ai-agents-for-beginners
Kontextové inžinierstvo pre AI agentov

(Kliknite na obrázok vyššie pre zobrazenie videa tejto lekcie)
Pochopenie zložitosti aplikácie, pre ktorú budujete AI agenta, je dôležité na vytvorenie spoľahlivého agenta. Potrebujeme vytvárať AI agentov, ktorí efektívne spravujú informácie na riešenie komplexných potrieb nad rámec prompt engineeringu.
V tejto lekcii sa pozrieme na to, čo je kontextové inžinierstvo a akú úlohu hrá pri budovaní AI agentov.
Úvod
Táto lekcia pokryje:
• Čo je kontextové inžinierstvo a prečo sa líši od prompt engineeringu.
• Stratégie pre efektívne kontextové inžinierstvo, vrátane toho, ako písať, vyberať, komprimovať a izolovať informácie.
• Bežné zlyhania kontextu, ktoré môžu dostať vášho AI agenta z cesty a ako ich opraviť.
Ciele učenia
Po dokončení tejto lekcie budete vedieť, ako:
• Definovať kontextové inžinierstvo a odlíšiť ho od prompt engineeringu.
• Identifikovať kľúčové komponenty kontextu v aplikáciách s veľkými jazykovými modelmi (LLM).
• Použiť stratégie písania, výberu, komprimovania a izolovania kontextu na zlepšenie výkonu agenta.
• Rozpoznať bežné zlyhania kontextu, ako sú znečistenie (poisoning), rozptýlenie, zmätok a konflikt, a implementovať techniky na ich zmiernenie.
Čo je kontextové inžinierstvo?
Pre AI agentov je kontext to, čo riadi plánovanie AI agenta pri vykonávaní určitých akcií. Kontextové inžinierstvo je prax zabezpečenia, aby mal AI agent správne informácie na dokončenie nasledujúceho kroku úlohy. Kontextové okno má obmedzenú veľkosť, takže ako tvorcovia agentov musíme vybudovať systémy a procesy na spravovanie pridávania, odstraňovania a zhušťovania informácií v kontextovom okne.
Prompt Engineering vs Kontextové inžinierstvo
Prompt engineering sa sústreďuje na jeden súbor statických inštrukcií na efektívne riadenie AI agentov pomocou súboru pravidiel. Kontextové inžinierstvo je spôsob, ako spravovať dynamický súbor informácií, vrátane počiatočného promptu, aby mal AI agent to, čo potrebuje v priebehu času. Hlavná myšlienka kontextového inžinierstva je urobiť tento proces opakovateľným a spoľahlivým.
Typy kontextu
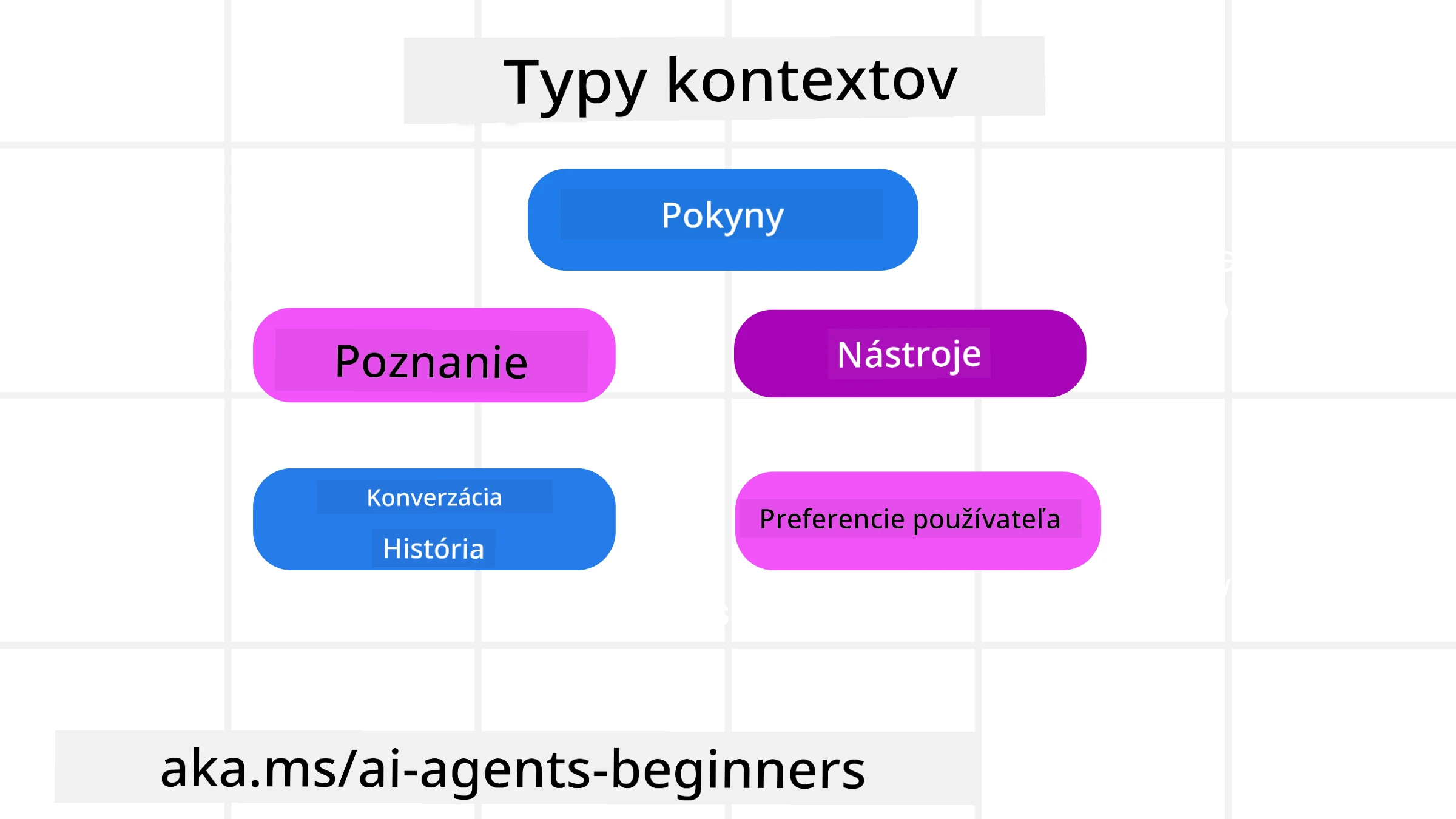
Je dôležité pamätať, že kontext nie je len jedna vec. Informácie, ktoré AI agent potrebuje, môžu prichádzať z rôznych zdrojov a je na nás, aby sme zabezpečili, že agent má prístup k týmto zdrojom:
Typy kontextu, ktoré môže AI agent potrebovať spravovať, zahŕňajú:
• Inštrukcie: Sú ako “pravidlá” agenta – prompty, systémové správy, few-shot príklady (ukazujúce AI, ako niečo robiť) a popisy nástrojov, ktoré môže použiť. Tu sa zameranie prompt engineeringu kombinuje s kontextovým inžinierstvom.
• Vedomosť: Zahŕňa fakty, informácie získané z databáz alebo dlhodobé spomienky, ktoré si agent uložil. To zahŕňa integráciu systému Retrieval Augmented Generation (RAG), ak agent potrebuje prístup k rôznym úložiskám znalostí a databázam.
• Nástroje: Sú to definície externých funkcií, API a MCP Servers, ktoré môže agent volať, spolu s odozvou (výsledkami), ktorú získa ich použitím.
• História konverzácie: Prebiehajúci dialóg s používateľom. Ako čas plynie, tieto konverzácie sú dlhšie a zložitejšie, čo znamená, že zaberajú miesto v kontextovom okne.
• Preferencie používateľa: Informácie naučené o tom, čo používateľ má rád alebo nemá rád v priebehu času. Tieto môžu byť uložené a vyvolané pri rozhodovaní, aby pomohli používateľovi.
Stratégie pre efektívne kontextové inžinierstvo
Plánovacie stratégie
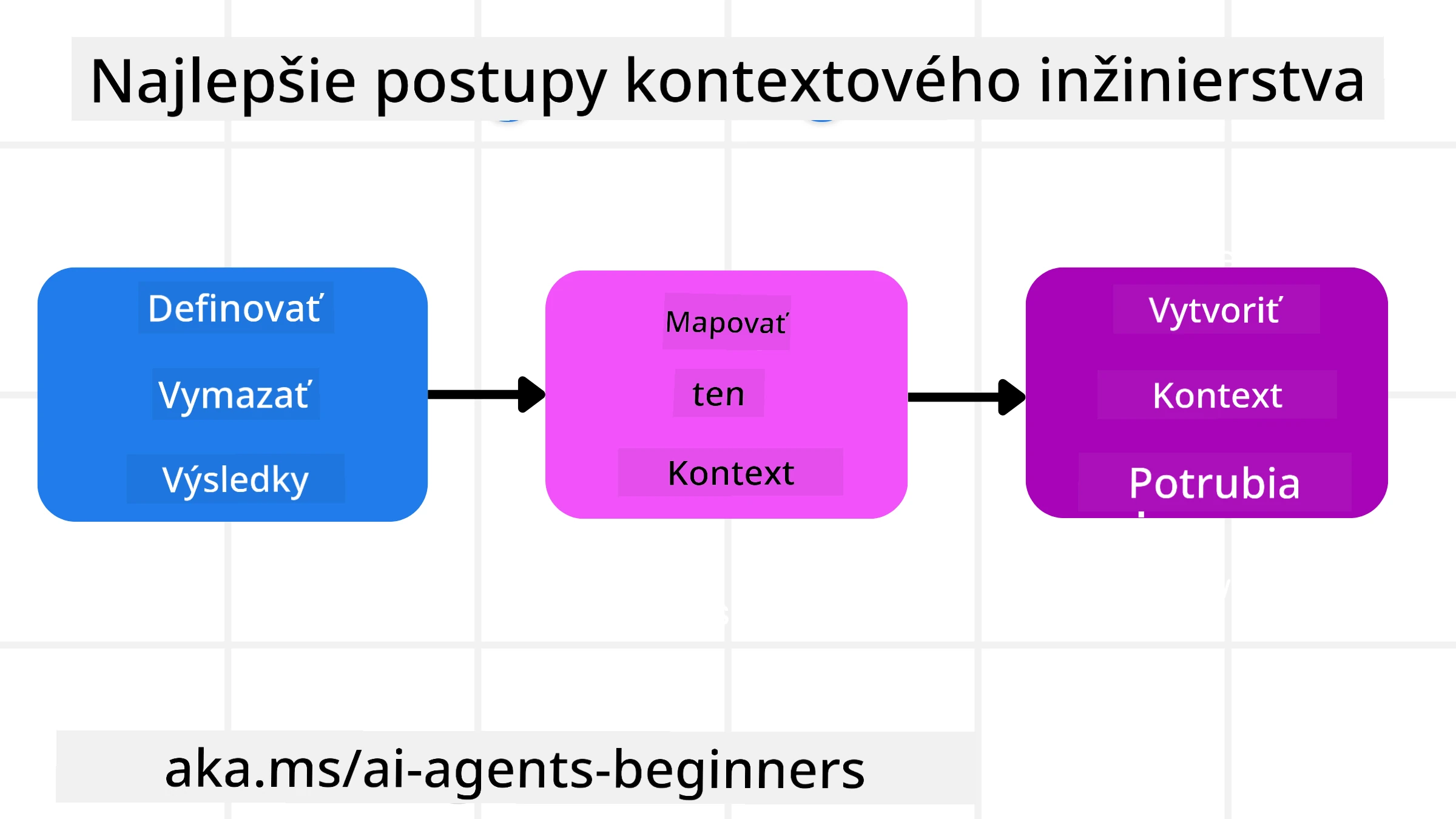
Dobrý prístup ku kontextovému inžinierstvu začína dobrým plánovaním. Tu je prístup, ktorý vám pomôže začať premýšľať o tom, ako aplikovať koncept kontextového inžinierstva:
-
Definujte jasné výsledky - Výsledky úloh, ktoré budú AI agenti vykonávať, by mali byť jasne definované. Odpovedzte na otázku - “Ako bude vyzerať svet, keď AI agent dokončí svoju úlohu?” Inými slovami, aká zmena, informácia alebo odpoveď by mal používateľ mať po interakcii s AI agentom.
-
Zmapujte kontext - Keď ste definovali výsledky AI agenta, musíte odpovedať na otázku “Aké informácie potrebuje AI agent na dokončenie tejto úlohy?”. Týmto spôsobom môžete začať mapovať kontext toho, kde sa tieto informácie nachádzajú.
-
Vytvorte kontextové pipeline - Keď už viete, kde sú informácie, musíte odpovedať na otázku “Ako agent získa tieto informácie?”. To je možné urobiť rôznymi spôsobmi, vrátane RAG, použitia MCP serverov a ďalších nástrojov.
Praktické stratégie
Plánovanie je dôležité, ale keď sa informácie začnú dostávať do kontextového okna nášho agenta, potrebujeme mať praktické stratégie na ich riadenie:
Správa kontextu
Zatiaľ čo niektoré informácie budú automaticky pridávané do kontextového okna, kontextové inžinierstvo znamená zaujatie aktívnejšej úlohy pri správe týchto informácií, čo sa dá robiť niekoľkými stratégiami:
-
Scratchpad agenta Tento umožňuje AI agentovi zapisovať si poznámky o relevantných informáciách týkajúcich sa aktuálnych úloh a interakcií používateľa počas jednej relácie. Toto by malo existovať mimo kontextového okna v súbore alebo runtime objekte, ktoré môže agent neskôr počas tejto relácie vyvolať v prípade potreby.
-
Pamäte Scratchpady sú dobré na správu informácií mimo kontextového okna jednej relácie. Pamäte umožňujú agentom ukladať a vyvolávať relevantné informácie naprieč viacerými reláciami. To môže zahŕňať zhrnutia, preferencie používateľov a spätnú väzbu pre zlepšenia v budúcnosti.
-
Kompresia kontextu Keď kontextové okno rastie a blíži sa k svojmu limitu, je možné použiť techniky ako sumarizácia a zaškrtávanie. To zahŕňa buď ponechanie iba najrelevantnejších informácií alebo odstránenie starších správ.
-
Systémy viacerých agentov Vývoj systémov s viacerými agentmi je formou kontextového inžinierstva, pretože každý agent má svoje vlastné kontextové okno. Ako sa tento kontext zdieľa a odovzdáva medzi rôznymi agentmi je ďalšia vec, ktorú treba naplánovať pri budovaní týchto systémov.
-
Sandbox prostredia Ak agent potrebuje spustiť nejaký kód alebo spracovať veľké množstvo informácií v dokumente, môže to vyžadovať veľké množstvo tokenov na spracovanie výsledkov. Namiesto uloženia všetkého v kontextovom okne môže agent použiť sandbox prostredie, ktoré dokáže spustiť tento kód a prečítať si iba výsledky a ďalšie relevantné informácie.
-
Objekty runtime stavu Toto sa robí vytváraním kontajnerov informácií na riadenie situácií, keď agent potrebuje mať prístup k určitým informáciám. Pre komplexnú úlohu by to umožnilo agentovi ukladať výsledky každej podúlohy krok za krokom, čím by kontext zostal prepojený len s tou konkrétnou podúlohou.
Príklad kontextového inžinierstva
Povedzme, že chceme, aby AI agent “Zarezervoval mi výlet do Paríža.”
• Jednoduchý agent používajúci iba prompt engineering by mohol jednoducho odpovedať: “Dobre, kedy by ste chceli ísť do Paríža?”. Spracoval len vašu priamu otázku v čase, keď ju používateľ položil.
• Agent používajúci stratégie kontextového inžinierstva by urobil omnoho viac. Ešte pred odpoveďou môže jeho systém:
◦ Skontrolovať váš kalendár pre dostupné dátumy (získavanie údajov v reálnom čase).
◦ Pripomenúť si minulé cestovné preferencie (z dlhodobej pamäte), ako napríklad preferovanú leteckú spoločnosť, rozpočet alebo či uprednostňujete priame lety.
◦ Identifikovať dostupné nástroje na rezerváciu letov a hotelov.
- Potom by odpoveď mohla vyzerať napríklad takto: “Ahoj [Vaše meno]! Vidím, že máte voľno v prvom týždni októbra. Mám hľadať priame lety do Paríža s [Preferovaná letecká spoločnosť] v rámci vášho bežného rozpočtu [Rozpočet]?”. Táto bohatšia, kontextovo uvedomelá odpoveď ilustruje silu kontextového inžinierstva.
Bežné zlyhania kontextu
Otrava kontextu
Čo to je: Keď sa do kontextu dostane halucinácia (nepravdivá informácia generovaná LLM) alebo chyba a je opakovane odkazovaná, čo spôsobí, že agent sleduje nemožné ciele alebo vyvíja nezmyselné stratégie.
Čo robiť: Implementujte validáciu kontextu a karanténu. Overte informácie predtým, než sa pridajú do dlhodobej pamäte. Ak sa zistí potenciálna otrava, začnite nové kontextové vlákna, aby sa zabránilo šíreniu zlých informácií.
Príklad rezervácie cesty: Váš agent si vymyslí priamy let z malého miestneho letiska do vzdialeného medzinárodného mesta, ktoré v skutočnosti medzinárodné lety neponúka. Tento neexistujúci detail o lete sa uloží do kontextu. Neskôr, keď požiadate agenta o rezerváciu, stále sa snaží nájsť lístky pre túto nemožnú trasu, čo vedie k opakovaným chybám.
Riešenie: Zaveďte krok, ktorý overí existenciu letu a trasy pomocou API v reálnom čase pred pridaním detailu letu do pracovného kontextu agenta. Ak validácia zlyhá, chybná informácia je “izolovaná v karanténe” a ďalej sa nepoužíva.
Rozptýlenie kontextu
Čo to je: Keď kontext rastie natoľko, že model sa príliš sústreďuje na nahromadenú históriu namiesto toho, aby využíval to, čo sa naučil počas tréningu, čo vedie k opakovaniu alebo nepomocným akciám. Modely môžu začať robiť chyby ešte predtým, než je kontextové okno plné.
Čo robiť: Použite sumarizáciu kontextu. Periodicky komprimujte nahromadené informácie do kratších súhrnov, ktoré uchovajú dôležité detaily a odstránia redundantnú históriu. To pomáha “resetovať” fokus.
Príklad rezervácie cesty: Dlhodobo ste diskutovali o rôznych vysnívaných destináciách, vrátane podrobného rozprávania o vašom backpacking výlete spred dvoch rokov. Keď nakoniec požiadate “nájdi mi lacný let na** budúci mesiac,” agent sa zasekne v starých, irelevantných detailoch a stále sa pýta na vašu výbavu na backpacking alebo minulé itineráre, zanedbávajúc vašu aktuálnu požiadavku.
Riešenie: Po určitom počte kolies alebo keď kontext príliš narastie, by mal agent zhrnúť najnovšie a najrelevantnejšie časti konverzácie – zamerať sa na vaše aktuálne dátumy a destináciu – a použiť tento skondenzovaný súhrn pre ďalší LLM volanie, zatiaľ čo menej relevantný historický chat sa zahodí.
Zmätok kontextu
Čo to je: Keď zbytočný kontext, často vo forme príliš veľa dostupných nástrojov, spôsobuje, že model generuje zlé odpovede alebo volá irelevantné nástroje. Menšie modely sú na to obzvlášť náchylné.
Čo robiť: Implementujte správu výbavy nástrojov pomocou techník RAG. Ukladajte popisy nástrojov do vektorovej databázy a vyberajte len tie najrelevantnejšie nástroje pre konkrétnu úlohu. Výskum ukazuje obmedziť výber nástrojov na menej ako 30.
Príklad rezervácie cesty: Váš agent má prístup k desiatkam nástrojov: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, atď. Pýtate sa: “What’s the best way to get around Paris?” V dôsledku množstva nástrojov sa agent zmätený pokúsi zavolať book_flight v rámci Paríža, alebo rent_car, aj keď uprednostňujete verejnú dopravu, pretože popisy nástrojov sa môžu prekrývať alebo jednoducho nedokáže rozlíšiť ten najlepší.
Riešenie: Použite RAG nad popismi nástrojov. Keď sa pýtate na spôsoby presunu po Paríži, systém dynamicky vyhľadá len najrelevantnejšie nástroje ako rent_car alebo public_transport_info na základe vašej otázky a predstaví zameranú “výbavu” nástrojov pre LLM.
Konflikt kontextu
Čo to je: Keď v kontexte existujú protichodné informácie, čo vedie k nekonzistentnému uvažovaniu alebo zlým konečným odpovediam. Často sa to stane, keď informácie prichádzajú postupne a skoré, nesprávne predpoklady zostanú v kontexte.
Čo robiť: Použite prerezávanie kontextu a odkladanie. Prerezávanie znamená odstraňovanie zastaralých alebo protichodných informácií, keď prídu nové detaily. Odkladanie dáva modelu samostatné pracovné miesto “scratchpad” na spracovanie informácií bez znečisťovania hlavného kontextu.
Príklad rezervácie cesty: Najskôr poviete agentovi, “Chcem letieť v ekonomickej triede.” Neskôr v konverzácii zmeníte názor a poviete, “Vlastne, na tento výlet poďme business triedu.” Ak obe inštrukcie zostanú v kontexte, agent môže dostať protichodné výsledky vyhľadávania alebo sa zmiasť, ktorú preferenciu uprednostniť.
Riešenie: Implementujte prerezávanie kontextu. Keď nová inštrukcia protirečí starej, staršia inštrukcia sa odstráni alebo explicitne predefinuje v kontexte. Alternatívne môže agent použiť scratchpad na zosúladenie protichodných preferencií pred rozhodnutím, čím sa zabezpečí, že iba finálna, konzistentná inštrukcia riadi jeho akcie.
Máte ďalšie otázky o kontextovom inžinierstve?
Pripojte sa k Microsoft Foundry Discord stretnúť sa s ostatnými študentmi, zúčastniť sa konzultačných hodín a získať odpovede na svoje otázky o AI agentech.
Upozornenie: Tento dokument bol preložený pomocou služby strojového prekladu AI Co-op Translator. Aj keď sa snažíme o presnosť, berte, prosím, na vedomie, že automatické preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho pôvodnom jazyku by sa mal považovať za rozhodujúci zdroj. Pre dôležité informácie odporúčame profesionálny ľudský preklad. Nie sme zodpovední za žiadne nedorozumenia alebo nesprávne výklady vzniknuté použitím tohto prekladu.