ai-agents-for-beginners
Engenharia de Contexto para Agentes de IA

(Clique na imagem acima para ver o vídeo desta aula)
Entender a complexidade da aplicação para a qual você está construindo um agente de IA é importante para tornar esse agente confiável. Precisamos construir Agentes de IA que gerenciem informações de forma eficaz para atender necessidades complexas além da engenharia de prompts.
Nesta aula, veremos o que é engenharia de contexto e seu papel na construção de agentes de IA.
Introduction
Esta aula abordará:
• O que é Engenharia de Contexto e por que é diferente da engenharia de prompts.
• Estratégias para uma Engenharia de Contexto eficaz, incluindo como escrever, selecionar, comprimir e isolar informações.
• Falhas Comuns de Contexto que podem atrapalhar seu agente de IA e como corrigi-las.
Learning Goals
Após concluir esta aula, você saberá e entenderá como:
• Definir engenharia de contexto e diferenciá-la da engenharia de prompts.
• Identificar os componentes-chave do contexto em aplicações com Large Language Models (LLMs).
• Aplicar estratégias para escrever, selecionar, comprimir e isolar contexto para melhorar o desempenho do agente.
• Reconhecer falhas comuns de contexto como envenenamento, distração, confusão e conflito, e implementar técnicas de mitigação.
What is Context Engineering?
Para Agentes de IA, contexto é o que direciona o planejamento do Agente de IA para tomar certas ações. Engenharia de Contexto é a prática de garantir que o Agente de IA tenha as informações corretas para completar a próxima etapa da tarefa. A janela de contexto é limitada em tamanho, então, como construtores de agentes, precisamos criar sistemas e processos para gerenciar a adição, remoção e condensação das informações na janela de contexto.
Prompt Engineering vs Context Engineering
Engenharia de prompts foca em um conjunto único de instruções estáticas para guiar efetivamente os Agentes de IA com um conjunto de regras. Engenharia de contexto é como gerenciar um conjunto dinâmico de informações, incluindo o prompt inicial, para garantir que o Agente de IA tenha o que precisa ao longo do tempo. A ideia principal em torno da engenharia de contexto é tornar esse processo repetível e confiável.
Types of Context
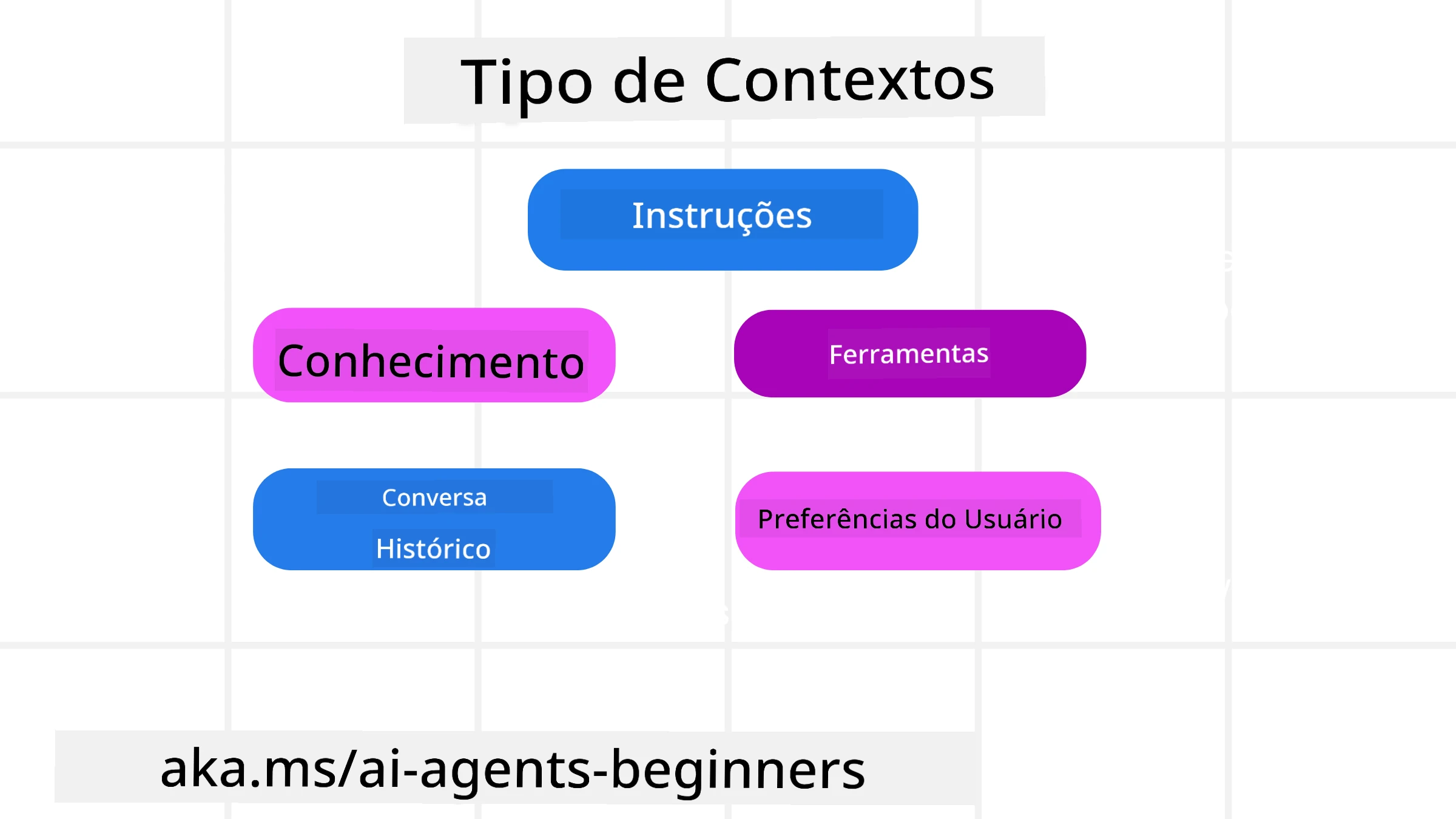
É importante lembrar que contexto não é apenas uma coisa. A informação que o Agente de IA precisa pode vir de uma variedade de fontes diferentes e cabe a nós garantir que o agente tenha acesso a essas fontes:
Os tipos de contexto que um agente de IA pode precisar gerenciar incluem:
• Instruções: Estas são como as “regras” do agente – prompts, mensagens do sistema, exemplos few-shot (mostrando ao IA como fazer algo) e descrições de ferramentas que ele pode usar. É aqui que o foco da engenharia de prompts se combina com a engenharia de contexto.
• Conhecimento: Isso cobre fatos, informações recuperadas de bancos de dados ou memórias de longo prazo que o agente acumulou. Isso inclui integrar um sistema Retrieval Augmented Generation (RAG) se um agente precisar acessar diferentes repositórios de conhecimento e bancos de dados.
• Ferramentas: Estas são as definições de funções externas, APIs e MCP Servers que o agente pode chamar, junto com o feedback (resultados) que ele obtém ao usá-las.
• Histórico de Conversa: O diálogo contínuo com um usuário. À medida que o tempo passa, essas conversas ficam mais longas e complexas, o que significa que ocupam espaço na janela de contexto.
• Preferências do Usuário: Informações aprendidas sobre gostos ou desgostos de um usuário ao longo do tempo. Isso pode ser armazenado e recuperado ao tomar decisões-chave para ajudar o usuário.
Strategies for Effective Context Engineering
Planning Strategies
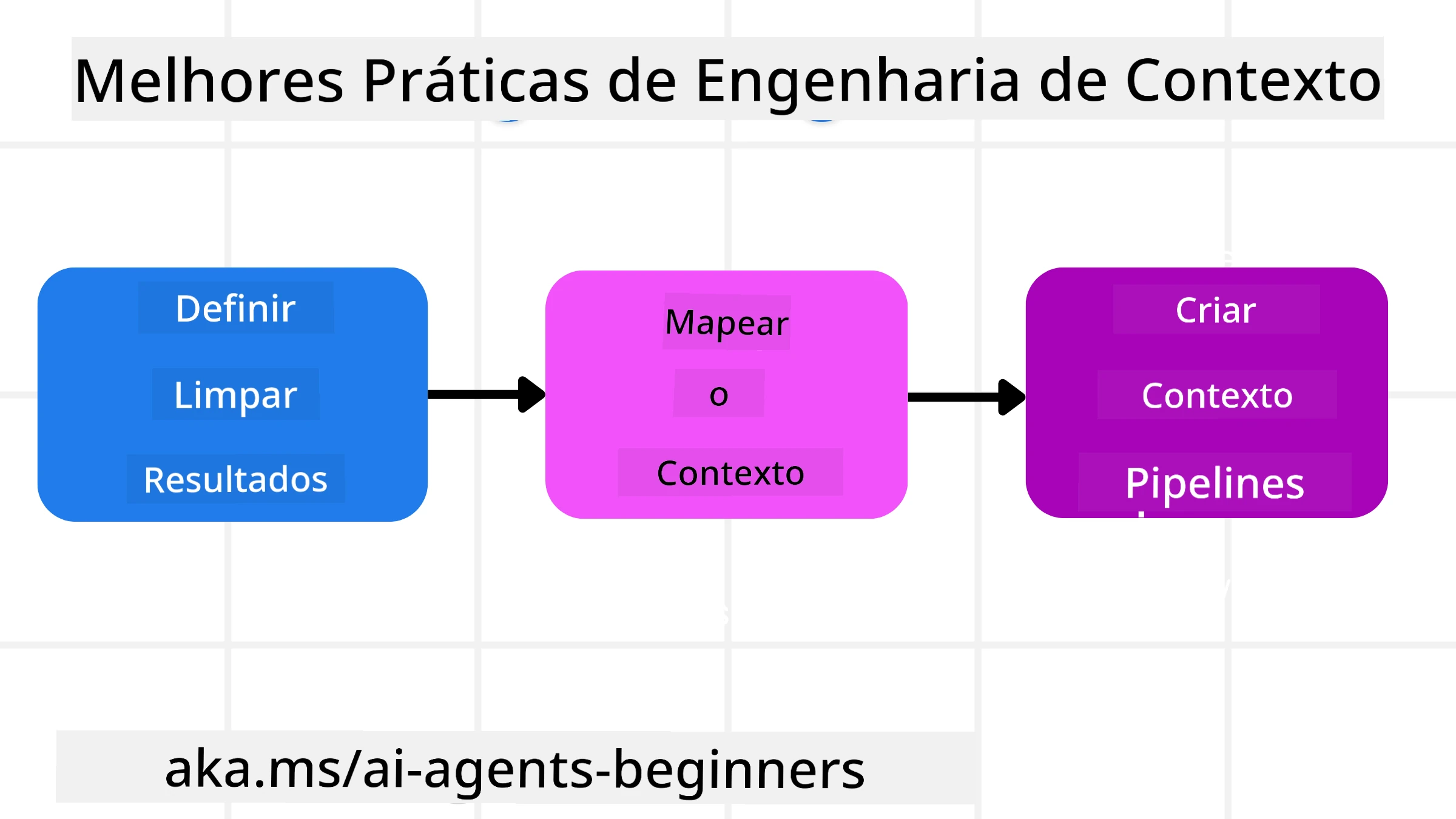
Boa engenharia de contexto começa com um bom planejamento. Aqui está uma abordagem que ajudará você a começar a pensar em como aplicar o conceito de engenharia de contexto:
- Define Clear Results - Os resultados das tarefas que os Agentes de IA irão executar devem ser claramente definidos. Responda à pergunta - “Como o mundo estará quando o Agente de IA terminar sua tarefa?” Em outras palavras, qual mudança, informação ou resposta o usuário deve ter após interagir com o Agente de IA.
- Map the Context - Depois de definir os resultados do Agente de IA, você precisa responder à pergunta “Quais informações o Agente de IA precisa para completar esta tarefa?”. Dessa forma você pode começar a mapear o contexto de onde essas informações podem ser encontradas.
- Create Context Pipelines - Agora que você sabe onde está a informação, precisa responder à pergunta “Como o Agente obterá essa informação?”. Isso pode ser feito de várias maneiras, incluindo RAG, uso de MCP servers e outras ferramentas.
Practical Strategies
Planejamento é importante, mas uma vez que a informação começa a fluir para a janela de contexto do nosso agente, precisamos ter estratégias práticas para gerenciá-la:
Managing Context
Enquanto algumas informações serão adicionadas à janela de contexto automaticamente, a engenharia de contexto trata de assumir um papel mais ativo sobre essas informações, o que pode ser feito por algumas estratégias:
-
Agent Scratchpad This allows for an AI Agent to takes notes of relevant information about the current tasks and user interactions during a single session. This should exist outside of the context window in a file or runtime object that the agent can later retrieve during this session if needed.
-
Memories Scratchpads are good for managing information outside of the context window of a single session. Memories enable agents to store and retrieve relevant information across multiple sessions. This could include summaries, user preferences and feedback for improvements in the future.
-
Compressing Context Once the context window grows and is nearing its limit, techniques such as summarization and trimming can be used. This includes either keeping only the most relevant information or removing older messages.
-
Multi-Agent Systems Developing multi-agent system is a form of context engineering because each agent has its own context window. How that context is shared and passed to different agents is another thing to plan out when building these systems.
-
Sandbox Environments If an agent needs to run some code or process large amounts of information in a document, this can take a large amount of tokens to process the results. Instead of having this all stored in the context window, the agent can use a sandbox environment that is able to run this code and only read the results and other relevant information.
-
Runtime State Objects This is done by creating containers of information to manage situations when the Agent needs to have access to certain information. For a complex task, this would enable an Agent to store the results of each subtask step by step, allowing the context to remain connected only to that specific subtask.
Example of Context Engineering
Let’s say we want an AI agent to “Reserve-me uma viagem para Paris.”
• A simple agent using only prompt engineering might just respond: “Ok, quando você gostaria de ir para Paris?”. It only processed your direct question at the time that the user asked.
• An agent using the context engineering strategies covered would do much more. Before even responding, its system might:
◦ Check your calendar for available dates (retrieving real-time data).
◦ Recall past travel preferences (from long-term memory) like your preferred airline, budget, or whether you prefer direct flights.
◦ Identify available tools for flight and hotel booking.
- Then, an example response could be: “Ei [Your Name]! Vejo que você está livre na primeira semana de outubro. Posso procurar voos diretos para Paris pela [Preferred Airline] dentro do seu orçamento habitual de [Budget]?”. This richer, context-aware response demonstrates the power of context engineering.
Common Context Failures
Context Poisoning
What it is: When a hallucination (false information generated by the LLM) or an error enters the context and is repeatedly referenced, causing the agent to pursue impossible goals or develop nonsense strategies.
What to do: Implement context validation and quarantine. Validate information before it’s added to long-term memory. If potential poisoning is detected, start fresh context threads to prevent the bad information from spreading.
Travel Booking Example: Your agent hallucinates a direct flight from a small local airport to a distant international city that doesn’t actually offer international flights. This non-existent flight detail gets saved into the context. Later, when you ask the agent to book, it keeps trying to find tickets for this impossible route, leading to repeated errors.
Solution: Implement a step that validates flight existence and routes with a real-time API before adding the flight detail to the agent’s working context. If the validation fails, the erroneous information is “quarantined” and not used further.
Context Distraction
What it is: When the context becomes so large that the model focuses too much on the accumulated history instead of using what it learned during training, leading to repetitive or unhelpful actions. Models may begin making mistakes even before the context window is full.
What to do: Use context summarization. Periodically compress accumulated information into shorter summaries, keeping important details while removing redundant history. This helps “reset” the focus.
Travel Booking Example: You’ve been discussing various dream travel destinations for a long time, including a detailed recounting of your backpacking trip from two years ago. When you finally ask to “encontre-me um voo barato para no próximo mês,” the agent gets bogged down in the old, irrelevant details and keeps asking about your backpacking gear or past itineraries, neglecting your current request.
Solution: After a certain number of turns or when the context grows too large, the agent should summarize the most recent and relevant parts of the conversation – focusing on your current travel dates and destination – and use that condensed summary for the next LLM call, discarding the less relevant historical chat.
Context Confusion
What it is: When unnecessary context, often in the form of too many available tools, causes the model to generate bad responses or call irrelevant tools. Smaller models are especially prone to this.
What to do: Implement tool loadout management using RAG techniques. Store tool descriptions in a vector database and select only the most relevant tools for each specific task. Research shows limiting tool selections to fewer than 30.
Travel Booking Example: Your agent has access to dozens of tools: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, etc. You ask, “What’s the best way to get around Paris?” Due to the sheer number of tools, the agent gets confused and attempts to call book_flight within Paris, or rent_car even though you prefer public transport, because the tool descriptions might overlap or it simply can’t discern the best one.
Solution: Use RAG over tool descriptions. When you ask about getting around Paris, the system dynamically retrieves only the most relevant tools like rent_car or public_transport_info based on your query, presenting a focused “loadout” of tools to the LLM.
Context Clash
What it is: When conflicting information exists within the context, leading to inconsistent reasoning or bad final responses. This often happens when information arrives in stages, and early, incorrect assumptions remain in the context.
What to do: Use context pruning and offloading. Pruning means removing outdated or conflicting information as new details arrive. Offloading gives the model a separate “scratchpad” workspace to process information without cluttering the main context.
Travel Booking Example: You initially tell your agent, “I want to fly economy class.” Later in the conversation, you change your mind and say, “Actually, for this trip, let’s go business class.” If both instructions remain in the context, the agent might receive conflicting search results or get confused about which preference to prioritize.
Solution: Implement context pruning. When a new instruction contradicts an old one, the older instruction is removed or explicitly overridden in the context. Alternatively, the agent can use a scratchpad to reconcile conflicting preferences before deciding, ensuring only the final, consistent instruction guides its actions.
Got More Questions About Context Engineering?
Join the Microsoft Foundry Discord to meet with other learners, attend office hours and get your AI Agents questions answered.
Isenção de responsabilidade: Este documento foi traduzido usando o serviço de tradução por IA Co-op Translator (https://github.com/Azure/co-op-translator). Embora nos esforcemos para garantir a precisão, esteja ciente de que traduções automatizadas podem conter erros ou imprecisões. O documento original em seu idioma nativo deve ser considerado a fonte autorizada. Para informações críticas, recomenda-se tradução profissional realizada por um tradutor humano. Não nos responsabilizamos por quaisquer mal-entendidos ou interpretações incorretas decorrentes do uso desta tradução.