14.2 回归任务真实案例
14.2 回归任务 - 房价预测⚓︎
14.2.1 下载数据⚓︎
数据集来自:"https://www.kaggle.com/datasets/harlfoxem/housesalesprediction/download?datasetVersionNumber=1",此数据集是 King County 地区2014年五月至2015年五月的房屋销售信息,适合于训练回归模型。
下载后是一个 archive.zip 文件,解压到 "ch14-DnnBasic\ExtendedDataReader\data\" 目录下成为 kc_house_data.csv 文件。
然后运行 "ch14-DnnBasic\ExtendedDataReader\Level2_HouseDataProcessor.py",将会生成两个文件:
- ch14.house.train.npz,训练文件
- ch14.house.test.npz,测试文件
数据字段解读⚓︎
- id:唯一id
- date:售出日期
- price:售出价格(标签值)
- bedrooms:卧室数量
- bathrooms:浴室数量
- sqft_living:居住面积
- sqft_lot:停车场面积
- floors:楼层数
- waterfront:泳池
- view:有多少次看房记录
- condition:房屋状况
- grade:评级
- sqft_above:地面上的面积
- sqft_basement:地下室的面积
- yr_built:建筑年份
- yr_renovated:翻修年份
- zipcode:邮政编码
- lat:维度
- long:经度
- sqft_living15:2015年翻修后的居住面积
- sqft_lot15:2015年翻修后的停车场面积
一些考虑:
- 唯一id在数据库中有用,在训练时并不是一个特征,所以要去掉
- 售出日期,由于是在一年内的数据,所以也没有用
- sqft_liging15的值,如果非0的话,应该替换掉sqft_living
- sqft_lot15的值,如果非0的话,应该替换掉sqft_lot
- 邮政编码对应的地理位置过于宽泛,只能引起噪音,应该去掉
- 返修年份,笔者认为它如果是非0值的话,可以替换掉建筑年份
- 看房记录次数多并不能代表该房子价格就高,而是因为地理位置、价格、配置等满足特定人群的要求,所以笔者认为它不是必须的特征值
所以最后只留下13个字段。
数据处理⚓︎
原始数据只有一个数据集,所以需要我们自己把它分成训练集和测试集,比例大概为4:1。此数据集为csv文件格式,为了方便,我们把它转换成了两个扩展名为npz的numpy压缩形式:
house_Train.npz,训练数据集house_Test.npz,测试数据集
加载数据⚓︎
与上面第一个例子的代码相似,但是房屋数据属性繁杂,所以需要做归一化,房屋价格也是至少6位数,所以也需要做归一化。
这里有个需要注意的地方,即训练集和测试集的数据,需要合并在一起做归一化,然后再分开使用。为什么要先合并呢?假设训练集样本中的房屋面积的范围为150到220,而测试集中的房屋面积有可能是160到230,两者不一致。分别归一化的话,150变成0,160也变成0,这样预测就会产生误差。
最后还需要在训练集中用GenerateValidaionSet(k=10)分出一个1:9的验证集。
14.2.2 搭建模型⚓︎
在不知道一个问题的实际复杂度之前,我们不妨把模型设计得复杂一些。如下图所示,这个模型包含了四组全连接层-Relu层的组合,最后是一个单输出做拟合。
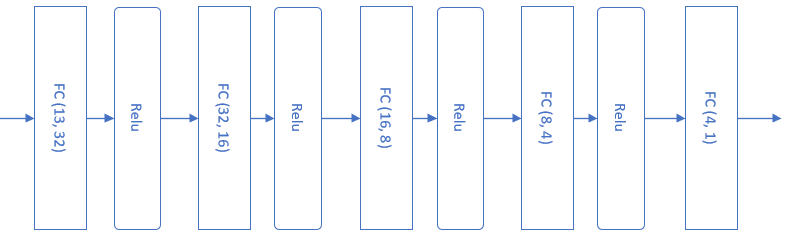
图14-5 完成房价预测任务的抽象模型
def model():
dr = LoadData()
num_input = dr.num_feature
num_hidden1 = 32
num_hidden2 = 16
num_hidden3 = 8
num_hidden4 = 4
num_output = 1
max_epoch = 1000
batch_size = 16
learning_rate = 0.1
params = HyperParameters_4_0(
learning_rate, max_epoch, batch_size,
net_type=NetType.Fitting,
init_method=InitialMethod.Xavier,
stopper=Stopper(StopCondition.StopDiff, 1e-7))
net = NeuralNet_4_0(params, "HouseSingle")
fc1 = FcLayer_1_0(num_input, num_hidden1, params)
net.add_layer(fc1, "fc1")
r1 = ActivationLayer(Relu())
net.add_layer(r1, "r1")
......
fc5 = FcLayer_1_0(num_hidden4, num_output, params)
net.add_layer(fc5, "fc5")
net.train(dr, checkpoint=10, need_test=True)
output = net.inference(dr.XTest)
real_output = dr.DeNormalizeY(output)
mse = np.sum((dr.YTestRaw - real_output)**2)/dr.YTest.shape[0]/10000
print("mse=", mse)
net.ShowLossHistory()
ShowResult(net, dr)
超参数说明:
- 学习率=0.1
- 最大
epoch=1000 - 批大小=16
- 拟合网络
- 初始化方法Xavier
- 停止条件为相对误差
1e-7
net.train()函数是一个阻塞函数,只有当训练完毕后才返回。
在train后面的部分,是用测试集来测试该模型的准确度,使用了数据城堡(Data Castle)的官方评测方法,用均方差除以10000,得到的数字越小越好。一般的模型大概是一个7位数的结果,稍微好一些的是6位数。
14.2.3 训练结果⚓︎
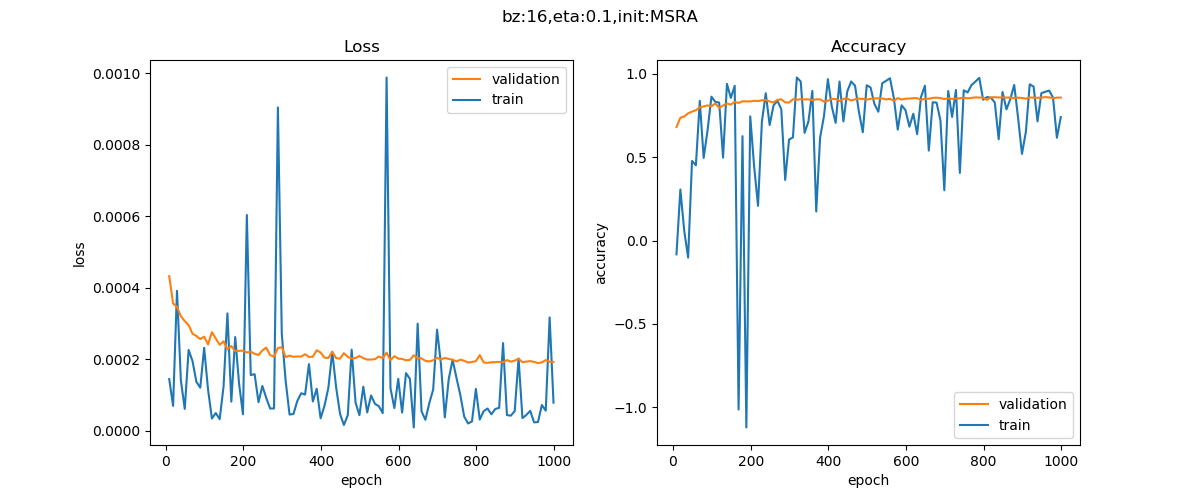
图14-6 训练过程中损失函数值和准确率的变化
由于标签数据也做了归一化,变换为都是0至1间的小数,所以均方差的数值很小,需要观察小数点以后的第4位。从图14-6中可以看到,损失函数值很快就降到了0.0002以下,然后就很缓慢地下降。而精度值在不断的上升,相信更多的迭代次数会带来更高的精度。
再看下面的打印输出部分,用R2_Score法得到的值为0.841,而用数据城堡官方的评测标准,得到的MSE值为2384411,还比较大,说明模型精度还应该有上升的空间。
......
epoch=999, total_iteration=972999
loss_train=0.000079, accuracy_train=0.740406
loss_valid=0.000193, accuracy_valid=0.857289
time used: 193.5549156665802
testing...
0.8412989144927305
mse= 2384411.5840510926
代码位置⚓︎
ch14, Level2