09.3 验证与测试
9.3 验证与测试⚓︎
9.3.1 基本概念⚓︎
训练集⚓︎
Training Set,用于模型训练的数据样本。
验证集⚓︎
Validation Set,或者叫做Dev Set,是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
在神经网络中,验证数据集用于:
- 寻找最优的网络深度
- 或者决定反向传播算法的停止点
- 或者在神经网络中选择隐藏层神经元的数量
- 在普通的机器学习中常用的交叉验证(Cross Validation)就是把训练数据集本身再细分成不同的验证数据集去训练模型。
测试集⚓︎
Test Set,用来评估最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
三者之间的关系如图9-5所示。
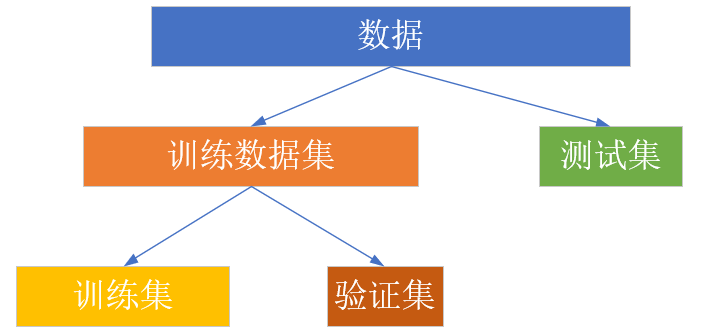
图9-5 训练集、验证集、测试集的关系
一个形象的比喻:
-
训练集:课本,学生根据课本里的内容来掌握知识。训练集直接参与了模型调参的过程,显然不能用来反映模型真实的能力。即不能直接拿课本上的问题来考试,防止死记硬背课本的学生拥有最好的成绩,即防止过拟合。
-
验证集:作业,通过作业可以知道不同学生学习情况、进步的速度快慢。验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型(刷题库的学生不能算是学习好的学生)。
-
测试集:考试,考的题是平常都没有见过,考察学生举一反三的能力。所以要通过最终的考试(测试集)来考察一个学型(模生)真正的能力(期末考试)。
考试题是学生们平时见不到的,也就是说在模型训练时看不到测试集。
9.3.2 交叉验证⚓︎
传统的机器学习⚓︎
在传统的机器学习中,我们经常用交叉验证的方法,比如把数据分成10份,V_1\sim V_{10},其中 V_1 \sim V_9 用来训练,V_{10} 用来验证。然后用 V_2\sim V_{10} 做训练,V_1 做验证……如此我们可以做10次训练和验证,大大增加了模型的可靠性。
这样的话,验证集也可以做训练,训练集数据也可以做验证,当样本很少时,这个方法很有用。
神经网络/深度学习⚓︎
那么深度学习中的用法是什么呢?
比如在神经网络中,训练时到底迭代多少次停止呢?或者我们设置学习率为多少合适呢?或者用几个中间层,以及每个中间层用几个神经元呢?如何正则化?这些都是超参数设置,都可以用验证集来解决。
在咱们前面的学习中,一般使用损失函数值小于门限值做为迭代终止条件,因为通过前期的训练,笔者预先知道了这个门限值可以满足训练精度。但对于实际应用中的问题,没有先验的门限值可以参考,如何设定终止条件?此时,我们可以用验证集来验证一下准确率,假设只有90%的准确率,可能是局部最优解。这样我们可以继续迭代,寻找全局最优解。
举个例子:一个BP神经网络,我们无法确定隐层的神经元数目,因为没有理论支持。此时可以按图9-6的示意图这样做。

图9-6 交叉训练的数据配置方式
- 随机将训练数据分成K等份(通常建议 K=10),得到D_0,D_1,D_9;
- 对于一个模型M,选择 D_9 为验证集,其它为训练集,训练若干轮,用 D_9 验证,得到误差 E。再训练,再用 D_9 测试,如此N次。对N次的误差做平均,得到平均误差;
- 换一个不同参数的模型的组合,比如神经元数量,或者网络层数,激活函数,重复2,但是这次用 D_8 去得到平均误差;
- 重复步骤2,一共验证10组组合;
- 最后选择具有最小平均误差的模型结构,用所有的 D_0 \sim D_9 再次训练,成为最终模型,不用再验证;
- 用测试集测试。
9.3.3 留出法 Hold out⚓︎
使用交叉验证的方法虽然比较保险,但是非常耗时,尤其是在大数据量时,训练出一个模型都要很长时间,没有可能去训练出10个模型再去比较。
在深度学习中,有另外一种方法使用验证集,称为留出法。亦即从训练数据中保留出验证样本集,主要用于解决过拟合情况,这部分数据不用于训练。如果训练数据的准确度持续增长,但是验证数据的准确度保持不变或者反而下降,说明神经网络亦即过拟合了,此时需要停止训练,用测试集做最终测试。
所以,训练步骤的伪代码如下:
for each epoch
shuffle
for each iteraion
获得当前小批量数据
前向计算
反向传播
更新梯度
if is checkpoint
用当前小批量数据计算训练集的loss值和accuracy值并记录
计算验证集的loss值和accuracy值并记录
如果loss值不再下降,停止训练
如果accuracy值满足要求,停止训练
end if
end for
end for
从本章开始,我们将使用新的DataReader类来管理训练/测试数据,与前面的SimpleDataReader类相比,这个类有以下几个不同之处:
- 要求既有训练集,也有测试集
- 提供
GenerateValidationSet()方法,可以从训练集中产生验证集
以上两个条件保证了我们在以后的训练中,可以使用本节中所描述的留出法,来监控整个训练过程。
关于三者的比例关系,在传统的机器学习中,三者可以是6:2:2。在深度学习中,一般要求样本数据量很大,所以可以给训练集更多的数据,比如8:1:1。
如果有些数据集已经给了你训练集和测试集,那就不关心其比例问题了,只需要从训练集中留出10%左右的验证集就可以了。
9.3.4 代码实现⚓︎
定义DataReader类如下:
class DataReader(object):
def __init__(self, train_file, test_file):
self.train_file_name = train_file
self.test_file_name = test_file
self.num_train = 0 # num of training examples
self.num_test = 0 # num of test examples
self.num_validation = 0 # num of validation examples
self.num_feature = 0 # num of features
self.num_category = 0 # num of categories
self.XTrain = None # training feature set
self.YTrain = None # training label set
self.XTest = None # test feature set
self.YTest = None # test label set
self.XTrainRaw = None # training feature set before normalization
self.YTrainRaw = None # training label set before normalization
self.XTestRaw = None # test feature set before normalization
self.YTestRaw = None # test label set before normalization
self.XVld = None # validation feature set
self.YVld = None # validation lable set
命名规则:
- 以
num_开头的表示一个整数,后面跟着数据集的各种属性的名称,如训练集(num_train)、测试集(num_test)、验证集(num_validation)、特征值数量(num_feature)、分类数量(num_category); X表示样本特征值数据,Y表示样本标签值数据;Raw表示没有经过归一化的原始数据。
得到训练集和测试集⚓︎
一般的数据集都有训练集和测试集,如果没有,需要从一个单一数据集中,随机抽取出一小部分作为测试集,剩下的一大部分作为训练集,一旦测试集确定后,就不要再更改。然后在训练过程中,从训练集中再抽取一小部分作为验证集。
读取数据⚓︎
def ReadData(self):
train_file = Path(self.train_file_name)
if train_file.exists():
...
test_file = Path(self.test_file_name)
if test_file.exists():
...
在读入原始数据后,数据存放在XTrainRaw、YTrainRaw、XTestRaw、YTestRaw中。由于有些数据不需要做归一化处理,所以,在读入数据集后,令:XTrain=XTrainRaw、YTrain=YTrainRaw、XTest=XTestRaw、YTest=YTestRaw,如此一来,就可以直接使用XTrain、YTrain、XTest、YTest做训练和测试了,避免不做归一化时上述4个变量为空。
特征值归一化⚓︎
def NormalizeX(self):
x_merge = np.vstack((self.XTrainRaw, self.XTestRaw))
x_merge_norm = self.__NormalizeX(x_merge)
train_count = self.XTrainRaw.shape[0]
self.XTrain = x_merge_norm[0:train_count,:]
self.XTest = x_merge_norm[train_count:,:]
如果需要归一化处理,则XTrainRaw -> XTrain、YTrainRaw -> YTrain、XTestRaw -> XTest、YTestRaw -> YTest。注意需要把Train、Test同时归一化,如上面代码中,先把XTrainRaw和XTestRaw合并,一起做归一化,然后再拆开,这样可以保证二者的值域相同。
比如,假设XTrainRaw中的特征值只包含1、2、3三种值,在对其归一化时,1、2、3会变成0、0.5、1;而XTestRaw中的特征值只包含2、3、4三种值,在对其归一化时,2、3、4会变成0、0.5、1。这就造成了0、0.5、1这三个值的含义在不同数据集中不一样。
把二者merge后,就包含了1、2、3、4四种值,再做归一化,会变成0、0.333、0.666、1,在训练和测试时,就会使用相同的归一化值。
标签值归一化⚓︎
根据不同的网络类型,标签值的归一化方法也不一样。
def NormalizeY(self, nettype, base=0):
if nettype == NetType.Fitting:
...
elif nettype == NetType.BinaryClassifier:
...
elif nettype == NetType.MultipleClassifier:
...
- 如果是
Fitting任务,即线性回归、非线性回归,对标签值使用普通的归一化方法,把所有的值映射到[0,1]之间 - 如果是
BinaryClassifier,即二分类任务,把标签值变成0或者1。base参数是指原始数据中负类的标签值。比如,原始数据的两个类别标签值是1、2,则base=1,把1、2变成0、1 - 如果是
MultipleClassifier,即多分类任务,把标签值变成One-Hot编码。
生成验证集⚓︎
def GenerateValidationSet(self, k = 10):
self.num_validation = (int)(self.num_train / k)
self.num_train = self.num_train - self.num_validation
# validation set
self.XVld = self.XTrain[0:self.num_validation]
self.YVld = self.YTrain[0:self.num_validation]
# train set
self.XTrain = self.XTrain[self.num_validation:]
self.YTrain = self.YTrain[self.num_validation:]
验证集是从归一化好的训练集中抽取出来的。上述代码假设XTrain已经做过归一化,并且样本是无序的。如果样本是有序的,则需要先打乱。
获得批量样本⚓︎
def GetBatchTrainSamples(self, batch_size, iteration):
start = iteration * batch_size
end = start + batch_size
batch_X = self.XTrain[start:end,:]
batch_Y = self.YTrain[start:end,:]
return batch_X, batch_Y
batch_size和当前批次iteration,就可以从已经打乱过的样本中获得当前批次的数据,在一个epoch中根据iteration的递增调用此函数。
样本打乱⚓︎
def Shuffle(self):
seed = np.random.randint(0,100)
np.random.seed(seed)
XP = np.random.permutation(self.XTrain)
np.random.seed(seed)
YP = np.random.permutation(self.YTrain)
self.XTrain = XP
self.YTrain = YP
样本打乱操作只涉及到训练集,在每个epoch开始时调用此方法。打乱时,要注意特征值X和标签值Y是分开存放的,所以要使用相同的seed来打乱,保证打乱顺序后的特征值和标签值还是一一对应的。