ai-agents-for-beginners
Inżynieria kontekstu dla agentów AI

(Kliknij powyższy obraz, aby obejrzeć wideo z tej lekcji)
Zrozumienie złożoności aplikacji, dla której tworzysz agenta AI, jest ważne dla stworzenia niezawodnego rozwiązania. Musimy budować agentów AI, którzy efektywnie zarządzają informacjami, aby sprostać złożonym potrzebom wykraczającym poza inżynierię promptów.
W tej lekcji przyjrzymy się, czym jest inżynieria kontekstu i jaka jest jej rola w tworzeniu agentów AI.
Wprowadzenie
Ta lekcja obejmie:
• Czym jest inżynieria kontekstu i dlaczego różni się od inżynierii promptów.
• Strategie efektywnej inżynierii kontekstu, w tym jak pisać, wybierać, kompresować i izolować informacje.
• Typowe błędy w kontekście, które mogą zakłócić działanie agenta AI oraz jak je naprawić.
Cele nauki
Po ukończeniu tej lekcji będziesz rozumieć, jak:
• Zdefiniować inżynierię kontekstu i odróżnić ją od inżynierii promptów.
• Zidentyfikować kluczowe składniki kontekstu w aplikacjach wykorzystujących modele językowe (LLM).
• Stosować strategie pisania, wybierania, kompresji i izolowania kontekstu, aby poprawić wydajność agenta.
• Rozpoznawać powszechne błędy kontekstowe takie jak zatrucie, rozproszenie, zamieszanie i konflikt oraz wdrażać techniki ich łagodzenia.
Czym jest inżynieria kontekstu?
Dla agentów AI kontekst to to, co napędza planowanie agenta AI do podjęcia określonych działań. Inżynieria kontekstu to praktyka zapewniania, że agent AI ma odpowiednie informacje, aby wykonać kolejny krok zadania. Okno kontekstowe ma ograniczony rozmiar, dlatego jako twórcy agentów musimy tworzyć systemy i procesy do zarządzania dodawaniem, usuwaniem i kondensowaniem informacji w oknie kontekstu.
Inżynieria promptów a inżynieria kontekstu
Inżynieria promptów koncentruje się na pojedynczym zestawie statycznych instrukcji, które skutecznie kierują agentem AI zbioru reguł. Inżynieria kontekstu zajmuje się zarządzaniem dynamicznym zestawem informacji, w tym początkowym promptem, aby zapewnić agentowi AI to, czego potrzebuje z czasem. Główną ideą inżynierii kontekstu jest uczynienie tego procesu powtarzalnym i niezawodnym.
Rodzaje kontekstu
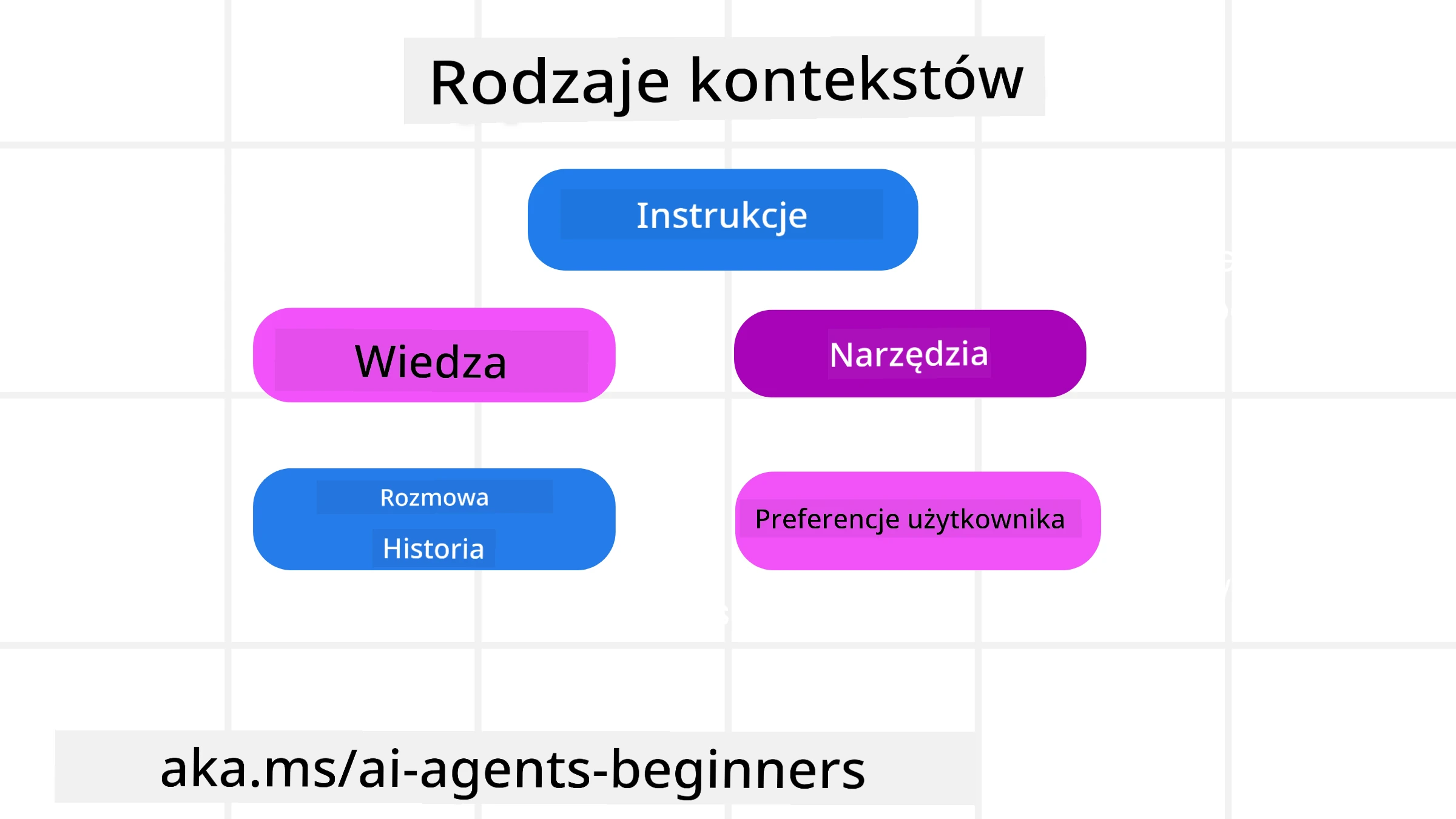
Ważne jest, aby pamiętać, że kontekst to nie tylko jedna rzecz. Informacje, których potrzebuje agent AI, mogą pochodzić z różnych źródeł i to do nas należy zapewnienie agenta dostępu do tych źródeł:
Rodzaje kontekstu, którymi agent AI może potrzebować zarządzać, obejmują:
• Instrukcje: Są jak „zasady” agenta – promptów, komunikaty systemowe, przykłady few-shot (pokazujące AI, jak coś zrobić) oraz opisy narzędzi, z których może korzystać. Tutaj inżynieria promptów łączy się z inżynierią kontekstu.
• Wiedza: Obejmuje fakty, informacje pobierane z baz danych lub długoterminowe pamięci zgromadzone przez agenta. Obejmuje to integrację systemu Retrieval Augmented Generation (RAG), jeśli agent potrzebuje dostępu do różnych źródeł wiedzy i baz danych.
• Narzędzia: To definicje zewnętrznych funkcji, API i serwerów MCP, które agent może wywołać, wraz z informacją zwrotną (wynikami) z ich wykorzystania.
• Historia rozmowy: Trwający dialog z użytkownikiem. Z upływem czasu te rozmowy stają się dłuższe i bardziej złożone, co zajmuje miejsce w oknie kontekstu.
• Preferencje użytkownika: Informacje poznane o upodobaniach lub niechęciach użytkownika w czasie. Mogą być przechowywane i wykorzystywane przy podejmowaniu kluczowych decyzji pomagających użytkownikowi.
Strategie efektywnej inżynierii kontekstu
Strategie planowania
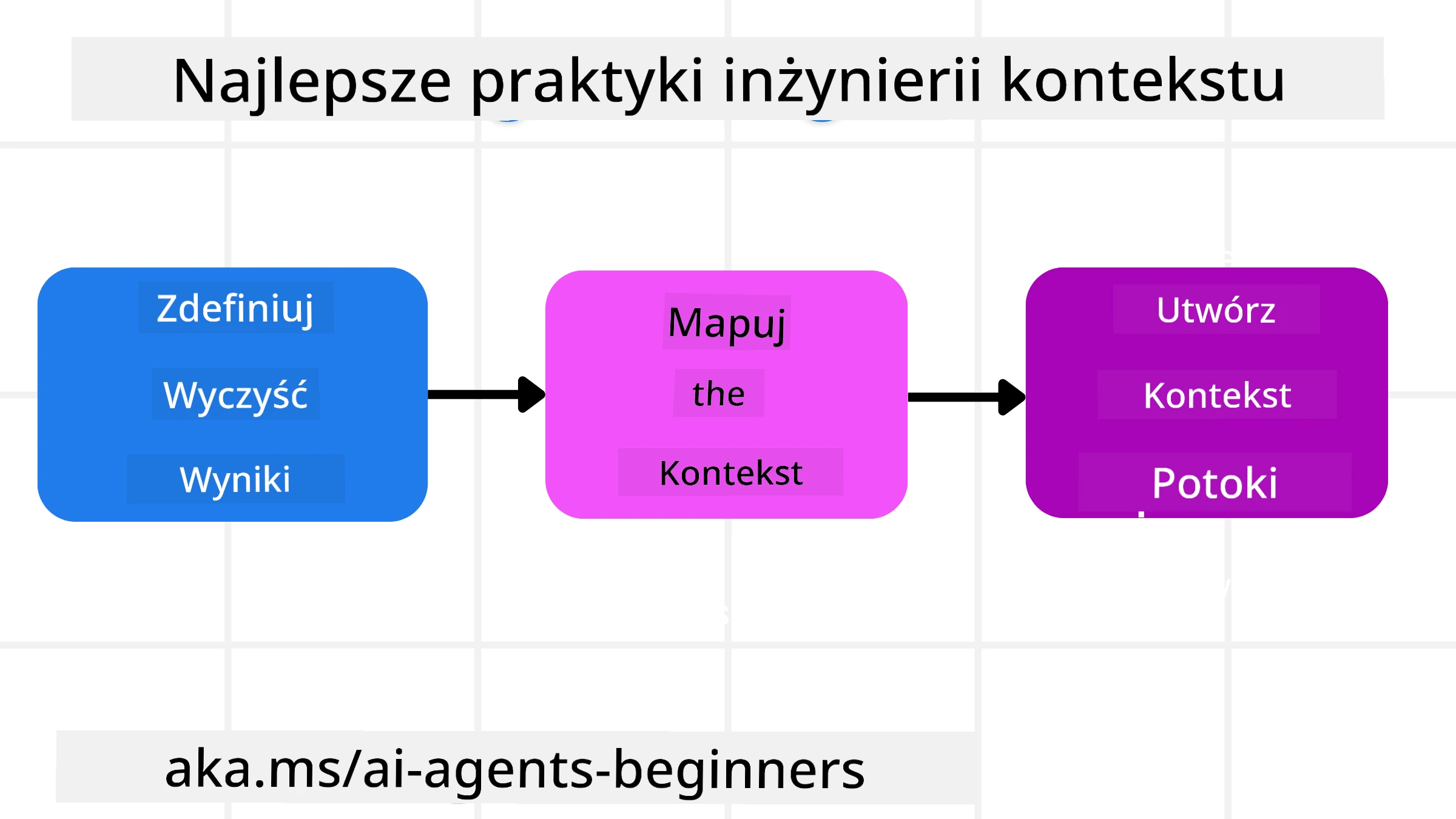
Dobra inżynieria kontekstu zaczyna się od dobrego planowania. Oto podejście, które pomoże Ci zacząć myśleć o zastosowaniu koncepcji inżynierii kontekstu:
-
Zdefiniuj jasne wyniki – wyniki zadań, które będą przypisane agentom AI powinny być jasno określone. Odpowiedz na pytanie – „Jak będzie wyglądał świat, gdy agent AI zakończy swoje zadanie?” Innymi słowy, jaką zmianę, informacje lub odpowiedź użytkownik powinien otrzymać po interakcji z agentem AI.
-
Zmapuj kontekst – gdy zdefiniujesz wyniki agenta AI, musisz odpowiedzieć na pytanie „Jakie informacje agent AI potrzebuje, aby ukończyć to zadanie?”. W ten sposób możesz zacząć mapować kontekst i lokalizacje tych informacji.
-
Stwórz potoki kontekstowe – gdy już wiesz, gdzie znajdują się informacje, musisz odpowiedzieć na pytanie „Jak agent zdobędzie te informacje?”. Można to zrobić na różne sposoby, w tym poprzez RAG, korzystanie z serwerów MCP i innych narzędzi.
Strategie praktyczne
Planowanie jest ważne, ale kiedy informacje zaczynają napływać do okna kontekstu naszego agenta, potrzebujemy praktycznych strategii do ich zarządzania:
Zarządzanie kontekstem
Choć niektóre informacje są automatycznie dodawane do okna kontekstu, inżynieria kontekstu polega na bardziej aktywnym podejściu do tych informacji, które można realizować za pomocą kilku strategii:
-
Notatnik agenta
Pozwala agentowi AI robić notatki dotyczące istotnych informacji o bieżących zadaniach i interakcjach z użytkownikiem podczas jednej sesji. Powinien istnieć poza oknem kontekstu, w pliku lub obiekcie uruchomieniowym, który agent może później odczytać podczas tej sesji w razie potrzeby. -
Pamięci
Notatniki dobrze służą do zarządzania informacjami poza oknem kontekstu jednej sesji. Pamięci umożliwiają agentom przechowywanie i odzyskiwanie istotnych informacji w wielu sesjach. Mogą to być podsumowania, preferencje użytkownika oraz feedback na potrzeby przyszłych ulepszeń. -
Kompresja kontekstu
Gdy okno kontekstu rośnie i zbliża się do limitu, można stosować techniki takie jak streszczenie i przycinanie. Obejmuje to zachowanie tylko najbardziej istotnych informacji lub usuwanie starszych wiadomości. -
Systemy wieloagentowe
Tworzenie systemów wieloagentowych jest formą inżynierii kontekstu, ponieważ każdy agent ma własne okno kontekstu. Jak ten kontekst jest udostępniany i przekazywany między agentami to kolejna kwestia do zaplanowania podczas budowy takich systemów. -
Środowiska piaskownicy
Jeśli agent musi uruchomić jakiś kod lub przetworzyć dużą ilość informacji w dokumencie, może to wymagać dużej liczby tokenów na przetworzenie wyników. Zamiast przechowywać to wszystko w oknie kontekstu, agent może użyć środowiska piaskownicy, które potrafi uruchomić ten kod i odczytać tylko wyniki oraz inne istotne informacje. -
Obiekty stanu runtime
Realizowane poprzez tworzenie kontenerów informacji do zarządzania sytuacjami, gdy agent musi mieć dostęp do określonych informacji. Dla złożonych zadań pozwala to agentowi przechowywać wyniki każdego podzadania krok po kroku, dzięki czemu kontekst pozostaje powiązany tylko z tym konkretnym podzadaniem.
Przykład inżynierii kontekstu
Powiedzmy, że chcemy, aby agent AI „Zarezerwował mi podróż do Paryża.”
• Prosty agent korzystający wyłącznie z inżynierii promptów może po prostu odpowiedzieć: „Dobrze, na kiedy chcesz lecieć do Paryża?”. Przetworzył tylko twoje bezpośrednie pytanie w momencie, gdy zostało zadane.
• Agent korzystający ze strategii inżynierii kontekstu opisywanych tutaj zrobi o wiele więcej. Zanim odpowie, jego system może:
◦ Sprawdzić twój kalendarz pod kątem dostępnych terminów (pozyskując dane w czasie rzeczywistym).
◦ Przypomnieć sobie wcześniejsze preferencje podróżnicze (z pamięci długoterminowej), takie jak ulubiona linia lotnicza, budżet czy preferencje dotyczące lotów bezpośrednich.
◦ Zidentyfikować dostępne narzędzia do rezerwacji lotów i hoteli.
- Następnie przykładowa odpowiedź mogłaby brzmieć: „Cześć [Twoje Imię]! Widzę, że jesteś dostępny w pierwszym tygodniu października. Czy mam szukać lotów bezpośrednich do Paryża na [preferowana linia lotnicza] mieszczących się w twoim zwykłym budżecie [budżet]?”. Ta bogatsza, świadoma kontekstu odpowiedź pokazuje siłę inżynierii kontekstu.
Typowe błędy związane z kontekstem
Zatrucie kontekstu
Co to jest: Gdy halucynacja (fałszywa informacja wygenerowana przez LLM) lub błąd wchodzi do kontekstu i jest wielokrotnie powtarzany, powodując, że agent dąży do niemożliwych celów lub tworzy nonsensowne strategie.
Co robić: Wdróż walidację kontekstu i izolację. Sprawdzaj informacje przed dodaniem ich do pamięci długoterminowej. Jeśli wykryjesz potencjalne zatrucie, zacznij nowe wątki kontekstowe, aby zapobiec rozprzestrzenianiu się złych informacji.
Przykład rezerwacji podróży: Twój agent „halucynuje” bezpośredni lot z małego lokalnego lotniska do odległego miasta międzynarodowego, które faktycznie nie obsługuje lotów międzynarodowych. Ten nieistniejący lot zostaje zapisany w kontekście. Później, gdy prosisz agenta o rezerwację, próbuje znaleźć bilety na tę niemożliwą trasę, co skutkuje powtarzającymi się błędami.
Rozwiązanie: Wdróż etap, który sprawdza istnienie lotu i trasy za pomocą API w czasie rzeczywistym przed dodaniem szczegółów lotu do kontekstu roboczego agenta. Jeśli walidacja się nie powiedzie, błędna informacja jest „izolowana” i nie jest dalej używana.
Rozproszenie kontekstu
Co to jest: Kiedy kontekst staje się tak duży, że model zbytnio skupia się na zgromadzonej historii zamiast wykorzystywać to, czego nauczył się podczas treningu, prowadząc do powtarzalnych lub niepomocnych działań. Modele mogą zacząć popełniać błędy nawet zanim okno kontekstowe się zapełni.
Co robić: Stosuj streszczenie kontekstu. Okresowo kompresuj zgromadzone informacje do krótszych podsumowań, zachowując ważne szczegóły, a usuwając nadmiarową historię. Pomaga to „zresetować” skupienie.
Przykład rezerwacji podróży: Dyskutujesz od dłuższego czasu o różnych wymarzonych miejscach podróży, w tym szczegółowo opisujesz swoją wyprawę z plecakiem sprzed dwóch lat. Gdy w końcu prosisz, aby „znalazł mi tani lot na następny miesiąc”, agent zostaje przytłoczony starymi, nieistotnymi szczegółami i ciągle pyta o twój sprzęt podróżniczy lub wcześniejsze plany, ignorując aktualne żądanie.
Rozwiązanie: Po określonej liczbie wymian lub gdy kontekst staje się zbyt duży, agent powinien podsumować najnowsze i najbardziej istotne fragmenty rozmowy – skupiając się na obecnych datach podróży i celu – i użyć tego skondensowanego podsumowania do następnego wywołania LLM, odrzucając mniej istotną historię.
Zamieszanie w kontekście
Co to jest: Gdy niepotrzebny kontekst, często w formie zbyt dużej liczby dostępnych narzędzi, powoduje, że model generuje złe odpowiedzi lub wywołuje nieistotne narzędzia. Mniejsze modele są szczególnie podatne na to.
Co robić: Wdróż zarządzanie zestawem narzędzi przy użyciu technik RAG. Przechowuj opisy narzędzi w bazie wektorowej i wybieraj tylko najbardziej odpowiednie narzędzia do konkretnego zadania. Badania pokazują, że ograniczenie wyboru narzędzi do poniżej 30 jest optymalne.
Przykład rezerwacji podróży: Twój agent ma dostęp do dziesiątek narzędzi: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations itd. Pytasz: „Jaki jest najlepszy sposób poruszania się po Paryżu?” Z powodu ogromu narzędzi, agent się gubi i próbuje wywołać book_flight w obrębie Paryża, albo rent_car, mimo że preferujesz transport publiczny, ponieważ opisy narzędzi mogą się pokrywać lub po prostu nie potrafi wybrać najlepszego.
Rozwiązanie: Używaj RAG na opisach narzędzi. Gdy pytasz o poruszanie się po Paryżu, system dynamicznie pobiera tylko najbardziej odpowiednie narzędzia takie jak rent_car lub public_transport_info na podstawie twojego zapytania, przedstawiając LLM skoncentrowany „zestaw” narzędzi.
Konflikt kontekstu
Co to jest: Gdy w kontekście istnieją sprzeczne informacje, prowadzące do niespójnego rozumowania lub złych końcowych odpowiedzi. Często zdarza się to, gdy informacje pojawiają się etapami, a wczesne, błędne założenia pozostają w kontekście.
Co robić: Stosuj przycinanie kontekstu i odciążanie. Przycinanie polega na usuwaniu przestarzałych lub sprzecznych informacji wraz z pojawieniem się nowych danych. Odciążanie daje modelowi oddzielne „pole robocze” (scratchpad) do przetwarzania informacji bez zaśmiecania głównego kontekstu.
Przykład rezerwacji podróży: Początkowo mówisz agentowi: „Chcę lecieć klasą ekonomiczną.” Później zmieniasz zdanie i mówisz: „Właściwie to na tę podróż weźmy klasę biznes.” Jeśli oba polecenia pozostaną w kontekście, agent może otrzymać sprzeczne wyniki wyszukiwania lub nie wiedzieć, którą preferencję priorytetyzować.
Rozwiązanie: Wdróż przycinanie kontekstu. Gdy nowe polecenie sprzeciwia się poprzedniemu, starsza instrukcja jest usuwana lub wyraźnie zastępowana w kontekście. Alternatywnie agent może użyć notatnika (scratchpad) do pogodzenia sprzecznych preferencji przed podjęciem decyzji, co zapewnia, że tylko ostateczna, spójna instrukcja kieruje jego działaniami.
Masz więcej pytań o inżynierię kontekstu?
Dołącz do Microsoft Foundry Discord, aby spotkać innych uczących się, uczestniczyć w godzinach konsultacji i uzyskać odpowiedzi na pytania dotyczące agentów AI.
Zastrzeżenie:
Dokument ten został przetłumaczony przy użyciu automatycznej usługi tłumaczeniowej AI Co-op Translator. Choć dokładamy starań, aby tłumaczenie było jak najbardziej precyzyjne, prosimy pamiętać, że tłumaczenia automatyczne mogą zawierać błędy lub nieścisłości. Oryginalny dokument w jego języku źródłowym powinien być uznawany za źródło wiążące. W przypadku informacji krytycznych zaleca się skorzystanie z profesjonalnego, ludzkiego tłumaczenia. Nie ponosimy odpowiedzialności za jakiekolwiek nieporozumienia lub błędne interpretacje wynikające z korzystania z tego tłumaczenia.