ai-agents-for-beginners

(点击上方图片观看本课视频)
代理式RAG
本课全面介绍了代理式检索增强生成(Agentic RAG),这是一种新兴的AI范式,在该范式下,大型语言模型(LLMs)能够自主规划下一步操作,同时从外部来源获取信息。不同于静态的先检索后阅读模式,代理式RAG涉及对LLM的迭代调用,穿插工具或函数调用及结构化输出。系统评估结果、优化查询、在必要时调用额外工具,并持续循环直到获得满意的解决方案。
介绍
本课将涵盖
- 理解代理式RAG: 了解在AI中出现的一种新范式,大型语言模型(LLMs)能够自主规划下一步操作,同时从外部数据源获取信息。
- 掌握迭代的制作者-检查者风格: 理解迭代调用LLM的循环,穿插工具或函数调用及结构化输出,旨在提升正确性和处理格式错误的查询。
- 探索实际应用: 识别代理式RAG表现突出的场景,如优先保证正确性的环境、复杂的数据库交互和延伸的工作流程。
学习目标
完成本课后,你将了解/掌握:
- 理解代理式RAG: 了解AI中新兴的范式,大型语言模型(LLMs)能够自主规划后续步骤,同时从外部数据源提取信息。
- 迭代的制作者-检查者风格: 掌握围绕迭代调用LLM的循环概念,穿插工具或函数调用和结构化输出,以提升正确性并处理格式错误查询。
- 掌控推理过程: 理解系统如何掌控其推理流程,基于问题自主决策解决策略,而非依赖预定义路径。
- 工作流程: 了解代理模型如何独立决定检索市场趋势报告、识别竞争对手数据、关联内部销售指标、综合分析成果与评估策略。
- 迭代循环、工具整合及记忆: 学习系统如何依赖循环交互模式,跨步骤维持状态和记忆,避免重复循环并作出明智决策。
- 处理失败模式与自我纠正: 探索系统强大的自我纠正机制,包括迭代与重新查询、利用诊断工具及依赖人工监督。
- 代理的边界: 理解代理式RAG的局限,聚焦于领域特定的自主性、基础设施依赖性和对安全措施的遵守。
- 实际使用案例和价值: 识别代理式RAG表现突出的多场景,如优先保证正确性的环境、复杂数据库交互和延伸的工作流程。
- 治理、透明度与信任: 了解治理和透明度的重要性,包括可解释推理、偏差控制和人工监管。
什么是代理式RAG?
代理式检索增强生成(Agentic RAG)是一种新兴的AI范式,在此范式中,大型语言模型(LLMs)能够自主规划下一步操作,同时从外部来源获取信息。与静态的先检索后阅读模式不同,代理式RAG中,LLM通过迭代调用,穿插工具或函数调用及结构化输出。系统对结果进行评估,优化查询,必要时调用额外工具,并不断循环直到达到满意的解决方案。这种迭代的“制作者-检查者”模式提升了准确性,处理了格式错误的查询,确保高质量结果。
系统主动掌控推理流程,重写失败的查询、选择不同的检索方法、整合多种工具——如Azure AI Search的向量搜索、SQL数据库或自定义API——然后确定最终答案。代理式系统的显著特质是其对推理过程的自主掌控。传统RAG实现依赖预定义路径,而代理系统根据找到的信息质量自主决定步骤顺序。
代理式检索增强生成(Agentic RAG)定义
代理式检索增强生成(Agentic RAG)是一种AI开发中新兴的范式,在此范式中,LLM不仅从外部数据源提取信息,还能自主规划下一步。不同于静态的先检索后读模式或精心编写的提示序列,代理式RAG包含一个迭代调用LLM的循环,穿插工具或函数调用及结构化输出。每一步系统评估取得的结果,决定是否优化查询,必要时调用额外工具,持续循环直至获得满意解决方案。
这种迭代的“制作者-检查者”操作模式设计用于提升正确性,处理结构化数据库中格式错误的查询(如NL2SQL),确保平衡且高质量的结果。系统主动掌控推理过程,能重写失败查询,选择不同检索方法,整合多种工具——如Azure AI Search中的向量搜索、SQL数据库或自定义API——最终确定答案。这样免去了过于复杂的编排框架,简单的“LLM调用→使用工具→再次调用LLM→…”循环即可产出复杂且有根有据的输出。
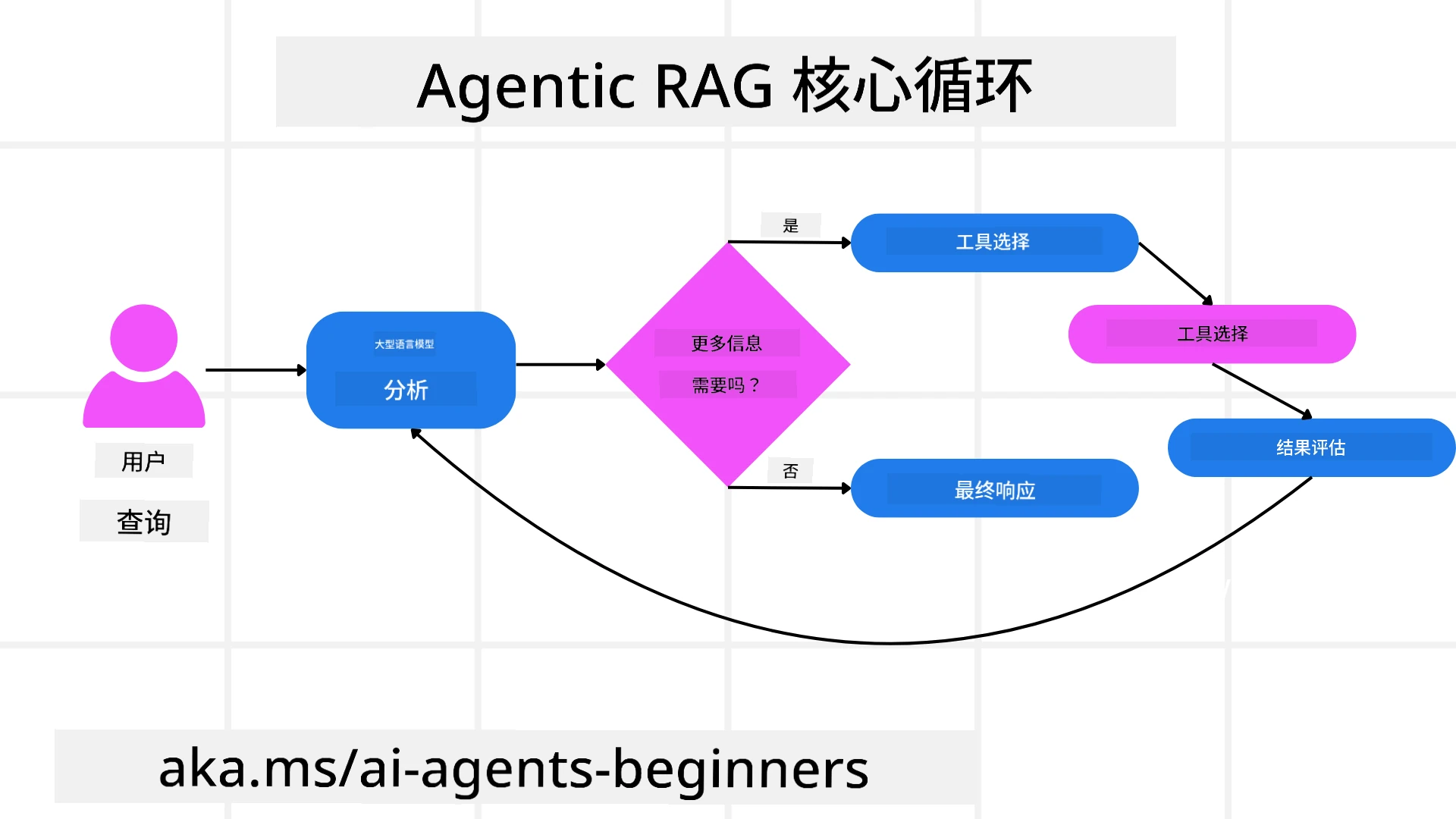
掌控推理过程
让系统“代理式”的关键品质,是其掌控推理过程的能力。传统RAG实现往往依赖人类预先定义模型路径:一个描述了何时及如何检索的思路链。但真正的代理系统会自主决定如何解决问题。它不仅仅是在执行脚本,而是基于获取信息的质量自主确定步骤顺序。 举例来说,当被要求制定产品发布策略时,它不会单纯依赖提示中完整的研究和决策流程。相反,代理模型独立决定:
- 使用Bing网页检索获取当前市场趋势报告
- 利用Azure AI Search识别相关竞争对手数据
- 通过Azure SQL数据库关联历史内部销售指标
- 结合Azure OpenAI服务综合分析结果形成整体策略
- 评估策略是否存在缺口或不一致,并在必要时进行下一轮检索 所有这些步骤——查询优化、选择信息源、迭代直至“满意”答案——均由模型自主决策,而非人工预设脚本。
迭代循环、工具整合与记忆
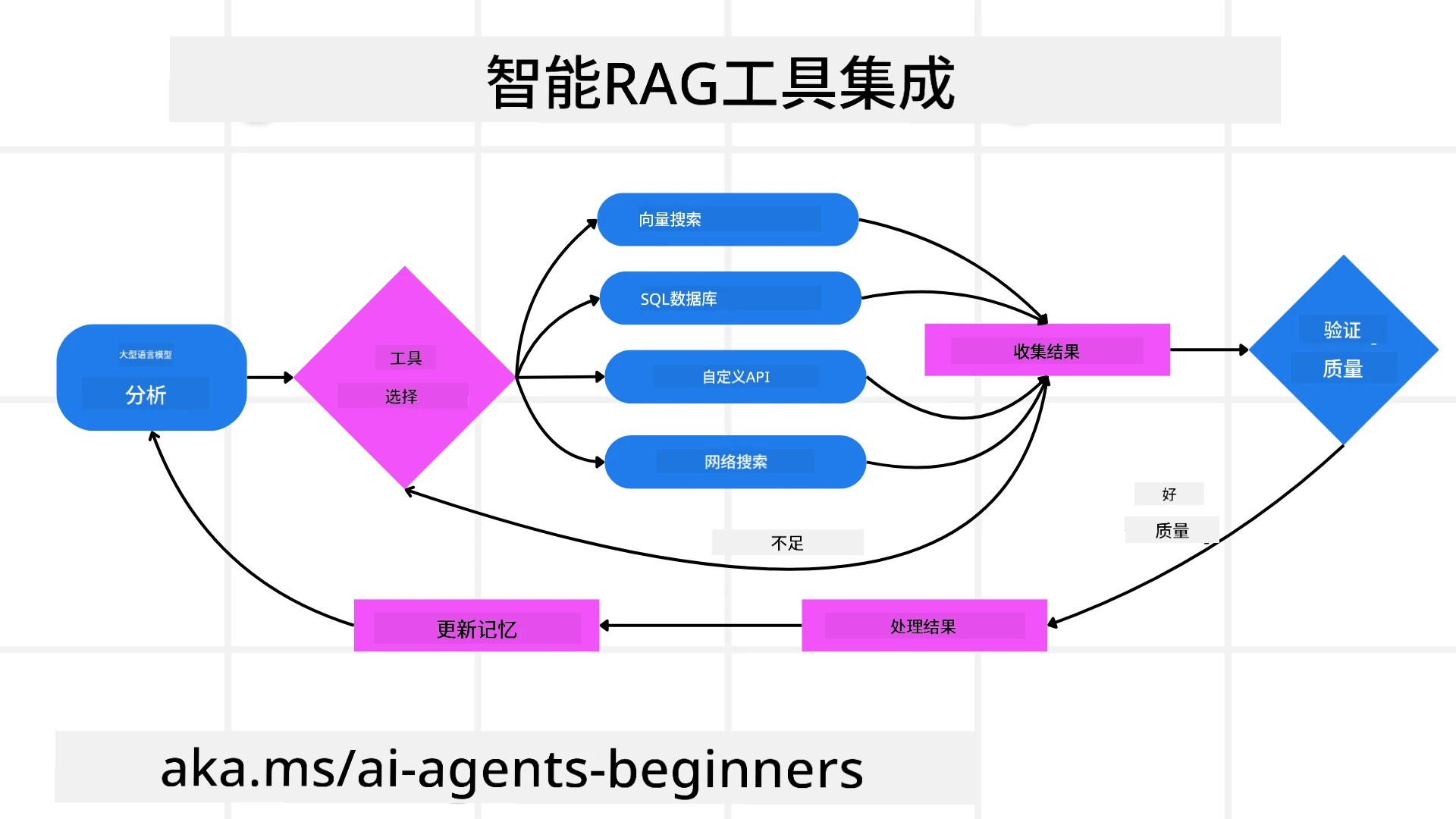
代理系统依赖循环互动模式:
- 初始调用: 将用户目标(即用户提示)提供给LLM。
- 工具调用: 如果模型发现信息缺失或指令模糊,则选择一个工具或检索方法——例如向量数据库查询(如Azure AI Search对私有数据的混合搜索)或结构化SQL调用——以获取更多上下文。
- 评估与优化: 评审返回数据后,模型判断信息是否足够。若不足,调整查询,尝试不同工具或修改策略。
- 循环直至满意: 这一循环持续进行,直到模型确定已有足够清晰且证据充分的信息以给出最终合理回答。
- 记忆与状态: 系统在各步骤间维持状态和记忆,能回忆之前尝试及结果,避免重复循环,且随着进展作出更明智的决策。
随着时间推移,模型对任务理解逐渐深化,能够处理复杂多步骤任务,无需人工反复干预或重塑提示。
处理失败模式与自我纠正
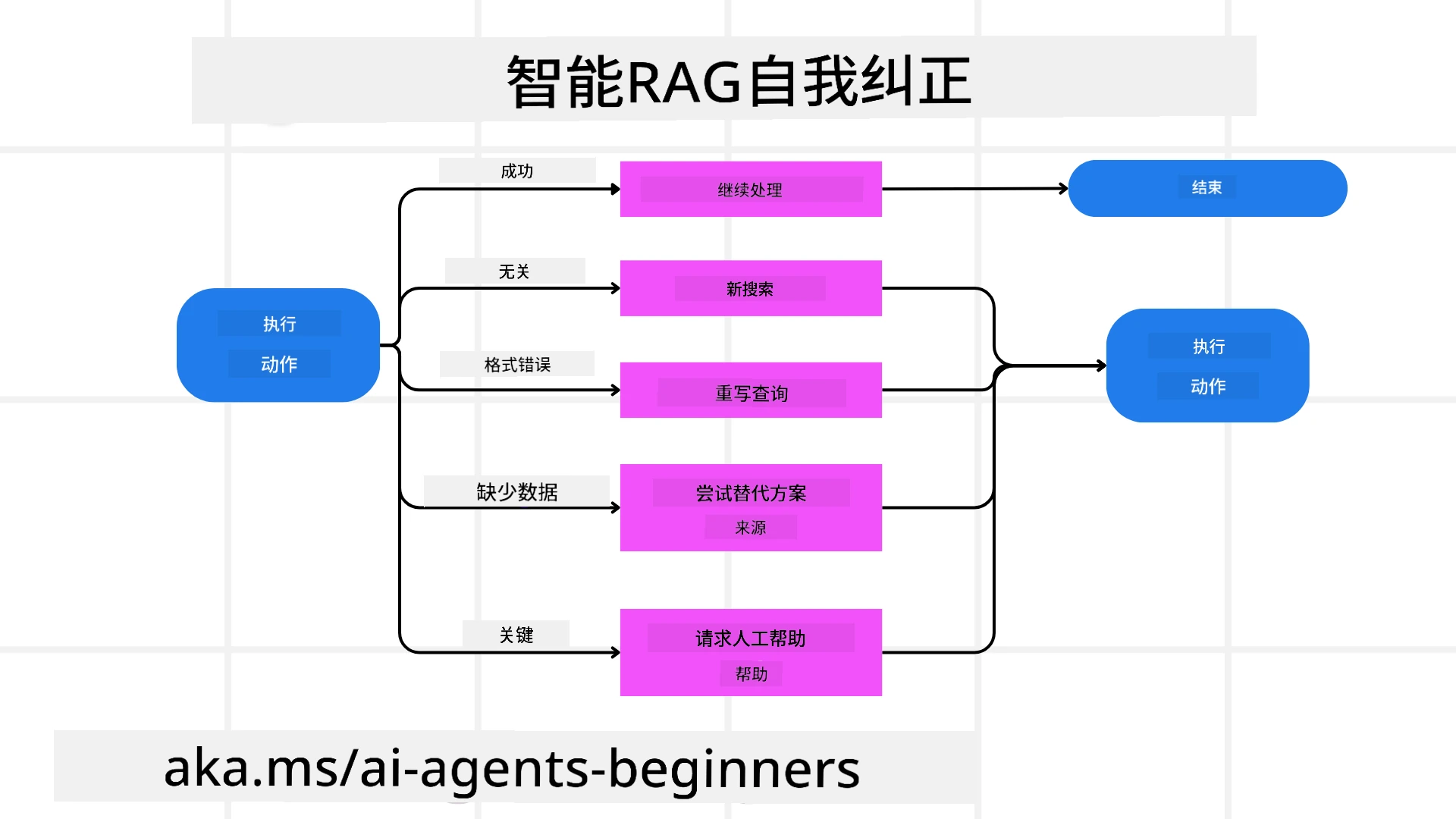
代理式RAG的自主性还体现在强大的自我纠正机制上。当系统遇到死胡同——如检索到无关文件或处理格式错误的查询——它能:
- 迭代和重新查询: 不返回低价值回复,而是尝试新的检索策略,重写数据库查询,或查看替代数据集。
- 使用诊断工具: 系统或调用额外函数帮助调试推理步骤,确认检索数据的正确性。诸如Azure AI Tracing等工具是实现强大可观测性和监控的关键。
- 依赖人工监督: 在高风险或多次失败场景下,模型可能提示不确定性并请求人工指导。一旦收到纠正反馈,模型能将经验纳入后续流程。
这种迭代动态方法使模型不断改进,既非一次性系统,而是在会话中从错误中学习。
代理的边界
尽管任务中具有自主性,代理式RAG并不等同于通用人工智能。其“代理”能力受限于开发者提供的工具、数据源和策略。它不能自行发明工具或突破设定的领域边界,而是擅长动态编排现有资源。 与更高级AI形式的主要区别包括:
- 领域特定自主性: 代理式RAG系统聚焦于在已知领域内实现用户定义目标,使用如查询重写或工具选择等策略提升结果。
- 基础设施依赖: 系统能力依赖开发者整合的工具和数据,无法无人工干预跨越这些界限。
- 遵守防护措施: 道德规范、合规规则和业务政策极为重要。代理的自由始终受限于安全措施和监管机制(希望如此?)
实际使用案例与价值
代理式RAG在需要迭代优化和精准性的场景中表现出色:
- 优先正确性环境: 如合规检查、监管分析或法律研究,代理模型可反复验证事实,咨询多方来源,重写查询直至给出充分审查答案。
- 复杂数据库交互: 处理结构化数据时,查询常常失败或需调整,系统能自主用Azure SQL或Microsoft Fabric OneLake细化查询,确保最终检索符合用户意图。
- 延伸工作流程: 长时会话可能随着新信息出现不断演变。代理式RAG可持续融合新数据,随着对问题域理解深入调整策略。
治理、透明度与信任
随着系统推理自主性增强,治理与透明度尤为关键:
- 可解释推理: 模型可提供查询轨迹、咨询的来源及推理步骤的审计日志。Azure AI Content Safety和Azure AI Tracing / GenAIOps等工具有助于保持透明并降低风险。
- 偏差控制与均衡检索: 开发者可调优检索策略,确保考虑到均衡、具有代表性的数据源,借助Azure Machine Learning中的自定义模型定期审计输出,检测偏差或失衡模式,特别适合高级数据科学团队。
- 人工监管与合规: 对于敏感任务,人工复核仍不可或缺。代理式RAG不是取代人工判断,而是通过提供更详实审核的选项增强其能力。
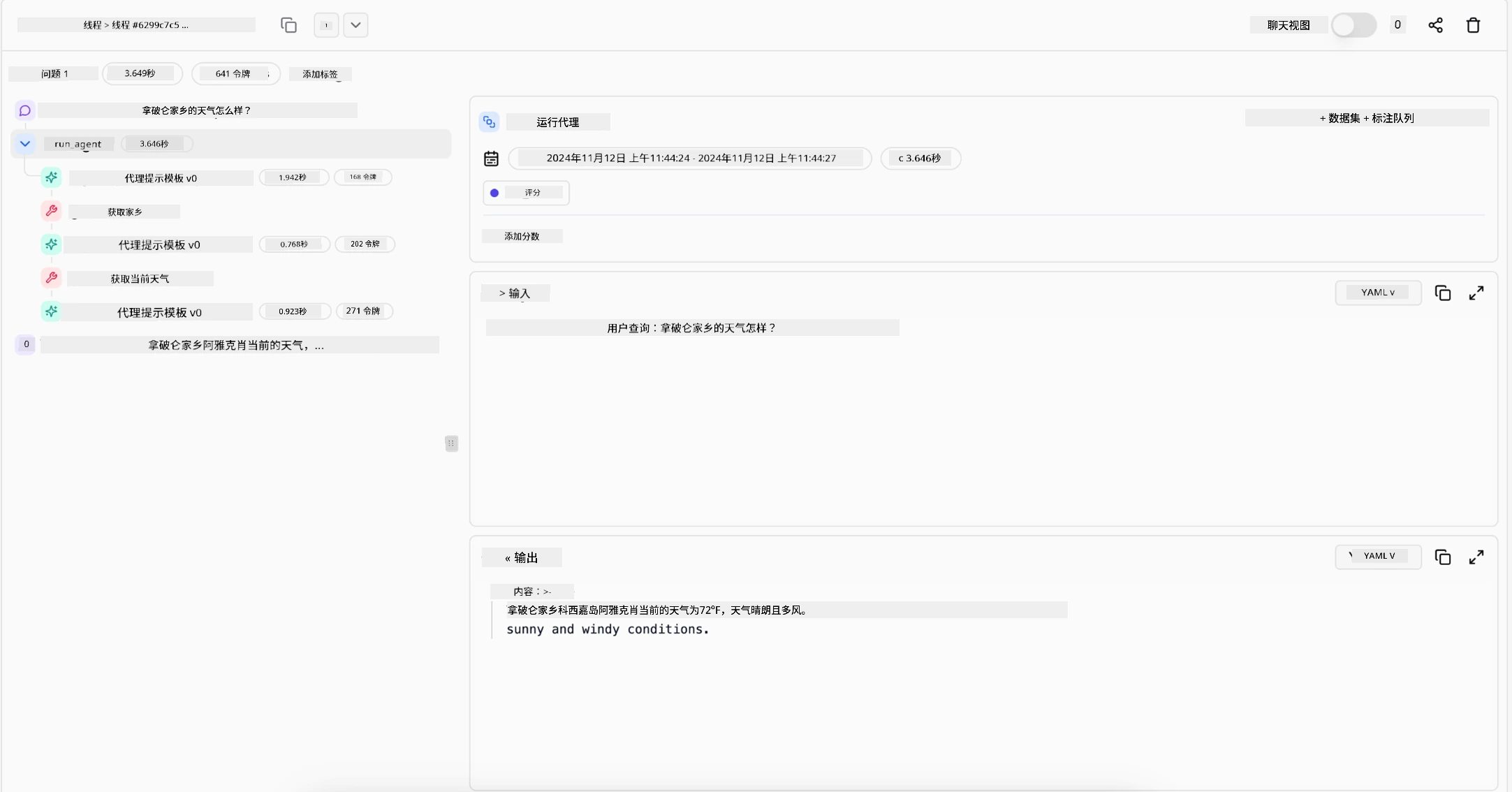
具备能清晰记录操作的工具至关重要,缺失这些工具,调试多步骤过程将极为困难。以下示例来自Literal AI(Chainlit背后的公司),展示一次代理运行:
结论
代理式RAG代表了AI系统处理复杂数据密集任务的自然演进。通过采用循环交互模式,自主选择工具,优化查询直至达到高质量结果,系统超越了静态提示跟随,成为更具适应性、且具上下文感知的决策者。虽然仍受限于人类定义的基础设施和伦理准则,这些代理能力使得企业和终端用户获得更加丰富、动感与实用的AI交互体验。
关于代理式RAG还有更多疑问?
加入 Microsoft Foundry Discord,与其他学习者交流,参加答疑时间,获得有关AI代理的解答。
附加资源
- 使用 Azure OpenAI 服务实现检索增强生成(RAG):学习如何使用您自己的数据与 Azure OpenAI 服务。本 Microsoft Learn 模块提供了实施 RAG 的全面指南
- 使用 Microsoft Foundry 评估生成式 AI 应用:本文涵盖在公开数据集上对模型的评估和比较,包括自主 AI 应用和 RAG 架构
- 什么是自主式 RAG | Weaviate
- 自主式 RAG:基于代理的检索增强生成完整指南 – Generation RAG 新闻
- 自主式 RAG:通过查询重构和自查询为您的 RAG 加速!Hugging Face 开源 AI 烹饪书
- 为 RAG 添加自主层
- 知识助手的未来:Jerry Liu
- 如何构建自主式 RAG 系统
- 使用 Microsoft Foundry Agent 服务扩展您的 AI 代理
学术论文
- 2303.17651 Self-Refine:带自我反馈的迭代细化
- 2303.11366 Reflexion:带语言强化学习的语言代理
- 2305.11738 CRITIC:大型语言模型可通过工具交互式批评实现自我纠正
- 2501.09136 自主式检索增强生成:关于自主式 RAG 的综述
先前课程
下一课程
免责声明:
本文件使用人工智能翻译服务 Co-op Translator 翻译。尽管我们力求准确,但请注意自动翻译可能存在错误或不准确之处。原始的母语文档应被视为权威来源。对于重要信息,建议采用专业人工翻译。我们不对因使用本翻译而产生的任何误解或误释承担责任。