ai-agents-for-beginners

(点击上方图片查看本节视频)
AI智能体中的元认知
介绍
欢迎来到关于AI智能体中元认知的课程!本章面向初学者,旨在探索AI智能体如何思考自身的思考过程。完成本节后,您将理解关键概念,并掌握将元认知应用于AI智能体设计的实用示例。
学习目标
完成本节后,您将能够:
- 理解智能体定义中推理循环的含义。
- 使用规划和评估技术帮助具有自我纠正能力的智能体。
- 创建能够操控代码以完成任务的智能体。
元认知简介
元认知指的是涉及思考自身思维的高级认知过程。对于AI智能体来说,这意味着它们能够基于自我意识和过去经验评估和调整其行动。元认知,或称“对思考的思考”,是构建具备智能行为的AI系统的重要概念。它涉及AI系统意识到自身内部过程,并能够监控、调节及适应其行为。就像我们在判断环境氛围或面对问题时所做的那样。这种自我意识可以帮助AI系统做出更好的决策,识别错误,并随着时间推移提升性能——这再次关联到图灵测试以及围绕AI是否会取代人类的争论。
在具有智能体特性的AI系统中,元认知有助于解决若干挑战,例如:
- 透明性:确保AI系统能够解释其推理和决策过程。
- 推理能力:增强AI系统整合信息和做出合理决策的能力。
- 适应性:使AI系统能够适应新环境和变化的条件。
- 认知感知:提高AI系统识别和解释环境数据的准确性。
什么是元认知?
元认知,或“对思维的思考”,是涉及自我意识和自我调节认知过程的高级认知活动。在AI领域,元认知赋能智能体评估并调整其策略和行动,从而提升解决问题和决策的能力。理解元认知后,您可以设计出不仅更智能而且更具适应性和效率的AI智能体。真正的元认知意味着AI明确地对自身的推理过程进行推理。
示例:“我优先选择便宜的航班,因为……我可能错过了直达航班,需重新检查。” 跟踪它为何或如何选择了某条路线。
- 注意到它犯了错误,因为过度依赖上次用户偏好,因此不仅修改最终建议,还调整其决策策略。
- 诊断模式,例如,“每当用户提到‘太拥挤’时,我不仅应该剔除某些景点,还应反思如果总是按人气排名‘热门景点’,这种选取方式是否存在缺陷。”
元认知在AI智能体中的重要性
元认知在AI智能体设计中发挥着关键作用,原因包括:

- 自我反思:智能体可以评估自身表现并识别改进空间。
- 适应能力:智能体基于过往经验和环境变化调整策略。
- 错误校正:智能体能够自主检测并修正错误,提升准确性。
- 资源管理:智能体通过规划和评估行动,优化时间与计算资源的使用。
AI智能体的组成部分
在深入元认知过程前,有必要理解AI智能体的基本组件。AI智能体通常包括:
- 角色设定(Persona):定义智能体与用户交互的个性和特征。
- 工具:智能体能够执行的功能和能力。
- 技能:智能体拥有的知识和专长。
这些组件协同作用,构成一个能够执行特定任务的“专业单元”。
示例: 设想一个旅游代理智能体,不仅为您规划假期,还能根据实时数据和过往客户旅程经验动态调整行程。
示例:旅游代理服务中的元认知
假设您正在设计一个由AI驱动的旅游代理服务。该智能体“旅行代理”帮助用户规划假期。为实现元认知,旅行代理需基于自我意识和过去经验评估及调整其行为。元认知作用如下:
当前任务
帮助用户规划一次巴黎之行。
完成任务的步骤
- 收集用户偏好:询问用户旅行日期、预算、兴趣(如博物馆、美食、购物)及具体需求。
- 检索信息:搜寻符合用户偏好的航班、住宿、景点和餐厅。
- 生成推荐:提供包含航班详细信息、酒店预订及建议活动的个性化行程。
- 根据反馈调整:征求用户对推荐行程的意见,并做必要调整。
需要的资源
- 航班和酒店预订数据库访问权限。
- 巴黎景点和餐厅信息。
- 以往互动的用户反馈数据。
经验与自我反思
旅行代理利用元认知评估自身表现并从经验中学习。例如:
- 分析用户反馈:旅行代理回顾反馈,识别受欢迎和不满意的推荐,并相应调整未来建议。
- 适应性调整:若用户曾表达不喜欢拥挤场所,旅行代理未来会避免在高峰时段推荐热门旅游点。
- 错误纠正:若以前预订过程中犯过如推荐已经满员酒店等错误,旅行代理将学会更严格地检查可用性,避免类似疏漏。
实际开发示例
以下是旅行代理集成元认知的简化代码示例:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
# 根据偏好搜索航班、酒店和景点
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
# 分析反馈并调整未来推荐
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# 示例用法
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
元认知为何重要
- 自我反思:智能体能分析自身表现,发现改进空间。
- 适应能力:智能体根据反馈及环境变化调整策略。
- 错误校正:智能体能自主检测并修正错误。
- 资源管理:智能体优化时间和计算资源使用。
通过集成元认知,旅行代理可提供更个性化和准确的旅行建议,提升用户体验。
2. 智能体中的规划
规划是AI智能体行为的核心部分。它涉及规划实现目标所需步骤,同时考虑当前状态、资源及可能障碍。
规划要素
- 当前任务:明确任务定义。
- 完成任务的步骤:将任务拆解为易管理的步骤。
- 所需资源:识别必要资源。
- 经验:运用过往经验指导规划。
示例: 以下是旅行代理帮助用户有效规划旅行应采取的步骤:
旅行代理步骤
- 收集用户偏好
- 询问用户有关旅行日期、预算、兴趣及具体需求。
- 示例:“您计划什么时候出行?”“预算范围是多少?”“假期喜欢哪些活动?”
- 检索信息
- 根据用户偏好搜索相关旅行选项。
- 航班:寻找符合预算和时间的可用航班。
- 住宿:匹配用户喜好的酒店或租赁房源。
- 景点及餐厅:筛选与用户兴趣相关的热门景点、活动及餐饮选项。
- 生成推荐
- 整合检索信息,制定个性化行程。
- 提供航班信息、酒店预订及推荐活动,确保符合用户偏好。
- 向用户展示行程
- 向用户展示拟定行程以供审核。
- 示例:“这是为您设计的巴黎旅行建议,包括航班、酒店及推荐的活动和餐厅,您觉得如何?”
- 收集反馈
- 征求用户对方案的反馈。
- 示例:“您感觉航班选项如何?”“酒店是否符合需求?”“需添加或删除哪些活动?”
- 基于反馈调整
- 根据用户反馈调整行程。
- 对航班、住宿和活动推荐作必要修改,更好匹配用户喜好。
- 最终确认
- 向用户展示更新后的行程并征求最终确认。
- 示例:“已根据您的反馈做了调整,以下是更新后的行程,您觉得满意吗?”
- 预订并确认
- 用户确认后,安排航班、住宿及活动预订。
- 向用户发送确认详情。
- 提供持续支持
- 出发前及旅行期间,随时协助用户处理变更或新需求。
- 示例:“旅行期间如需帮助,随时联系我!”
示例交互
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# 在预订请求中的示例用法
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
3. 纠正型RAG系统
首先,让我们了解RAG工具和先发式上下文加载的区别。
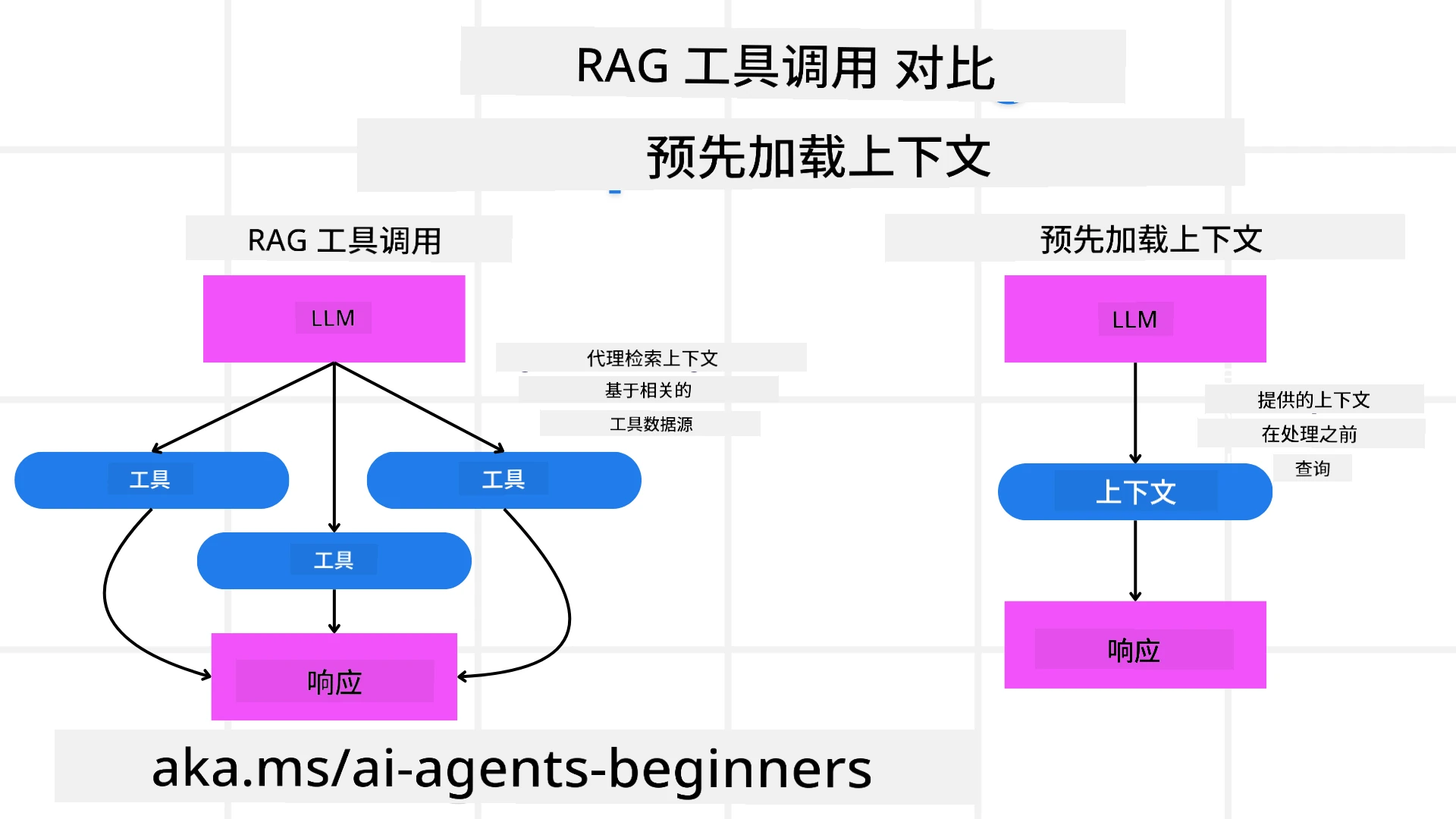
检索增强生成(RAG)
RAG结合了检索系统和生成模型。查询时,检索系统从外部源获取相关文档或数据,将检索到的信息用于增强生成模型的输入,有助于模型生成更准确且符合上下文的回答。
在RAG系统中,智能体从知识库检索相关信息,利用此信息生成恰当的回应或动作。
纠正型RAG方法
纠正型RAG方法侧重于利用RAG技术纠正错误并提升AI智能体的准确性。主要涉及:
- 提示技巧:使用特定提示引导智能体检索相关信息。
- 工具:实现算法和机制,使智能体评估检索信息的相关性并生成准确回答。
- 评估:持续评估智能体表现,进行调整以提升准确度和效率。
示例:搜索智能体中的纠正型RAG
考虑一个从网络检索信息以回答用户查询的搜索智能体。纠正型RAG方法可能包括:
- 提示技巧:基于用户输入制定搜索查询。
- 工具:使用自然语言处理及机器学习算法排序和筛选搜索结果。
- 评估:分析用户反馈,识别并纠正检索信息中的不准确部分。
旅行代理中的纠正型RAG
纠正型RAG(检索增强生成)提升了AI在检索并生成信息时纠错的能力。看看旅行代理如何利用纠正型RAG提供更加准确和相关的旅行推荐。
主要包括:
- 提示技巧:用特定提示引导智能体检索相关信息。
- 工具:实现算法和机制,评价检索信息的相关性并生成准确回应。
- 评估:持续评估智能体表现,根据反馈进行调整。
旅行代理中实施纠正型RAG的步骤
- 初始用户互动
- 旅行代理收集用户初步偏好,如目的地、旅行日期、预算和兴趣。
-
示例:
preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] }
- 信息检索
- 旅行代理基于用户偏好检索航班、住宿、景点和餐厅信息。
-
示例:
flights = search_flights(preferences) hotels = search_hotels(preferences) attractions = search_attractions(preferences)
- 生成初步推荐
- 旅行代理使用检索信息生成个性化行程。
-
示例:
itinerary = create_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary)
- 收集用户反馈
- 旅行代理征求用户对初步推荐的意见。
-
示例:
feedback = { "liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"] }
- 纠正型RAG流程
- 提示技巧:旅行代理基于用户反馈制定新搜索查询。
-
示例:
if "disliked" in feedback: preferences["avoid"] = feedback["disliked"]
-
- 工具:旅行代理使用算法对新搜索结果进行排序和筛选,强调基于用户反馈的相关性。
-
示例:
new_attractions = search_attractions(preferences) new_itinerary = create_itinerary(flights, hotels, new_attractions) print("Updated Itinerary:", new_itinerary)
-
- 评估:旅行代理通过分析用户反馈持续评估推荐的相关性和准确性,并做必要调整。
-
示例:
def adjust_preferences(preferences, feedback): if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences preferences = adjust_preferences(preferences, feedback)
-
- 提示技巧:旅行代理基于用户反馈制定新搜索查询。
实战示例
以下为结合纠正型RAG方法的旅行代理简化Python代码示例:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
new_itinerary = self.generate_recommendations()
return new_itinerary
# 示例用法
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
new_itinerary = travel_agent.adjust_based_on_feedback(feedback)
print("Updated Itinerary:", new_itinerary)
先发式上下文加载
预先加载上下文包括在处理查询之前将相关的上下文或背景信息加载到模型中。这意味着模型从一开始就可以访问这些信息,这有助于它生成更有信息量的响应,而无需在过程中检索额外的数据。
以下是一个简化示例,展示了如何在 Python 的旅行代理应用中实现预先加载上下文:
class TravelAgent:
def __init__(self):
# 预先加载热门目的地及其信息
self.context = {
"Paris": {"country": "France", "currency": "Euro", "language": "French", "attractions": ["Eiffel Tower", "Louvre Museum"]},
"Tokyo": {"country": "Japan", "currency": "Yen", "language": "Japanese", "attractions": ["Tokyo Tower", "Shibuya Crossing"]},
"New York": {"country": "USA", "currency": "Dollar", "language": "English", "attractions": ["Statue of Liberty", "Times Square"]},
"Sydney": {"country": "Australia", "currency": "Dollar", "language": "English", "attractions": ["Sydney Opera House", "Bondi Beach"]}
}
def get_destination_info(self, destination):
# 从预加载的上下文中获取目的地信息
info = self.context.get(destination)
if info:
return f"{destination}:\nCountry: {info['country']}\nCurrency: {info['currency']}\nLanguage: {info['language']}\nAttractions: {', '.join(info['attractions'])}"
else:
return f"Sorry, we don't have information on {destination}."
# 使用示例
travel_agent = TravelAgent()
print(travel_agent.get_destination_info("Paris"))
print(travel_agent.get_destination_info("Tokyo"))
说明
-
初始化(
__init__方法):TravelAgent类预加载了一个包含热门目的地信息的字典,如巴黎、东京、纽约和悉尼。该字典包括每个目的地的国家、货币、语言及主要景点等详细信息。 -
获取信息(
get_destination_info方法):当用户查询特定目的地时,get_destination_info方法从预先加载的上下文字典中获取相关信息。
通过预先加载上下文,旅行代理应用可以快速响应用户查询,而无需在实时中从外部来源检索信息,提高应用的效率和响应速度。
以目标为引导启动计划然后进行迭代
以目标为引导启动计划意味着从一开始就明确一个清晰的目标或期望结果。通过事先定义该目标,模型可以在迭代过程中将其作为指导原则。这有助于确保每次迭代都朝着实现预期结果的方向进行,使过程更高效、更有针对性。
以下是一个示例,展示如何在旅行代理中以目标引导启动和迭代旅行计划,使用Python实现:
场景
旅行代理想为客户定制个性化假期。目标是根据客户的偏好和预算制定一个能够最大化客户满意度的旅行行程。
步骤
- 定义客户的偏好和预算。
- 根据这些偏好引导启动初始计划。
- 迭代优化计划,以提升客户满意度。
Python 代码
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def bootstrap_plan(self, preferences, budget):
plan = []
total_cost = 0
for destination in self.destinations:
if total_cost + destination['cost'] <= budget and self.match_preferences(destination, preferences):
plan.append(destination)
total_cost += destination['cost']
return plan
def match_preferences(self, destination, preferences):
for key, value in preferences.items():
if destination.get(key) != value:
return False
return True
def iterate_plan(self, plan, preferences, budget):
for i in range(len(plan)):
for destination in self.destinations:
if destination not in plan and self.match_preferences(destination, preferences) and self.calculate_cost(plan, destination) <= budget:
plan[i] = destination
break
return plan
def calculate_cost(self, plan, new_destination):
return sum(destination['cost'] for destination in plan) + new_destination['cost']
# 示例用法
destinations = [
{"name": "Paris", "cost": 1000, "activity": "sightseeing"},
{"name": "Tokyo", "cost": 1200, "activity": "shopping"},
{"name": "New York", "cost": 900, "activity": "sightseeing"},
{"name": "Sydney", "cost": 1100, "activity": "beach"},
]
preferences = {"activity": "sightseeing"}
budget = 2000
travel_agent = TravelAgent(destinations)
initial_plan = travel_agent.bootstrap_plan(preferences, budget)
print("Initial Plan:", initial_plan)
refined_plan = travel_agent.iterate_plan(initial_plan, preferences, budget)
print("Refined Plan:", refined_plan)
代码说明
-
初始化(
__init__方法):TravelAgent类初始化时载入一系列潜在目的地,每个目的地包含名称、费用和活动类型等属性。 -
引导启动计划(
bootstrap_plan方法):该方法根据客户的偏好和预算创建初始旅行计划。它遍历目的地列表,若目的地符合客户偏好且预算允许,则将其加入计划。 -
匹配偏好(
match_preferences方法):该方法检查某个目的地是否符合客户的偏好。 -
迭代计划(
iterate_plan方法):该方法通过尝试用更符合客户偏好且预算符合的目的地替换计划中的部分目的地,来优化最初计划。 -
计算费用(
calculate_cost方法):该方法计算当前计划的总费用,包括潜在的新目的地。
使用示例
- 初始计划:旅行代理根据客户偏好(观光)和2000美元预算制定初始计划。
- 优化计划:旅行代理迭代优化计划,以更好地符合客户的偏好和预算。
通过明确目标(如最大化客户满意度)启动计划,并通过迭代优化计划,旅行代理可以为客户创建定制且优化的旅行行程。此方法确保从一开始旅行计划就符合客户偏好和预算,且随迭代不断改善。
利用大语言模型(LLM)进行重排序和评分
大型语言模型(LLM)可以用于重排序和评分,通过评估检索到的文档或生成的响应的相关性和质量来实现。具体如下:
检索:初步检索步骤基于查询获取一组候选文档或回答。
重排序:LLM 评估这些候选项,依据相关性和质量进行重新排序。这一步确保最相关且高质量的信息优先呈现。
评分:LLM 对每个候选项赋予分数,反映其相关性和质量,有助于挑选出最佳的响应或文档。
通过利用 LLM 进行重排序和评分,系统能够提供更准确且上下文相关的信息,从而提升整体用户体验。
下面是一个例子,说明旅行代理如何运用大语言模型(LLM)基于用户偏好对旅行目的地进行重排序和评分,Python示例:
场景 - 基于偏好的旅行推荐
旅行代理希望根据客户的偏好推荐最佳旅行目的地。LLM 将协助对这些目的地进行重排序和评分,以确保展示最相关的选项。
步骤:
- 收集用户偏好。
- 检索潜在的旅行目的地列表。
- 使用 LLM 基于用户偏好对目的地进行重排序和评分。
以下示例演示如何使用 Azure OpenAI 服务来更新之前的代码:
需求
- 需要拥有 Azure 订阅。
- 创建 Azure OpenAI 资源并获取 API 密钥。
Python示例代码
import requests
import json
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def get_recommendations(self, preferences, api_key, endpoint):
# 为 Azure OpenAI 生成提示
prompt = self.generate_prompt(preferences)
# 定义请求的头信息和载荷
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
payload = {
"prompt": prompt,
"max_tokens": 150,
"temperature": 0.7
}
# 调用 Azure OpenAI API 获取重新排序和评分的目的地
response = requests.post(endpoint, headers=headers, json=payload)
response_data = response.json()
# 提取并返回推荐结果
recommendations = response_data['choices'][0]['text'].strip().split('\n')
return recommendations
def generate_prompt(self, preferences):
prompt = "Here are the travel destinations ranked and scored based on the following user preferences:\n"
for key, value in preferences.items():
prompt += f"{key}: {value}\n"
prompt += "\nDestinations:\n"
for destination in self.destinations:
prompt += f"- {destination['name']}: {destination['description']}\n"
return prompt
# 示例用法
destinations = [
{"name": "Paris", "description": "City of lights, known for its art, fashion, and culture."},
{"name": "Tokyo", "description": "Vibrant city, famous for its modernity and traditional temples."},
{"name": "New York", "description": "The city that never sleeps, with iconic landmarks and diverse culture."},
{"name": "Sydney", "description": "Beautiful harbour city, known for its opera house and stunning beaches."},
]
preferences = {"activity": "sightseeing", "culture": "diverse"}
api_key = 'your_azure_openai_api_key'
endpoint = 'https://your-endpoint.com/openai/deployments/your-deployment-name/completions?api-version=2022-12-01'
travel_agent = TravelAgent(destinations)
recommendations = travel_agent.get_recommendations(preferences, api_key, endpoint)
print("Recommended Destinations:")
for rec in recommendations:
print(rec)
代码说明 - 偏好预订器
-
初始化:
TravelAgent类初始化时载入一系列潜在旅行目的地,每个包含名称和描述等属性。 -
获取推荐(
get_recommendations方法):该方法基于用户偏好生成发送给 Azure OpenAI 服务的提示,并通过 HTTP POST 请求调用 Azure OpenAI API 来获取重排序和评分后的目的地。 -
生成提示(
generate_prompt方法):该方法构建发送给 Azure OpenAI 的提示内容,包括用户偏好和目的地列表。提示指引模型根据提供的偏好对目的地进行重排序和评分。 -
API 调用:使用
requests库向 Azure OpenAI API 端点发送 HTTP POST 请求,响应包含重排序和评分后的目的地。 -
使用示例:旅行代理收集用户偏好(如对观光和多元文化的兴趣),使用 Azure OpenAI 服务获取重排序和评分后的旅行目的地推荐。
请务必将 your_azure_openai_api_key 替换为实际的 Azure OpenAI API 密钥,将 https://your-endpoint.com/... 替换为你的 Azure OpenAI 部署的实际端点 URL。
通过利用 LLM 进行重排序和评分,旅行代理能够为客户提供更个性化、更相关的旅行推荐,提升整体体验。
RAG:提示技术 vs 工具
检索增强生成(RAG)既可以是一种提示技术,也可以是一种AI代理开发中的工具。理解两者的区别能帮助你更有效地利用 RAG。
作为提示技术的 RAG
什么是?
- 作为提示技术,RAG 涉及构造特定查询或提示,引导从大型语料库或数据库中检索相关信息,然后利用这些信息生成响应或动作。
工作原理:
- 构建提示:根据任务或用户输入设计结构化良好的提示或查询。
- 检索信息:使用提示在预先存在的知识库或数据集中搜索相关数据。
- 生成响应:结合检索到的信息和生成式 AI 模型,产生全面且连贯的回答。
旅行代理中的示例:
- 用户输入:“我想参观巴黎的博物馆。”
- 提示:“寻找巴黎的顶级博物馆。”
- 检索信息:关于卢浮宫、奥赛博物馆等的详情。
- 生成响应:“这里是巴黎的一些顶级博物馆:卢浮宫、奥赛博物馆和蓬皮杜中心。”
作为工具的 RAG
什么是?
- 作为工具,RAG 是一个集成系统,自动化检索和生成过程,让开发者无需手动为每个查询撰写提示即可实现复杂的 AI 功能。
工作原理:
- 集成:将 RAG 嵌入 AI 代理架构,自动管理检索和生成任务。
- 自动化:工具负责从接收用户输入到生成最终响应的全部过程,无需显式为每一步设计提示。
- 效率:通过简化检索和生成流程,提高代理性能,实现更快更准确的响应。
旅行代理中的示例:
- 用户输入:“我想参观巴黎的博物馆。”
- RAG 工具:自动检索博物馆信息,并生成响应。
- 生成响应:“这里是巴黎的一些顶级博物馆:卢浮宫、奥赛博物馆和蓬皮杜中心。”
对比
| 方面 | 提示技术 | 工具 |
|---|---|---|
| 手动 vs 自动 | 每个查询手动构造提示。 | 自动化处理检索和生成。 |
| 控制能力 | 对检索过程有更多控制。 | 简化并自动化检索和生成。 |
| 灵活性 | 允许根据特定需求自定义提示。 | 更适合大规模实施。 |
| 复杂度 | 需要设计和调优提示。 | 更易于集成到 AI 代理架构中。 |
实践示例
提示技术示例:
def search_museums_in_paris():
prompt = "Find top museums in Paris"
search_results = search_web(prompt)
return search_results
museums = search_museums_in_paris()
print("Top Museums in Paris:", museums)
工具示例:
class Travel_Agent:
def __init__(self):
self.rag_tool = RAGTool()
def get_museums_in_paris(self):
user_input = "I want to visit museums in Paris."
response = self.rag_tool.retrieve_and_generate(user_input)
return response
travel_agent = Travel_Agent()
museums = travel_agent.get_museums_in_paris()
print("Top Museums in Paris:", museums)
评估相关性
评估相关性是 AI 代理性能的关键环节。它确保代理检索和生成的信息适当、准确且对用户有用。下面探讨 AI 代理中如何评估相关性,包括实践示例和技术。
评估相关性的关键概念
- 上下文感知:
- 代理必须理解用户查询的上下文,以检索和生成相关信息。
- 示例:当用户查询“巴黎最佳餐厅”时,代理应考虑用户偏好,比如料理类型和预算。
- 准确性:
- 代理提供的信息应事实准确且最新。
- 示例:推荐当前营业且评价良好的餐厅,而非过时或已关闭的选项。
- 用户意图:
- 代理需推断用户查询背后的意图,提供最相关信息。
- 示例:用户问“经济实惠的酒店”,代理应优先推荐价格合理的选项。
- 反馈循环:
- 持续收集并分析用户反馈,有助于代理优化其相关性评估过程。
- 示例:结合用户对以往推荐的评分与反馈,改进未来响应。
评估相关性的实践方法
- 相关性评分:
- 根据检索项与用户查询及偏好的匹配程度,为每项分配相关性分数。
-
示例:
def relevance_score(item, query): score = 0 if item['category'] in query['interests']: score += 1 if item['price'] <= query['budget']: score += 1 if item['location'] == query['destination']: score += 1 return score
- 过滤与排序:
- 过滤掉无关项,根据相关性分数对剩余项排序。
-
示例:
def filter_and_rank(items, query): ranked_items = sorted(items, key=lambda item: relevance_score(item, query), reverse=True) return ranked_items[:10] # 返回前10个相关项目
- 自然语言处理(NLP):
- 使用 NLP 技术理解用户查询,检索相关信息。
-
示例:
def process_query(query): # 使用自然语言处理从用户的查询中提取关键信息 processed_query = nlp(query) return processed_query
- 用户反馈整合:
- 收集用户对推荐的反馈,调整后续的相关性评估。
-
示例:
def adjust_based_on_feedback(feedback, items): for item in items: if item['name'] in feedback['liked']: item['relevance'] += 1 if item['name'] in feedback['disliked']: item['relevance'] -= 1 return items
示例:旅行代理中评估相关性
下面是旅行代理如何评估旅行推荐相关性的实践示例:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
ranked_hotels = self.filter_and_rank(hotels, self.user_preferences)
itinerary = create_itinerary(flights, ranked_hotels, attractions)
return itinerary
def filter_and_rank(self, items, query):
ranked_items = sorted(items, key=lambda item: self.relevance_score(item, query), reverse=True)
return ranked_items[:10] # 返回前10个相关项目
def relevance_score(self, item, query):
score = 0
if item['category'] in query['interests']:
score += 1
if item['price'] <= query['budget']:
score += 1
if item['location'] == query['destination']:
score += 1
return score
def adjust_based_on_feedback(self, feedback, items):
for item in items:
if item['name'] in feedback['liked']:
item['relevance'] += 1
if item['name'] in feedback['disliked']:
item['relevance'] -= 1
return items
# 示例用法
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_items = travel_agent.adjust_based_on_feedback(feedback, itinerary['hotels'])
print("Updated Itinerary with Feedback:", updated_items)
目标导向搜索
目标导向搜索涉及理解和解析用户查询背后的目的或目标,以检索和生成最相关且有用的信息。这一方法超越了简单关键词匹配,更注重把握用户的实际需求和上下文。
目标导向搜索的关键概念
- 理解用户意图:
- 用户意图通常分为三类:信息型、导航型和事务型。
- 信息型意图:用户寻求某个主题的信息(如“巴黎最佳博物馆有哪些?”)。
- 导航型意图:用户想访问特定网站或页面(如“卢浮宫官方网站”)。
- 事务型意图:用户希望完成某种事务,如订机票或购物(如“预订去巴黎的机票”)。
- 用户意图通常分为三类:信息型、导航型和事务型。
- 上下文感知:
- 分析用户查询的上下文,有助于准确识别意图,包括考虑之前交互、用户偏好和当前查询的具体细节。
- 自然语言处理(NLP):
- 利用 NLP 技术理解和解析用户的自然语言查询,包括实体识别、情感分析和查询解析等任务。
- 个性化:
- 基于用户历史、偏好和反馈个性化搜索结果,提高信息相关性。
实践示例:旅行代理中的目标导向搜索
以旅行代理为例,看看如何实现目标导向搜索。
-
收集用户偏好
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
理解用户意图
def identify_intent(query): if "book" in query or "purchase" in query: return "transactional" elif "website" in query or "official" in query: return "navigational" else: return "informational" - 上下文感知
def analyze_context(query, user_history): # 将当前查询与用户历史结合以了解上下文 context = { "current_query": query, "user_history": user_history } return context -
搜索和个性化结果
def search_with_intent(query, preferences, user_history): intent = identify_intent(query) context = analyze_context(query, user_history) if intent == "informational": search_results = search_information(query, preferences) elif intent == "navigational": search_results = search_navigation(query) elif intent == "transactional": search_results = search_transaction(query, preferences) personalized_results = personalize_results(search_results, user_history) return personalized_results def search_information(query, preferences): # 信息性意图的示例搜索逻辑 results = search_web(f"best {preferences['interests']} in {preferences['destination']}") return results def search_navigation(query): # 导航性意图的示例搜索逻辑 results = search_web(query) return results def search_transaction(query, preferences): # 交易性意图的示例搜索逻辑 results = search_web(f"book {query} to {preferences['destination']}") return results def personalize_results(results, user_history): # 个性化示例逻辑 personalized = [result for result in results if result not in user_history] return personalized[:10] # 返回前10个个性化结果 -
示例用法
travel_agent = Travel_Agent() preferences = { "destination": "Paris", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) user_history = ["Louvre Museum website", "Book flight to Paris"] query = "best museums in Paris" results = search_with_intent(query, preferences, user_history) print("Search Results:", results)
4. 作为工具生成代码
代码生成代理使用 AI 模型编写和执行代码,解决复杂问题并自动化任务。
代码生成代理
代码生成代理使用生成式 AI 模型编写和执行代码。这些代理可以通过生成并运行各种编程语言的代码来解决复杂问题、自动化任务并提供有价值的见解。
实际应用
- 自动代码生成:为特定任务生成代码片段,如数据分析、网络爬取或机器学习。
- SQL 作为 RAG:使用 SQL 查询从数据库中检索和操作数据。
- 问题解决:创建并执行代码解决特定问题,如优化算法或分析数据。
示例:用于数据分析的代码生成代理
假设你正在设计一个代码生成代理。它的工作流程可能是:
- 任务:分析数据集以识别趋势和模式。
- 步骤:
- 将数据集加载到数据分析工具中。
- 生成 SQL 查询以过滤和聚合数据。
- 执行查询并获取结果。
- 使用结果生成可视化和见解。
- 所需资源:数据集访问权限、数据分析工具和 SQL 能力。
- 经验:利用过去的分析结果提升未来分析的准确性和相关性。
示例:旅游代理的代码生成代理
在此示例中,我们设计一个代码生成代理——旅游代理,帮助用户规划旅行,通过生成和执行代码来完成任务。该代理可以处理诸如获取旅行选项、筛选结果和使用生成式 AI 编制行程等任务。
代码生成代理概述
- 收集用户偏好:收集用户输入,如目的地、旅行日期、预算和兴趣。
- 生成获取数据的代码:生成代码片段以获取航班、酒店和景点信息。
- 执行生成的代码:运行生成的代码以获取实时信息。
- 生成行程:将获取的数据编译成个性化旅行计划。
- 基于反馈调整:接收用户反馈,并在必要时重新生成代码以优化结果。
逐步实现
-
收集用户偏好
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
生成获取数据的代码
def generate_code_to_fetch_data(preferences): # 示例:生成根据用户偏好搜索航班的代码 code = f""" def search_flights(): import requests response = requests.get('https://api.example.com/flights', params={preferences}) return response.json() """ return code def generate_code_to_fetch_hotels(preferences): # 示例:生成搜索酒店的代码 code = f""" def search_hotels(): import requests response = requests.get('https://api.example.com/hotels', params={preferences}) return response.json() """ return code -
执行生成的代码
def execute_code(code): # 使用 exec 执行生成的代码 exec(code) result = locals() return result travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) flight_code = generate_code_to_fetch_data(preferences) hotel_code = generate_code_to_fetch_hotels(preferences) flights = execute_code(flight_code) hotels = execute_code(hotel_code) print("Flight Options:", flights) print("Hotel Options:", hotels) -
生成行程
def generate_itinerary(flights, hotels, attractions): itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary attractions = search_attractions(preferences) itinerary = generate_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary) -
基于反馈调整
def adjust_based_on_feedback(feedback, preferences): # 根据用户反馈调整偏好设置 if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]} updated_preferences = adjust_based_on_feedback(feedback, preferences) # 使用更新后的偏好设置重新生成并执行代码 updated_flight_code = generate_code_to_fetch_data(updated_preferences) updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences) updated_flights = execute_code(updated_flight_code) updated_hotels = execute_code(updated_hotel_code) updated_itinerary = generate_itinerary(updated_flights, updated_hotels, attractions) print("Updated Itinerary:", updated_itinerary)
利用环境感知和推理
基于表的架构确实可以通过利用环境感知和推理增强查询生成过程。
以下是如何实现的示例:
- 理解架构:系统将理解表的架构并利用这些信息来指导查询生成。
- 基于反馈调整:系统会基于反馈调整用户偏好,并推理哪些架构字段需要更新。
- 生成并执行查询:系统基于新的偏好生成并执行查询以获取更新的航班和酒店数据。
这里是一个包含这些概念的 Python 代码示例:
def adjust_based_on_feedback(feedback, preferences, schema):
# 根据用户反馈调整偏好
if "liked" in feedback:
preferences["favorites"] = feedback["liked"]
if "disliked" in feedback:
preferences["avoid"] = feedback["disliked"]
# 基于架构推理以调整其他相关偏好
for field in schema:
if field in preferences:
preferences[field] = adjust_based_on_environment(feedback, field, schema)
return preferences
def adjust_based_on_environment(feedback, field, schema):
# 基于架构和反馈的自定义逻辑调整偏好
if field in feedback["liked"]:
return schema[field]["positive_adjustment"]
elif field in feedback["disliked"]:
return schema[field]["negative_adjustment"]
return schema[field]["default"]
def generate_code_to_fetch_data(preferences):
# 生成代码以根据更新的偏好获取航班数据
return f"fetch_flights(preferences={preferences})"
def generate_code_to_fetch_hotels(preferences):
# 生成代码以根据更新的偏好获取酒店数据
return f"fetch_hotels(preferences={preferences})"
def execute_code(code):
# 模拟代码执行并返回模拟数据
return {"data": f"Executed: {code}"}
def generate_itinerary(flights, hotels, attractions):
# 根据航班、酒店和景点生成行程
return {"flights": flights, "hotels": hotels, "attractions": attractions}
# 示例架构
schema = {
"favorites": {"positive_adjustment": "increase", "negative_adjustment": "decrease", "default": "neutral"},
"avoid": {"positive_adjustment": "decrease", "negative_adjustment": "increase", "default": "neutral"}
}
# 示例用法
preferences = {"favorites": "sightseeing", "avoid": "crowded places"}
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_preferences = adjust_based_on_feedback(feedback, preferences, schema)
# 使用更新的偏好重新生成并执行代码
updated_flight_code = generate_code_to_fetch_data(updated_preferences)
updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences)
updated_flights = execute_code(updated_flight_code)
updated_hotels = execute_code(updated_hotel_code)
updated_itinerary = generate_itinerary(updated_flights, updated_hotels, feedback["liked"])
print("Updated Itinerary:", updated_itinerary)
说明 - 基于反馈的预订
- 架构感知:
schema字典定义了如何根据反馈调整偏好。它包括如favorites和avoid等字段及对应的调整。 - 调整偏好(
adjust_based_on_feedback方法):该方法根据用户反馈和架构调整偏好。 - 基于环境的调整(
adjust_based_on_environment方法):此方法根据架构和反馈定制调整。 - 生成并执行查询:系统生成代码以获取基于调整后偏好的航班和酒店数据,并模拟这些查询的执行。
- 生成行程:系统基于新的航班、酒店和景点数据创建更新的行程。
通过使系统具备环境感知能力并基于架构进行推理,它可以生成更准确和相关的查询,从而提供更好的旅行推荐和更个性化的用户体验。
使用 SQL 作为检索增强生成 (RAG) 技术
SQL(结构化查询语言)是与数据库交互的强大工具。作为检索增强生成 (RAG) 方法的一部分,SQL 可以从数据库中检索相关数据,为 AI 代理生成响应或行为提供信息。下面探讨 SQL 在旅行代理中的 RAG 技术应用。
关键概念
- 数据库交互:
- 使用 SQL 查询数据库,检索相关信息并操作数据。
- 示例:从旅行数据库中获取航班详情、酒店信息和景点。
- 与 RAG 的集成:
- 根据用户输入和偏好生成 SQL 查询。
- 检索的数据用来生成个性化推荐或行为。
- 动态查询生成:
- AI 代理基于上下文和用户需求生成动态 SQL 查询。
- 示例:根据预算、日期和兴趣定制 SQL 查询筛选结果。
应用
- 自动代码生成:生成针对特定任务的代码片段。
- SQL 作为 RAG:使用 SQL 查询操作数据。
- 问题解决:创建并执行代码解决问题。
示例: 一个数据分析代理:
- 任务:分析数据集发现趋势。
- 步骤:
- 加载数据集。
- 生成 SQL 查询筛选数据。
- 执行查询并获取结果。
- 生成可视化和见解。
- 资源:数据集访问权限,SQL 能力。
- 经验:利用过去结果提高未来分析质量。
实践示例:在旅游代理中使用 SQL
-
收集用户偏好
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
生成 SQL 查询
def generate_sql_query(table, preferences): query = f"SELECT * FROM {table} WHERE " conditions = [] for key, value in preferences.items(): conditions.append(f"{key}='{value}'") query += " AND ".join(conditions) return query -
执行 SQL 查询
import sqlite3 def execute_sql_query(query, database="travel.db"): connection = sqlite3.connect(database) cursor = connection.cursor() cursor.execute(query) results = cursor.fetchall() connection.close() return results -
生成推荐
def generate_recommendations(preferences): flight_query = generate_sql_query("flights", preferences) hotel_query = generate_sql_query("hotels", preferences) attraction_query = generate_sql_query("attractions", preferences) flights = execute_sql_query(flight_query) hotels = execute_sql_query(hotel_query) attractions = execute_sql_query(attraction_query) itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) itinerary = generate_recommendations(preferences) print("Suggested Itinerary:", itinerary)
示例 SQL 查询
-
航班查询
SELECT * FROM flights WHERE destination='Paris' AND dates='2025-04-01 to 2025-04-10' AND budget='moderate'; -
酒店查询
SELECT * FROM hotels WHERE destination='Paris' AND budget='moderate'; -
景点查询
SELECT * FROM attractions WHERE destination='Paris' AND interests='museums, cuisine';
通过将 SQL 作为检索增强生成 (RAG) 技术的一部分,像旅游代理这样的 AI 代理可以动态检索并利用相关数据,提供准确且个性化的推荐。
元认知示例
为了演示元认知的实现,我们创建一个简单代理,在解决问题时反思其决策过程。在这个例子中,我们构建一个系统,使代理尝试优化酒店选择,但随后评估自己的推理,并在做出错误或次优选择时调整策略。
我们通过一个基本示例来模拟,代理根据价格和质量组合选择酒店,但会“反思”其决策并进行相应调整。
如何体现元认知:
- 初始决策:代理选择最便宜的酒店,未考虑质量影响。
- 反思与评估:初始选择后,代理根据用户反馈检查酒店是否为“不良”选择。如果发现酒店质量过低,代理将反思其推理。
- 调整策略:代理根据反思调整策略,从“最便宜”切换为“最高质量”,从而提升未来的决策过程。
示例代码如下:
class HotelRecommendationAgent:
def __init__(self):
self.previous_choices = [] # 存储之前选择的酒店
self.corrected_choices = [] # 存储修正后的选择
self.recommendation_strategies = ['cheapest', 'highest_quality'] # 可用的策略
def recommend_hotel(self, hotels, strategy):
"""
Recommend a hotel based on the chosen strategy.
The strategy can either be 'cheapest' or 'highest_quality'.
"""
if strategy == 'cheapest':
recommended = min(hotels, key=lambda x: x['price'])
elif strategy == 'highest_quality':
recommended = max(hotels, key=lambda x: x['quality'])
else:
recommended = None
self.previous_choices.append((strategy, recommended))
return recommended
def reflect_on_choice(self):
"""
Reflect on the last choice made and decide if the agent should adjust its strategy.
The agent considers if the previous choice led to a poor outcome.
"""
if not self.previous_choices:
return "No choices made yet."
last_choice_strategy, last_choice = self.previous_choices[-1]
# 假设我们有一些用户反馈,告诉我们上次选择是否合适
user_feedback = self.get_user_feedback(last_choice)
if user_feedback == "bad":
# 如果上次选择不满意,则调整策略
new_strategy = 'highest_quality' if last_choice_strategy == 'cheapest' else 'cheapest'
self.corrected_choices.append((new_strategy, last_choice))
return f"Reflecting on choice. Adjusting strategy to {new_strategy}."
else:
return "The choice was good. No need to adjust."
def get_user_feedback(self, hotel):
"""
Simulate user feedback based on hotel attributes.
For simplicity, assume if the hotel is too cheap, the feedback is "bad".
If the hotel has quality less than 7, feedback is "bad".
"""
if hotel['price'] < 100 or hotel['quality'] < 7:
return "bad"
return "good"
# 模拟一列酒店(价格和质量)
hotels = [
{'name': 'Budget Inn', 'price': 80, 'quality': 6},
{'name': 'Comfort Suites', 'price': 120, 'quality': 8},
{'name': 'Luxury Stay', 'price': 200, 'quality': 9}
]
# 创建一个代理
agent = HotelRecommendationAgent()
# 第一步:代理使用“最便宜”策略推荐酒店
recommended_hotel = agent.recommend_hotel(hotels, 'cheapest')
print(f"Recommended hotel (cheapest): {recommended_hotel['name']}")
# 第二步:代理反思选择,并在必要时调整策略
reflection_result = agent.reflect_on_choice()
print(reflection_result)
# 第三步:代理再次推荐,这次使用调整后的策略
adjusted_recommendation = agent.recommend_hotel(hotels, 'highest_quality')
print(f"Adjusted hotel recommendation (highest_quality): {adjusted_recommendation['name']}")
代理的元认知能力
关键在于代理具备:
- 评估之前选择和决策过程的能力。
- 基于反思调整策略,即元认知的实际运用。
这是一种简单的元认知形式,系统能够基于内部反馈调整推理过程。
结论
元认知是一个强大的工具,能显著增强 AI 代理的能力。通过整合元认知过程,可以设计出更智能、更适应性强且更高效的代理。使用附加资源进一步探索 AI 代理中引人入胜的元认知世界。
有关元认知设计模式的更多问题?
加入 Microsoft Foundry Discord,与其他学习者交流,参加办公时间并获得 AI 代理相关问题的解答。
上一课
下一课
免责声明:
本文档使用 AI 翻译服务 Co-op Translator 进行翻译。虽然我们努力确保翻译的准确性,但请注意,自动翻译可能包含错误或不准确之处。原始语言版本的文档应被视为权威来源。对于重要信息,建议使用专业人工翻译。我们不对因使用本翻译而产生的任何误解或误释承担责任。