ai-agents-for-beginners
Pag-engineer ng Konteksto para sa mga Ahente ng AI

(I-click ang larawan sa itaas para panoorin ang video ng leksyong ito)
Mahalagang maunawaan ang kompleksidad ng aplikasyon na binubuo mo para sa isang AI agent upang makagawa ng isang maaasahang isa. Kailangan nating bumuo ng mga AI Agent na epektibong namamahala ng impormasyon upang tugunan ang mga kumplikadong pangangailangan na lampas sa prompt engineering.
Sa leksyong ito, titingnan natin kung ano ang pag-engineer ng konteksto at ang papel nito sa pagbuo ng mga AI agent.
Panimula
Saklaw ng leksyong ito:
• Ano ang Pag-engineer ng Konteksto at bakit ito naiiba sa prompt engineering.
• Mga Estratehiya para sa mabisang Pag-engineer ng Konteksto, kabilang kung paano magsulat, pumili, mag-compress, at mag-isolate ng impormasyon.
• Karaniwang Pagkabigo ng Konteksto na maaaring makasira sa iyong AI agent at kung paano ayusin ang mga ito.
Mga Layunin sa Pagkatuto
Matapos matapos ang leksyong ito, maiintindihan mo kung paano:
• I-defina ang pag-engineer ng konteksto at iiba ito mula sa prompt engineering.
• Tukuyin ang mga pangunahing bahagi ng konteksto sa mga aplikasyon ng Large Language Model (LLM).
• I-apply ang mga estratehiya para sa pagsulat, pagpili, pag-compress, at pag-iisolate ng konteksto upang mapabuti ang pagganap ng agent.
• Kilalanin ang mga karaniwang pagkabigo ng konteksto gaya ng poisoning, distraction, confusion, at clash, at magpatupad ng mga teknik sa pag-iwas.
Ano ang Pag-engineer ng Konteksto?
Para sa mga AI Agent, ang konteksto ang nagtutulak sa pagpaplano ng isang AI Agent upang gumawa ng mga partikular na aksyon. Ang Pag-engineer ng Konteksto ay ang gawain ng pagtiyak na ang AI Agent ay may tamang impormasyon upang makumpleto ang susunod na hakbang ng gawain. Limitado ang laki ng context window, kaya bilang mga tagabuo ng agent kailangan nating bumuo ng mga sistema at proseso upang pamahalaan ang pagdaragdag, pagtanggal, at pagpagpaliit ng impormasyon sa context window.
Prompt Engineering vs Context Engineering
Nakatuon ang prompt engineering sa isang nakapirming hanay ng mga instruksyon upang epektibong gabayan ang mga AI Agent gamit ang isang set ng mga patakaran. Ang context engineering naman ay kung paano pamahalaan ang isang dinamikong hanay ng impormasyon, kasama na ang paunang prompt, upang matiyak na ang AI Agent ay may kailangan nito sa paglipas ng panahon. Ang pangunahing ideya sa paligid ng context engineering ay gawing paulit-ulit at maaasahan ang prosesong ito.
Mga Uri ng Konteksto

Mahalagang tandaan na ang konteksto ay hindi isang bagay lamang. Ang impormasyon na kailangan ng AI Agent ay maaaring manggaling sa iba’t ibang pinagkukunan at tungkulin nating tiyakin na may access ang agent sa mga pinagkukunang ito:
Ang mga uri ng kontekstong maaaring kailanganin ng isang AI agent upang pamahalaan ay kinabibilangan ng:
• Instruksyon: Ito ay parang mga “patakaran” ng agent – prompts, system messages, few-shot examples (nagpapakita sa AI kung paano gumawa ng isang bagay), at mga paglalarawan ng mga tool na maaari nitong gamitin. Dito pinagsasama ang pokus ng prompt engineering at context engineering.
• Kaalaman: Saklaw nito ang mga katotohanan, impormasyon na nakuha mula sa mga database, o pangmatagalang memorya na naipon ng agent. Kasama dito ang integrasyon ng Retrieval Augmented Generation (RAG) system kung kailangan ng agent ng access sa iba’t ibang knowledge stores at databases.
• Mga Tool: Ito ang mga depinisyon ng external functions, APIs at MCP Servers na maaaring tawagin ng agent, kasama ang feedback (mga resulta) na nakukuha nito mula sa paggamit ng mga ito.
• Kasaysayan ng Usapan: Ang nagpapatuloy na dayalogo sa isang user. Habang lumilipas ang oras, tumatagal at nagiging mas kumplikado ang mga usapang ito na nangangahulugang kumakain sila ng espasyo sa context window.
• Mga Kagustuhan ng User: Impormasyon na natutunan tungkol sa mga gusto o hindi gusto ng isang user sa paglipas ng panahon. Maaaring itago ang mga ito at tawagin kapag gumagawa ng mga pangunahing desisyon upang tulungan ang user.
Mga Estratehiya para sa Epektibong Pag-engineer ng Konteksto
Mga Estratehiya sa Pagpaplano
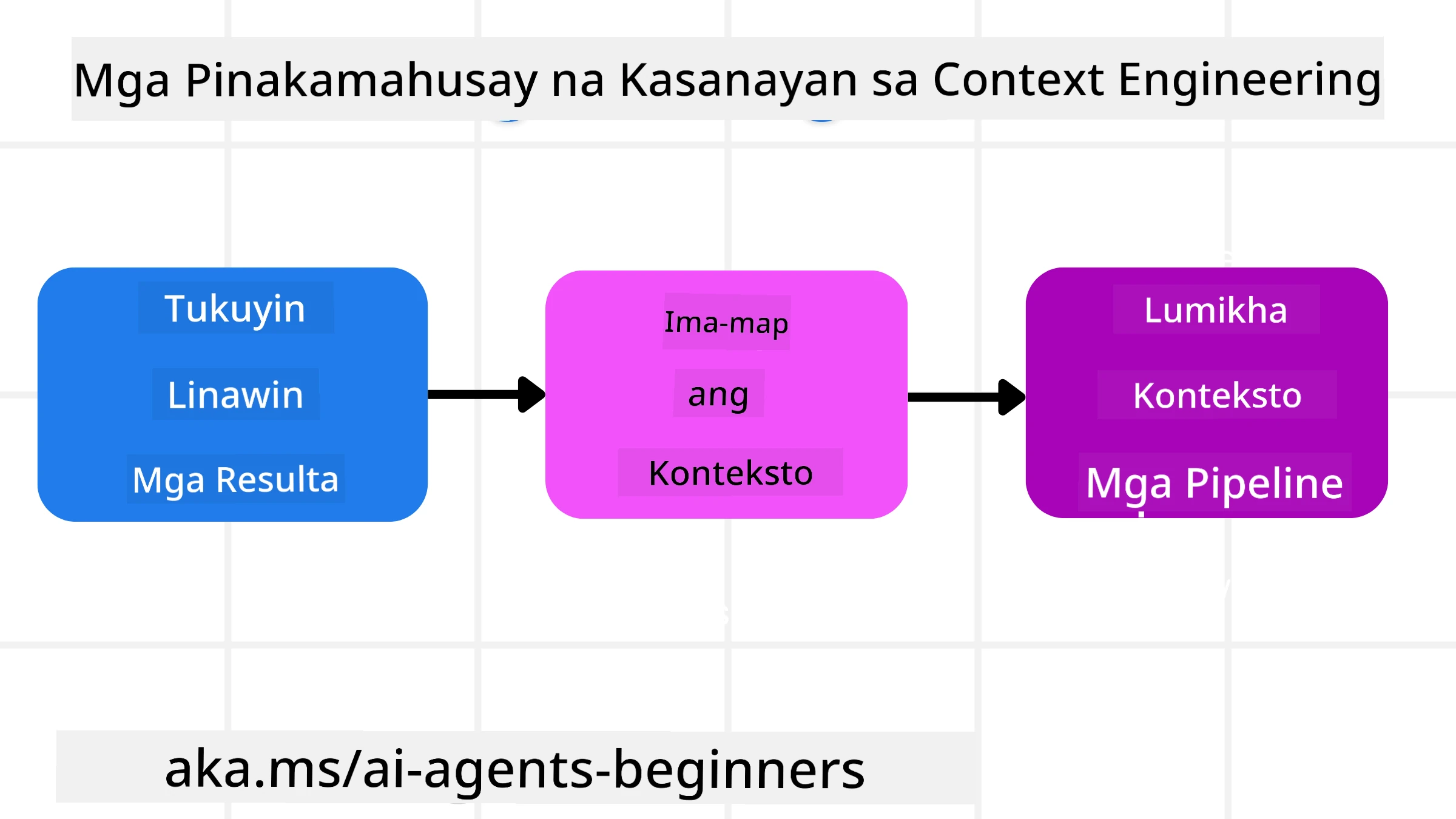
Nagsisimula ang mabuting pag-engineer ng konteksto sa mahusay na pagpaplano. Narito ang isang pamamaraan na tutulong sa iyo upang simulan ang pag-iisip kung paano i-apply ang konsepto ng pag-engineer ng konteksto:
- Mag-defina ng Malinaw na Resulta - Dapat malinaw na nade-define ang mga resulta ng mga gawain na itatalaga sa mga AI Agent. Sagutin ang tanong - “Ano ang magiging hitsura ng mundo kapag tapos na ang AI Agent sa kanyang gawain?” Sa ibang salita, anong pagbabago, impormasyon, o tugon ang dapat makuha ng user pagkatapos makipag-ugnayan sa AI Agent.
- I-map ang Konteksto - Kapag na-define mo na ang mga resulta ng AI Agent, kailangan mong sagutin ang tanong na “Anong impormasyon ang kailangan ng AI Agent upang makumpleto ang gawain na ito?”. Sa ganitong paraan maaari mong simulang i-map ang konteksto kung saan maaaring matagpuan ang impormasyong iyon.
- Lumikha ng mga Context Pipeline - Ngayon na alam mo kung saan ang impormasyon, kailangan mong sagutin ang tanong na “Paano makukuha ng Agent ang impormasyong ito?”. Maaari itong gawin sa iba’t ibang paraan kabilang ang RAG, paggamit ng MCP servers at iba pang mga tool.
Praktikal na Mga Estratehiya
Mahalaga ang pagpaplano ngunit kapag nagsimulang dumaloy ang impormasyon sa context window ng ating agent, kailangan natin ng mga praktikal na estratehiya upang pamahalaan ito:
Pamamahala ng Konteksto
Habang ang ilang impormasyon ay awtomatikong idadagdag sa context window, ang pag-engineer ng konteksto ay tungkol sa pagiging mas aktibo sa paghawak ng impormasyong ito na maaaring gawin sa ilang mga estratehiya:
-
Agent Scratchpad Ito ay nagpapahintulot sa isang AI Agent na magtala ng mga nauugnay na impormasyon tungkol sa kasalukuyang mga gawain at pakikipag-ugnayan sa user sa loob ng isang sesyon. Dapat itong umiiral sa labas ng context window sa isang file o runtime object na maaaring kunin ng agent mamaya sa sesyong ito kung kinakailangan.
-
Memories Maganda ang scratchpads para sa pamamahala ng impormasyon sa labas ng context window ng isang solong sesyon. Pinapayagan ng memories ang mga agent na mag-imbak at kumuha ng mga nauugnay na impormasyon sa maraming sesyon. Maaaring kasama rito ang mga buod, kagustuhan ng user at feedback para sa mga pagpapabuti sa hinaharap.
-
Pag-compress ng Konteksto Kapag lumalaki ang context window at papalapit na sa limitasyon nito, maaaring gamitin ang mga teknik tulad ng summarization at trimming. Kasama dito ang pagpapanatili lamang ng pinaka-nauugnay na impormasyon o pagtanggal ng mga lumang mensahe.
-
Multi-Agent Systems Ang pag-develop ng multi-agent system ay isang anyo ng pag-engineer ng konteksto dahil bawat agent ay may sarili nitong context window. Kung paano ibinabahagi at ipinapasa ang kontekstong iyon sa iba’t ibang agent ay isa pang bagay na dapat planuhin kapag binubuo ang mga sistemang ito.
-
Sandbox Environments Kung kailangan ng agent na magpatakbo ng ilang code o magproseso ng malaking dami ng impormasyon sa isang dokumento, maaaring gumamit ito ng maraming token upang iproseso ang mga resulta. Sa halip na itago ang lahat nito sa context window, maaaring gumamit ang agent ng sandbox environment na kayang patakbuhin ang code na ito at basahin lamang ang mga resulta at iba pang nauugnay na impormasyon.
-
Runtime State Objects Ginagawa ito sa pamamagitan ng paglikha ng mga container ng impormasyon upang pamahalaan ang mga sitwasyon kung kailan kailangan ng Agent na magkaroon ng access sa tiyak na impormasyon. Para sa isang kumplikadong gawain, papayagan nito ang Agent na i-imbak ang mga resulta ng bawat subtask nang hakbang-hakbang, na nagpapahintulot na manatiling konektado ang konteksto lamang sa partikular na subtask na iyon.
Halimbawa ng Pag-engineer ng Konteksto
Sabihin nating gusto natin ang isang AI agent na “Mag-book ng biyahe papuntang Paris para sa akin.”
• Ang isang simpleng agent na gumagamit lamang ng prompt engineering ay maaaring tumugon lang: “Okay, kailan mo gustong pumunta sa Paris?”. Pinroseso lang nito ang iyong direktang tanong noong oras na nagtanong ang user.
• Ang isang agent na gumagamit ng mga estratehiya ng context engineering na tinalakay ay gagawa ng mas marami. Bago pa man sumagot, maaaring gawin ng system nito:
◦ Suriin ang iyong kalendaryo para sa mga available na petsa (kumukuha ng real-time na data).
◦ Alalahanin ang nakaraang mga kagustuhan sa paglalakbay (mula sa long-term memory) tulad ng iyong paboritong airline, badyet, o kung mas gusto mo ba ang direct flights.
◦ Tukuyin ang mga available na tool para sa pag-book ng flight at hotel.
- Pagkatapos, ang isang halimbawa ng tugon ay pwedeng maging: “Hey [Your Name]! I see you’re free the first week of October. Shall I look for direct flights to Paris on [Preferred Airline] within your usual budget of [Budget]?” Ang mas mayaman na tugon na may kamalayan sa konteksto na ito ay nagpapakita ng kapangyarihan ng pag-engineer ng konteksto.
Karaniwang Pagkabigo ng Konteksto
Context Poisoning
Ano ito: Kapag isang hallucination (maling impormasyon na ginawa ng LLM) o isang error ang pumasok sa konteksto at paulit-ulit na nirerefer, na nagiging dahilan para ang agent ay maghangad ng mga imposibleng layunin o bumuo ng mga walang kabuluhang estratehiya.
Ano ang gagawin: Magpatupad ng context validation at quarantine. I-validate ang impormasyon bago ito idagdag sa long-term memory. Kung may napansin na potensyal na poisoning, magsimula ng mga bagong context thread upang pigilan ang pagkalat ng maling impormasyon.
Halimbawa sa Pag-book ng Paglalakbay: Nag-hallucinate ang iyong agent ng direct flight mula sa maliit na lokal na paliparan papunta sa malayong internasyonal na lungsod na hindi naman talaga nag-aalok ng international flights. Ang di-umiiral na detalye ng flight na ito ay nai-save sa konteksto. Pagkaraan, kapag tinanong mo ang agent na mag-book, patuloy nitong hinahanap ang mga ticket para sa imposibleng rutang ito, na nagreresulta sa paulit-ulit na mga error.
Solusyon: Magpatupad ng isang hakbang na nagsa-validate ng pagkakaroon ng flight at mga ruta gamit ang real-time API bago idagdag ang detalye ng flight sa working context ng agent. Kung mabigo ang validation, ang maling impormasyon ay “ikukwarantine” at hindi gagamitin pa.
Context Distraction
Ano ito: Kapag naging napakalaki ang konteksto na masyadong nagpo-focus ang modelo sa naipong kasaysayan sa halip na gamitin ang natutunan nito sa training, na nagreresulta sa paulit-ulit o hindi kapaki-pakinabang na mga aksyon. Maaaring magsimulang magkamali ang mga modelo kahit bago pa punuin ang context window.
Ano ang gagawin: Gumamit ng context summarization. Panahon-panahong i-compress ang naipong impormasyon sa mas maiikling buod, pinapanatili ang mahahalagang detalye habang inaalis ang redundant na kasaysayan. Nakakatulong ito upang “i-reset” ang pokus.
Halimbawa sa Pag-book ng Paglalakbay: Matagal ninyong pinag-usapan ang iba’t ibang dream travel destinations, kabilang ang detalyadong pagkukuwento ng iyong backpacking trip dalawang taon na ang nakalipas. Nang huli mong hilingin na “maghanap ng murang flight para sa akin para sa susunod na buwan,” natabunan ang agent ng lumang, hindi na kaugnay na detalye at tuloy-tuloy nitong tinatanong ang tungkol sa iyong backpacking gear o mga nakaraang itinerary, na binabalewala ang iyong kasalukuyang kahilingan.
Solusyon: Pagkatapos ng isang tiyak na bilang ng mga turn o kapag lumaki na ang konteksto, ang agent ay dapat buodin ang pinaka-kamakailan at pinaka-nauugnay na bahagi ng pag-uusap – nakatuon sa iyong kasalukuyang mga petsa ng paglalakbay at destinasyon – at gamitin ang pinaikling buod na iyon para sa susunod na LLM call, itinatapon ang hindi gaanong kaugnay na makasaysayang chat.
Context Confusion
Ano ito: Kapag ang hindi kinakailangang konteksto, madalas sa anyo ng masyadong maraming magagamit na mga tool, ay nagiging sanhi para sa modelo na gumawa ng masamang tugon o tumawag ng hindi kaugnay na mga tool. Mas madaling maapektuhan nito ang mas maliliit na modelo.
Ano ang gagawin: Magpatupad ng tool loadout management gamit ang mga teknik ng RAG. Itago ang mga deskripsyon ng tool sa isang vector database at piliin lamang ang pinaka-nauugnay na mga tool para sa bawat partikular na gawain. Ipinapakita ng pananaliksik ang pag-limit sa pagpili ng tool sa mas mababa sa 30.
Halimbawa sa Pag-book ng Paglalakbay: May access ang iyong agent sa dose-dosenang tool: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations, atbp. Tinanong mo, “Ano ang pinakamagandang paraan para maglibot sa Paris?” Dahil sa dami ng mga tool, naguguluhan ang agent at sinusubukan nitong tawagin ang book_flight sa loob ng Paris, o rent_car kahit mas gusto mo ang pampublikong transportasyon, dahil maaaring mag-overlap ang mga deskripsyon ng tool o hindi nito matukoy kung alin ang pinakamainam.
Solusyon: Gumamit ng RAG sa ibabaw ng mga deskripsyon ng tool. Kapag nagtanong ka tungkol sa paglibot sa Paris, dinamiko na kinukuha ng sistema lamang ang pinaka-nauugnay na mga tool gaya ng rent_car o public_transport_info batay sa iyong query, na nagpapakita ng isang naka-focus na “loadout” ng mga tool sa LLM.
Context Clash
Ano ito: Kapag may magkasalungat na impormasyon sa loob ng konteksto, na nagreresulta sa hindi magkakatugmang pag-rason o masamang panghuling tugon. Madalas itong nangyayari kapag dumarating ang impormasyon sa mga yugto, at nananatili sa konteksto ang mga unang, maling hinuha.
Ano ang gagawin: Gumamit ng context pruning at offloading. Ang pruning ay nangangahulugang pagtanggal ng lipas o magkasalungat na impormasyon habang dumarating ang mga bagong detalye. Ang offloading naman ay nagbibigay sa modelo ng hiwalay na “scratchpad” workspace upang iproseso ang impormasyon nang hindi nagkakalat sa pangunahing konteksto.
Halimbawa sa Pag-book ng Paglalakbay: Unang sinabi mo sa iyong agent, “Gusto kong mag-flight sa economy class.” Kalaunan sa pag-uusap, nagbago ang isip at sinabi mo, “Sa katunayan, para sa biyahe na ito, business class na lang.” Kung pareho pang nananatili sa konteksto, maaaring makakuha ang agent ng magkasalungat na search results o malito kung alin ang prayoridad na kagustuhan.
Solusyon: Magpatupad ng context pruning. Kapag ang bagong instruksyon ay sumasalungat sa lumang isa, ang lumang instruksyon ay tinatanggal o tahasang ine-override sa konteksto. Bilang alternatibo, maaaring gumamit ang agent ng scratchpad upang paghinayin ang magkasalungat na mga kagustuhan bago magpasyang aksyunan, tinitiyak na ang tanging huling, magkakatugmang instruksyon lamang ang gumagabay sa mga aksyon nito.
May Karagdagang Mga Tanong Tungkol sa Pag-engineer ng Konteksto?
Sumali sa Microsoft Foundry Discord upang makipagkita sa iba pang mga nag-aaral, dumalo sa office hours at masagot ang iyong mga tanong tungkol sa AI Agents.
Paunawa: Isinalin ang dokumentong ito gamit ang AI translation service na Co-op Translator. Bagaman nagsusumikap kami para sa katumpakan, pakitandaan na ang awtomatikong pagsasalin ay maaaring maglaman ng mga pagkakamali o kamalian. Ang orihinal na dokumento sa orihinal nitong wika ang dapat ituring na opisyal na sanggunian. Para sa mahahalagang impormasyon, inirerekomenda ang propesyonal na pagsasaling-tao. Hindi kami mananagot sa anumang hindi pagkakaunawaan o maling interpretasyon na maaaring magmula sa paggamit ng pagsasaling ito.