08.2 半线性激活函数
8.2 半线性激活函数⚓︎
又可以叫非饱和型激活函数。
8.2.1 ReLU函数⚓︎
Rectified Linear Unit,修正线性单元,线性整流函数,斜坡函数。
公式⚓︎
导数⚓︎
值域⚓︎
- 输入值域:(-\infty, \infty)
- 输出值域:(0,\infty)
- 导数值域:\\{0,1\\}
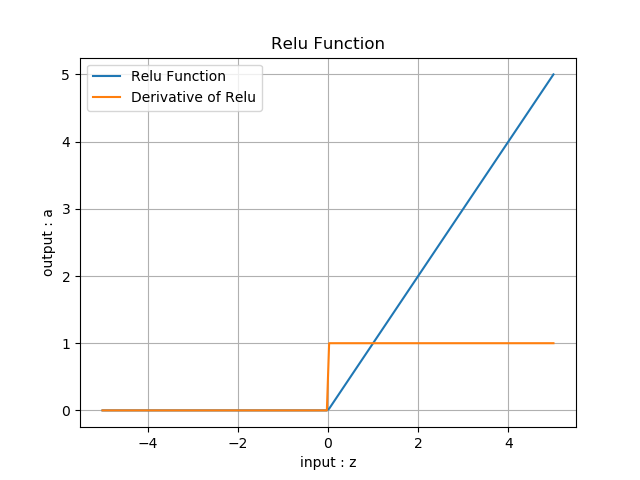
图8-6 线性整流函数ReLU
仿生学原理⚓︎
相关大脑方面的研究表明生物神经元的信息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%~4%的神经元处于活跃状态。使用线性修正以及正则化可以对机器神经网络中神经元的活跃度(即输出为正值)进行调试;相比之下,Sigmoid函数在输入为0时输出为0.5,即已经是半饱和的稳定状态,不够符合实际生物学对模拟神经网络的期望。不过需要指出的是,一般情况下,在一个使用修正线性单元(即线性整流)的神经网络中大概有50%的神经元处于激活态。
优点⚓︎
- 反向导数恒等于1,更加有效率的反向传播梯度值,收敛速度快;
- 避免梯度消失问题;
- 计算简单,速度快;
- 活跃度的分散性使得神经网络的整体计算成本下降。
缺点⚓︎
无界。
梯度很大的时候可能导致的神经元“死”掉。
这个死掉的原因是什么呢?是因为很大的梯度导致更新之后的网络传递过来的输入是小于零的,从而导致ReLU的输出是0,计算所得的梯度是零,然后对应的神经元不更新,从而使ReLU输出恒为零,对应的神经元恒定不更新,等于这个ReLU失去了作为一个激活函数的作用。问题的关键点就在于输入小于零时,ReLU回传的梯度是零,从而导致了后面的不更新。在学习率设置不恰当的情况下,很有可能网络中大部分神经元“死”掉,也就是说不起作用了。
用和Sigmoid函数那里更新相似的算法步骤和参数,来模拟一下ReLU的梯度下降次数,也就是学习率\eta = 0.2,希望函数值从0.9衰减到0.5,这样需要多少步呢?
由于ReLU的导数为1,所以:
也就是说,同样的学习速率,ReLU函数只需要两步就可以做到Sigmoid需要67步才能达到的数值!
8.2.2 Leaky ReLU函数⚓︎
LReLU,带泄露的线性整流函数。
公式⚓︎
导数⚓︎
值域⚓︎
输入值域:(-\infty, \infty)
输出值域:(-\infty,\infty)
导数值域:\\{\alpha,1\\}
函数图像⚓︎
函数图像如图8-7所示。
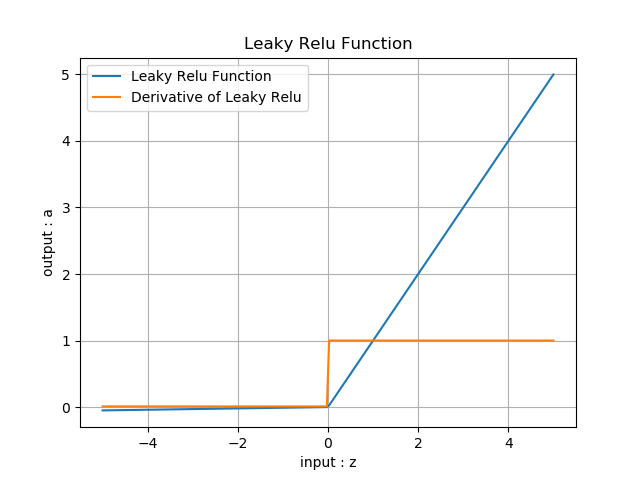
图8-7 LeakyReLU的函数图像
优点⚓︎
继承了ReLU函数的优点。
Leaky ReLU同样有收敛快速和运算复杂度低的优点,而且由于给了z<0时一个比较小的梯度\alpha,使得z<0时依旧可以进行梯度传递和更新,可以在一定程度上避免神经元“死”掉的问题。
8.2.3 Softplus函数⚓︎
公式⚓︎
导数⚓︎
⚓︎
输入值域:(-\infty, \infty)
输出值域:(0,\infty)
导数值域:(0,1)
函数图像⚓︎
Softplus的函数图像如图8-8所示。
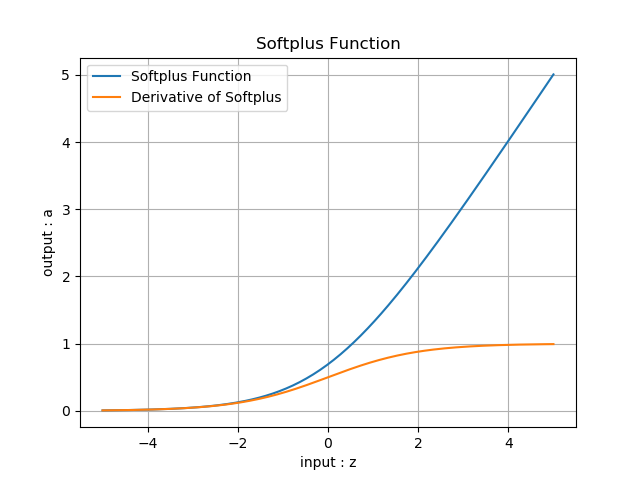
图8-8 Softplus的函数图像
8.2.4 ELU函数⚓︎
公式⚓︎
导数⚓︎
值域⚓︎
输入值域:(-\infty, \infty)
输出值域:(-\alpha,\infty)
导数值域:(0,1]
函数图像⚓︎
ELU的函数图像如图8-9所示。
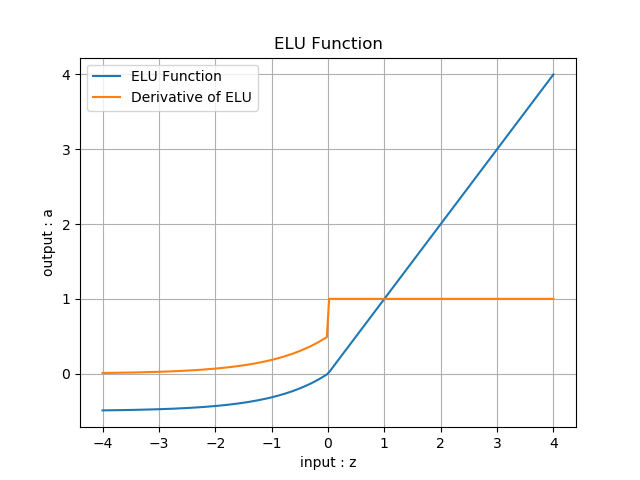
图8-9 ELU的函数图像
代码位置⚓︎
ch08, Level2