en welke rol het speelt bij het bouwen van AI-agenten.
Introductie
Deze les behandelt:
• Wat contextengineering is en waarom het anders is dan prompt-engineering.
• Strategieën voor effectieve contextengineering, inclusief hoe je informatie schrijft, selecteert, comprimeert en isoleert.
• Veelvoorkomende contextfouten die je AI-agent kunnen doen ontsporen en hoe je ze oplost.
Leerdoelen
Na het voltooien van deze les weet je hoe je:
• Contextengineering definiëren en onderscheiden van prompt-engineering.
• De belangrijkste componenten van context identificeren in toepassingen met Large Language Models (LLM).
• Strategieën toepassen voor het schrijven, selecteren, comprimeren en isoleren van context om de prestaties van de agent te verbeteren.
• Veelvoorkomende contextfouten herkennen zoals vergiftiging, afleiding, verwarring en botsing, en mitigerende technieken implementeren.
Wat is contextengineering?
Voor AI-agenten is context wat de planning van een AI-agent aanstuurt om bepaalde acties te ondernemen. Contextengineering is de praktijk om ervoor te zorgen dat de AI-agent de juiste informatie heeft om de volgende stap van de taak te voltooien. Het contextvenster is beperkt in grootte, dus als ontwikkelaars van agenten moeten we systemen en processen bouwen om het toevoegen, verwijderen, en condenseren van de informatie in het contextvenster te beheren.
Prompt-engineering vs contextengineering
Prompt-engineering richt zich op één set statische instructies om AI-agenten effectief te begeleiden met een reeks regels. Contextengineering gaat over het beheren van een dynamische set informatie, inclusief de initiële prompt, om ervoor te zorgen dat de AI-agent over tijd heeft wat hij nodig heeft. Het belangrijkste idee achter contextengineering is om dit proces herhaalbaar en betrouwbaar te maken.
Soorten context
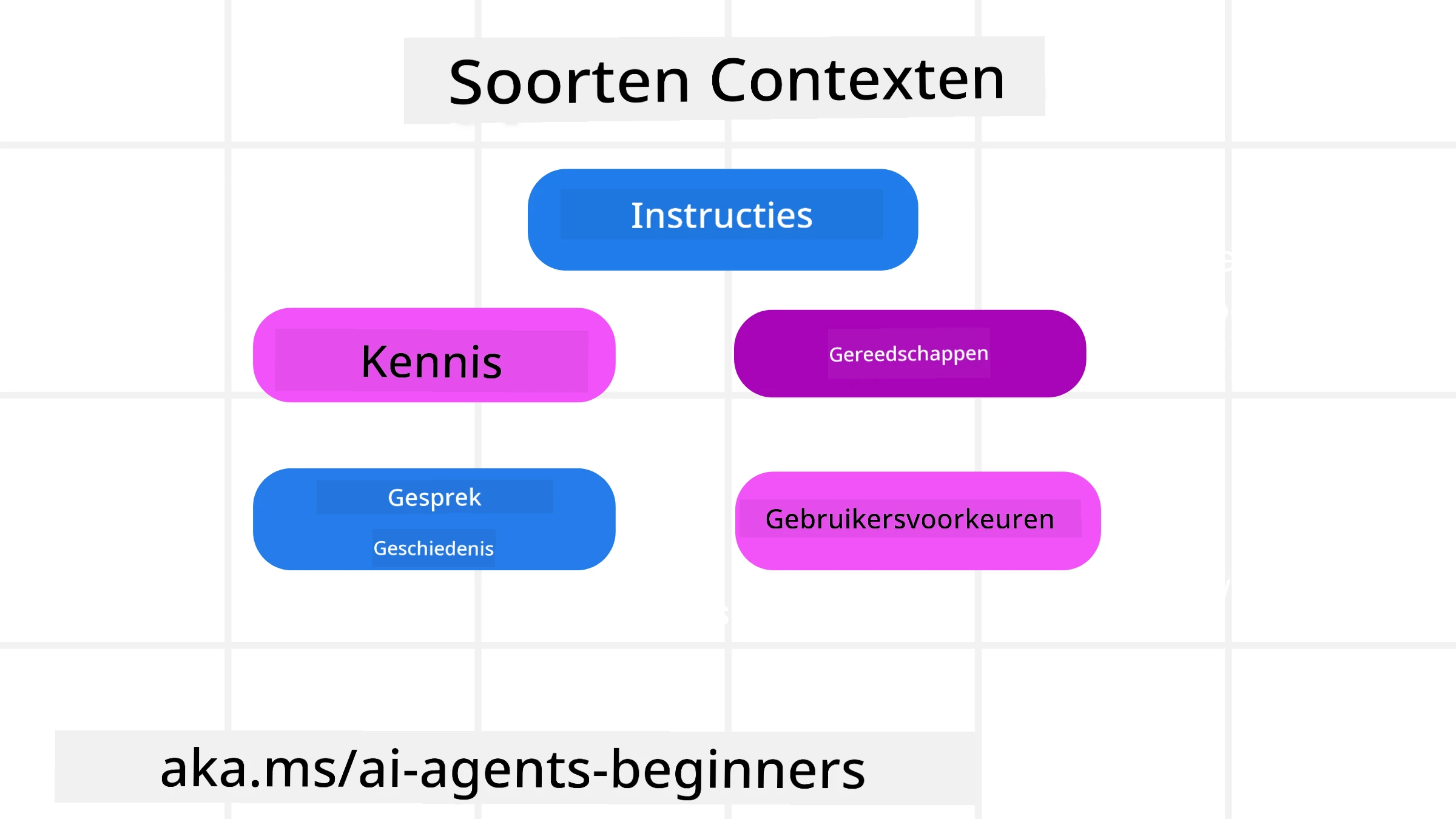
Het is belangrijk te onthouden dat context niet slechts één ding is. De informatie die de AI-agent nodig heeft kan uit verschillende bronnen komen en het is aan ons om ervoor te zorgen dat de agent toegang heeft tot deze bronnen:
De typen context die een AI-agent mogelijk moet beheren omvatten:
• Instructies: Dit zijn als het ware de “regels” van de agent – prompts, systeemberichten, few-shot voorbeelden (die de AI laten zien hoe iets te doen), en beschrijvingen van tools die de agent kan gebruiken. Dit is waar de focus van prompt-engineering samenkomt met contextengineering.
• Kennis: Dit omvat feiten, informatie opgehaald uit databases, of langetermijnherinneringen die de agent heeft opgebouwd. Dit omvat het integreren van een Retrieval Augmented Generation (RAG)-systeem als een agent toegang nodig heeft tot verschillende kennisopslagplaatsen en databases.
• Tools: Dit zijn de definities van externe functies, API’s en MCP Servers die de agent kan aanroepen, samen met de feedback (resultaten) die het krijgt van het gebruik ervan.
• Gesprekshistorie: De lopende dialoog met een gebruiker. Naarmate de tijd verstrijkt, worden deze gesprekken langer en complexer, wat betekent dat ze ruimte in het contextvenster innemen.
• Gebruikersvoorkeuren: Informatie die in de loop van de tijd wordt geleerd over iemands voorkeuren of afkeuren. Deze kunnen worden opgeslagen en opgevraagd bij het nemen van belangrijke beslissingen om de gebruiker te helpen.
Strategieën voor effectieve contextengineering
Planningsstrategieën
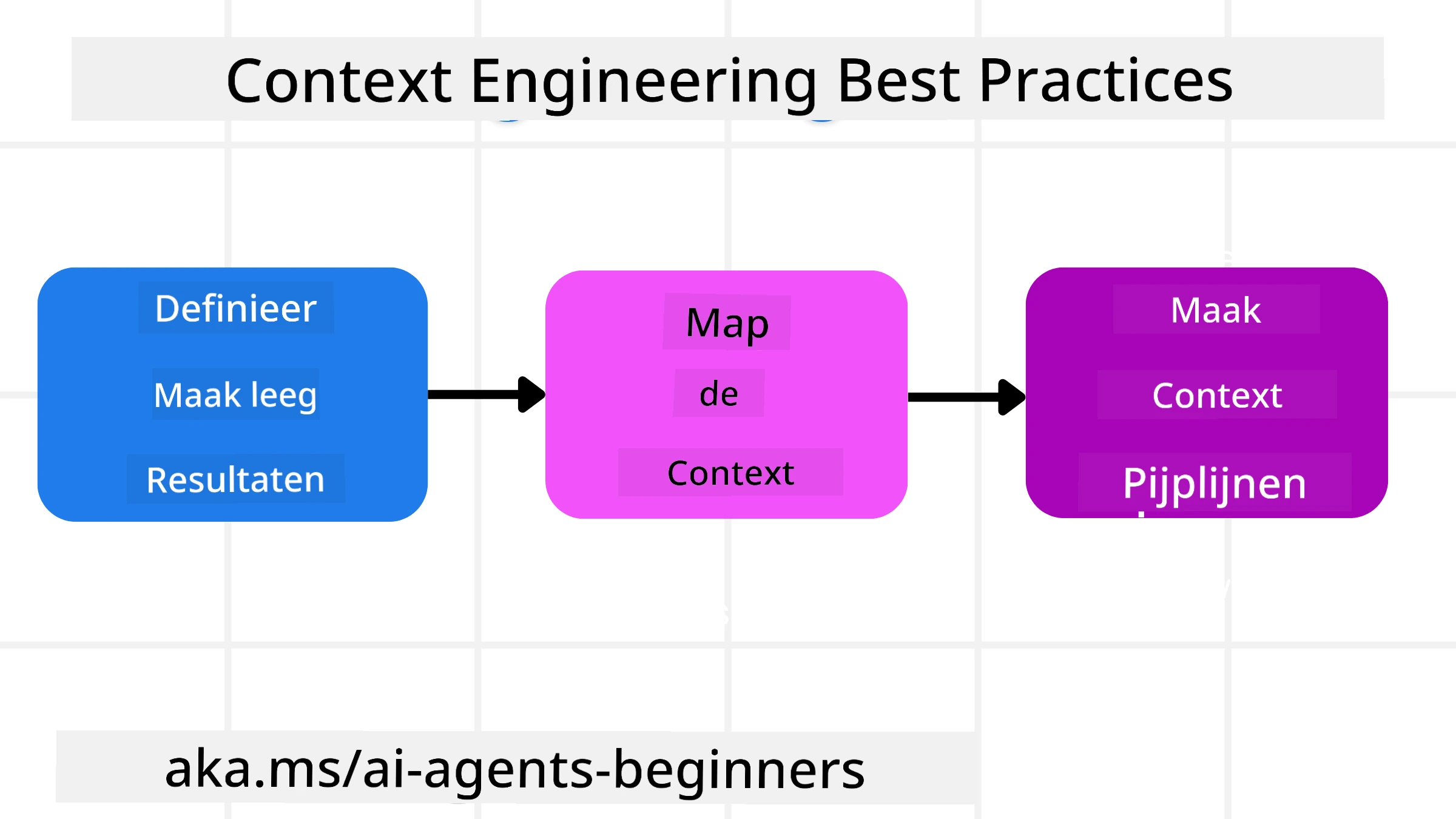
Goede contextengineering begint met goede planning. Hier is een benadering die je zal helpen na te denken over hoe je het concept contextengineering kunt toepassen:
- Definieer duidelijke resultaten - De resultaten van de taken die aan AI-agenten worden toegewezen moeten duidelijk worden gedefinieerd. Beantwoord de vraag - “Hoe ziet de wereld eruit wanneer de AI-agent klaar is met zijn taak?” Met andere woorden, welke verandering, informatie, of reactie moet de gebruiker hebben na interactie met de AI-agent.
- Breng de context in kaart - Zodra je de resultaten van de AI-agent hebt gedefinieerd, moet je de vraag beantwoorden van “Welke informatie heeft de AI-agent nodig om deze taak te voltooien?”. Op deze manier kun je beginnen de context in kaart te brengen van waar die informatie zich kan bevinden.
- Maak contextpijplijnen - Nu je weet waar de informatie is, moet je de vraag beantwoorden “Hoe krijgt de agent deze informatie?”. Dit kan op verschillende manieren worden gedaan, waaronder RAG, gebruik van MCP-servers en andere tools.
Praktische strategieën
Planning is belangrijk maar zodra de informatie in het contextvenster van onze agent begint binnen te stromen, hebben we praktische strategieën nodig om het te beheren:
Context beheren
Terwijl sommige informatie automatisch aan het contextvenster wordt toegevoegd, gaat contextengineering over het aannemen van een meer actieve rol ten aanzien van deze informatie, wat kan worden gedaan met een paar strategieën:
-
Agent Scratchpad Dit maakt het voor een AI-agent mogelijk om aantekeningen te maken van relevante informatie over de huidige taken en gebruikersinteracties gedurende een enkele sessie. Dit moet buiten het contextvenster bestaan in een bestand of runtime-object dat de agent later tijdens deze sessie kan ophalen indien nodig.
-
Herinneringen Scratchpads zijn goed voor het beheren van informatie buiten het contextvenster van een enkele sessie. Herinneringen stellen agenten in staat om relevante informatie op te slaan en op te halen over meerdere sessies. Dit kan samenvattingen, gebruikersvoorkeuren en feedback omvatten voor toekomstige verbeteringen.
-
Context comprimeren Zodra het contextvenster groeit en bijna aan zijn limiet komt, kunnen technieken zoals samenvatting en trimmen worden gebruikt. Dit omvat ofwel het alleen behouden van de meest relevante informatie of het verwijderen van oudere berichten.
-
Multi-agentsystemen Het ontwikkelen van multi-agentsystemen is een vorm van contextengineering omdat elke agent zijn eigen contextvenster heeft. Hoe die context wordt gedeeld en doorgegeven aan verschillende agenten is iets anders om te plannen bij het bouwen van deze systemen.
-
Sandbox-omgevingen Als een agent code moet uitvoeren of grote hoeveelheden informatie in een document moet verwerken, kan dit veel tokens vergen om de resultaten te verwerken. In plaats van dit allemaal in het contextvenster op te slaan, kan de agent een sandbox-omgeving gebruiken die in staat is om deze code uit te voeren en alleen de resultaten en andere relevante informatie te lezen.
-
Runtime-statusobjecten Dit gebeurt door containers van informatie te creëren om situaties te beheren waarin de agent toegang tot bepaalde informatie nodig heeft. Voor een complexe taak stelt dit een agent in staat om de resultaten van elk subtaken stap voor stap op te slaan, waardoor de context alleen verbonden blijft met die specifieke subtaak.
Voorbeeld van contextengineering
Stel dat we een AI-agent willen die “Boek voor mij een reis naar Parijs.”
• Een eenvoudige agent die alleen prompt-engineering gebruikt zou misschien gewoon reageren: “Oké, wanneer wil je naar Parijs gaan?”. Het verwerkte alleen je directe vraag op het moment dat de gebruiker vroeg.
• Een agent die de contextengineeringstrategieën toepast zou veel meer doen. Voordat hij zelfs maar antwoordt, zou zijn systeem het volgende kunnen doen:
◦ Controleer je agenda op beschikbare data (het ophalen van realtimegegevens).
◦ Haal eerdere reisvoorkeuren op (uit langetermijngeheugen), zoals je favoriete luchtvaartmaatschappij, budget of de voorkeur voor directe vluchten.
◦ Identificeer beschikbare tools voor het boeken van vluchten en hotels.
- Vervolgens zou een voorbeeldantwoord kunnen zijn: “Hey [Your Name]! Ik zie dat je vrij bent de eerste week van oktober. Zal ik zoeken naar directe vluchten naar Parijs met [Preferred Airline] binnen je gebruikelijke budget van [Budget]?”. Dit rijkere, contextbewuste antwoord toont de kracht van contextengineering aan.
Veelvoorkomende contextfouten
Contextvergiftiging
Wat het is: Wanneer een hallucinatie (valse informatie gegenereerd door het LLM) of een fout de context binnendringt en herhaaldelijk wordt aangehaald, waardoor de agent onmogelijke doelen nastreeft of onzinstrategieën ontwikkelt.
Wat te doen: Implementeer contextvalidatie en isolatie. Valideer informatie voordat deze aan het langetermijngeheugen wordt toegevoegd. Als potentiële vergiftiging wordt gedetecteerd, begin dan nieuwe contextthreads om te voorkomen dat de foutieve informatie zich verspreidt.
Voorbeeld reisboeking: Je agent hallucinereert een directe vlucht van een klein lokaal vliegveld naar een verre internationale stad die in werkelijkheid geen internationale vluchten aanbiedt. Deze niet-bestaande vluchtgegevens worden in de context opgeslagen. Later, wanneer je de agent vraagt te boeken, blijft hij proberen tickets te vinden voor deze onmogelijke route, wat leidt tot herhaalde fouten.
Oplossing: Implementeer een stap die de bestaan van vluchten en routes valideert met een realtime-API voordat je de vluchtgegevens toevoegt aan de werkcontext van de agent. Als de validatie faalt, wordt de foutieve informatie “geïsoleerd” en niet verder gebruikt.
Contextafleiding
Wat het is: Wanneer de context zo groot wordt dat het model te veel focust op de opgebouwde geschiedenis in plaats van te gebruiken wat het tijdens de training leerde, wat leidt tot repetitieve of niet-helpende acties. Modellen kunnen fouten beginnen te maken zelfs voordat het contextvenster vol is.
Wat te doen: Gebruik contextsamenvatting. Periodiek comprimeer je geaccumuleerde informatie tot kortere samenvattingen, waarbij je belangrijke details behoudt en redundante geschiedenis verwijdert. Dit helpt de focus te “resetten”.
Voorbeeld reisboeking: Je hebt lange tijd verschillende droomreisbestemmingen besproken, inclusief een gedetailleerde verslaglegging van je backpackreis van twee jaar geleden. Wanneer je uiteindelijk vraagt om “vind voor mij een goedkope vlucht voor volgende maand,” raakt de agent verstrikt in de oude, irrelevante details en blijft vragen stellen over je backpackuitrusting of eerdere reisschema’s, waarbij hij je huidige verzoek verwaarloost.
Oplossing: Na een bepaald aantal beurten of wanneer de context te groot wordt, zou de agent de meest recente en relevante delen van het gesprek moeten samenvatten – met de nadruk op je huidige reisdata en bestemming – en die compacte samenvatting gebruiken voor de volgende LLM-aanroep, waarbij minder relevante historische chat wordt weggegooid.
Contextverwarring
Wat het is: Wanneer onnodige context, vaak in de vorm van te veel beschikbare tools, ertoe leidt dat het model slechte antwoorden genereert of irrelevante tools aanroept. Kleinere modellen zijn hier vooral vatbaar voor.
Wat te doen: Implementeer tool-loadoutbeheer met behulp van RAG-technieken. Sla toolbeschrijvingen op in een vector database en selecteer alleen de meest relevante tools voor elke specifieke taak. Onderzoek toont aan dat het beperken van toolselecties tot minder dan 30 effectief is.
Voorbeeld reisboeking: Je agent heeft toegang tot tientallen tools: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, etc. Je vraagt: “Wat is de beste manier om je te verplaatsen in Parijs?” Vanwege het grote aantal tools raakt de agent in de war en probeert hij book_flight binnen Parijs aan te roepen, of rent_car hoewel je de voorkeur geeft aan het openbaar vervoer, omdat de toolbeschrijvingen elkaar kunnen overlappen of hij simpelweg niet kan bepalen welke de beste is.
Oplossing: Gebruik RAG over toolbeschrijvingen. Wanneer je vraagt hoe je je in Parijs kunt verplaatsen, haalt het systeem dynamisch alleen de meest relevante tools op zoals rent_car of public_transport_info op basis van je vraag, en presenteert een gerichte “loadout” van tools aan de LLM.
Contextbotsing
Wat het is: Wanneer tegenstrijdige informatie binnen de context aanwezig is, wat leidt tot inconsistente redenering of slechte eindantwoorden. Dit gebeurt vaak wanneer informatie in fasen binnenkomt en vroege, onjuiste aannames in de context blijven staan.
Wat te doen: Gebruik context pruning en offloading. Pruning betekent het verwijderen van verouderde of tegenstrijdige informatie zodra nieuwe details binnenkomen. Offloading geeft het model een aparte “scratchpad” werkruimte om informatie te verwerken zonder de hoofdcontext te verrommelen.
Voorbeeld reisboeking: Je vertelt je agent aanvankelijk: “Ik wil in economy class vliegen.” Later in het gesprek verander je van gedachten en zeg je: “Eigenlijk, voor deze reis, laten we business class nemen.” Als beide instructies in de context blijven, kan de agent tegenstrijdige zoekresultaten krijgen of in de war raken over welke voorkeur prioriteit moet krijgen.
Oplossing: Implementeer context pruning. Wanneer een nieuwe instructie in tegenspraak is met een oude, wordt de oudere instructie verwijderd of expliciet overschreven in de context. Als alternatief kan de agent een scratchpad gebruiken om tegenstrijdige voorkeuren te verzoenen voordat hij beslist, zodat alleen de uiteindelijke, consistente instructie zijn acties stuurt.
Heb je meer vragen over contextengineering?
Sluit je aan bij de Microsoft Foundry Discord om andere deelnemers te ontmoeten, spreekuren bij te wonen en je vragen over AI-agenten beantwoord te krijgen.
Disclaimer: Dit document is vertaald met behulp van de AI-vertalingsdienst Co-op Translator. Hoewel we streven naar nauwkeurigheid, dient u zich ervan bewust te zijn dat geautomatiseerde vertalingen fouten of onnauwkeurigheden kunnen bevatten. Het oorspronkelijke document in de oorspronkelijke taal moet als de gezaghebbende bron worden beschouwd. Voor kritieke informatie wordt een professionele menselijke vertaling aanbevolen. Wij zijn niet aansprakelijk voor eventuele misverstanden of verkeerde interpretaties die voortvloeien uit het gebruik van deze vertaling.