ai-agents-for-beginners
Ingineria Contextului pentru Agenții AI

(Faceți clic pe imaginea de mai sus pentru a viziona videoclipul acestei lecții)
Înțelegerea complexității aplicației pentru care construiți un agent AI este importantă pentru a crea unul de încredere. Trebuie să construim agenți AI care să gestioneze eficient informațiile pentru a aborda nevoi complexe dincolo de ingineria promptului.
În această lecție, vom analiza ce este ingineria contextului și rolul său în construirea agenților AI.
Introducere
Această lecție va acoperi:
• Ce este Ingineria Contextului și de ce este diferită de ingineria promptului.
• Strategii pentru Ingineria Contextului eficientă, inclusiv cum să scrii, selectezi, comprimi și izolezi informațiile.
• Eșecuri comune ale contextului care pot deraia agentul AI și cum să le rezolvi.
Obiectivele Învățării
După finalizarea acestei lecții, veți înțelege cum să:
• Definești ingineria contextului și să o diferențiezi de ingineria promptului.
• Identifici componentele cheie ale contextului în aplicațiile de modele lingvistice mari (LLM).
• Aplici strategii pentru scrierea, selectarea, comprimarea și izolarea contextului pentru a îmbunătăți performanța agentului.
• Recunoști eșecurile comune ale contextului precum otrăvirea, distragerea, confuzia și conflictele, și să implementezi tehnici de atenuare.
Ce este Ingineria Contextului?
Pentru agenții AI, contextul este ceea ce determină planificarea unui agent AI de a lua anumite acțiuni. Ingineria Contextului este practica de a asigura că agentul AI are informațiile potrivite pentru a finaliza următorul pas al sarcinii. Fereastra de context este limitată ca dimensiune, așa că, ca dezvoltatori de agenți, trebuie să construim sisteme și procese pentru a gestiona adăugarea, eliminarea și condensarea informațiilor în fereastra de context.
Ingineria Promptului vs Ingineria Contextului
Ingineria promptului se concentrează pe un set singular de instrucțiuni statice pentru a ghida eficient agenții AI cu un set de reguli. Ingineria contextului gestionează un set dinamic de informații, inclusiv promptul inițial, pentru a asigura că agentul AI are ce îi trebuie în timp. Ideea principală a ingineriei contextului este de a face acest proces repetabil și fiabil.
Tipuri de Context
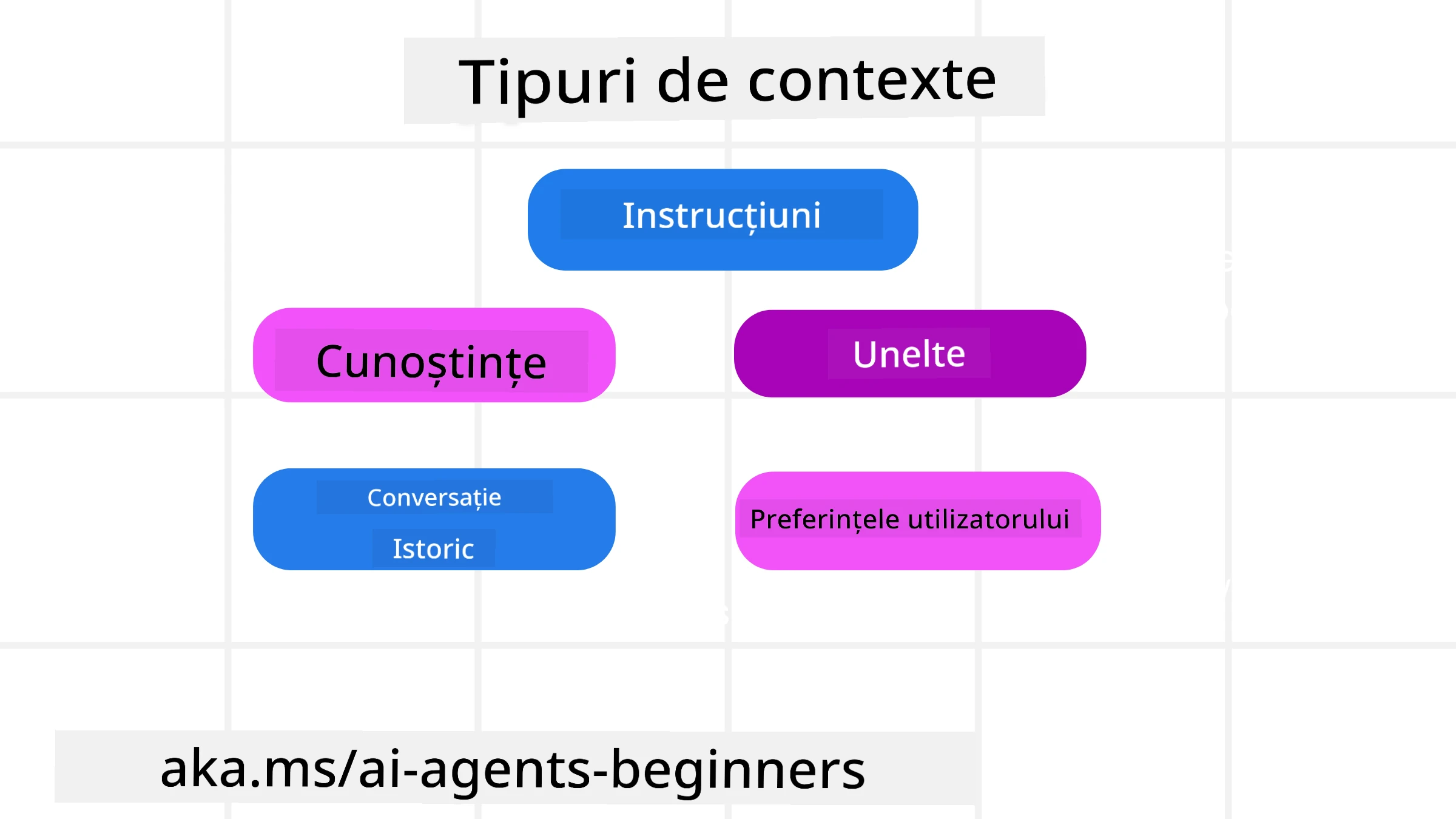
Este important să ne amintim că contextul nu este doar un singur lucru. Informațiile de care agentul AI are nevoie pot proveni din diferite surse și este responsabilitatea noastră să ne asigurăm că agentul are acces la aceste surse:
Tipurile de context pe care un agent AI trebuie să le gestioneze includ:
• Instrucțiuni: Acestea sunt ca „regulile” agentului – prompturi, mesaje de sistem, exemple few-shot (arată AI cum să facă ceva) și descrieri ale instrumentelor pe care le poate folosi. Aici se combină focalizarea ingineriei promptului cu ingineria contextului.
• Cunoștințe: Acoperă fapte, informații preluate din baze de date sau amintiri pe termen lung pe care agentul le-a acumulat. Acesta include integrarea unui sistem Retrieval Augmented Generation (RAG) dacă agentul are nevoie să acceseze diferite depozite de cunoștințe și baze de date.
• Instrumente: Acestea sunt definițiile funcțiilor externe, API-urilor și serverelor MCP pe care agentul le poate apela, împreună cu feedback-ul (rezultatele) obținut din utilizarea lor.
• Istoricul Conversațiilor: Dialogul continuu cu un utilizator. Pe măsură ce timpul trece, aceste conversații devin mai lungi și mai complexe, ocupând spațiu în fereastra de context.
• Preferințele Utilizatorului: Informații învățate despre gusturile sau antipatiile unui utilizator de-a lungul timpului. Acestea pot fi stocate și apelate când se iau decizii cheie pentru a ajuta utilizatorul.
Strategii pentru Ingineria Contextului eficientă
Strategii de Planificare
O inginerie bună a contextului începe cu o planificare bună. Iată o abordare care vă va ajuta să începeți să gândiți cum să aplicați conceptul de inginerie a contextului:
- Definește Rezultate Clare - Rezultatele sarcinilor atribuite agenților AI ar trebui să fie definite clar. Răspundeți la întrebarea: „Cum va arăta lumea când agentul AI își va termina sarcina?” Cu alte cuvinte, ce schimbare, informație sau răspuns ar trebui să primească utilizatorul după interacțiunea cu agentul AI.
- Cartografiază Contextul - Odată ce ați definit rezultatele agentului AI, trebuie să răspundeți la întrebarea „Ce informație are nevoie agentul AI pentru a finaliza această sarcină?”. Astfel începeți să conturați contextul și unde pot fi găsite acele informații.
- Creează Fluxuri de Context - Acum că știți unde se află informația, trebuie să răspundeți la întrebarea „Cum va obține agentul această informație?”. Acest lucru poate fi realizat în diverse moduri, inclusiv cu RAG, utilizarea serverelor MCP și alte instrumente.
Strategii Practice
Planificarea este importantă, dar odată ce informația începe să intre în fereastra de context a agentului nostru, avem nevoie de strategii practice pentru a o gestiona:
Gestionarea Contextului
În timp ce unele informații vor fi adăugate automat în fereastra de context, ingineria contextului presupune a avea un rol mai activ asupra acestei informații, ceea ce poate fi realizat prin câteva strategii:
-
Blocnotesul Agentului
Acesta permite agentului AI să ia notițe despre informații relevante legate de sarcinile curente și interacțiunile cu utilizatorul în timpul unei singure sesiuni. Acesta ar trebui să existe în afara ferestrei de context, într-un fișier sau obiect în runtime pe care agentul îl poate recupera ulterior în această sesiune, dacă e nevoie. -
Amintiri
Blocnotele sunt bune pentru gestionarea informațiilor în afara ferestrei de context a unei singure sesiuni. Amintirile permit agenților să stocheze și să recupereze informații relevante pe parcursul mai multor sesiuni. Acestea pot include rezumate, preferințe ale utilizatorilor și feedback pentru îmbunătățiri ulterioare. -
Compresia Contextului
Când fereastra de context crește și se apropie de limită, pot fi folosite tehnici precum rezumarea și tăierea. Aceasta înseamnă fie păstrarea doar a celor mai relevante informații, fie eliminarea mesajelor mai vechi. -
Sisteme Multi-Agent
Dezvoltarea unui sistem multi-agent este o formă de inginerie a contextului, deoarece fiecare agent are propria fereastră de context. Cum este partajat și transferat acest context către diferiți agenți este altceva ce trebuie planificat în construirea acestor sisteme. -
Mediile Sandbox
Dacă un agent trebuie să ruleze cod sau să proceseze cantități mari de informații într-un document, acest lucru poate consuma un număr mare de tokeni pentru a procesa rezultatele. În loc să stocheze toate acestea în fereastra de context, agentul poate folosi un mediu sandbox care poate rula codul și doar să citească rezultatele și alte informații relevante. -
Obiecte de Stare Runtime
Acest lucru se face prin crearea de containere de informații pentru a gestiona situații când agentul trebuie să aibă acces la anumite informații. Pentru o sarcină complexă, acest lucru ar permite agentului să stocheze rezultatele fiecărui subtask pas cu pas, permițând contextului să rămână conectat doar la subtask-ul specific.
Exemplu de Inginerie a Contextului
Să spunem că vrem ca un agent AI să „Să-mi rezerve o călătorie la Paris.”
• Un agent simplu care folosește doar ingineria promptului ar putea răspunde doar: „Bine, când doriți să mergeți la Paris?”. Acesta a procesat doar întrebarea directă în momentul în care utilizatorul a pus-o.
• Un agent care folosește strategiile de inginerie a contextului descrise va face mult mai mult. Înainte de a răspunde, sistemul său ar putea:
◦ Verifica calendarul tău pentru date disponibile (preluând date în timp real).
◦ Recupera preferințele tale de călătorie anterioare (din memoria pe termen lung) precum compania aeriană preferată, bugetul sau dacă preferi zboruri directe.
◦ Identifica instrumentele disponibile pentru rezervări de zbor și hotel.
- Apoi, un răspuns de exemplu ar putea fi: „Salut [Numele Tău]! Văd că ești liber în prima săptămână din octombrie. Să caut zboruri directe către Paris cu [Compania Aeriană Preferată] în cadrul bugetului tău obișnuit de [Buget]?” Acest răspuns mai bogat, conștient de context, demonstrează puterea ingineriei contextului.
Eșecuri Comune ale Contextului
Otrăvirea Contextului
Ce este: Când o halucinație (informație falsă generată de LLM) sau o eroare intră în context și este referențiată repetat, determinând agentul să urmărească obiective imposibile sau să dezvolte strategii lipsite de sens.
Ce trebuie făcut: Implementați validarea contextului și izolarea. Validați informațiile înainte să fie adăugate în memoria pe termen lung. Dacă se detectează potențială otrăvire, începeți fire noi de context pentru a preveni răspândirea informațiilor greșite.
Exemplu de rezervare călătorie: Agentul tău halucinează un zbor direct de la un aeroport local mic la un oraș internațional îndepărtat care nu oferă de fapt zboruri internaționale. Această detaliu de zbor inexistent este salvat în context. Ulterior, când ceri agentului să facă o rezervare, acesta continuă să încerce să găsească bilete pentru această rută imposibilă, ducând la erori repetate.
Soluție: Implementați un pas care validează existența și rutele zborurilor cu un API în timp real înainte de a adăuga detaliul zborului în contextul de lucru al agentului. Dacă validarea eșuează, informația eronată este “izolată” și nu este folosită în continuare.
Distragerea Contextului
Ce este: Când contextul devine atât de mare încât modelul se concentrează prea mult pe istoricul acumulat în loc să folosească ceea ce a învățat în timpul antrenamentului, ducând la acțiuni repetitive sau nefolositoare. Modelele pot începe să facă greșeli chiar și înainte ca fereastra de context să fie plină.
Ce trebuie făcut: Folosiți rezumarea contextului. Periodic comprimați informațiile acumulate în rezumate mai scurte, păstrând detaliile importante și eliminând istoricul redundant. Acest lucru ajută la “resetarea” concentrării.
Exemplu de rezervare călătorie: Ai discutat mult timp despre diverse destinații de vis pentru călătorii, inclusiv o relatare detaliată despre excursia cu rucsacul acum doi ani. Când în cele din urmă ceri să „găsești un zbor ieftin pentru luna viitoare”, agentul rămâne blocat în detaliile vechi, irelevante, și continuă să întrebe despre echipamentul de drumeție sau itinerariile anterioare, neglijând cererea ta curentă.
Soluție: După un anumit număr de interacțiuni sau când contextul devine prea mare, agentul ar trebui să rezume cele mai recente și relevante părți ale conversației — concentrându-se pe datele și destinația ta de călătorie actuală — și să utilizeze acel rezumat condensat pentru următoarea apelare a LLM, eliminând conversația istorică mai puțin relevantă.
Confuzia Contextului
Ce este: Când contextul inutil, adesea sub forma unui număr prea mare de instrumente disponibile, determină modelul să genereze răspunsuri proaste sau să apeleze instrumente irelevante. Modelele mai mici sunt în special predispuse la acest fenomen.
Ce trebuie făcut: Implementați gestionarea încărcăturii instrumentelor folosind tehnici RAG. Stocați descrierile instrumentelor într-o bază de date vectorială și selectați doar cele mai relevante instrumente pentru fiecare sarcină specifică. Cercetările arată că limitarea selecției la mai puțin de 30 este optimă.
Exemplu de rezervare călătorie: Agentul tău are acces la zeci de instrumente: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations etc. Întrebi: „Care este cea mai bună modalitate de a mă deplasa prin Paris?” Datorită numărului mare de instrumente, agentul se confuzează și încearcă să apeleze book_flight în interiorul Parisului sau rent_car chiar dacă preferi transportul public, deoarece descrierile instrumentelor pot suprapune sau pentru că nu poate distinge cel mai potrivit.
Soluție: Folosiți RAG peste descrierile instrumentelor. Când întrebi cum să te deplasezi prin Paris, sistemul extrage dinamic doar cele mai relevante instrumente precum rent_car sau public_transport_info pe baza întrebării tale, prezentând un „set de instrumente” concentrat pentru LLM.
Conflictul Contextului
Ce este: Când există informații contradictorii în context, ducând la raționamente inconsistente sau răspunsuri finale proaste. Acest lucru se întâmplă adesea când informația sosește în etape, iar presupunerile greșite inițiale rămân în context.
Ce trebuie făcut: Folosiți tăierea contextului și descărcarea. Tăierea înseamnă eliminarea informațiilor învechite sau conflictuale pe măsură ce apar noi detalii. Descărcarea oferă modelului un spațiu separat de tip „blocnotes” pentru procesarea informațiilor fără a aglomera contextul principal.
Exemplu de rezervare călătorie: Inițial îi spui agentului, „Vreau clasa economică.” Mai târziu în conversație, te răzgândești și spui, „De fapt, pentru această călătorie, să fie clasa business.” Dacă ambele instrucțiuni rămân în context, agentul ar putea primi rezultate de căutare contradictorii sau se poate confunda în privința preferinței prioritare.
Soluție: Implementați tăierea contextului. Când o nouă instrucțiune contrazice pe cea veche, instrucțiunea mai veche este eliminată sau explicit înlocuită în context. Alternativ, agentul poate folosi un blocnotes pentru a concilia preferințele contradictorii înainte de decizie, asigurându-se că doar instrucțiunea finală, consecventă, îi ghidează acțiunile.
Aveți Mai Multe Întrebări Despre Ingineria Contextului?
Alăturați-vă Microsoft Foundry Discord pentru a întâlni alți cursanți, a participa la ore de consiliere și a primi răspunsuri la întrebările despre Agenții AI.
Declinare a responsabilității:
Acest document a fost tradus folosind serviciul de traducere automată AI Co-op Translator. Deși ne străduim pentru acuratețe, vă rugăm să rețineți că traducerile automate pot conține erori sau inexactități. Documentul original în limba sa nativă trebuie considerat sursa autoritară. Pentru informații critice, se recomandă traducerea profesională realizată de un specialist uman. Nu suntem responsabili pentru eventualele neînțelegeri sau interpretări greșite care pot rezulta din utilizarea acestei traduceri.