ai-agents-for-beginners

(Klicka på bilden ovan för att se videon från denna lektion)
Designmönster för användning av verktyg
Verktyg är intressanta eftersom de möjliggör för AI-agenter att ha ett bredare utbud av kapaciteter. Istället för att agenten har en begränsad uppsättning åtgärder den kan utföra, kan agenten nu utföra ett brett spektrum av åtgärder genom att lägga till ett verktyg. I detta kapitel ska vi titta på designmönstret för användning av verktyg, som beskriver hur AI-agenter kan använda specifika verktyg för att uppnå sina mål.
Introduktion
I denna lektion ska vi försöka besvara följande frågor:
- Vad är designmönstret för användning av verktyg?
- Vilka användningsfall kan det tillämpas på?
- Vilka element/byggstenar behövs för att implementera designmönstret?
- Vilka särskilda överväganden finns för att använda designmönstret för användning av verktyg för att bygga pålitliga AI-agenter?
Lerningsmål
Efter att ha slutfört denna lektion kommer du att kunna:
- Definiera designmönstret för användning av verktyg och dess syfte.
- Identifiera användningsfall där designmönstret för användning av verktyg är tillämpligt.
- Förstå de centrala elementen som behövs för att implementera designmönstret.
- Känna igen överväganden för att säkerställa pålitlighet hos AI-agenter som använder detta designmönster.
Vad är designmönstret för användning av verktyg?
Designmönstret för användning av verktyg fokuserar på att ge LLM:er (Large Language Models) möjligheten att interagera med externa verktyg för att uppnå specifika mål. Verktyg är kod som kan exekveras av en agent för att utföra åtgärder. Ett verktyg kan vara en enkel funktion såsom en kalkylator eller ett API-anrop till en tredjepartstjänst som aktiekursuppslagning eller väderprognos. Inom ramen för AI-agenter är verktyg utformade för att exekveras av agenter som svar på modellgenererade funktionsanrop.
Vilka användningsfall kan det tillämpas på?
AI-agenter kan utnyttja verktyg för att slutföra komplexa uppgifter, hämta information eller fatta beslut. Designmönstret för användning av verktyg används ofta i scenarier som kräver dynamisk interaktion med externa system, såsom databaser, webbtjänster eller kodtolkare. Denna förmåga är användbar för ett antal olika användningsfall, inklusive:
- Dynamisk informationsinhämtning: Agenter kan fråga externa API:er eller databaser för att hämta aktuell data (t.ex. en SQLite-databas för dataanalys, hämta aktiekurser eller väderinformation).
- Kodexekvering och tolkning: Agenter kan exekvera kod eller skript för att lösa matematiska problem, generera rapporter eller utföra simuleringar.
- Automatisering av arbetsflöden: Automatisering av repetitiva eller flerstegsarbetsflöden genom att integrera verktyg som schemaläggare, e-posttjänster eller datapipelines.
- Kundsupport: Agenter kan interagera med CRM-system, ärendehanteringsplattformar eller kunskapsdatabaser för att lösa användarfrågor.
- Innehållsgenerering och redigering: Agenter kan använda verktyg såsom grammatikkontroller, textsammanfattare eller innehållssäkerhetsutvärderare för att assistera vid innehållsskapande.
Vilka element/byggstenar behövs för att implementera designmönstret för användning av verktyg?
Dessa byggstenar gör det möjligt för AI-agenten att utföra ett brett spektrum av uppgifter. Låt oss titta på de viktigaste elementen som behövs för att implementera designmönstret för användning av verktyg:
-
Funktion/verktygsscheman: Detaljerade definitioner av tillgängliga verktyg, inklusive funktionsnamn, syfte, nödvändiga parametrar och förväntade utdata. Dessa scheman möjliggör för LLM att förstå vilka verktyg som är tillgängliga och hur man konstruerar giltiga förfrågningar.
-
Logik för funktionskörning: Styr hur och när verktyg anropas baserat på användarens avsikt och samtalskontext. Detta kan inkludera planeringsmoduler, routningsmekanismer eller villkorliga flöden som avgör verktygsanvändning dynamiskt.
-
Meddelandeshanteringssystem: Komponenter som hanterar konversationsflödet mellan användarinmatningar, LLM-svar, verktygsanrop och verktygsutdata.
-
Verktygsintegrationsramverk: Infrastruktur som kopplar agenten till olika verktyg, vare sig de är enkla funktioner eller komplexa externa tjänster.
-
Felhantering och validering: Mekanismer för att hantera fel vid verktygsexekvering, validera parametrar och hantera oväntade svar.
-
Tillståndshantering: Spårar samtalskontext, tidigare verktyginteraktioner och persistenta data för att säkerställa konsekvens över flera turer.
Nästa ska vi titta närmare på funktions-/verktygsanrop.
Funktions-/verktygsanrop
Funktionsanrop är det primära sättet vi möjliggör för Large Language Models (LLM) att interagera med verktyg. Du kommer ofta att se ‘Funktion’ och ‘Verktyg’ användas omväxlande eftersom ‘funktioner’ (block av återanvändbar kod) är de ‘verktyg’ som agenter använder för att utföra uppgifter. För att en funktions kod ska anropas måste en LLM jämföra användarens förfrågan med funktionens beskrivning. För detta skickas ett schema som innehåller beskrivningar av alla tillgängliga funktioner till LLM. LLM väljer sedan den mest lämpliga funktionen för uppgiften och returnerar dess namn och argument. Den valda funktionen anropas, dess svar skickas tillbaka till LLM, som använder informationen för att svara på användarens förfrågan.
För att utvecklare ska kunna implementera funktionsanrop för agenter behöver man:
- En LLM-modell som stödjer funktionsanrop
- Ett schema som innehåller funktionsbeskrivningar
- Koden för varje beskriven funktion
Låt oss använda exemplet att ta reda på aktuell tid i en stad för att illustrera:
-
Initiera en LLM som stödjer funktionsanrop:
Inte alla modeller stöder funktionsanrop, så det är viktigt att kontrollera att LLM du använder gör det. Azure OpenAI stödjer funktionsanrop. Vi kan börja med att initiera Azure OpenAI-klienten.
# Initiera Azure OpenAI-klienten client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_AI_PROJECT_ENDPOINT"), api_key=os.getenv("AZURE_OPENAI_API_KEY"), api_version="2024-05-01-preview" ) -
Skapa ett funktionsschema:
Nästa steg är att definiera ett JSON-schema som innehåller funktionsnamn, beskrivning av vad funktionen gör samt namn och beskrivningar av funktionsparametrarna.
Vi skickar sedan detta schema till klienten som skapades tidigare, tillsammans med användarens förfrågan att hitta tiden i San Francisco. Det viktiga att notera är att ett verktygsanrop är vad som returneras, inte det slutgiltiga svaret på frågan. Som nämnts tidigare returnerar LLM namnet på funktionen den valde för uppgiften och argumenten som ska skickas till den.# Funktionsbeskrivning för modellen att läsa tools = [ { "type": "function", "function": { "name": "get_current_time", "description": "Get the current time in a given location", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } } ]# Initialt användarmeddelande messages = [{"role": "user", "content": "What's the current time in San Francisco"}] # Första API-anropet: Be modellen använda funktionen response = client.chat.completions.create( model=deployment_name, messages=messages, tools=tools, tool_choice="auto", ) # Bearbeta modellens svar response_message = response.choices[0].message messages.append(response_message) print("Model's response:") print(response_message)Model's response: ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_pOsKdUlqvdyttYB67MOj434b', function=Function(arguments='{"location":"San Francisco"}', name='get_current_time'), type='function')]) -
Funktionskoden som krävs för att utföra uppgiften:
Nu när LLM har valt vilken funktion som behöver köras måste koden som utför uppgiften implementeras och exekveras.
Vi kan implementera koden för att hämta aktuell tid i Python. Vi behöver även skriva kod för att extrahera namn och argument från response_message för att få slutresultatet.def get_current_time(location): """Get the current time for a given location""" print(f"get_current_time called with location: {location}") location_lower = location.lower() for key, timezone in TIMEZONE_DATA.items(): if key in location_lower: print(f"Timezone found for {key}") current_time = datetime.now(ZoneInfo(timezone)).strftime("%I:%M %p") return json.dumps({ "location": location, "current_time": current_time }) print(f"No timezone data found for {location_lower}") return json.dumps({"location": location, "current_time": "unknown"})# Hantera funktionsanrop if response_message.tool_calls: for tool_call in response_message.tool_calls: if tool_call.function.name == "get_current_time": function_args = json.loads(tool_call.function.arguments) time_response = get_current_time( location=function_args.get("location") ) messages.append({ "tool_call_id": tool_call.id, "role": "tool", "name": "get_current_time", "content": time_response, }) else: print("No tool calls were made by the model.") # Andra API-anropet: Hämta det slutgiltiga svaret från modellen final_response = client.chat.completions.create( model=deployment_name, messages=messages, ) return final_response.choices[0].message.contentget_current_time called with location: San Francisco Timezone found for san francisco The current time in San Francisco is 09:24 AM.
Funktionsanrop är kärnan i de flesta, om inte alla, design för användning av verktyg i agenter, men att implementera det från grunden kan ibland vara utmanande.
Som vi lärde oss i Lektion 2 ger agentiska ramverk oss förbyggda byggstenar för att implementera verktygsanvändning.
Exempel på verktygsanvändning med agentiska ramverk
Här är några exempel på hur du kan implementera designmönstret för användning av verktyg med olika agentiska ramverk:
Microsoft Agent Framework
Microsoft Agent Framework är ett open-source AI-ramverk för att bygga AI-agenter. Det förenklar processen att använda funktionsanrop genom att låta dig definiera verktyg som Python-funktioner med @tool-dekorationen. Ramverket hanterar fram-och-tillbaka-kommunikationen mellan modellen och din kod. Det ger också tillgång till förbyggda verktyg som File Search och Code Interpreter via AzureAIProjectAgentProvider.
Följande diagram illustrerar processen för funktionsanrop med Microsoft Agent Framework:
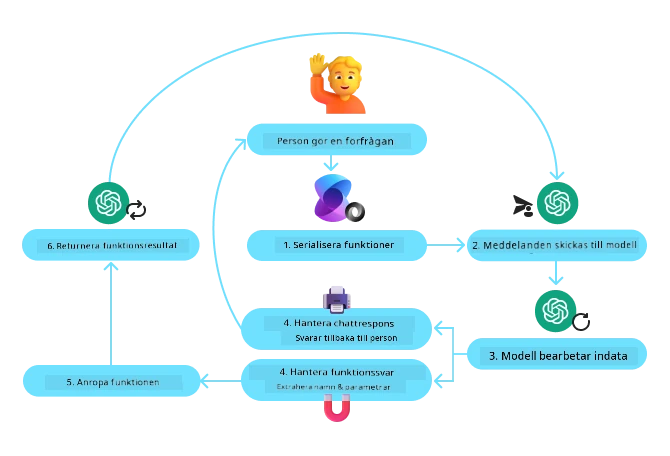
I Microsoft Agent Framework definieras verktygen som dekorerade funktioner. Vi kan konvertera funktionen get_current_time som vi såg tidigare till ett verktyg genom att använda @tool-dekorationen. Ramverket serialiserar automatiskt funktionen och dess parametrar, och skapar schemat som skickas till LLM.
from agent_framework import tool
from agent_framework.azure import AzureAIProjectAgentProvider
from azure.identity import AzureCliCredential
@tool
def get_current_time(location: str) -> str:
"""Get the current time for a given location"""
...
# Skapa klienten
provider = AzureAIProjectAgentProvider(credential=AzureCliCredential())
# Skapa en agent och kör med verktyget
agent = await provider.create_agent(name="TimeAgent", instructions="Use available tools to answer questions.", tools=get_current_time)
response = await agent.run("What time is it?")
Azure AI Agent Service
Azure AI Agent Service är ett nyare agentiskt ramverk som är designat för att hjälpa utvecklare att säkert bygga, distribuera och skala högkvalitativa och utbyggbara AI-agenter utan att behöva hantera underliggande beräknings- och lagringsresurser. Det är särskilt användbart för företagsapplikationer eftersom det är en helt hanterad tjänst med företagsklassad säkerhet.
Jämfört med att utveckla direkt med LLM API ger Azure AI Agent Service några fördelar, inklusive:
- Automatisk verktygsanrop – inga behov av att tolka ett verktygsanrop, anropa verktyget och hantera svaret; allt detta sker nu serverside
- Säker hantering av data – istället för att hantera eget samtalstillstånd kan du förlita dig på trådar för att lagra all information som behövs
- Färdiga verktyg – Verktyg som kan användas för att interagera med dina datakällor, såsom Bing, Azure AI Search och Azure Functions.
De verktyg som finns tillgängliga i Azure AI Agent Service kan delas in i två kategorier:
- Kunskapsverktyg:
- Åtgärdsverktyg:
Agenttjänsten gör det möjligt för oss att använda dessa verktyg tillsammans som en toolset. Den använder även threads som håller reda på historiken av meddelanden från en särskild konversation.
Föreställ dig att du är en försäljningsagent på ett företag som heter Contoso. Du vill utveckla en samtalsagent som kan svara på frågor om din försäljningsdata.
Följande bild illustrerar hur du kan använda Azure AI Agent Service för att analysera din försäljningsdata:
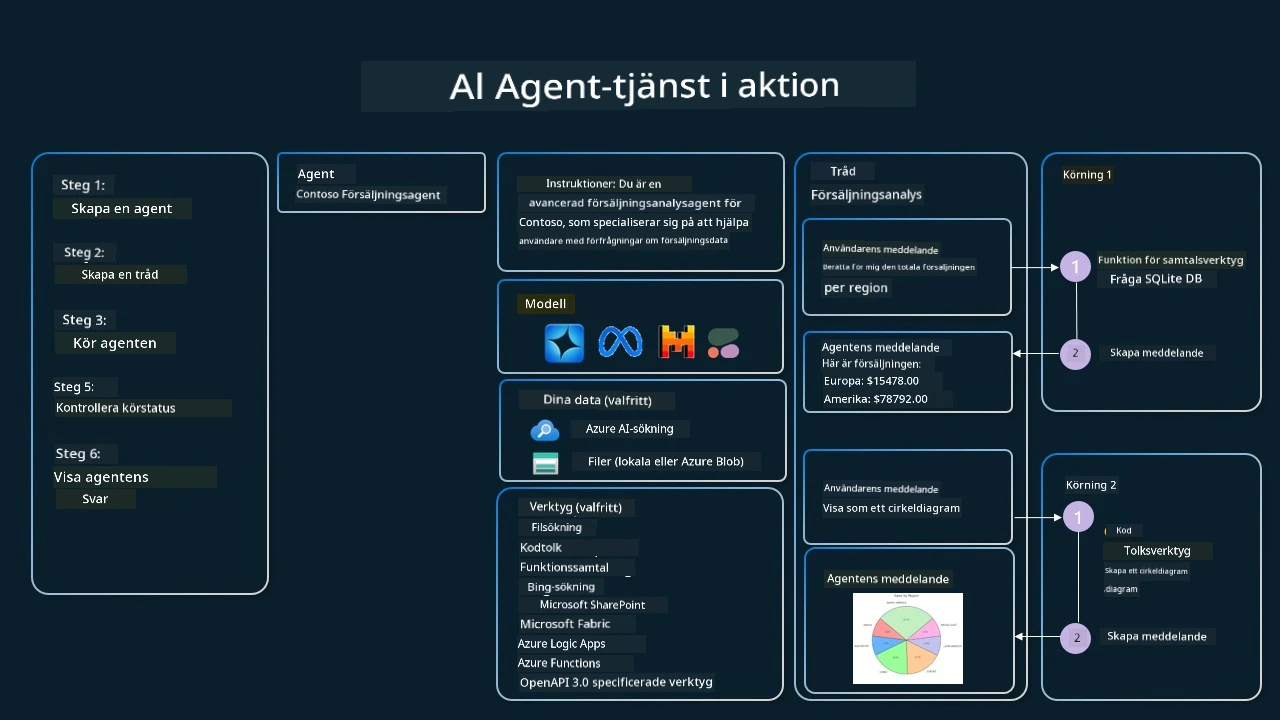
För att använda något av dessa verktyg med tjänsten kan vi skapa en klient och definiera ett verktyg eller en verktygssamling. För att implementera detta praktiskt kan vi använda följande Python-kod. LLM kommer att kunna titta på verktygssamlingen och avgöra om den ska använda den användarskapade funktionen fetch_sales_data_using_sqlite_query eller den förbyggda Kodtolkaren beroende på användarens förfrågan.
import os
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
from fetch_sales_data_functions import fetch_sales_data_using_sqlite_query # fetch_sales_data_using_sqlite_query-funktion som finns i en fil som heter fetch_sales_data_functions.py.
from azure.ai.projects.models import ToolSet, FunctionTool, CodeInterpreterTool
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initiera verktygssats
toolset = ToolSet()
# Initiera funktionella anropsagenten med fetch_sales_data_using_sqlite_query-funktionen och lägg till den i verktygssatsen
fetch_data_function = FunctionTool(fetch_sales_data_using_sqlite_query)
toolset.add(fetch_data_function)
# Initiera Code Interpreter-verktyget och lägg till det i verktygssatsen.
code_interpreter = code_interpreter = CodeInterpreterTool()
toolset.add(code_interpreter)
agent = project_client.agents.create_agent(
model="gpt-4o-mini", name="my-agent", instructions="You are helpful agent",
toolset=toolset
)
Vilka särskilda överväganden finns för att använda designmönstret för användning av verktyg för att bygga pålitliga AI-agenter?
En vanlig oro med SQL som genereras dynamiskt av LLM:er är säkerheten, särskilt risken för SQL-injektion eller illvilliga handlingar, såsom att ta bort eller manipulera databasen. Även om dessa farhågor är giltiga kan de effektivt mildras genom att korrekt konfigurera databasåtkomstbehörigheter. För de flesta databaser innebär detta att konfigurera databasen som skrivskyddad. För databastjänster som PostgreSQL eller Azure SQL ska appen tilldelas en skrivskyddad (SELECT) roll.
Att köra appen i en säker miljö förbättrar skyddet ytterligare. I företagsmiljöer extraheras och transformeras vanligtvis data från operativa system till en skrivskyddad databas eller datalager med ett användarvänligt schema. Detta tillvägagångssätt säkerställer att data är säkert, optimerat för prestanda och tillgänglighet, samt att appen har begränsad, skrivskyddad åtkomst.
Exempelkoder
- Python: Agent Framework
- .NET: Agent Framework
Fler frågor om designmönstret för användning av verktyg?
Gå med i Microsoft Foundry Discord för att möta andra lärande, delta i kontorstid och få svar på dina frågor om AI-agenter.
Ytterligare resurser
- Azure AI Agents Service Workshop
- Contoso Creative Writer Multi-Agent Workshop
- Översikt över Microsoft Agent Framework
Föregående lektion
Förstå agentiska designmönster
Nästa lektion
Ansvarsfriskrivning: Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet, vänligen notera att automatiska översättningar kan innehålla fel eller brister. Det ursprungliga dokumentet på dess modersmål bör betraktas som den auktoritativa källan. För kritisk information rekommenderas professionell mänsklig översättning. Vi ansvarar inte för eventuella missförstånd eller feltolkningar som uppstår från användningen av denna översättning.