ai-agents-for-beginners
Контекстное проектирование для AI-Агентов

(Нажмите на изображение выше, чтобы посмотреть видео этого урока)
Понимание сложности приложения, для которого вы создаёте AI-агента, важно для создания надёжного агента. Нам нужно создавать AI-агентов, которые эффективно управляют информацией для решения сложных задач, выходящих за рамки простого проектирования подсказок.
В этом уроке мы рассмотрим, что такое контекстное проектирование и какую роль оно играет при создании AI-агентов.
Введение
В этом уроке мы рассмотрим:
• Что такое контекстное проектирование и почему оно отличается от проектирования подсказок.
• Стратегии эффективного контекстного проектирования, включая написание, выбор, сжатие и изоляцию информации.
• Распространённые ошибки с контекстом, которые могут сорвать работу вашего AI-агента, и способы их исправления.
Учебные цели
После изучения этого урока вы будете уметь:
• Определять контекстное проектирование и отличать его от проектирования подсказок.
• Опознавать ключевые компоненты контекста в приложениях с большими языковыми моделями (LLM).
• Применять стратегии написания, выбора, сжатия и изоляции контекста для улучшения работы агента.
• Распознавать распространённые ошибки с контекстом, такие как отравление, отвлечение, путаница и конфликт, и внедрять методы их устранения.
Что такое контекстное проектирование?
Для AI-агентов контекст — это то, что управляет планированием действий агента. Контекстное проектирование — это практика обеспечения AI-агента нужной информацией для выполнения следующего шага задачи. Окно контекста ограничено по размеру, поэтому создателям агентов нужно создавать системы и процессы для управляемого добавления, удаления и сжатия информации в окне контекста.
Проектирование подсказок против контекстного проектирования
Проектирование подсказок сосредоточено на одном наборе статичных инструкций для эффективного управления AI-агентами с помощью набора правил. Контекстное проектирование — это управление динамическим набором информации, включая начальную подсказку, чтобы гарантировать, что AI-агент имеет всё необходимое со временем. Основная идея контекстного проектирования — сделать этот процесс повторяемым и надёжным.
Виды контекста
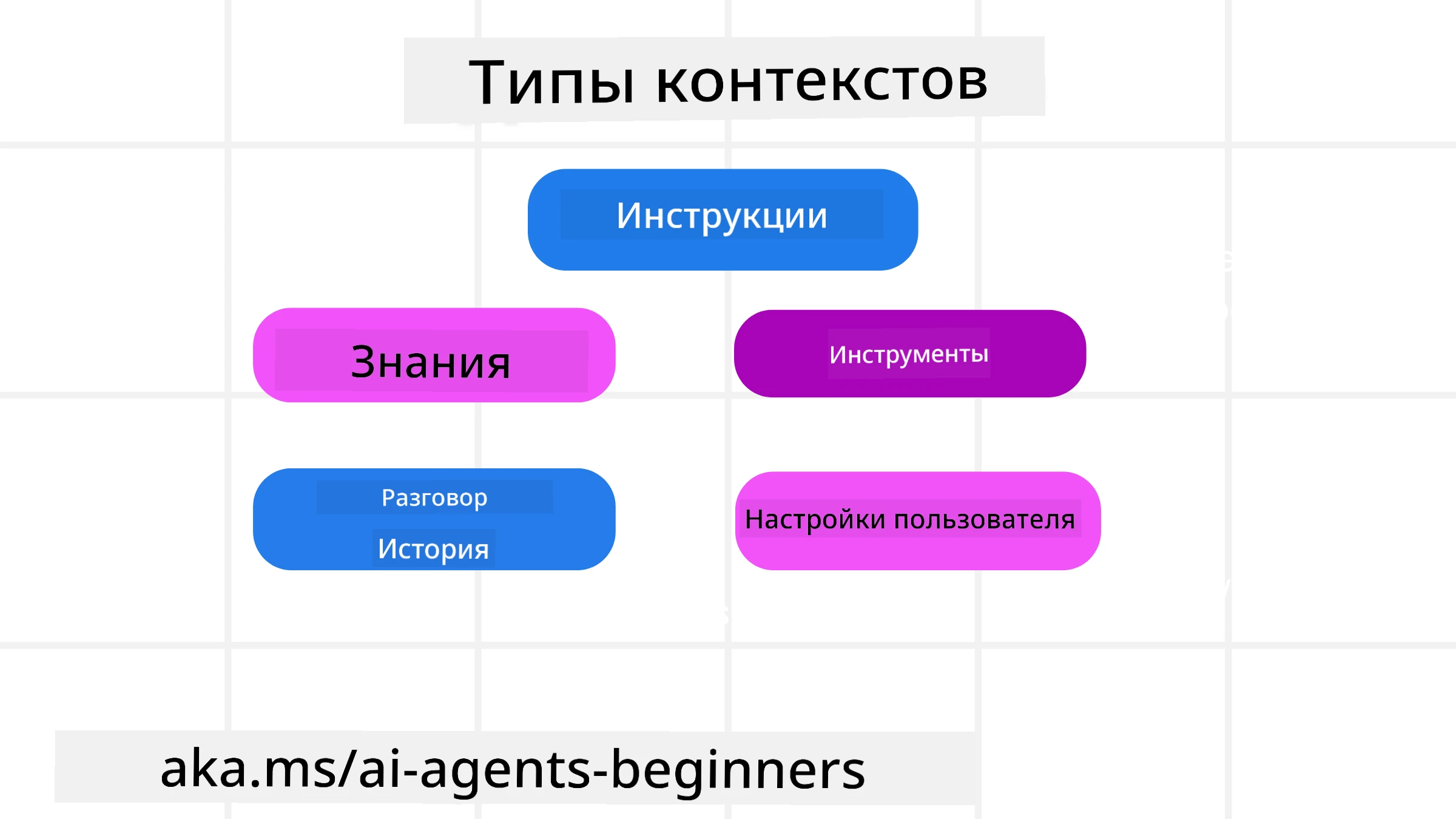
Важно помнить, что контекст — это не что-то одно. Информация, которая нужна AI-агенту, может поступать из разных источников, и наша задача — обеспечить агенту доступ к этим источникам:
Типы контекста, которыми может управлять AI-агент, включают:
• Инструкции: Это как “правила” агента – подсказки, системные сообщения, несколько примеров (демонстрирующих, как выполнять задачи), и описания инструментов, которые он может использовать. Здесь сосредоточено пересечение проектирования подсказок и контекстного проектирования.
• Знания: Включают факты, информацию, полученную из баз данных, или накопленную долгосрочную память агента. Сюда включена интеграция системы Retrieval Augmented Generation (RAG), если агенту нужен доступ к разным хранилищам знаний и базам данных.
• Инструменты: Определения внешних функций, API и MCP серверов, которые агент может вызвать, а также обратная связь (результаты), получаемая при их использовании.
• История разговора: Текущий диалог с пользователем. Со временем эти разговоры становятся длиннее и сложнее, занимая больше места в окне контекста.
• Предпочтения пользователя: Информация о вкусах и антипатиях пользователя, накопленная со временем. Эти данные можно хранить и использовать при принятии ключевых решений, чтобы помочь пользователю.
Стратегии эффективного контекстного проектирования
Стратегии планирования
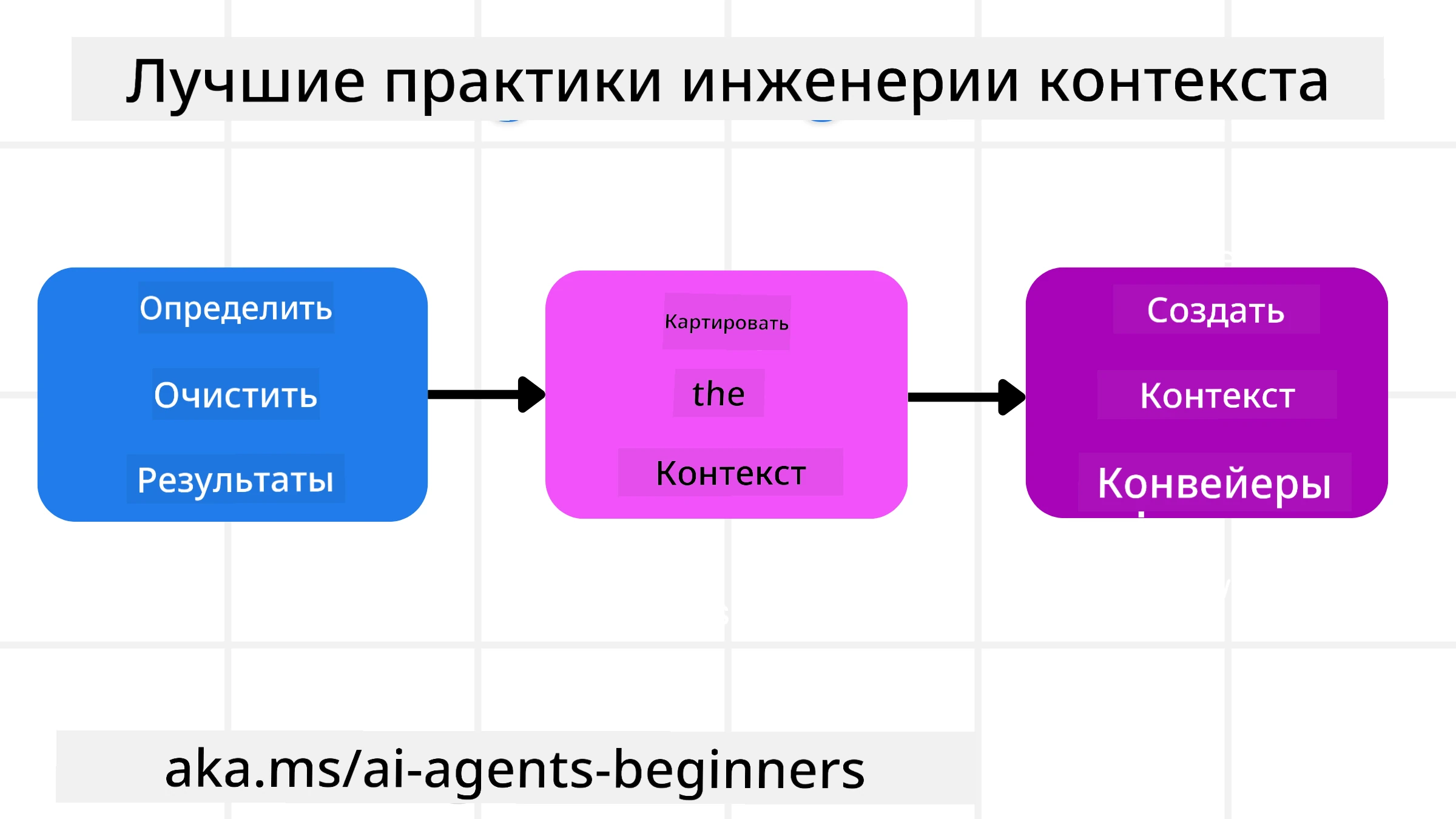
Хорошее контекстное проектирование начинается с хорошего планирования. Вот подход, который поможет начать думать, как применять концепцию контекстного проектирования:
-
Чётко определите результаты — результаты задач, которые будут назначены AI-агентам, должны быть чётко описаны. Ответьте на вопрос — «Как будет выглядеть мир, когда AI-агент завершит свою задачу?» Другими словами, какое изменение, информация или ответ должны быть у пользователя после взаимодействия с AI-агентом.
-
Составьте карту контекста — после определения результатов AI-агента нужно ответить на вопрос «Какая информация нужна AI-агенту для выполнения этой задачи?». Так вы сможете определить, где именно эту информацию можно найти.
-
Создайте контекстные конвейеры — теперь, когда вы знаете, где находится информация, нужно ответить на вопрос «Как агент получит эту информацию?». Это можно реализовать разными способами, включая RAG, использование MCP серверов и других инструментов.
Практические стратегии
Планирование важно, но когда информация начинает поступать в окно контекста нашего агента, нам нужны практические стратегии для её управления:
Управление контекстом
Хотя некоторая информация автоматически добавляется в окно контекста, контекстное проектирование подразумевает более активное управление этой информацией, для чего подходят несколько стратегий:
-
Блокнот агента
Позволяет AI-агенту делать заметки о релевантной информации о текущих задачах и взаимодействиях с пользователем в рамках одной сессии. Он должен существовать вне окна контекста в файле или объекте во время выполнения, чтобы агент мог позже получить к нему доступ при необходимости. -
Память
Блокноты хороши для управления информацией вне окна контекста одной сессии. Память позволяет агентам хранить и извлекать релевантную информацию между сессиями. Это могут быть резюме, предпочтения пользователя и отзывы для улучшений в будущем. -
Сжатие контекста
Когда окно контекста растёт и приближается к лимиту, можно использовать техники суммирования и обрезки. Это включает сохранение только самой важной информации или удаление устаревших сообщений. -
Мультиагентные системы
Разработка мультиагентных систем — это форма контекстного проектирования, поскольку у каждого агента своё окно контекста. Как именно этот контекст передаётся и разделяется между агентами — ещё один аспект планирования при создании таких систем. -
Песочницы
Если агенту нужно выполнить код или обработать большой объём данных из документа, это может занять много токенов для обработки результатов. Вместо того, чтобы хранить всё это в окне контекста, агент может использовать окружение песочницы, где запускается код и далее читаются только результаты и другая релевантная информация. -
Объекты состояния выполнения
Создаются контейнеры информации для управления ситуациями, когда агенту нужен доступ к определённой информации. Для сложной задачи это позволит агенту поэтапно хранить результаты каждого подшага, сохраняя контекст только для конкретной подзадачи.
Пример контекстного проектирования
Предположим, мы хотим, чтобы AI-агент «Забронировал мне поездку в Париж.»
• Простой агент, использующий только проектирование подсказок, может просто ответить: «Хорошо, когда вы хотите поехать в Париж?». Он обработал только ваш прямой вопрос в момент запроса.
• Агент, применяющий стратегии контекстного проектирования, сделает гораздо больше. Прежде чем ответить, система может:
◦ Проверить ваш календарь на доступные даты (получая актуальные данные).
◦ Вспомнить прошлые предпочтения путешествий (из долгосрочной памяти), такие как любимая авиакомпания, бюджет или предпочтение прямых рейсов.
◦ Определить доступные инструменты для бронирования авиабилетов и отелей.
- Тогда пример ответа мог бы быть таким: «Привет, [Ваше имя]! Я вижу, что вы свободны в первую неделю октября. Искать прямые рейсы в Париж на [любимая авиакомпания] в пределах вашего обычного бюджета [бюджет]?». Такой более насыщенный и учитывающий контекст ответ демонстрирует силу контекстного проектирования.
Распространённые ошибки с контекстом
Отравление контекста
Что это: Когда галлюцинация (ложная информация, созданная LLM) или ошибка попадает в контекст и неоднократно используется, из-за чего агент преследует невозможные цели или разрабатывает бессмысленные стратегии.
Что делать: Внедрять проверку контекста и карантин. Проверять информацию перед добавлением в долгосрочную память. Если обнаружено возможное отравление, запускать новую цепочку контекста, чтобы предотвратить распространение плохой информации.
Пример с бронированием путешествия: Ваш агент “галлюцинирует” существование прямого рейса из маленького местного аэропорта в далёкий международный город, хотя такой рейс не существует. Эти неверные данные сохраняются в контексте. Позже, когда вы просите забронировать билет, агент продолжает искать билеты по этому невозможному маршруту, вызывая повторяющиеся ошибки.
Решение: Реализовать этап, который проверяет существование рейсов и маршрутов через API в реальном времени до добавления детали рейса в рабочий контекст агента. Если проверка не проходит, ошибочная информация помещается в “карантин” и не используется дальше.
Отвлечение контекста
Что это: Когда контекст становится настолько большим, что модель слишком сосредотачивается на накопленной истории вместо того, чтобы использовать то, чему научилась при обучении, вызывая повторяющиеся или непродуктивные действия. Модели могут начинать ошибаться ещё до того, как окно контекста заполнено полностью.
Что делать: Использовать суммирование контекста. Периодически сжимать накопленную информацию в короткие резюме, сохраняя важные детали и удаляя избыточную историю. Это помогает “сбросить” внимание.
Пример с бронированием путешествия: Вы долго обсуждали разные мечтательные места для путешествий, включая подробный рассказ о походе с рюкзаком два года назад. Когда вы наконец просите «Найди мне дешёвый билет на следующий месяц», агент застревает на старых, нерелевантных деталях и продолжает спрашивать о вашей туристической экипировке или прошлых маршрутах, игнорируя текущий запрос.
Решение: После определённого количества обменов или при слишком большом размере контекста агент должен суммировать наиболее свежие и релевантные части разговора — сосредоточившись на текущих датах и месте поездки — и использовать это сжатое резюме для следующего вызова LLM, отбрасывая менее важную историческую беседу.
Путаница контекста
Что это: Когда слишком много инструментов или ненужный контекст вызывает генерацию модели плохих ответов или вызов нерелевантных инструментов. Особенно подвержены этому небольшие модели.
Что делать: Внедрять управление набором инструментов с помощью техник RAG. Хранить описания инструментов в векторной базе данных и выбирать только наиболее релевантные инструменты для каждой конкретной задачи. Исследования показывают, что нужно ограничивать количество выбранных инструментов менее чем 30.
Пример с бронированием путешествия: Ваш агент имеет доступ к десяткам инструментов: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations и др. Вы спрашиваете: «Как лучше передвигаться по Парижу?» Из-за большого количества инструментов агент путается и пытается вызвать book_flight внутри Парижа или rent_car, хотя вы предпочитаете общественный транспорт, так как описания инструментов могут пересекаться или агент не может определить лучший.
Решение: Использовать RAG по описаниям инструментов. Когда вы спрашиваете о передвижении по Парижу, система динамически извлекает только самые релевантные инструменты, такие как rent_car или public_transport_info, представляя модели сфокусированный “набор” инструментов.
Конфликт контекста
Что это: Когда в контексте есть противоречивая информация, приводящая к неконсистентному рассуждению или плохим итоговым ответам. Обычно происходит, когда информация поступает постепенно, и ранние неправильные предположения остаются в контексте.
Что делать: Применять обрезку контекста и выгрузку. Обрезка — это удаление устаревшей или конфликтующей информации по мере поступления новых данных. Выгрузка даёт модели отдельное “рабочее пространство” (блокнот) для обработки информации без засорения основного контекста.
Пример с бронированием путешествия: Сначала вы говорите агенту: «Я хочу лететь эконом-классом.» Позже в разговоре меняете решение: «На самом деле для этой поездки давай бизнес-класс.» Если обе инструкции остаются в контексте, агент получает конфликтующие результаты поиска или путается, какую предпочтение учитывать.
Решение: Внедрить обрезку контекста. Когда новая инструкция противоречит старой, последняя удаляется или явно переопределяется в контексте. Либо агент может использовать блокнот, чтобы согласовать конфликтующие предпочтения, прежде чем принять решение, гарантируя, что только итоговая и согласованная инструкция будет направлять его действия.
Есть вопросы по контекстному проектированию?
Присоединяйтесь к Microsoft Foundry Discord, чтобы встретиться с другими учащимися, посетить открытые часы и получить ответы на вопросы о AI-агентах.
Отказ от ответственности:
Этот документ был переведен с помощью сервиса автоматического перевода Co-op Translator. Несмотря на наши усилия обеспечить точность, просим учитывать, что автоматический перевод может содержать ошибки или неточности. Оригинальный документ на исходном языке следует считать официальным и авторитетным источником. Для получения критически важной информации рекомендуется обращаться к профессиональному человеческому переводу. Мы не несем ответственности за любые недоразумения или неправильные толкования, возникшие в результате использования данного перевода.