09.4 神经网络非线性回归的实现
9.4 双层神经网络实现非线性回归⚓︎
9.4.1 万能近似定理⚓︎
万能近似定理(universal approximation theorem) ^{[1]},是深度学习最根本的理论依据。它证明了在给定网络具有足够多的隐藏单元的条件下,配备一个线性输出层和一个带有任何“挤压”性质的激活函数(如Sigmoid激活函数)的隐藏层的前馈神经网络,能够以任何想要的误差量近似任何从一个有限维度的空间映射到另一个有限维度空间的Borel可测的函数。
前馈网络的导数也可以以任意好地程度近似函数的导数。
万能近似定理其实说明了理论上神经网络可以近似任何函数。但实践上我们不能保证学习算法一定能学习到目标函数。即使网络可以表示这个函数,学习也可能因为两个不同的原因而失败:
- 用于训练的优化算法可能找不到用于期望函数的参数值;
- 训练算法可能由于过拟合而选择了错误的函数。
根据“没有免费的午餐”定理,说明了没有普遍优越的机器学习算法。前馈网络提供了表示函数的万能系统,在这种意义上,给定一个函数,存在一个前馈网络能够近似该函数。但不存在万能的过程既能够验证训练集上的特殊样本,又能够选择一个函数来扩展到训练集上没有的点。
总之,具有单层的前馈网络足以表示任何函数,但是网络层可能大得不可实现,并且可能无法正确地学习和泛化。在很多情况下,使用更深的模型能够减少表示期望函数所需的单元的数量,并且可以减少泛化误差。
9.4.2 定义神经网络结构⚓︎
本节的目的是要用神经网络完成图9-1和图9-2中的曲线拟合。
根据万能近似定理的要求,我们定义一个两层的神经网络,输入层不算,一个隐藏层,含3个神经元,一个输出层。图9-7显示了此次用到的神经网络结构。
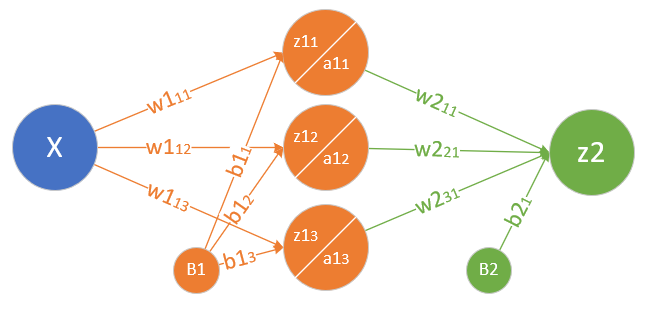
图9-7 单入单出的双层神经网络
为什么用3个神经元呢?这也是笔者经过多次试验的最佳结果。因为输入层只有一个特征值,我们不需要在隐层放很多的神经元,先用3个神经元试验一下。如果不够的话再增加,神经元数量是由超参控制的。
输入层⚓︎
输入层就是一个标量x值,如果是成批输入,则是一个矢量或者矩阵,但是特征值数量总为1,因为只有一个横坐标值做为输入。
权重矩阵W1/B1⚓︎
隐层⚓︎
我们用3个神经元:
权重矩阵W2/B2⚓︎
W2的尺寸是3x1,B2的尺寸是1x1。
输出层⚓︎
由于我们只想完成一个拟合任务,所以输出层只有一个神经元,尺寸为1x1:
9.4.3 前向计算⚓︎
根据图9-7的网络结构,我们可以得到如图9-8的前向计算图。
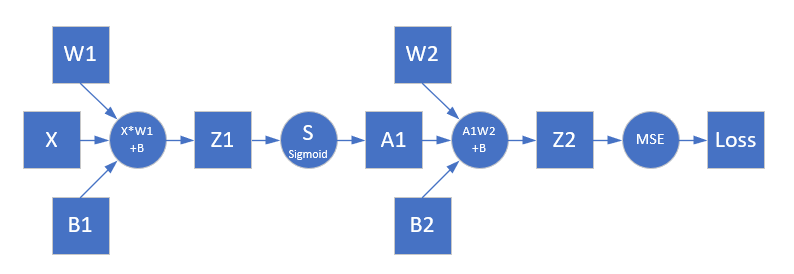
图9-8 前向计算图
隐层⚓︎
- 线性计算
矩阵形式:
- 激活函数
矩阵形式:
输出层⚓︎
由于我们只想完成一个拟合任务,所以输出层只有一个神经元:
损失函数⚓︎
均方误差损失函数:
其中,z2是预测值,y是样本的标签值。
9.4.4 反向传播⚓︎
我们比较一下本章的神经网络和第5章的神经网络的区别,看表9-13。
表9-13 本章中的神经网络与第5章的神经网络的对比
| 第5章的神经网络 | 本章的神经网络 |
|---|---|
 |
|
本章使用了真正的“网络”,而第5章充其量只是一个神经元而已。再看本章的网络的右半部分,从隐层到输出层的结构,和第5章的神经元结构一摸一样,只是输入为3个特征,而第5章的输入为两个特征。比较正向计算公式的话,也可以得到相同的结论。这就意味着反向传播的公式应该也是一样的。
由于我们第一次接触双层神经网络,所以需要推导一下反向传播的各个过程。看一下计算图,然后用链式求导法则反推。
求损失函数对输出层的反向误差⚓︎
根据公式4:
求W2的梯度⚓︎
根据公式3和W2的矩阵形状,把标量对矩阵的求导分解到矩阵中的每一元素:
求B2的梯度⚓︎
与第5章相比,除了把X换成A以外,其它的都一样。对于输出层来说,A就是它的输入,也就相当于是X。
求损失函数对隐层的反向误差⚓︎
下面的内容是双层神经网络独有的内容,也是深度神经网络的基础,请大家仔细阅读体会。我们先看看正向计算和反向计算图,即图9-9。
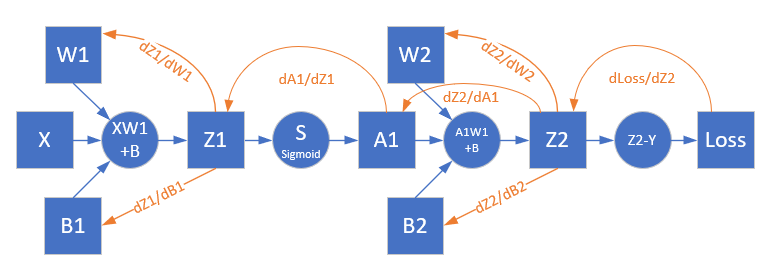
图9-9 正向计算和反向传播路径图
图9-9中:
- 蓝色矩形表示数值或矩阵;
- 蓝色圆形表示计算单元;
- 蓝色的箭头表示正向计算过程;
- 红色的箭头表示反向计算过程。
如果想计算W1和B1的反向误差,必须先得到Z1的反向误差,再向上追溯,可以看到Z1->A1->Z2->Loss这条线,Z1->A1是一个激活函数的运算,比较特殊,所以我们先看Loss->Z->A1如何解决。
根据公式3和A1矩阵的形状:
现在来看激活函数的误差传播问题,由于公式2在计算时,并没有改变矩阵的形状,相当于做了一个矩阵内逐元素的计算,所以它的导数也应该是逐元素的计算,不改变误差矩阵的形状。根据Sigmoid激活函数的导数公式,有:
所以最后到达Z1的误差矩阵是:
有了dZ1后,再向前求W1和B1的误差,就和第5章中一样了,我们直接列在下面:
9.4.5 代码实现⚓︎
主要讲解神经网络NeuralNet2类的代码,其它的类都是辅助类。
前向计算⚓︎
class NeuralNet2(object):
def forward(self, batch_x):
# layer 1
self.Z1 = np.dot(batch_x, self.wb1.W) + self.wb1.B
self.A1 = Sigmoid().forward(self.Z1)
# layer 2
self.Z2 = np.dot(self.A1, self.wb2.W) + self.wb2.B
if self.hp.net_type == NetType.BinaryClassifier:
self.A2 = Logistic().forward(self.Z2)
elif self.hp.net_type == NetType.MultipleClassifier:
self.A2 = Softmax().forward(self.Z2)
else: # NetType.Fitting
self.A2 = self.Z2
#end if
self.output = self.A2
Layer2中考虑了多种网络类型,在此我们暂时只关心NetType.Fitting类型。
反向传播⚓︎
class NeuralNet2(object):
def backward(self, batch_x, batch_y, batch_a):
# 批量下降,需要除以样本数量,否则会造成梯度爆炸
m = batch_x.shape[0]
# 第二层的梯度输入 公式5
dZ2 = self.A2 - batch_y
# 第二层的权重和偏移 公式6
self.wb2.dW = np.dot(self.A1.T, dZ2)/m
# 公式7 对于多样本计算,需要在横轴上做sum,得到平均值
self.wb2.dB = np.sum(dZ2, axis=0, keepdims=True)/m
# 第一层的梯度输入 公式8
d1 = np.dot(dZ2, self.wb2.W.T)
# 第一层的dZ 公式10
dZ1,_ = Sigmoid().backward(None, self.A1, d1)
# 第一层的权重和偏移 公式11
self.wb1.dW = np.dot(batch_x.T, dZ1)/m
# 公式12 对于多样本计算,需要在横轴上做sum,得到平均值
self.wb1.dB = np.sum(dZ1, axis=0, keepdims=True)/m
保存和加载权重矩阵数据⚓︎
在训练结束后,或者每个epoch结束后,都可以选择保存训练好的权重矩阵值,避免每次使用时重复训练浪费时间。
而在初始化完毕神经网络后,可以立刻加载历史权重矩阵数据(前提是本次的神经网络设置与保存时的一致),这样可以在历史数据的基础上继续训练,不会丢失以前的进度。
def SaveResult(self):
self.wb1.SaveResultValue(self.subfolder, "wb1")
self.wb2.SaveResultValue(self.subfolder, "wb2")
def LoadResult(self):
self.wb1.LoadResultValue(self.subfolder, "wb1")
self.wb2.LoadResultValue(self.subfolder, "wb2")
辅助类⚓︎
Activators- 激活函数类,包括Sigmoid/Tanh/Relu等激活函数的实现,以及Losistic/Softmax分类函数的实现DataReader- 数据操作类,读取、归一化、验证集生成、获得指定类型批量数据HyperParameters2- 超参类,各层的神经元数量、学习率、批大小、网络类型、初始化方法等
class HyperParameters2(object):
def __init__(self, n_input, n_hidden, n_output,
eta=0.1, max_epoch=10000, batch_size=5, eps = 0.1,
net_type = NetType.Fitting,
init_method = InitialMethod.Xavier):
LossFunction- 损失函数类,包含三种损失函数的代码实现NeuralNet2- 神经网络类,初始化、正向、反向、更新、训练、验证、测试等一系列方法TrainingTrace- 训练记录类,记录训练过程中的损失函数值、验证精度WeightsBias- 权重矩阵类,初始化、加载数据、保存数据
代码位置⚓︎
ch09, HelperClass2
- 双层神经网络解决方案的基本代码都在
HelperClass2子目录下
参考文献⚓︎
[1] Hornik, K., Stinchcombe, M., and White, H. (1989). Multilayer feedforward networks are uni-versal approximators. Neural Networks, 2, 359–366. 171