ai-agents-for-beginners
Konteksteknikk for AI-agenter

(Klikk på bildet over for å se video av denne leksjonen)
Å forstå kompleksiteten i applikasjonen du bygger en AI-agent for, er viktig for å lage en pålitelig en. Vi må bygge AI-agenter som effektivt håndterer informasjon for å møte komplekse behov utover prompt engineering.
I denne leksjonen skal vi se på hva konteksteknikk er og hvilken rolle det har i bygging av AI-agenter.
Introduksjon
Denne leksjonen vil dekke:
• Hva konteksteknikk er og hvorfor det er annerledes enn prompt engineering.
• Strategier for effektiv konteksteknikk, inkludert hvordan man skriver, velger, komprimerer og isolerer informasjon.
• Vanlige kontekstfeil som kan sette AI-agenten din ut av kurs, og hvordan fikse dem.
Læringsmål
Etter å ha fullført denne leksjonen vil du forstå hvordan du:
• Definerer konteksteknikk og skiller det fra prompt engineering.
• Identifiserer nøkkelkomponentene i konteksten i applikasjoner med store språkmodeller (LLM).
• Bruker strategier for skriving, valg, komprimering og isolasjon av kontekst for å forbedre agentens ytelse.
• Gjenkjenner vanlige kontekstfeil som forgiftning, distraksjon, forvirring og konflikt, og implementerer mottiltak.
Hva er konteksteknikk?
For AI-agenter er kontekst det som driver planleggingen av AI-agenten for å utføre bestemte handlinger. Konteksteknikk er praksisen med å sikre at AI-agenten har riktig informasjon for å fullføre neste steg i oppgaven. Kontekstvinduet er begrenset i størrelse, så som agentutviklere må vi bygge systemer og prosesser for å håndtere å legge til, fjerne og kondensere informasjonen i kontekstvinduet.
Prompt Engineering vs Konteksteknikk
Prompt engineering fokuserer på et enkelt sett med statiske instruksjoner for effektivt å styre AI-agenter med et sett regler. Konteksteknikk handler om hvordan man håndterer et dynamisk sett av informasjon, inkludert den initielle prompten, for å sikre at AI-agenten har det den trenger over tid. Hovedideen med konteksteknikk er å gjøre denne prosessen gjentakbar og pålitelig.
Typer kontekst
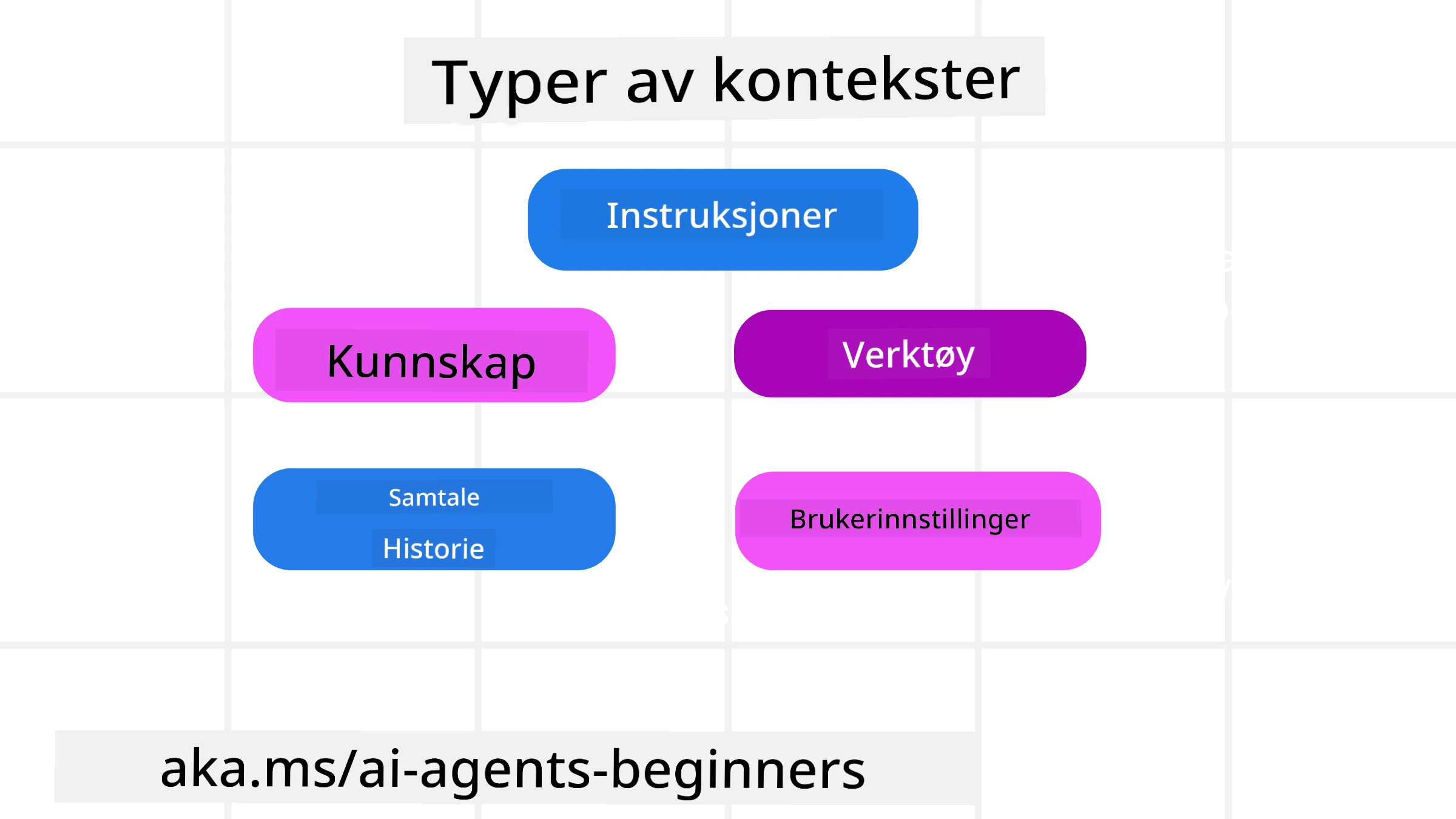
Det er viktig å huske at kontekst ikke bare er én ting. Informasjonen som AI-agenten trenger kan komme fra en rekke forskjellige kilder, og det er opp til oss å sikre at agenten har tilgang til disse kildene:
Typene kontekst en AI-agent kan trenge å håndtere inkluderer:
• Instruksjoner: Dette er som agentens “regler” – prompts, systemmeldinger, få-skudd-eksempler (som viser AI hvordan man gjør noe), og beskrivelser av verktøy den kan bruke. Her kombineres fokuset fra prompt engineering med konteksteknikk.
• Kunnskap: Dette dekker fakta, informasjon hentet fra databaser, eller langtidsminner agenten har opparbeidet. Dette inkluderer integrering av et Retrieval Augmented Generation (RAG)-system hvis en agent trenger tilgang til forskjellige kunnskapslager og databaser.
• Verktøy: Dette er definisjonene av eksterne funksjoner, API-er og MCP-servere som agenten kan kalle, sammen med tilbakemeldinger (resultater) den får ved å bruke dem.
• Samtalehistorikk: Den pågående dialogen med en bruker. Etter hvert som tiden går, blir disse samtalene lengre og mer komplekse, noe som betyr at de tar opp plass i kontekstvinduet.
• Brukerpreferanser: Informasjon som er lært om en brukers liker eller misliker over tid. Disse kan lagres og kalles opp når viktige beslutninger tas for å hjelpe brukeren.
Strategier for effektiv konteksteknikk
Planleggingsstrategier
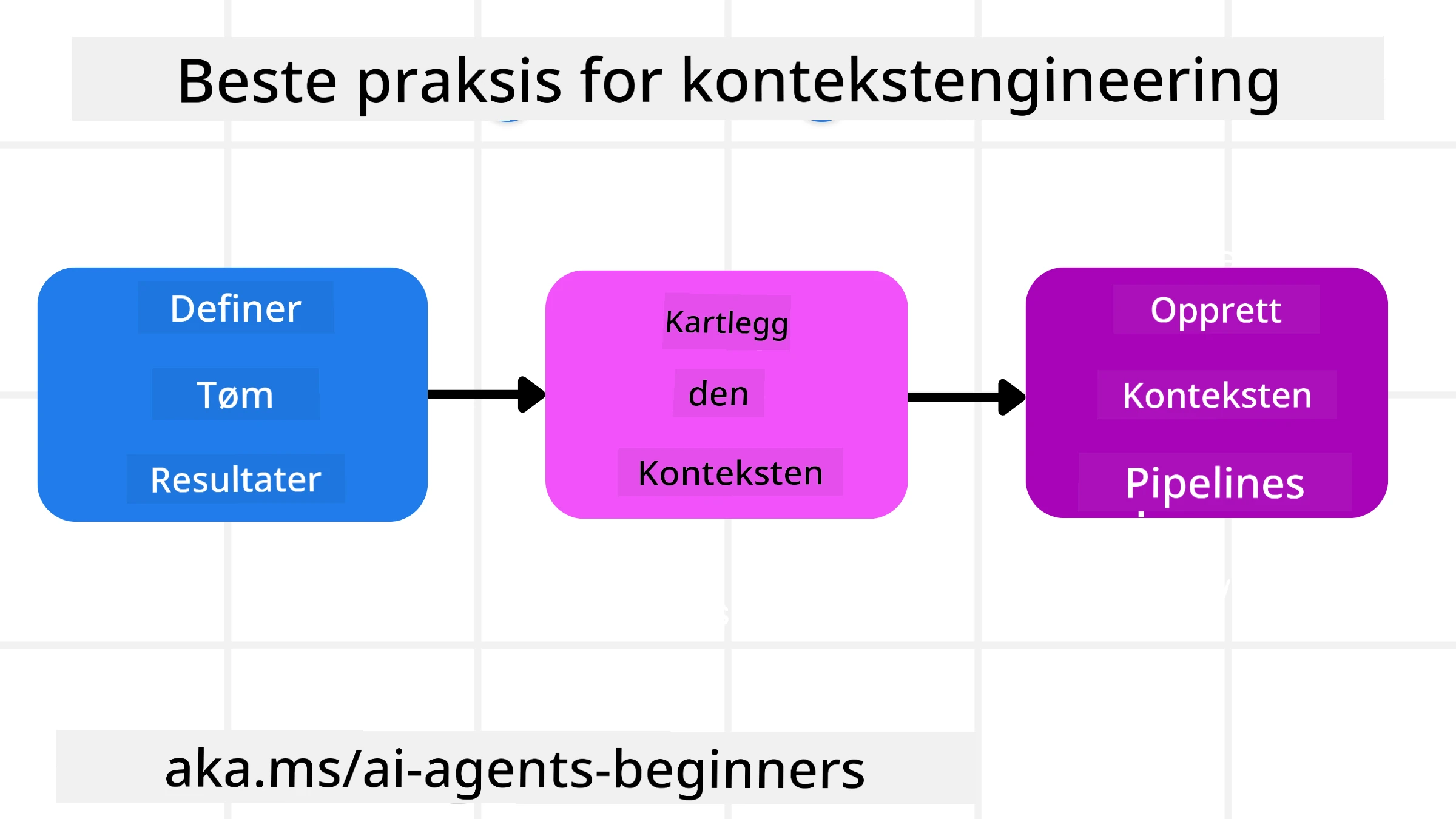
God konteksteknikk starter med god planlegging. Her er en tilnærming som vil hjelpe deg å begynne å tenke på hvordan du kan bruke konseptet konteksteknikk:
- Definer klare resultater - Resultatene av oppgavene AI-agentene skal utføre bør være klart definerte. Svar på spørsmålet – “Hvordan vil verden se ut når AI-agenten er ferdig med oppgaven sin?” Med andre ord, hvilken endring, informasjon eller respons bør brukeren ha etter interaksjon med AI-agenten.
- Kartlegg konteksten – Når du har definert resultatene til AI-agenten, må du besvare spørsmålet: “Hvilken informasjon trenger AI-agenten for å fullføre denne oppgaven?”. På denne måten kan du begynne å kartlegge hvor informasjonen kan finnes.
- Lag kontekstpipelines – Nå som du vet hvor informasjonen er, må du svare på spørsmålet “Hvordan vil agenten hente denne informasjonen?”. Dette kan gjøres på ulike måter, inkludert RAG, bruk av MCP-servere og andre verktøy.
Praktiske strategier
Planlegging er viktig, men når informasjonen begynner å strømme inn i agentens kontekstvindu, trenger vi praktiske strategier for å håndtere den:
Håndtering av kontekst
Mens noe informasjon automatisk legges til i kontekstvinduet, handler konteksteknikk om å ta en mer aktiv rolle i denne informasjonen, som kan gjøres med noen strategier:
-
Agentens notatblokk
Dette lar en AI-agent ta notater om relevant informasjon om gjeldende oppgaver og brukerinteraksjoner under en enkelt økt. Dette bør eksistere utenfor kontekstvinduet i en fil eller kjøretidsobjekt som agenten senere kan hente under denne økten om nødvendig. -
Minner
Notatblokker er gode for å håndtere informasjon utenfor kontekstvinduet i en enkelt økt. Minner gjør det mulig for agenter å lagre og hente relevant informasjon på tvers av flere økter. Dette kan inkludere sammendrag, brukerpreferanser og tilbakemeldinger for forbedringer i fremtiden. -
Kompresjon av kontekst
Når kontekstvinduet vokser og nærmer seg grensen, kan teknikker som oppsummering og trimming brukes. Dette inkluderer enten å beholde bare den mest relevante informasjonen eller å fjerne eldre meldinger. -
Multi-agent-systemer
Utvikling av multi-agent-system er en form for konteksteknikk fordi hver agent har sitt eget kontekstvindu. Hvordan den konteksten deles og overføres til forskjellige agenter er noe annet man må planlegge når disse systemene bygges. -
Sandkassemiljøer
Hvis en agent trenger å kjøre noe kode eller prosessere store mengder informasjon i et dokument, kan dette kreve mange tokens for å behandle resultatene. I stedet for å ha dette lagret i kontekstvinduet kan agenten bruke et sandkassemiljø som kan kjøre denne koden og kun lese resultatene og annen relevant informasjon. -
Objekter for kjøretidstilstand
Dette gjøres ved å lage containere av informasjon for å håndtere situasjoner når agenten trenger tilgang til bestemt informasjon. For en kompleks oppgave vil dette gjøre det mulig for agenten å lagre resultatene av hver deloppgave steg for steg, og la konteksten forbli koblet kun til den spesifikke deloppgaven.
Eksempel på konteksteknikk
La oss si at vi vil at en AI-agent skal “Booke en tur til Paris for meg.”
• En enkel agent som bare bruker prompt engineering kan bare svare: “Ok, når vil du reise til Paris?”. Den bearbeidet bare ditt direkte spørsmål på tidspunktet brukeren stilte det.
• En agent som bruker konteksteknikkstrategiene vi har dekket vil gjøre mye mer. Før den svarer, kan systemet for eksempel:
◦ Sjekke kalenderen din for tilgjengelige datoer (hente sanntidsdata).
◦ Huske tidligere reisepreferanser (fra langtidsminne), som favorittflyselskap, budsjett eller om du foretrekker direktefly.
◦ Identifisere tilgjengelige verktøy for fly- og hotellbestilling.
- Deretter kan et eksempel på svar være: “Hei [Ditt navn]! Jeg ser at du er ledig i første uke av oktober. Skal jeg se etter direktefly til Paris på [Foretrukket flyselskap] innen ditt vanlige budsjett på [Budsjett]?”. Dette rikere, kontekstbevisste svaret demonstrerer kraften i konteksteknikk.
Vanlige kontekstfeil
Kontekstforgiftning
Hva det er: Når en hallusinasjon (falsk informasjon generert av LLM) eller en feil kommer inn i konteksten og refereres til gjentatte ganger, slik at agenten prøver å oppnå umulige mål eller utvikler meningsløse strategier.
Hva man skal gjøre: Implementer kontekstvalidering og karantene. Validér informasjon før den legges til langtidsminnet. Hvis potensiell forgiftning oppdages, start nye konteksttråder for å forhindre at dårlig informasjon sprer seg.
Eksempel på reisebestilling: Agenten din hallusinerer en direkteflyvning fra en liten lokal flyplass til en fjern internasjonal by som faktisk ikke tilbyr internasjonale flyvninger. Denne ikke-eksisterende flydetaljen blir lagret i konteksten. Senere, når du ber agenten bestille, prøver den gjentatte ganger å finne billetter for denne umulige ruten, noe som fører til gjentatte feil.
Løsning: Implementer et steg som validerer flyets eksistens og ruter med en sanntids-API før flydetaljen legges til agentens arbeidskontekst. Hvis valideringen feiler, blir feilinformasjonen “karantinert” og ikke brukt videre.
Kontekstdistraksjon
Hva det er: Når konteksten blir så stor at modellen fokuserer for mye på den akkumulerte historikken i stedet for å bruke det den lærte under trening, noe som fører til repeterende eller uhjelpsomme handlinger. Modeller kan begynne å gjøre feil allerede før kontekstvinduet er fullt.
Hva man skal gjøre: Bruk kontekstoppsummering. Komprimer periodisk akkumulerte opplysninger til kortere sammendrag, behold viktige detaljer mens overflødig historie fjernes. Dette hjelper å “tilbakestille” fokuset.
Eksempel på reisebestilling: Du har diskutert ulike drømmereisemål i lang tid, inkludert en detaljert gjengivelse av ryggsekkreisen din for to år siden. Når du endelig ber om å “finne et billig fly neste måned,” blir agenten fanget i gamle, irrelevante detaljer og fortsetter å spørre om ryggsekkutstyret ditt eller tidligere reiseruter, og overser din nåværende forespørsel.
Løsning: Etter et visst antall omganger eller når konteksten blir for stor, bør agenten oppsummere de mest nylige og relevante delene av samtalen – med fokus på dine nåværende reisedatoer og destinasjon – og bruke dette kondenserte sammendraget for neste LLM-kall, og forkaste den mindre relevante historiske samtalen.
Kontekstforvirring
Hva det er: Når unødvendig kontekst, ofte i form av for mange tilgjengelige verktøy, får modellen til å generere dårlige svar eller å kalle irrelevante verktøy. Mindre modeller er spesielt utsatt for dette.
Hva man skal gjøre: Implementer verktøylasterstyring ved hjelp av RAG-teknikker. Lagre verktøybeskrivelser i en vektordatabase og velg kun de mest relevante verktøyene for hver spesifikke oppgave. Forskning viser at det hjelper å begrense verktøyvalg til færre enn 30.
Eksempel på reisebestilling: Agenten din har tilgang til dusinvis av verktøy: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, osv. Du spør, “Hva er den beste måten å komme seg rundt i Paris på?” På grunn av det store antallet verktøy blir agenten forvirret og prøver å kalle book_flight innenfor Paris, eller rent_car selv om du foretrekker offentlig transport, fordi verktøybeskrivelsene kan overlappe eller den rett og slett ikke klarer å skille ut det beste valget.
Løsning: Bruk RAG over verktøybeskrivelser. Når du spør om hvordan du kommer deg rundt i Paris, henter systemet dynamisk bare de mest relevante verktøyene som rent_car eller public_transport_info basert på spørringen din, og presenterer en fokusert “verktøylast” for LLM.
Kontekstkonflikt
Hva det er: Når motstridende informasjon finnes i konteksten, noe som fører til inkonsekvent resonnering eller dårlige endelige svar. Dette skjer ofte når informasjon kommer i stadier, og tidlige, feilaktige antakelser forblir i konteksten.
Hva man skal gjøre: Bruk kontekstbeskjæring og avlasting. Beskjæring betyr å fjerne utdatert eller motstridende informasjon når nye detaljer kommer. Avlasting gir modellen et eget “notatblokk”-arbeidsområde for å bearbeide informasjon uten å rote til hovedkonteksten.
Eksempel på reisebestilling: Du sier først til agenten, “Jeg vil fly økonomiklasse.” Senere i samtalen ombestemmer du deg og sier, “Egentlig, for denne turen, la oss gå businessklasse.” Hvis begge instruksjonene forblir i konteksten, kan agenten få motstridende søkresultater eller bli forvirret om hvilken preferanse som skal prioriteres.
Løsning: Implementer kontekstbeskjæring. Når en ny instruksjon motsier en gammel, fjernes den eldre instruksjonen eller overstyres eksplisitt i konteksten. Alternativt kan agenten bruke en notatblokk til å forene motstridende preferanser før den tar en beslutning, og sikrer at bare den endelige, konsekvente instruksen styrer handlingene.
Har du flere spørsmål om konteksteknikk?
Bli med i Microsoft Foundry Discord for å møte andre lærende, delta på kontortid og få svar på spørsmål om AI-agenter.
Ansvarsfraskrivelse: Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi streber etter nøyaktighet, vennligst vær oppmerksom på at automatiske oversettelser kan inneholde feil eller unøyaktigheter. Det opprinnelige dokumentet på dets opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for eventuelle misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.