ai-agents-for-beginners
Kontextteknik för AI-agenter

(Klicka på bilden ovan för att se lektionens video)
Att förstå komplexiteten i den applikation du bygger en AI-agent för är viktigt för att skapa en pålitlig sådan. Vi behöver bygga AI-agenter som effektivt hanterar information för att ta itu med komplexa behov bortom promptutformning.
I den här lektionen kommer vi att titta på vad kontextteknik är och dess roll i att bygga AI-agenter.
Introduktion
Den här lektionen kommer att täcka:
• Vad kontextteknik är och varför det skiljer sig från promptutformning.
• Strategier för effektiv kontextteknik, inklusive hur man skriver, väljer, komprimerar och isolerar information.
• Vanliga kontextfel som kan spåra ur din AI-agent och hur man åtgärdar dem.
Lärandemål
Efter att ha genomfört denna lektion kommer du att veta och förstå hur du:
• Definierar kontextteknik och skiljer det från promptutformning.
• Identifierar nyckelkomponenterna i kontext i applikationer som använder stora språkmodeller (LLM).
• Tillämpa strategier för att skriva, välja, komprimera och isolera kontext för att förbättra agentens prestanda.
• Känner igen vanliga kontextfel såsom förgiftning, distraktion, förvirring och krock, och implementerar åtgärder för att mildra dem.
Vad är kontextteknik?
För AI-agenter är kontext det som driver planeringen för att en AI-agent ska vidta vissa åtgärder. Kontextteknik är praxis för att säkerställa att AI-agenten har rätt information för att slutföra nästa steg i uppgiften. Kontextfönstret är begränsat i storlek, så som agentbyggare behöver vi bygga system och processer för att hantera tillägg, borttagning och kondensering av information i kontextfönstret.
Promptutformning vs Kontextteknik
Promptutformning fokuserar på en enda uppsättning statiska instruktioner för att effektivt styra AI-agenter med en uppsättning regler. Kontextteknik handlar om hur man hanterar en dynamisk uppsättning information, inklusive den initiala prompten, för att säkerställa att AI-agenten har vad den behöver över tid. Huvudidén med kontextteknik är att göra denna process upprepbar och pålitlig.
Typer av kontext
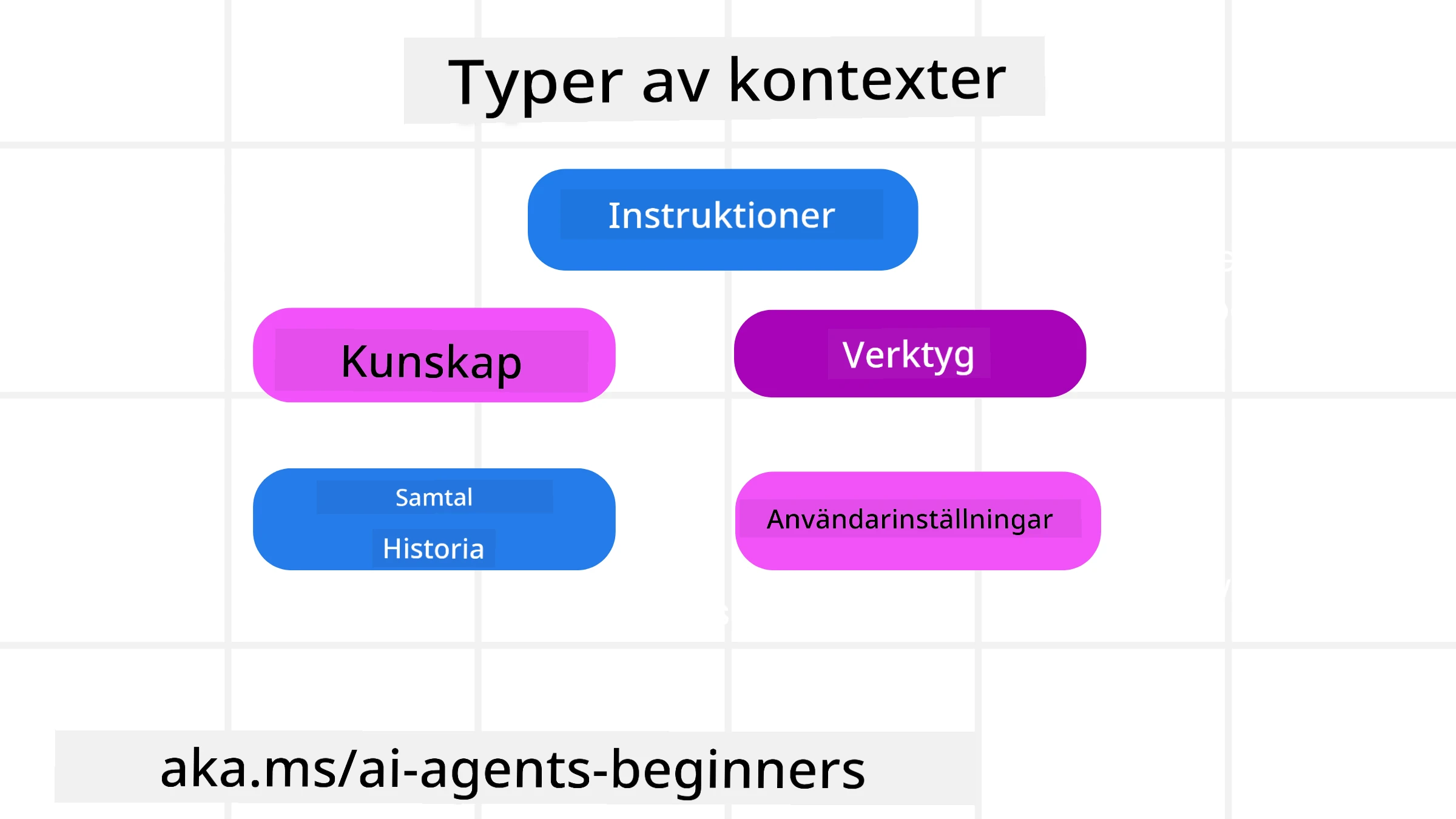
Det är viktigt att komma ihåg att kontext inte bara är en sak. Informationen som AI-agenten behöver kan komma från en mängd olika källor och det är upp till oss att säkerställa att agenten har tillgång till dessa källor:
De typer av kontext som en AI-agent kan behöva hantera inkluderar:
• Instruktioner: Dessa är som agentens “regler” – prompts, systemmeddelanden, few-shot-exempel (som visar hur AI:n ska göra något) och beskrivningar av verktyg den kan använda. Här kombineras fokus från promptutformning med kontextteknik.
• Kunskap: Detta täcker fakta, information hämtad från databaser eller långsiktiga minnen som agenten samlat på sig. Detta inkluderar att integrera ett Retrieval Augmented Generation (RAG)-system om en agent behöver åtkomst till olika kunskapslager och databaser.
• Verktyg: Detta är definitionerna av externa funktioner, API:er och MCP Servers som agenten kan anropa, tillsammans med den återkoppling (resultat) den får från att använda dem.
• Samtalshistorik: Den pågående dialogen med en användare. Med tiden blir dessa konversationer längre och mer komplexa vilket innebär att de tar upp utrymme i kontextfönstret.
• Användarpreferenser: Information som lärts om en användares tycken eller ogillar över tid. Dessa kan lagras och användas när viktiga beslut ska fattas för att hjälpa användaren.
Strategier för effektiv kontextteknik
Planeringsstrategier
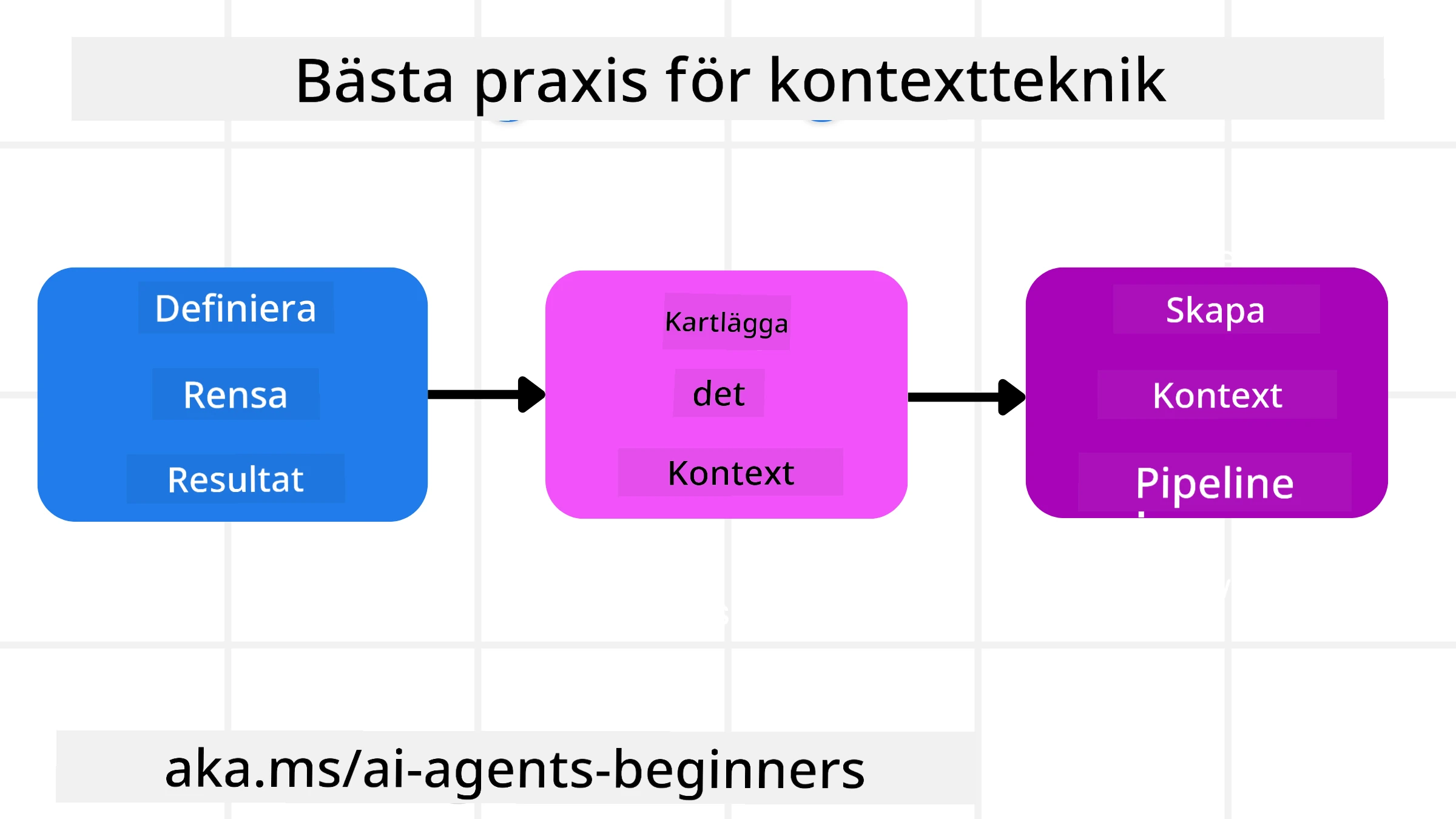
Bra kontextteknik börjar med god planering. Här är ett tillvägagångssätt som hjälper dig att börja tänka på hur du tillämpar begreppet kontextteknik:
- Definiera tydliga resultat - Resultaten av de uppgifter som AI-agenter kommer att tilldelas bör vara tydligt definierade. Svara på frågan - “Hur kommer världen att se ut när AI-agenten är klar med sin uppgift?” Med andra ord, vilken förändring, information eller respons ska användaren ha efter att ha interagerat med AI-agenten.
- Kartlägg kontexten - När du har definierat AI-agentens resultat behöver du svara på frågan “Vilken information behöver AI-agenten för att slutföra denna uppgift?”. På så sätt kan du börja kartlägga var den informationen kan finnas.
- Skapa kontextpipeliner - Nu när du vet var informationen finns måste du svara på frågan “Hur kommer agenten att få denna information?”. Detta kan göras på olika sätt inklusive RAG, användning av MCP-servrar och andra verktyg.
Praktiska strategier
Planering är viktigt men när informationen börjar flöda in i vår agents kontextfönster behöver vi ha praktiska strategier för att hantera den:
Hantera kontext
Medan viss information läggs till i kontextfönstret automatiskt handlar kontextteknik om att ta en mer aktiv roll i denna informationshantering vilket kan göras med några strategier:
-
Agentens anteckningsblock Detta möjliggör för en AI-agent att göra anteckningar om relevant information om de aktuella uppgifterna och användarinteraktionerna under en enda session. Detta bör finnas utanför kontextfönstret i en fil eller ett körobjekt som agenten senare kan hämta under denna session om det behövs.
-
Minnen Anteckningsblock är bra för att hantera information utanför kontextfönstret för en enda session. Minnen gör det möjligt för agenter att lagra och hämta relevant information över flera sessioner. Detta kan inkludera sammanfattningar, användarpreferenser och feedback för förbättringar i framtiden.
-
Komprimera kontext När kontextfönstret växer och närmar sig sin gräns kan tekniker såsom summering och trimning användas. Detta inkluderar antingen att bara behålla den mest relevanta informationen eller att ta bort äldre meddelanden.
-
System med flera agenter Att utveckla system med flera agenter är en form av kontextteknik eftersom varje agent har sitt eget kontextfönster. Hur den kontexten delas och skickas till olika agenter är något annat att planera när man bygger dessa system.
-
Sandlådemiljöer Om en agent behöver köra kod eller bearbeta stora mängder information i ett dokument kan detta kräva många tokens för att bearbeta resultaten. Istället för att ha allt lagrat i kontextfönstret kan agenten använda en sandlådemiljö som kan köra denna kod och endast läsa resultaten och annan relevant information.
-
Runtime state-objekt Detta görs genom att skapa behållare med information för att hantera situationer när agenten behöver ha åtkomst till viss information. För en komplex uppgift skulle detta göra det möjligt för en agent att lagra resultaten av varje deluppgiftssteg steg för steg, vilket gör att kontexten förblir kopplad endast till den specifika deluppgiften.
Exempel på kontextteknik
Låt oss säga att vi vill att en AI-agent ska “Boka en resa till Paris åt mig.”
• En enkel agent som bara använder promptutformning skulle kanske bara svara: “Okej, när vill du åka till Paris?”. Den bearbetade bara din direkta fråga vid den tidpunkt användaren ställde den.
• En agent som använder de kontextteknikstrategier som täckts skulle göra mycket mer. Innan den ens svarar kan dess system till exempel:
◦ Kolla din kalender för tillgängliga datum (hämtar realtidsdata).
◦ Återkalla tidigare resepreferenser (från långsiktigt minne) som ditt föredragna flygbolag, budget eller om du föredrar direktflyg.
◦ Identifiera tillgängliga verktyg för flyg- och hotellbokning.
- Sedan kan ett exempel på ett svar vara: “Hey [Your Name]! I see you’re free the first week of October. Shall I look for direct flights to Paris on [Preferred Airline] within your usual budget of [Budget]?”. Detta rikare, kontextmedvetna svar visar kraften i kontextteknik.
Vanliga kontextfel
Kontextförgiftning
Vad det är: När en hallucination (felaktig information som genereras av LLM) eller ett fel kommer in i kontexten och refereras upprepade gånger, vilket gör att agenten driver mot omöjliga mål eller utvecklar nonsensstrategier.
Vad man ska göra: Implementera kontextvalidering och karantän. Validera information innan den läggs till i långsiktigt minne. Om potentiell förgiftning upptäcks, starta nya kontexttrådar för att förhindra att den dåliga informationen sprids.
Exempel vid resebokning: Din agent hallucinera ett direktflyg från en liten lokal flygplats till en avlägsen internationell stad som faktiskt inte erbjuder internationella flyg. Denna icke-existerande flygdetalj sparas i kontexten. Senare, när du ber agenten boka, fortsätter den försöka hitta biljetter för denna omöjliga rutt, vilket leder till upprepade fel.
Lösning: Implementera ett steg som validerar flygexistens och rutter med ett realtids-API innan flygdetaljen läggs till i agentens arbetskontext. Om valideringen misslyckas blir den felaktiga informationen “karantäniserad” och används inte vidare.
Kontekstdistraktion
Vad det är: När kontexten blir så stor att modellen fokuserar för mycket på den ackumulerade historiken istället för att använda vad den lärt sig under träningen, vilket leder till repetitiva eller oanvändbara handlingar. Modeller kan börja göra misstag även innan kontextfönstret är fullt.
Vad man ska göra: Använd kontextsummarering. Komprimera periodiskt ackumulerad information till kortare sammanfattningar, behåll viktiga detaljer samtidigt som redundant historik tas bort. Detta hjälper till att “återställa” fokuset.
Exempel vid resebokning: Du har diskuterat olika drömresmål under lång tid, inklusive en detaljerad återberättelse av din ryggsäckningsresa för två år sedan. När du slutligen ber att “hitta mig ett billigt flyg för nästa månad”, blir agenten fast i gamla, irrelevanta detaljer och fortsätter att fråga om din ryggsäckningsutrustning eller tidigare resplaner, och försummar din aktuella förfrågan.
Lösning: Efter ett visst antal vändor eller när kontexten växer för mycket bör agenten sammanfatta de senaste och mest relevanta delarna av konversationen – med fokus på dina aktuella resdatum och destination – och använda den kondenserade sammanfattningen för nästa LLM-anrop, och kassera den mindre relevanta historiska chatten.
Konstextförvirring
Vad det är: När onödig kontext, ofta i form av för många tillgängliga verktyg, får modellen att generera dåliga svar eller anropa irrelevanta verktyg. Mindre modeller är särskilt benägna att detta.
Vad man ska göra: Implementera verktygslastningshantering med hjälp av RAG-tekniker. Lagra verktygsbeskrivningar i en vektordatabas och välj endast de mest relevanta verktygen för varje specifik uppgift. Forskning visar att begränsa verktygsval till färre än 30 är effektivt.
Exempel vid resebokning: Din agent har tillgång till dussintals verktyg: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, etc. Du frågar, “Vad är det bästa sättet att ta sig runt i Paris?” På grund av det stora antalet verktyg blir agenten förvirrad och försöker anropa book_flight inom Paris, eller rent_car trots att du föredrar kollektivtrafik, eftersom verktygsbeskrivningarna kanske överlappar eller den helt enkelt inte kan avgöra vilket som är bäst.
Lösning: Använd RAG över verktygsbeskrivningar. När du frågar om hur man tar sig runt i Paris hämtar systemet dynamiskt endast de mest relevanta verktygen som rent_car eller public_transport_info baserat på din förfrågan, och presenterar en fokuserad “loadout” av verktyg för LLM:en.
Konstkrock
Vad det är: När motsägelsefull information finns inom kontexten, vilket leder till inkonsekvent resonemang eller dåliga slutgiltiga svar. Detta händer ofta när information anländer i etapper och tidiga, felaktiga antaganden finns kvar i kontexten.
Vad man ska göra: Använd konstklippning och avlastning. Pruning innebär att ta bort föråldrad eller konfliktfylld information när nya detaljer anländer. Offloading ger modellen ett separat “scratchpad”-arbetsområde för att bearbeta information utan att störa huvudkontexten.
Exempel vid resebokning: Du säger initialt till din agent, “Jag vill flyga ekonomiklass.” Senare i konversationen ändrar du dig och säger, “Egentligen, för den här resan tar vi business class.” Om båda instruktionerna finns kvar i kontexten kan agenten få motstridiga sökresultat eller bli förvirrad om vilken preferens som ska prioriteras.
Lösning: Implementera konstklippning. När en ny instruktion motsäger en gammal tas den äldre instruktionen bort eller uttryckligen åsidosätts i kontexten. Alternativt kan agenten använda ett scratchpad för att förenliga motstridiga preferenser innan den bestämmer sig, och säkerställer att endast den slutliga, konsekventa instruktionen styr dess åtgärder.
Fler frågor om kontextteknik?
Gå med i Microsoft Foundry Discord för att träffa andra elever, delta i kontorstider och få dina frågor om AI-agenter besvarade.
Ansvarsfriskrivning: Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet bör du vara medveten om att automatiska översättningar kan innehålla fel eller brister. Det ursprungliga dokumentet i sitt originalspråk bör betraktas som den auktoritativa källan. För viktig information rekommenderas professionell översättning utförd av en mänsklig översättare. Vi ansvarar inte för några missförstånd eller feltolkningar som uppstår på grund av användningen av denna översättning.